一、业务增长MySQL带来的业务痛点分析:
1. 性能瓶颈:
- 随着公司的业务快速发展,数据库中的数据量猛增,访问性能也变慢了,单台MySQL实例无法应对和满足大规模数据管理和请求访问,导致数据库性能下降,成为瓶颈。
- 关系型数据本身就比较容易形成系统瓶颈,无论是从单机存储容量、连接数、处理能力都有限。
- 当单表的数据量达到1000W以后,由于查询和操作的维度较广,哪怕使用了MySQL从库读写分离、优化索引等操作时,性能还是无可避免严重下降。
2. 数据强一致性同步延迟:
- 当架构增加Redis、RabbitMQ等消息队列
- OLTP的大数据量统计数据类异构表同步只能满足业务的T+1
- 系统架构中,异步设计方案中的中间件故障,导致数据重传、数据丢失
二、数据库应用的类型:
| Item | 区分 | OLAP | OLTP |
|---|---|---|---|
| 1 | 名称 | 在线分析处理(Online Analytical Processing) 在线事务处理 | (Online Transaction Processing) |
| 2 | 作用 | 处理企业级的决策分析、战略分析以及业务分析等 | 处理企业级的常规业务操作,如公司的采购、销售、存储、支付等 |
| 3 | 侧重点 | 多维数据分析技术和聚合算法,方便分析数据 | 强调数据的精确、事务的原子性和并发性 |
| 4 | 数据类型 | 历史性、汇总性、非实时性、不可变性数据 | 实时的、明细的、实时性的、可变性数据 |
| 5 | 场景 | 数据仓库 | 常规业务操作 |
| 6 | 查询模式 | 采用复杂的算法和存储结构,如多维数据库和立方体结构 | 需要简单的SQL语句,如基本的、事务相关的查询 |
| 7 | 性能要求 | 更高的存储要求和处理能力 | 快速且稳定的响应速度,可扩展性和高可用性 |
| 8 | 应用场景 | 企业级的决策支持和战略分析等领域 | 采购、销售、库存管理、银行交易等领域,极短的时间内快速响应用户请求,从而保证业务的正常运行 |
所以,在日常的企业级应用中,OLAP和OLTP针对不同的业务场景,有不同的解决方案。OLAP主要用于企业级决策和战略分析,需要快速的数据查询和分析技术。相反,OLTP主要用于企业日常操作,需要快速的数据更新和处理技术。
三、项目中的优化手段之《分库分表》:
1. 业务痛点:
- 由于数据量过大而导致数据库性能降低的问题
2. 解决的问题:
- 优化单一表数据量过大而产生的性能问题,使得单个表的数据量变小,提高检索性能,一定程度上可以缓解查询性能瓶颈
- 避免IO争抢并减少锁表的几率
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,在一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
- 有些系统中使用的“冷热数据分离”,备份历史库
- 在高并发和海量数据的场景下,分库分表能够有效缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源的瓶颈
3. 带来新的问题:
- 跨库join(安全性等方面考虑,一般是禁止跨库join的)
- 分布式事务
- 业务复杂度增加
- 投入的硬件成本也会更高
- 跨分片的复杂查询,跨分片事务等
- 跨节点关联查询
- 跨节点多库进行查询时,limit分页,order by排序问题,就变得比较复杂
- 主键避重,主键值ID无法保证全局唯一
- 公共表、参数表、数据字典表等都是数据量较小,变动少,每个数据库都保存一份
四、TDSQL-C MySQL Serverless解决的痛点:
TDSQL-C MySQL Serverless实例提供了CPU、内存的实时弹性能力,构建云上资源架构下的MySQL产品新形态。
1. 常规业务下的痛点:
| Item | 业务方案 | 业务痛点 | Serverless实例解决方案 |
|---|---|---|---|
| 1 | 自建MySQL实例 | (1). 需要购买大量的云服务器构建MySQL集群,设备成本费用高 (2). 专人运维成本,部署业务 (3). 双11等活动时,提前负责服务的扩缩容 |
(1). 按量收费,不使用不收费 (2). 云函数计算,从CI/CD到服务部署,扩缩容,全部自动完成,客户可以更专注于业务代码 |
| 2 | 传统的云数据库 | (1). 提供多种内存/CPU规格给用户购买 (2). 用户只能按最大负载量购买满负载配置,即使没有使用到,也需要为选中的规格付费 |
(1). 自动扩缩容,访问量上来时自动扩容,降低时自动缩容,用户不需要关注规格 (2). 按照实际使用的资源付费 (3). 不使用不计费,如果没有访问,不应该收费 |
2. Serverless数据库特点:
举个场景:如果自己想要出行就只能购买汽车、摩托车,现在可以直接通过滴滴等第三方平台使用打车服务,只需输入目的地即可,不需要再关注买车的坑、开车怕被撞和汽车保养的问题,核心诉求得到了更好的满足。
Serverless数据库可以看做,直接在云上直接购买虚拟机,部署业务,负责服务的扩缩容,从CI/CD到服务部署,扩缩容,全部自动完成,用户只需要更专注于业务代码即可。
Serverless数据库的基本特点是无需运维、以API方式提供服务、按实际使用计费、无使用无费用等。
3. 在业务波动较大的场景下,普通实例和Serverless实例资源使用和规格变化情况如下图所示:

由上图可以看到,在业务波动较大的场景下:
| Item | 数据实例 | 资源低谷期 | 资源高峰期 | 灵活性 |
|---|---|---|---|---|
| 1 | 普通实例 | 在低谷期浪费的资源较多 | 在高峰期资源不足,业务受损 | 比较固定的资源 |
| 2 | Serverless实例 | 在低谷期可以动态弹性释放不需要的资源,从而减少了资源浪费 | 在高峰期也能完全满足业务需求,保证业务不受损,提高了系统的稳定性 | 动态弹性伸缩能力 |
总结:由于Serverless实例的规格会随业务需求量随时调整,总体浪费的资源很少,提升了资源利用率,降低了资源使用量。
4. TDSQL-C MySQL Serverless的优势:
| Item | 优势项 | 描述 |
|---|---|---|
| 1 | 更低的成本 | (1). 对于创业初期的企业,MySQL Serverless不依赖其它的基础设施和相关服务。 (2). 即买即用并可以提供稳定和高效的数据存取服务。 (3). 使用期间只需要为占用的资源按使用量付费。 |
| 2 | 更大的存储空间 | (1). 存储空间最大可高达32 TB。 (2). 根据实例数据量自动扩展,可以有效避免集群存储资源不足对业务造成影响。 |
| 3 | 计算资源自动弹性扩缩容 | (1). 用户读取和写入需要的计算资源可弹性伸缩。 (2). 不需要手动扩缩容,极大减少了运维成本和系统风险。 |
| 4 | 全面托管和免运维 | (1). 版本升级、系统部署、扩缩容、报警处理等底层服务不需要关心。 (2). 用户无感知,业务无影响,服务持续可用,真正免运维。 |
5. 适用场景:
- 开发、测试环境等低频数据库使用场景
- 中小企业建站服务等SaaS应用场景
- 个人开发者用户
- 学校教学、学生实验等教育场景
- 物联网(IoT)、边缘计算等不确定负载场景
- 全托管或希望完全免运维的用户
- 业务有波动或不可预测的用户
- 具有间歇性定时任务的业务场景
五、TDSQL-C Serverless数据库的三大特性:
Serverless 是腾讯自研云原生数据库 TDSQL-C MySQL 版的无服务器架构版,自动扩缩容,仅按照实际使用量计费,不用不计费,轻松应对业务数据量动态变化和持续增长。
1. 自动启停,不使用无计费:
Serverless 服务支持自定义实例自动暂停时间,无连接时实例会自动暂停。当有任务连接接入时,实例会秒级无间断自动唤醒。
2. 按使用量计费:
可调整 CCU 弹性扩缩容的范围,Serverless 集群会在该范围内根据实际业务压力自动增加或减少 CCU。
3. 自动扩缩容:
Serverless 集群会持续监控用户的 CPU、内存等 workload 负载情况,根据一定的规则触发自动扩缩容策略。
六、自动启停,不使用无计费:
1. 需求描述:
| 1. 需求背景: |
|---|
| 可根据业务需要,自助开启或关闭自动暂停设置 |
| 2. 实现思路: |
|---|
| 1. 自动启停的逻辑比较简单,默认只要1小时(用户可配)内监测到没有访问就回收掉计算节点,访问回来就把节点重新拉起。 2. 也可以在控制台,指定数据库实例进行手动暂停操作。 |
2. 测试方案:
date +"%T.%N" && mysql -h gz-cynosdbmysql-grp-9eujfhd.sql.tencentcdb.com -P 27304 -u root -pDb123. -Nse "show databases" && date +"%T.%N"
3. 测试结果分析:
Linux的date命令可以用来显示或设定系统的日期与时间,通过获取命令开始前时间,再获取命令开始后时间,可以得到这条命令一共花费的时间值。
命令参数:
%T 时间(含时分秒,小时以24小时制来表示)。
%N 在显示时,插入新的一行。
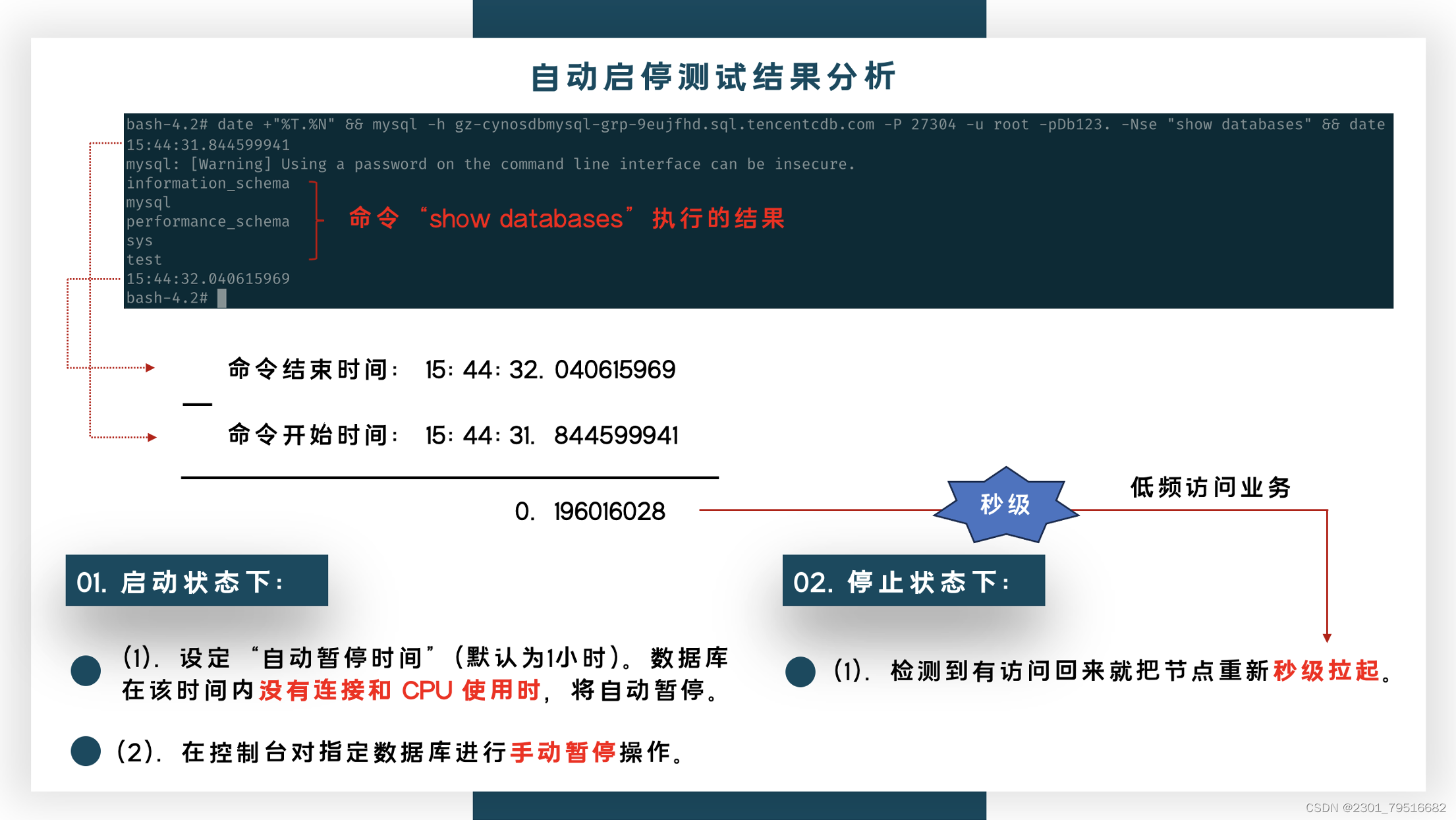
先将TDSQL-C MySQL如上述两种方法停掉,使用MySQL自带的“show databases”命令查看所有的数据库,因为默认的命令,也不涉及到什么慢查询,只能算空负载运行。可以看到执行的时间差,可以是秒级连接。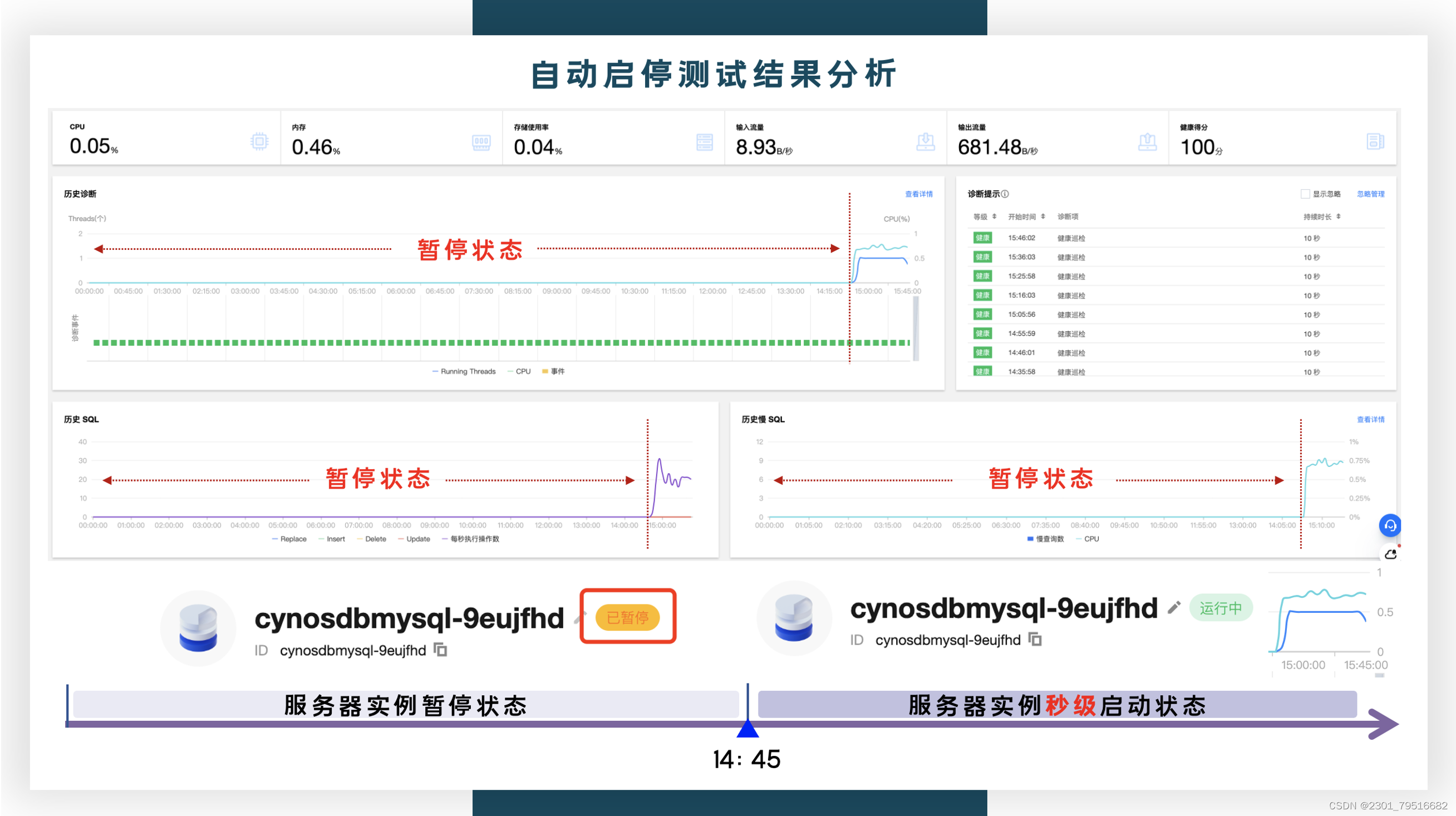
从TDSQL-C MySQL的实时监控报表也可以看出,在14:15之前的时间段是暂停的状态,在15:00左右,有连接访问,马上就秒级启动服务器,充分的说明了当没有数据库请求时,监控服务会触发计算资源的回收。当用户再次访问时,接入层则会唤醒集群,再次提供访问。
4. 原理说明:
TDSQL-C Serverless冷启动秒级内就能完成,怎么做到能贴近云函数的启动时间呢?
当有连接访问时,系统会秒级自动启动处于暂停状态的数据库,用户不需设置重连机制。
- TDSQL-C MySQL 版的接入层增加了一个恢复感知器(简称 perceptron)的模块来实现请求转发,perceptron 在和客户端握手之后,不会使用户端到集群的连接断连。恢复集群后,与 TDSQL-C MySQL 版握手,后续转发四层报文。
- 整体流程设计采用了两个挑战随机数进行鉴权,以实现中继模块 perceptron 不存储用户名密码的情况下也可以完成用户名密码验证,保证了用户密码的安全性,也不会引入存储密码不一致的问题。

- 当集群处于暂停状态时,仅保留 perceptron 的路由
- 当集群恢复后时,系统同时保留 perceptron 的路由和 TDSQL-C 的路由,并设置 perceptron 的路由权重为 0,以实现新增连接直连到 TDSQL-C,同时存量与perceptron 已经建连的连接依然能够通讯。
七、按使用量计费:
1. TDSQL-C MySQL 版 Serverless 服务的计费说明:
| 1. 计费模式 |
|---|
| (1). Serverless 服务的计算和存储独立计费。 (2). 计算按 CCU 个数计费,存储按使用量 GB 计费,计费系统按秒计费,按小时结算。 |
| 2. 计费公式 |
|---|
| Serverless 总费用 = 计算节点费用 + 存储空间费用 = Serverless 算力价格 × CCU 量 + 存储空间价格 × 存储空间 |
定义了一个算力单元CCU(TDSQL-C Compute Unit)=max {CPU, MEM/2, 最小规格}。
- MEM/2的含义是,由于定义的规格CPU/内存比都是1/2,内存除以2相当于把内存换算成CPU。
- 整体还是以CPU决定整个算力。
- 通过计算每个小时CCU平均值给用户计费。
2. 创建一张订单表:
创建一张订单表,用于方便写SQL语句进行压测,如下我们会进行一下insert写的场景压测,分析一下,TDSQL-C MySQL怎么样实现使用量计费。
CREATE TABLE `orders` (
`order_id` bigint(20) NOT NULL COMMENT '订单编号',
`customer_id` bigint(10) NOT NULL COMMENT '下单用户编号',
`product_id` bigint(15) NOT NULL COMMENT '产品编号',
`product_name` varchar(30) NOT NULL COMMENT '产品名称',
`product_price` decimal(10,2) NOT NULL COMMENT '产品价格',
`quantity` int(11) NOT NULL COMMENT '产品数量',
`total_price` decimal(10,2) NOT NULL COMMENT '总价格',
`order_time` datetime NOT NULL COMMENT '下单时间',
`delivery_time` datetime NOT NULL COMMENT '发货时间',
`status` int(1) NOT NULL DEFAULT '1' COMMENT '订单状态 1:已完成 0:未完成',
`address` varchar(100) NOT NULL COMMENT '家庭住址',
`phone` bigint(11) NOT NULL COMMENT '联系电话',
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='订单信息表';
创建表执行SQL成功。

3. 使用腾讯云的“云压测”进行测试:
云压测(Performance Testing Service, PTS)是一款分布式性能测试服务,可模拟海量用户的真实业务场景,全方位验证系统可用性和稳定性。支持按需发起压测任务,提供百万并发多地域流量发起能力。提供流量录制、场景编排、流量定制、高级脚本定制等功能,可快速根据业务模型定义压测场景,真实还原应用大规模业务访问场景,帮助用户提前识别应用性能问题。
创建一个压测的案例场景,为了更好的说明按使用量来计费,我们选择了递增压测的方案,模拟一下根据不同的业务量,产生不同的负载,Serverless 集群会在该范围内根据实际业务压力自动增加或减少 CCU,根据不同的算力CCU产生不同的费用。
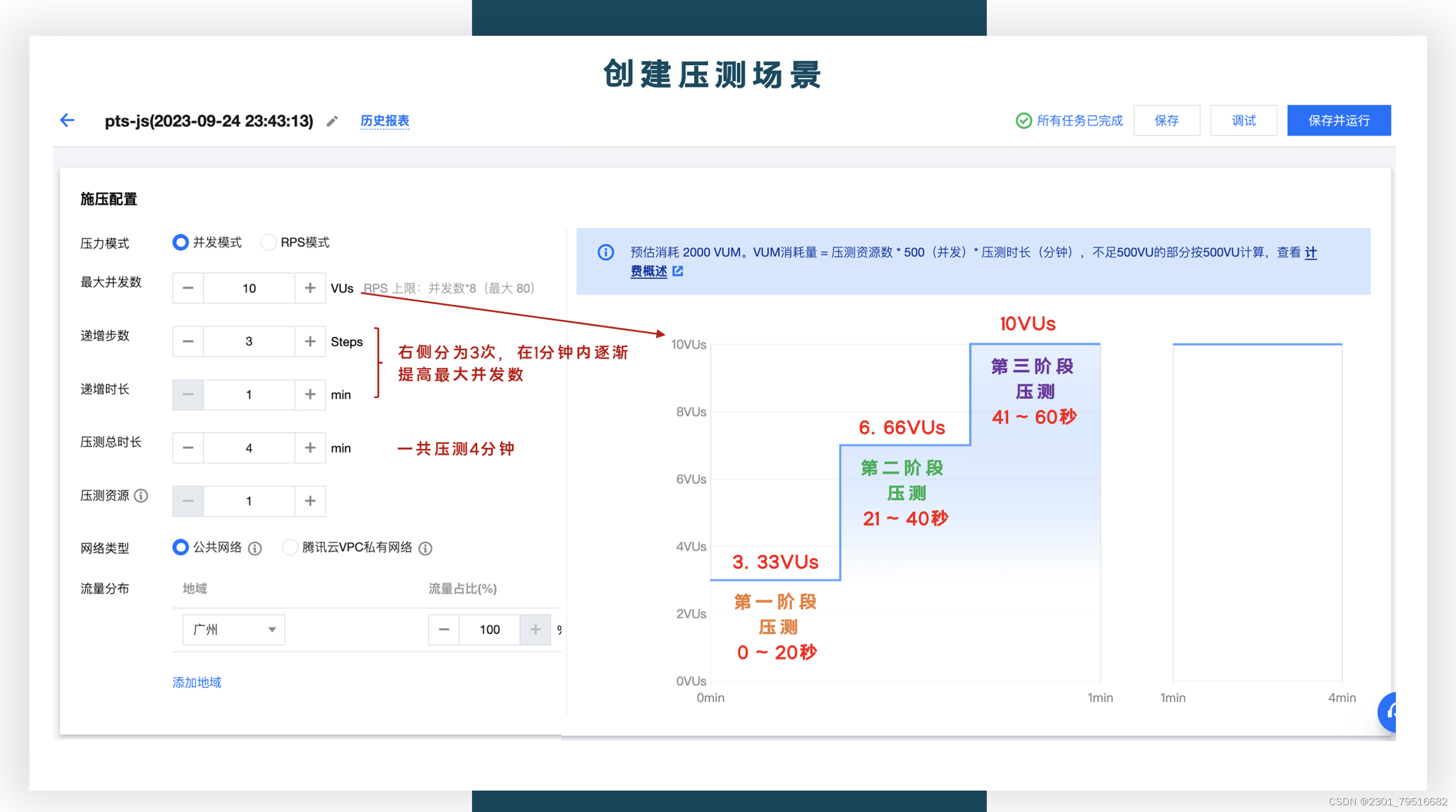
压测场景说明:
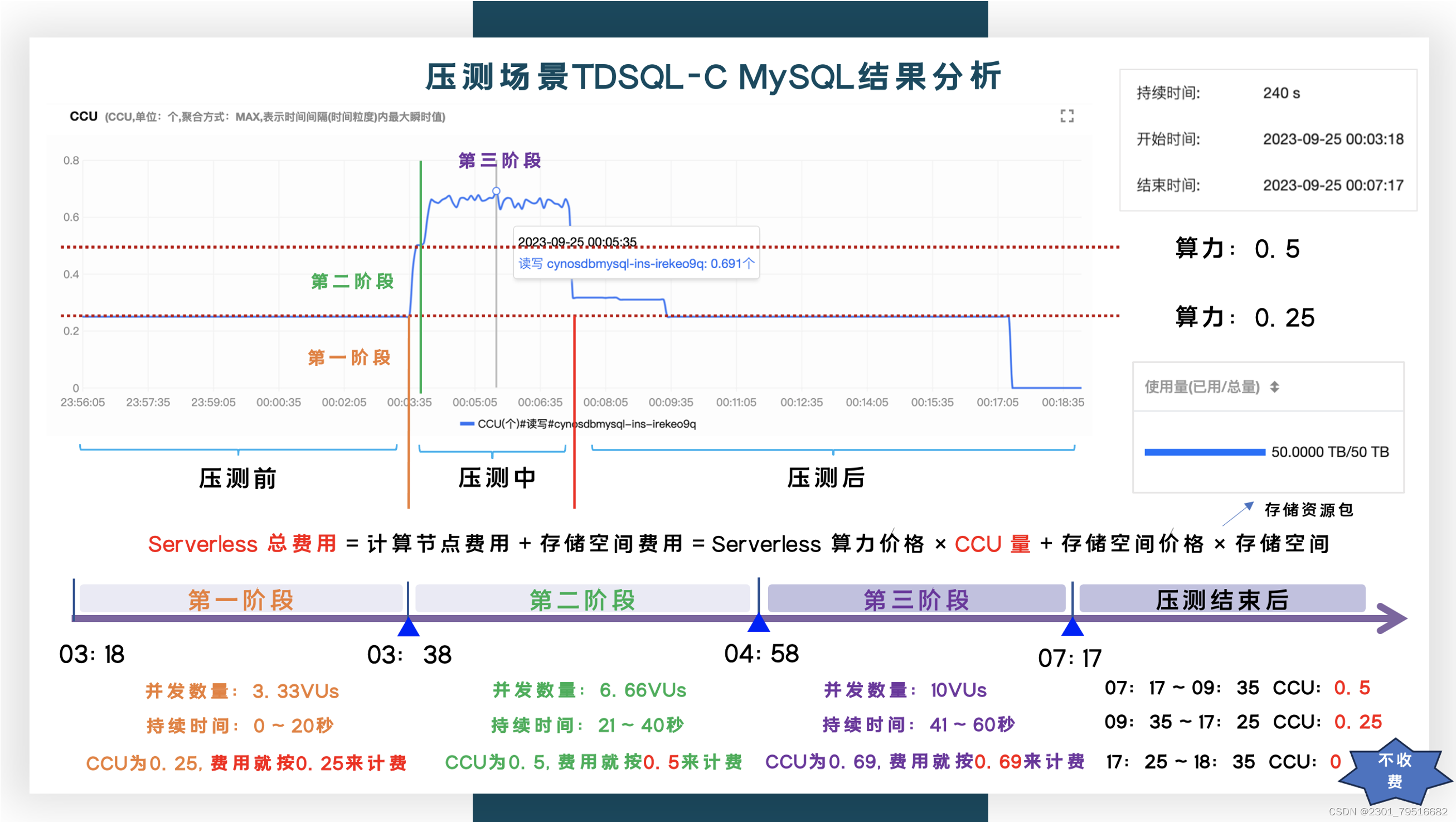
一共压测2000VUM,最大的并发数是10VUs,为了还原生产的场景,按阶段性递增进行压测,一共压测4分钟,在1分钟内分3次过去逐渐增加并发数,由3.33VUs到6.66VUs,再到10VUs,演示流量逐渐慢慢增长,看一下CCU的弹性自动扩容能力。
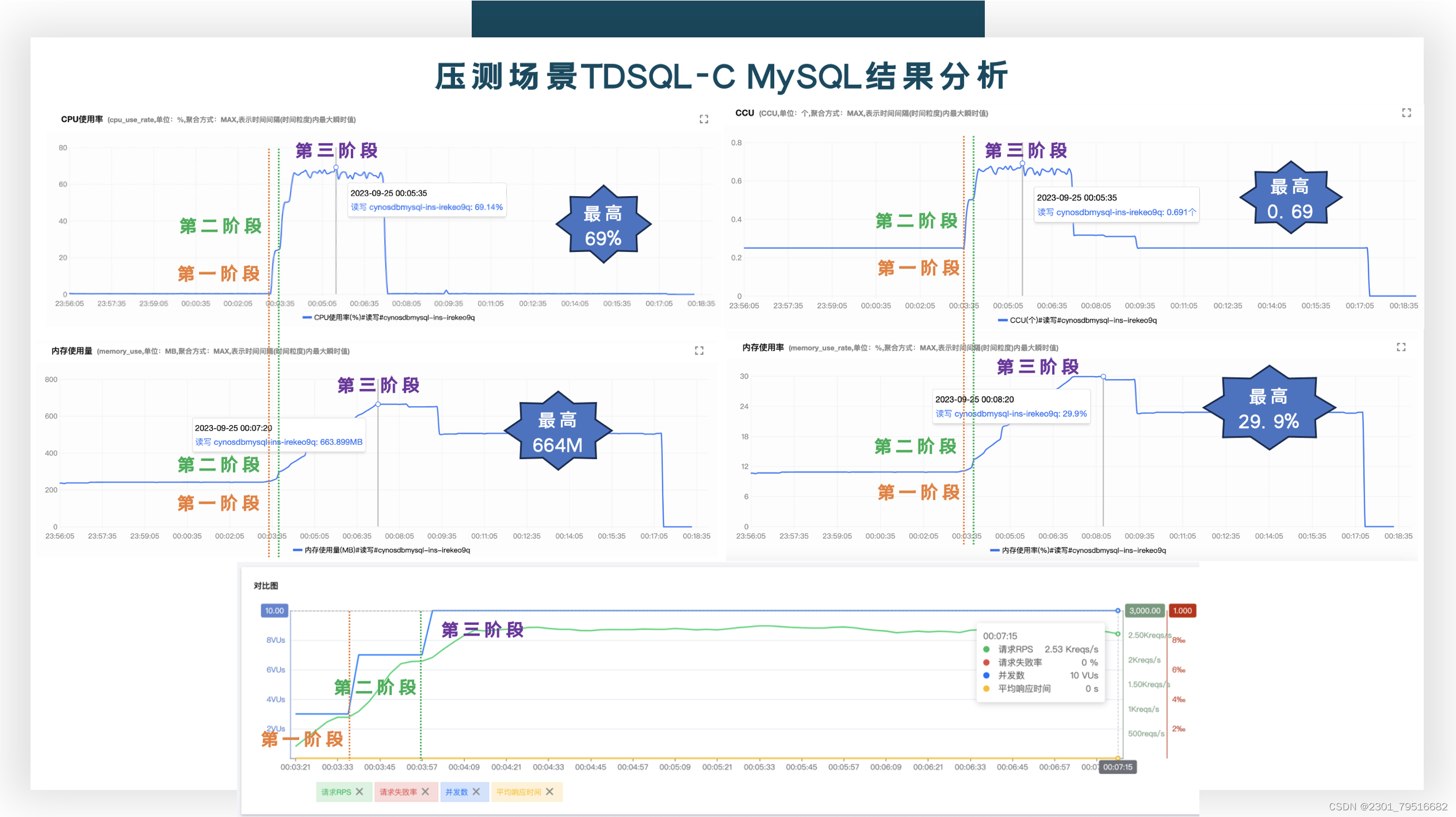
以下是这次递增压测的结果报表,一共是576809个请求(接近6w个请求),没有一个网络请求失败的,平均的响应时间是在3.75ms,最高的并发数是在10VUs,下面的折线图也是分为3次有规律的进行递增。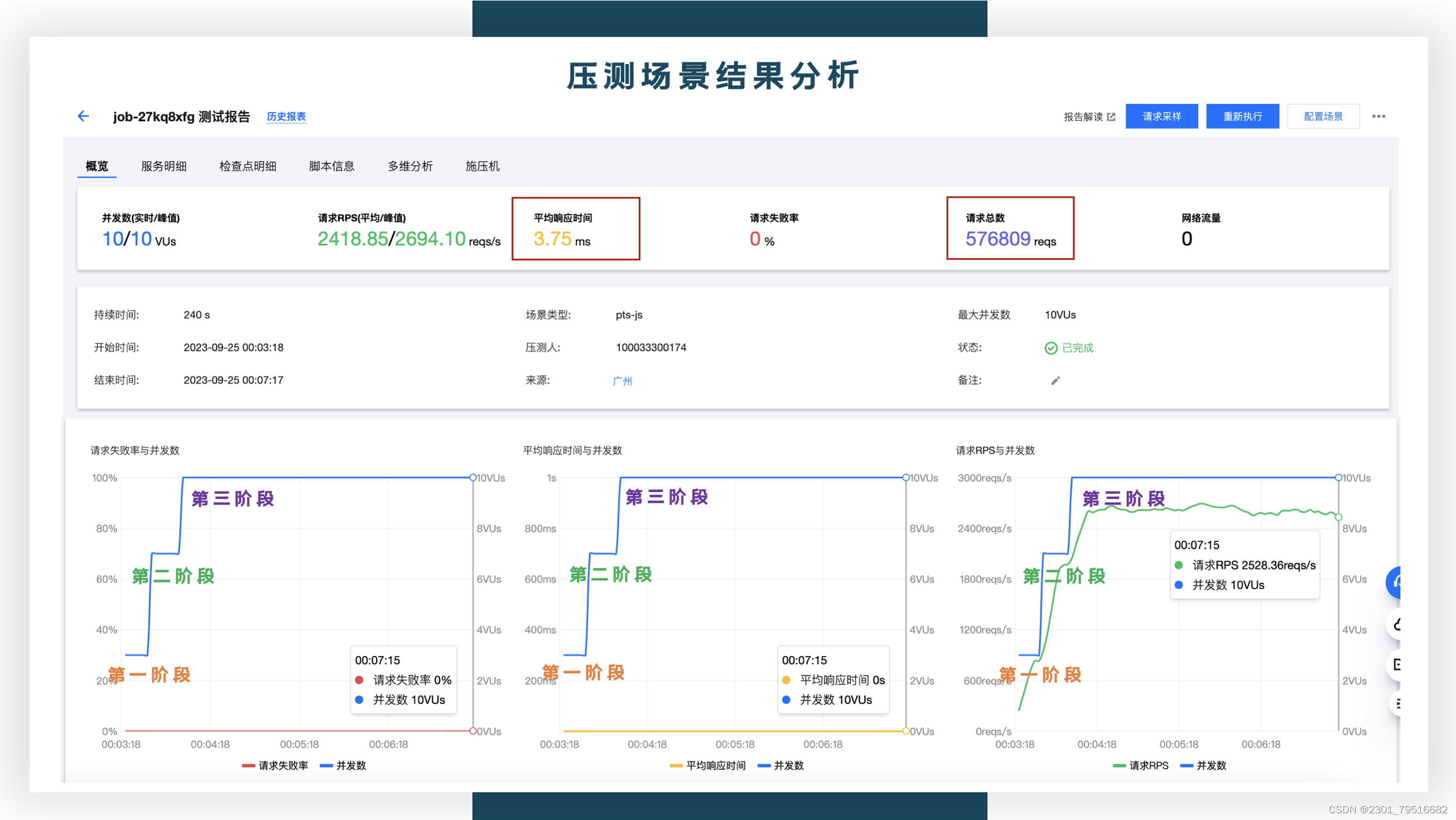
举例说明,我们设置了算力配置为:选择最小最大规格为0.25核-1核:

从图中可以看到,递增压测分为3波:
- 第一波初期的CCU在0.25左右,就会按0.25算力来进行计费
- 第二波的CCU在0.5左右,就会按0.25算力来进行计费
- 第三波业务高峰过来,CCU逐渐升高到0.691左右,就会按照0.69来进行计费,能够很好的应对业务负载。
- 在压测结束后,CCU逐渐从0.5降到0.25,再到0,不使用就不计费
下图可以看到我们在压测产生的同时,CCU的费用也提高了,可以很方便的进行自动扩缩容,访问量上来时自动扩容,降低时自动缩容,按照实际使用的资源付费,不使用不计费,如果没有访问,就不收费。

以下为CPU、内存的性能数据参考,都是正比的增长趋势,所以,上面讲到的CCU的计费方式,跟CPU和内存是有关系的。
八、自动扩缩容:
目标是做到秒级的扩缩容,并且期间对用户是平滑的,无感知的。
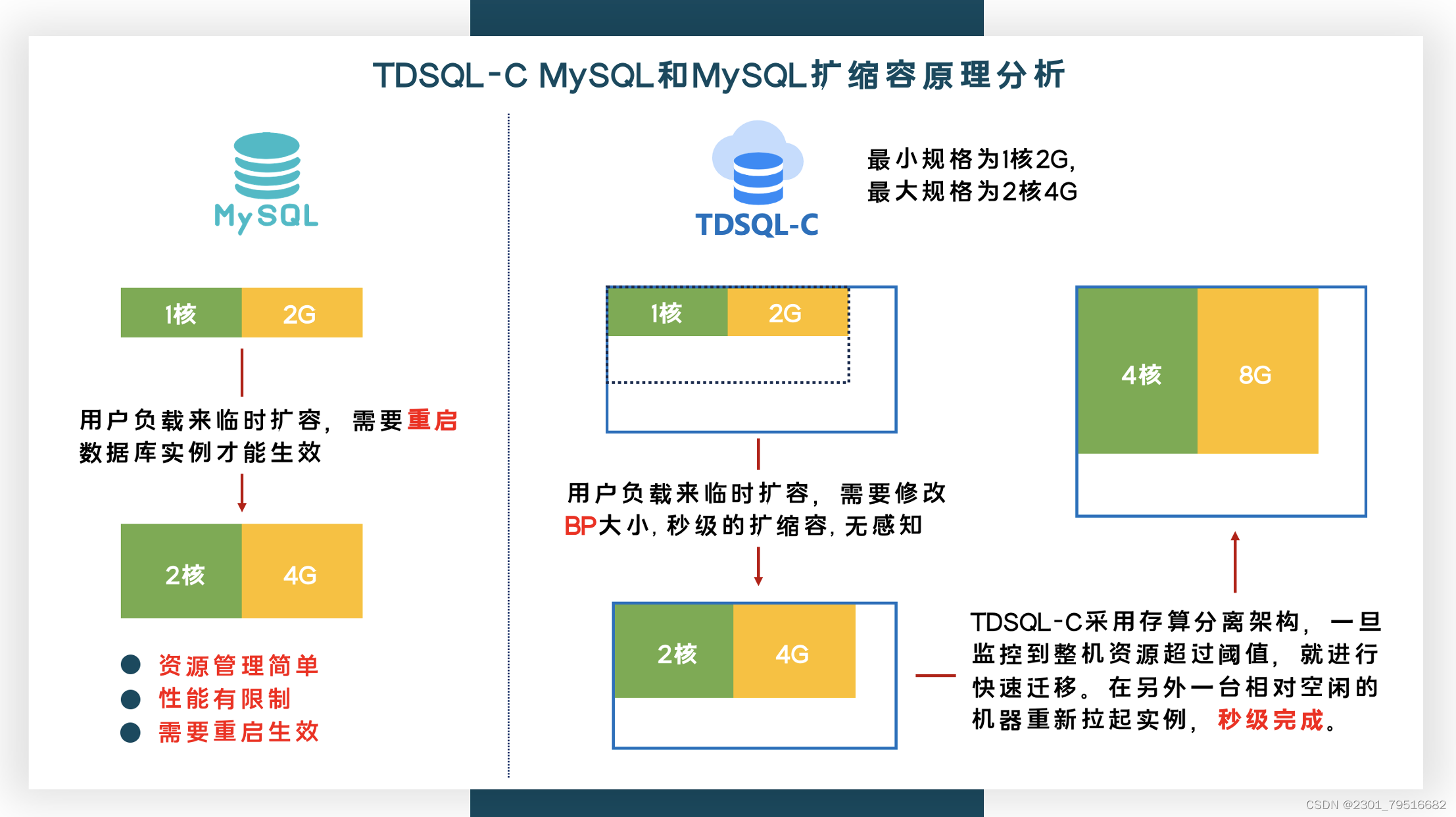
以上图为例子,用户在购买时选择最小规格为1核2G,最大规格为2核4G。
1. 如果是传统的MySQL数据库实例:
初始为1核2G,当业务访问过来,把CPU用满了时,用户需要手动去修改规则,修改后需要重启后才能生效。
2. 如果是TDSQL-C MySQL Serverless数据库实例:
- 初始就给用户提供最大CPU规格,内存则从最小规格开始,假设用户使用的CPU超过1核,并持续一段时间,将把内存从2G扩到4G。
- TDSQL-C Serverless的CPU资源不会受限,可以在设置的最大规格内任意使用。优点是用户性能不受限,引入的缺点是可能整机出现满负载。
- 由于TDSQL-C采用存算分离架构,一旦监控到整机资源超过阈值,就进行快速迁移。迁移其实就是在另外一台相对空闲的机器重新拉起实例,秒级完成。在资源负载上可以精准控制。
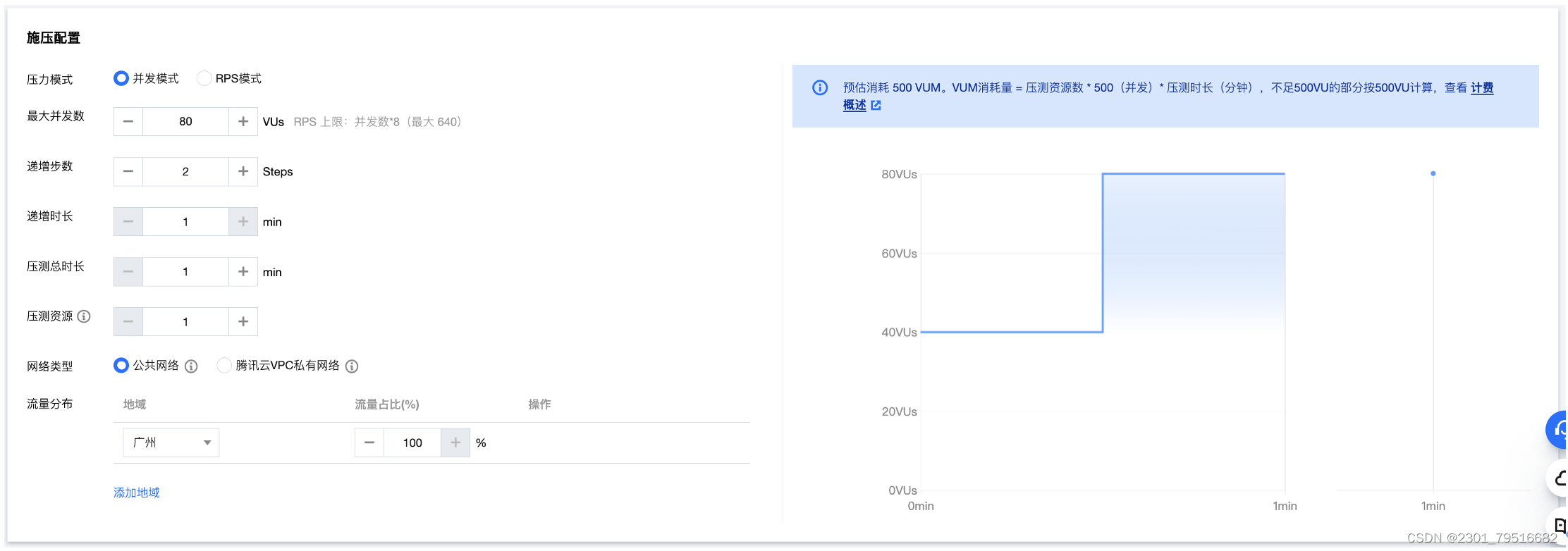
3. 创建压测测试场景(使用80VUs):
这里也是采用子递增压测的方式,但是之次使用最大的并发数为80VUs,在1分钟内全部压测完,然后,在前30s使用40VUs,后面30s直接使用80VUS。
4. 压测结果分析:
这里也是模拟一下,应对于突发急剧增加的流量,TDSQL-C MySQL是如何进行扩容的。
- 第一区间是比如正常的业务流量,如下单购物,使用了并发40VUs,最大使用的算力差不多是0.8左右
- 第二区间是突然遇到双11活动,业务的访问量马上急剧增加,这时候,TDSQL-C MySQL可以自动扩容到CCU接近4左右,可以完全满足业务突增的情况
- 第三区间表示活动结束了,对应的业务访问量就降下来了,可以看到CCU也可以弹性的回收缩回到0.8左右
- 第四区间在没有任何访问量的时候,监控服务会触发计算资源的回收,此时,CCU降低到0,没有使用,就可以不收费

从上图,我们可以得出一个结论:
- 秒级的扩缩容,期间对用户是平滑的,无感知
- Serverless 服务支持按实际计算和存储资源使用量收取费用,不用不付费
由于压测的并发数比较大,也可以看到TDSQL-C MySQL有一些诊断提示,我们也可以根据一些警告进行一些系统的优化,以对应业务的变化。

九、秒级扩容背后的架构原理:
1. 主流公司的现有架构:
很多公司目前的主流架构是采用单体冗余架构(一主多从),这种架构在扩展性存在很大的问题。
- 实例的升降级和读扩展,都需要通过数据搬迁来实现
- 随着数据量不断的增长,迁移耗时越来越长
2. 存算分离架构:
为了解决一主多从架构在扩展性这方面的问题,大多数采用的方案是采用存算分离架构。
- 一类是ShareNothing架构,计算和存储均支持水平扩展,扩展能力非常强。但是最大的问题是SQL兼容性,需要不断的持续构建和完善自己的生态。
- 另一类是ShareStorage架构,共享存储架构并没有改变查询引擎和ACI这些基础特性,可以做到100%的兼容性。
腾讯云优先选择了基于共享存储架构的数据库产品TDSQL-C提供Serverless服务。

TDSQL-C是腾讯云基于共享存储架构的云原生数据库,由于ToB业务对稳定性的要求很高,复用了云上比较成熟的组件。
- 在计算层使用腾讯维护的MySQL内核分支-TXSQL,复用它的bugfix和新特性
- 在存储层使用腾讯内部的云硬盘CBS,把CBS的核心存储和硬盘逻辑进行剖离,打造了统一存储平台HiSTOR
作为存储底座,加上云硬盘CBS、云分布式文件系统CFS等多款云上的产品,提供副本同步、故障自动迁移、数据校验等一系列完善的数据安全保障能力,这正是TDSQL-C MySQL Serverless产品能够稳定运行数年的重要基石。
十、 总结:
随着云计算的发展,Serverless架构带来的优势,就是用户不用更多的去考虑服务器的相关的运维工作,无需再去考虑规格大小、存储类型、网络带宽的问题,Serverless架构会帮助自动扩缩容、无需服务器运维了、无需备份数据、软件配置等工作。
随着 Serverless 概念的迅速普及,腾讯云数据库TDSQL-C也推出了 Serverless 产品形态,可以为用户提供更低成本、更灵活的云数据库服务,减少了用户维护数据库规格的负担。
通过上面对TDSQL-C Serverless 在自动扩缩容、按使用量计费、不使用不计费3个方面进行学习与探讨,TDSQL-C Serverless在无负载时不产生任何费用,而当业务流量到来时能够秒级自动扩容扛起突发请求,做到按使用量分配计算资源、按使用量进行扣除费用。
对于开发者和企业来说,Serverless 服务是腾讯云自研的新一代云原生关系型数据库 TDSQL-C MySQL 版的无服务器架构版,是全 Serverless 架构的云原生数据库。Serverless 服务支持按实际计算和存储资源使用量收取费用,不用不付费,可以为企业很好的进行降本增效。