目录
2、 Why should there be word embeddings?
1. What is an embedding matrix?
2. Why do you need to set the number of dimensions?
3. Advantages compared to one-hot encoding
4. What are word2vec and GLove?
1. The similarity between word embedding and graph embedding
1、 One-hot encoding
One-hot encoding is a method used in data preprocessing and feature engineering, primarily in machine learning and data analysis, to convert categorical data into a numerical format.
The one-hot encoding process involves converting each category into a binary vector, where each category is represented as a vector with all zero values except for a single element, which is set to 1 to indicate the presence of that category.
for example:Let's say there are four animals.
Cat: [1,0,0,0]
Dog: [0,1,0,0]
Ox: [0,0,1,0]
Sheep: [0,0,0,1]
The disadvantages are obvious: There are thousands of different words that appear in the real situation text。
1、Inability to express relationships between words.
2、This kind of overly sparse vector results in inefficient computation and storage.
2、 Why should there be word embeddings?
Text is unstructured data and is not computable.
However,vectors are structured data and are computable.
3、What is word embedding?
Word embedding is a class of methods for text representation. It serves the same purpose as one-hot encoding and integer encoding, but it has more advantages, such as word embeddings that can change high-dimensional one-hot sparseness to low-dimensional density.
Example: (as shown in the figure below:)
s='I like learning math' Using word embedding, each word in s is represented as a 128-dimensional vector (this dimension can be customized, as long as it can be kept consistent with the dimension of the embedding matrix) [Why set dimension] (the purpose is to capture the relationship between words).

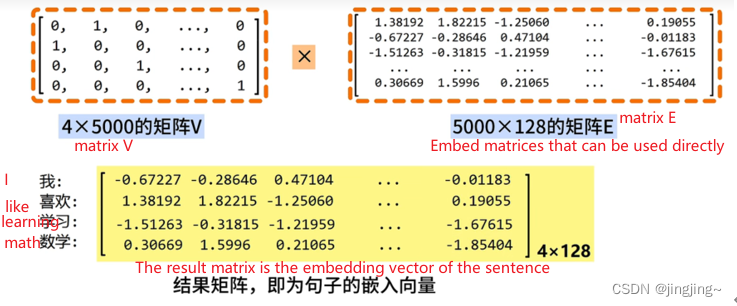
The right matrix E in the figure above is the embedding matrix.
1. What is an embedding matrix?
The embedding matrix is trained by specific word embedding algorithms, such as word2vec, fasttext, Glove, etc., to obtain a general embedding matrix. (as shown in the figure below)

2. Why do you need to set the number of dimensions?
The dimensionality is set to further illustrate the relationship between words (shown on the left side of the figure below)

Through the dimensionality reduction algorithm, not only the similarity can be expressed, but also the mathematical relationship can be obtained through calculation, and plotted on the two-dimensional plane, it can be found that the corresponding positions of words with similar semantics are also more similar.
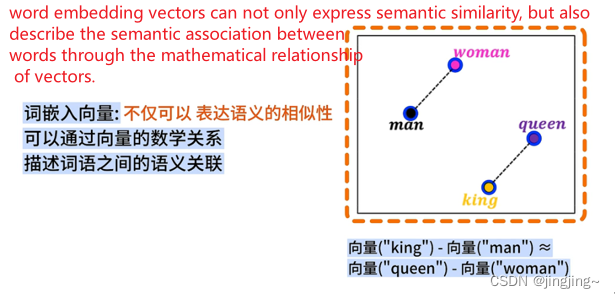
The above figure shows that word embedding vectors can not only express semantic similarity, but also describe the semantic association between words through the mathematical relationship of vectors.
3. Advantages compared to one-hot encoding
1. Through lower-dimensional expression, the expression efficiency is improved.
2. It can understand the semantics of words and reason about words, that is, words with similar semantics will be closer in vector space.
3. The embedding matrix is universal, and the same word vector can be used in different NLP tasks.
Detailed video reference: What is word embedding, Word Embedding algorithm_Bilibili_bilibili
什么是词嵌入,Word Embedding算法_哔哩哔哩_bilibili
4. What are word2vec and GLove?
Word2vec and Glove are both ways to Embedding. He was introduced in 2013 by Google's Mikolov to propose a new set of word embedding methods.
Word2vec has two training modes: CBOW (Continuous Bag-of-Words Model) and Skip-gram (Continuous Skip-gram Model)
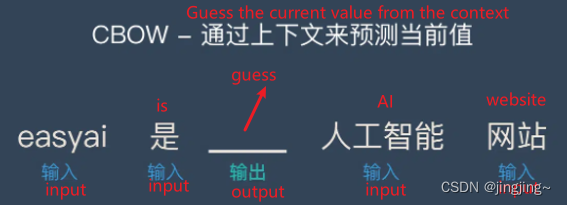
1. CBOW predicts the current value through context. It's the equivalent of subtracting a word from a sentence and letting you guess what that word is.
Like what:
2. Skip-gram uses the current word to predict the context. It's the equivalent of giving you a word and letting you guess what words might appear before and after.
Like what:

For details, please refer to: https://easyai.tech/ai-definition/word2vec/
For more information about the Glove algorithm, please refer to: http://www.fanyeong.com/2018/02/19/glove-in-detail/
4、the node embedding
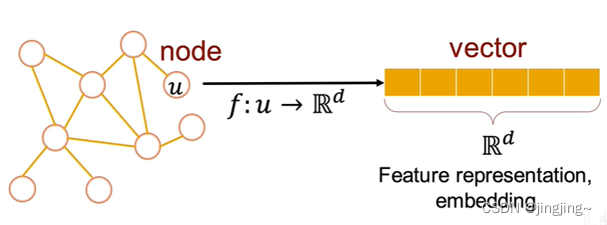
The graph into a low-dimensional continuous dense d-dimensional vector, d=6 in the figure above, is called graph embedding.
1. The similarity between word embedding and graph embedding
Word embeddings are similar to the random walk of the graph, there is a certain relationship between adjacent words (similar), and random walk is also similar to the adjacent nodes (the middle point can be predicted). (The left image is a node, and the right image is a word embedding)
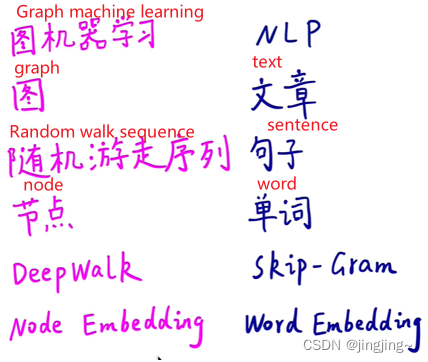
2. What is a random walk?
Random walk (deepWalk) is to select adjacent nodes in the graph is completely random, and its embedding disadvantages, complete random walk, training node embedding vectors, will only be close to oneself to resemble the existence, and far away but actually similar can not be captured.
For example, the Suez Canal and the Panama Canal in the picture below are not similar in random walks. It can only find similarities around the periphery.
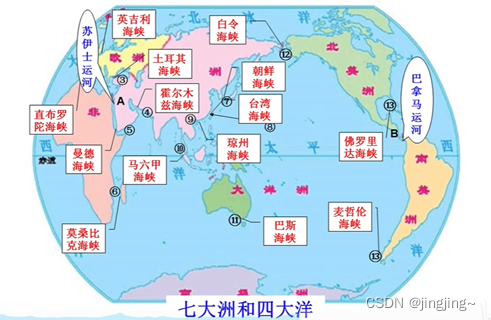
Disadvantages of DeepWalk:
1. Use a completely random walk to train nodes to embed vectors.
2. It can only reflect the community similarity information of adjacent nodes.
3. Unable to reflect the similar information of the functional roles of nodes.
Referenced video: https://www.bilibili.com/video/BV1BS4y1E7tf/?spm_id_from=333.788&vd_source=ce838d56b689e47d2bdd968af2d91d20
3.Node2vec

Node2vec is equivalent to a biased random walk (adjustable pq value). (a multiply weighted== weighted graph or multiply 1 == without weighted chart)
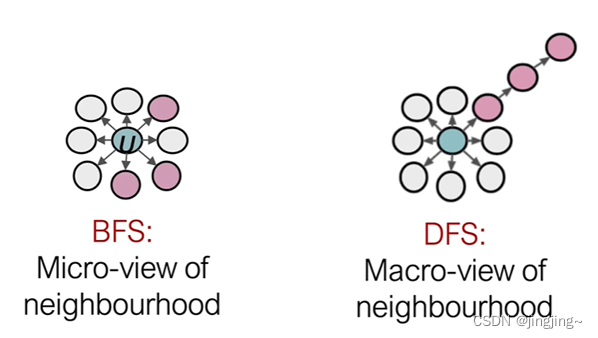
In the figure on the left, if p is reduced to BFS (to find the surrounding similarity), and if the q tone is small to DFS (to find the distance similar), it can be imagined as a combination of DFS and BFS. It is a second-order random walk, not a first-order deepWalk (equivalent to a special case of p=1, q=1).
4. Summary
(Node2vec graph embedding algorithm) is unsupervised and deepwalk (equivalent to using Word2vec on graphs):
1. Node2Vec solves the graph embedding problem by mapping each node in the graph as a vector (embedding).
2. Vectors (embeddings) contain the semantic information of the node (adjacent communities and functional roles).
3. For nodes with similar semantics, the distance of vectors (embeddings) is also close.
4. Vectors (embedding) are used for subsequent tasks such as classification, clustering, link prediction, and recommendation.
5. On the basis of DeepWalk's complete random walk, Node2Vec adds p and q parameters to achieve partial random walk. Different combinations of p and q correspond to different exploration scopes and node semantics.
6. DFS depth priority exploration, adjacent nodes, vector (embedding) distance is similar.
7. BFS breadth is explored first, and nodes with the same functional role have similar vector (embedding) distances.
8. DeepWalk is a special case of Node2Vec in p=1 and q=1.
5、Extension(LinkEmbedding)
It is the connection of two points, which is equivalent to fusing two points together.