文章目录
实验内容
一、进程的创建
编写一段源程序,使用系统调用fork()创建子进程,当此程序运行时,在系统中有父进程和子进程在并发执行。观察屏幕上的显示结果,并分析原因(源代码:forkpid.c)。
1、编辑源程序

2、编辑结果
3、编译和运行程序
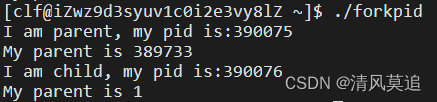
4、解释运行结果
假设命令./forkpid创建的进程称为A,则A中的fork()调用会创建一个子进程,称为B。
fork()函数只在父进程A中成功被调用一次,但是在A和B两个进程中都会有返回值。成功创建子进程后,在父进程A中,fork的返回值为创建的子进程的pid;在子进程中,fork的返回值为0。
因此,if(p1==0)后面的代码块会在子进程中被执行,而else后面的代码块会在父进程中被执行。由上述运行结果可知,进程的创建关系如下。
pid: 389733 --> 390075(A) --> 390076(B)
那么还有一个问题,上述运行结果中的My parent is 1,岂不是说B进程的父进程pid是1?这不是矛盾了吗?根据我所查阅的资料,这是因为父进程A比子进程B先结束,B中查找自己的父进程时,父进程A已经不在了,会使用pid为1的进程代替。在Linux中,pid号为1的进程是所有进程的祖先进程。
参考:
- https://blog.csdn.net/lein_wang/article/details/81946108 - 为什么父进程id是1
- https://www.cnblogs.com/alantu2018/p/8526970.html - linux的 0号进程 和 1 号进程
二、进程共享
父进程创建子进程后,父子进程各自分支中的程序各自私有,其余部分,包括创建前和分支结束后的程序段,均为父子进程共享。(源代码:forkshare_1.c)
1、运行

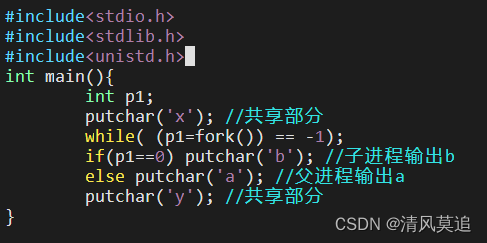

2、解释运行结果
根据运行结果我们很容易看出,进程调度顺序和上一节中一样,是先调度父进程再调度字进程。其中前三个字母xay是父进程的输出,后面三个字母xby则是子进程的输出。
可令人困惑不解的是,子进程不也应该从fork()返回的地方开始运行吗?那为什么'x'会被输出两次?我一时间有些蒙圈。
在查找资料后,我尝试了另一个示例,其中仅仅是将putchar('x')换成了printf("x\n"),而最主要的区别就是多了一个\n。下面是代码及其运行结果。
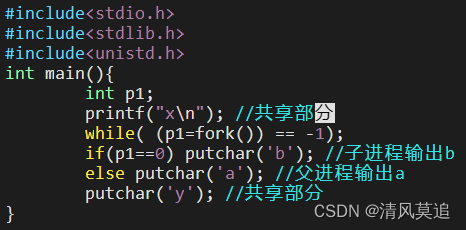

子进程会从fork()返回的地方开始执行,没有错。问题出在stdout缓冲区的机制上,在输出xayxby的示例中,运行putchar('x')语句并没有直接将x写到屏幕上,而仅仅是将x放到了缓冲里。随后运行fork()创建子进程,会将父进程的stdout缓冲区也复制一份,而复制的缓冲区中就包含了刚刚放入的x。这便是两个x从何而来。
而如果打印的内容中包含了\n,就会马上将内容写到屏幕上并刷新缓冲区,这便是为什么第二个示例中x只有一个。
参考:
- https://blog.csdn.net/koches/article/details/7787468 - linux中fork–子进程是从哪里开始运行
三、进程终止
如果子进程在其分支结束处使用了进程终止exit()系统调用而终止执行,则不会再执行分支结束后的程序段。(源代码:forkshare_2.c)
1、运行

2、解释运行结果
子进程因为在分支中输出b后就exit()结束进程了,因此子进程不会输出后面的y,其它与上一节情况相同,不作多解释。
四、进程同步
当父进程有许多任务要做时,往往会针对每一个任务创建一个子进程去完成,然后再等待每一个子进程的终止。其同步关系是父进程等待子进程 (源代码:wait.c)。
实现的方法是:1)子进程终止时执行exit()向父进程发终止信号,2)父进程使用wait()等待子进程的终止。
1、运行
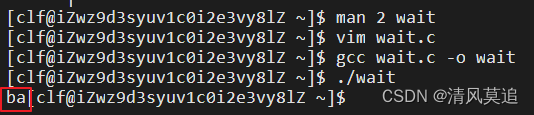
2、解释运行结果
前面三个程序都是父进程输出的 va在前而子进程输出的b在后,这次ba换子进程的输出在前了。
父进程中掉用wait(0)函数会立即阻塞自己,并等待子进程的退出。注意阻塞和空循环等待是有区别的,进程阻塞自己后会交出cpu的控制权。
不过,wait(0)和exit(0)中都有一个0,这个0是什么意思呢?其实这两个零并不是同一个东西,wait的函数头原型是int wait(int *status),参数是一个int类型的指针,wait(0)其实相当于wait(NULL),这个参数为NULL表示我们不关心子进程是如何退出的,只要退出就行。而如果你写成wait(1),那么编译时候就会报错了,因为类型不匹配。
而exit(0)的参数是退出码,你完全可以使用任性地使用exit(123)退出子进程,并在父进程中仍然以wait(0)接收子进程的终止信号。
参考:
- https://zhuanlan.zhihu.com/p/549981187 - 入门篇:进程等待函数wait详解
- https://blog.csdn.net/qustdjx/article/details/7704323 - wait()以及wait(&status)\ waitpid()
- https://zhuanlan.zhihu.com/p/647776823 - Linux Shell 中的各种退出码
- https://www.cnblogs.com/shikamaru/p/5359731.html - exit(0)、exit(1)、和return
五、Linux中子进程映像的重新装入
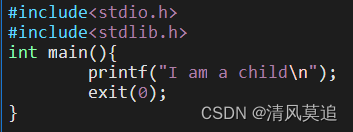
创建一个子进程,并给它加载程序,其功能是显示“I am a child”。设被加载的程序路径名为./child。分析:由于子进程需要加载的程序比较简单,不带参数,所以可以使用execl()实现加载。
1、运行
./child_parent.c:
./child.c:

2、解释运行结果
我在./child_parent.c文件的execl()语句后加了一个printf()语句,这样也行能够更好地体现execl的运行机制。
上述源代码中共有两个printf语句,但最终只有./child.c中的printf语句产生了输出。这是因为,execl加载进程时并不会新建一个进程,而是使用传入路径中的程序覆盖当前进程,并从新进程的main函数开始执行。覆盖后,使用fork()创建的那个程序,当然也包括其中的printf("I am child A\n"),已经不存在了。
使用execl,子进程可以更好地干自己的活,而不只是作为父进程的拷贝。
参考:
- https://blog.csdn.net/bao_bei/article/details/48287945 - Linux下execl函数学习_linux的execl函数
六、线程
Linux 系统下的多线程遵循 POSIX 线程接口,称为 pthread。编写 Linux 下的多线程程式,需要使用头文档 pthread.h,连接时需要使用库 libpthread。顺便说一下,Linux 下pthread 的实现是通过系统调用 clone()来实现的。clone()是 Linux 所特有的系统调用,他的使用方式类似 fork,关于 clone()的周详情况,有兴趣的读者能够去查看有关文档说明。下面我们展示一个最简单的多线程程序 pthread_create.c。
1、运行
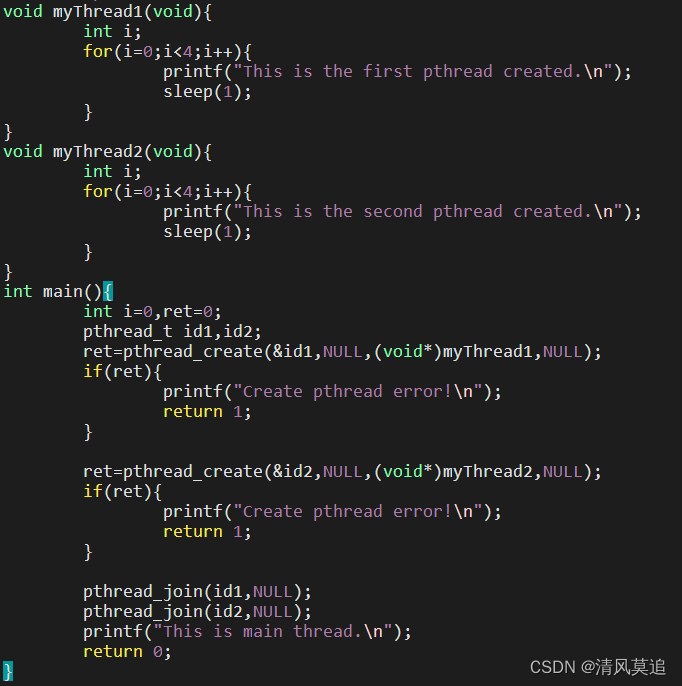
2、解释运行结果
// 线程创建函数的函数头
int pthread_create(pthread_t *thread, pthread_attr_t *attr, void *(*strat_routine)(void *), void *arg)
返回值(int):创建成功时返回0,失败时返回错误码。
参数:
- thread:前面先创建了空的线程标识符
pthread_t id1,这里传入&id1告诉函数要将新建线程的标识符放到哪里。可以对比scanf("%d", &x)的用法。 - attr:线程的属性,传入
NULL表示默认。 - start_routine:线程要执行的函数的指针,上述示例代码中实参前的
(void*)大概是强制类型转换为指针的意思。函数头中那一串void *(*strat_routine)(void *)你可能看着有点晕,感觉自己的C语言功底不太够用了,抱歉我也是。 - arg:线程要执行的函数所需要的参数,传入
NULL意思是不需要参数。
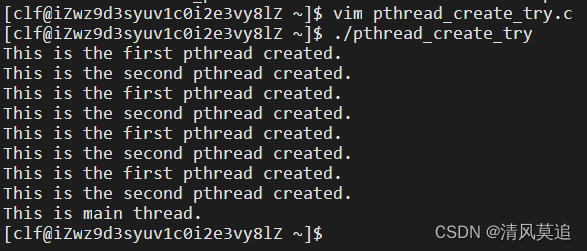
我在main函数return前添加了一个printf语句。
pthread_join的作用是让主线程进入阻塞态,等待子线程运行结束后,主线程再接着运行。否则,从子线程创建时开始,主线程与两个子线程就开始并发执行,当主线程很快运行结束并return后,整个进程也会结束,即子线程跟着结束,都来不及在屏幕上打印信息。
可以看到输出中交替打印两个字符串各四次后,最后打印出来的是This is main thread.。
参考:
- https://blog.csdn.net/sevens_0804/article/details/102823184 - Linux多线程操作pthread_t
- https://www.jb51.net/article/176510.htm - 简单了解C语言中主线程退出对子线程的影响
七、共享资源的互斥访问
创建两个线程来实现对一个数的递加 pthread_example.c
1、运行
例程1:
代码太长,截图不便,我直接贴文本吧。
#include<pthread.h>
#include<stdlib.h>
#include<stdio.h>
#include<sys/time.h>
#include<string.h>
#include<unistd.h>
#define MAX 10
pthread_t thread[2];
pthread_mutex_t mut;
int number=0;
int i;
void thread1(){
printf("thread1: I'm thread 1\n");
for(i=0;i<MAX;i++){
printf("thread1: number=%d\n",number);
pthread_mutex_lock(&mut);
number++;
pthread_mutex_unlock(&mut);
sleep(2);
}
pthread_exit(NULL);
}
void thread2(){
printf("thread2: I'm thread 2\n");
for(i=0;i<MAX;i++){
printf("thread2: number=%d\n",number);
pthread_mutex_lock(&mut);
number++;
pthread_mutex_unlock(&mut);
sleep(3);
}
pthread_exit(NULL);
}
void thread_create(){
int temp;
memset(&thread,0,sizeof(thread));
if( (temp=pthread_create(&thread[0],NULL,(void*)thread1,NULL)) != 0){
printf("create thread1 failed!\n");
}else{
printf("create thread1 success!\n");
}
if( (temp=pthread_create(&thread[1],NULL,(void*)thread2,NULL)) != 0){
printf("create thread2 failed!\n");
}else{
printf("create thread2 success!\n");
}
}
void thread_wait(){
if(thread[0]!=0){
pthread_join(thread[0],NULL);
printf("thread1 end!\n");
}
if(thread[1]!=0){
pthread_join(thread[1],NULL);
printf("thread2 end!\n");
}
}
int main(){
pthread_mutex_init(&mut,NULL);
printf("I am main, I am creating thread!\n");
thread_create();
printf("I am main, I am waiting thread end!\n");
thread_wait();
return 0;
}
2、解释运行结果
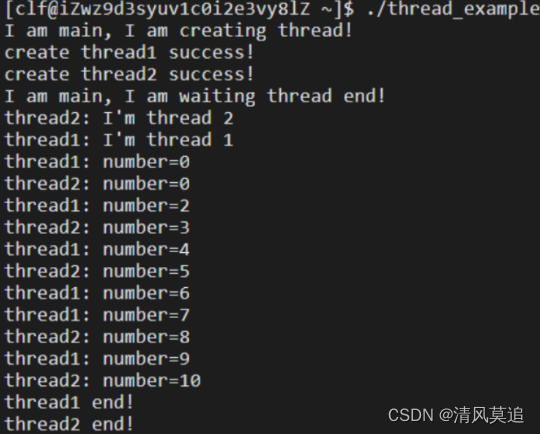
进程是资源分配的基本单位,线程是调度的基本单位。上述代码中,int number和int i都是被两个线程所共享的变量。利用mutex可以实现对共享资源的互斥访问,这个比较容易理解,但是上面的运行结果中,可能有些令人疑惑的地方。
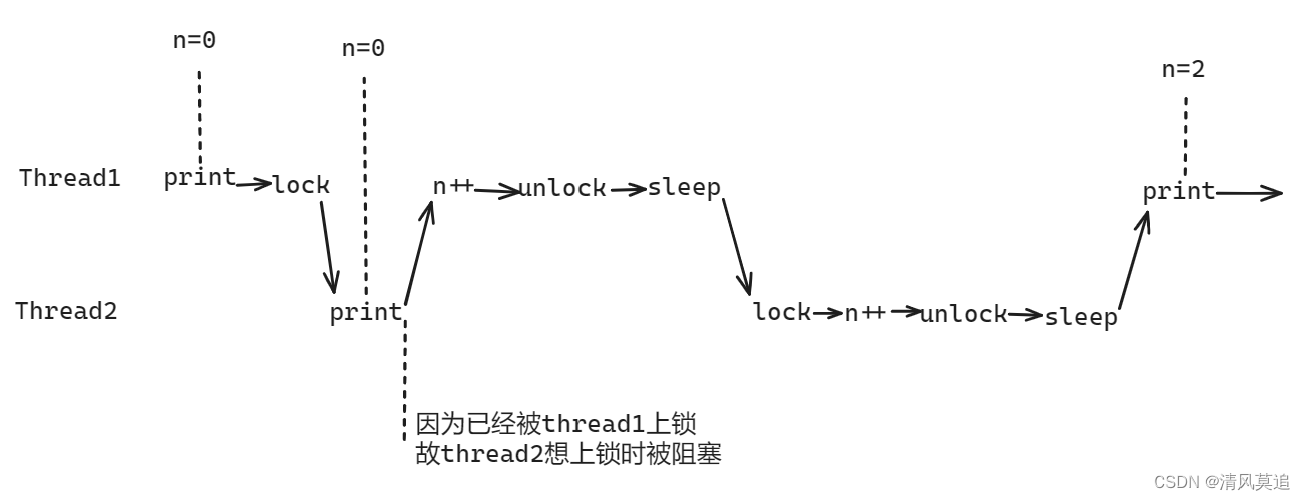
1、为什么会打印两次"number=0",这正常吗?
是正常的,比如在如下图所示的执行顺序(但不唯一)中,就会出现打印两次"number=0"然后打印"number=2"的情况。注意sleep()会直接让当前进程阻塞,因此下图中在sleep处都是拐点。
2、为什么thread1连续输出了两个数"number=6"和"number=7"?
对进程的同步与互斥有些模糊时,容易产生这样的疑问。运行结果中,大部分输出都是thread1和thread2交替的,只有6和7这里是同一个线程连续输出两次,以至于觉得本应该交替输出、而连续输出是异常的。
其实不是,上述thread1的代码中是sleep(2),而thread2的代码中是sleep(3)。如果你将thread1中的sleep(2)修改成sleep(1),可以观察到大部分时候都是thread1在连续输出。总之,代码中只是使用mutex实现了对共享资源的互斥访问而已,并没有实现同步。
3、验证lock与unlock的作用。
到这里,我只知道mutex可以实现对共享资源(全局变量number)的互斥访问,程序也确实看起来正常运行。不过,它只循环了10次呢。而且不知道你有没有发现一个问题,另一个全局变量i,不也同样是thread1和thread2两个线程的共享资源吗?
让我们将总循环次数提到10万吧:#define MAX=100000,同时将阻塞时间缩到sleep(0.001)让它运行得快一点。然后重新编译并运行一下我们的代码:
例程2:
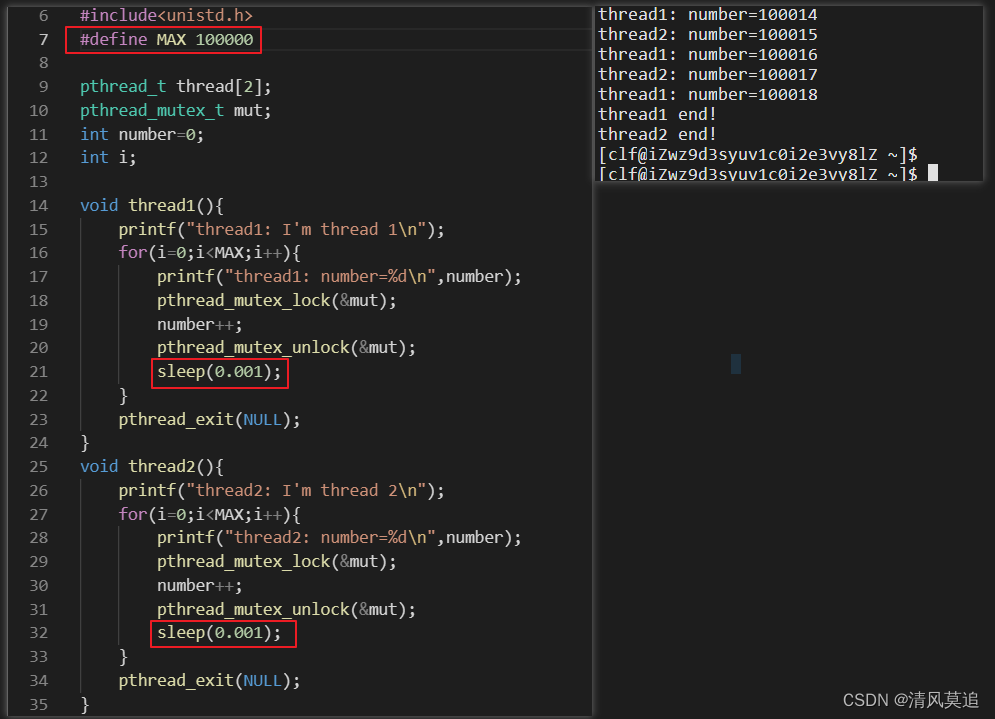
看!最后结果是number=100018,而并不是我们所设置的100000,那么很可能就是由于对于共享变量 i 的访问发生了冲突。我将例程2运行了5次,记录每次最后的number值如下:
100018 100017 100011 100024 100009
为了验证确实是变量 i 导致的问题,而不是其它的什么原因——比如上帝在你的计算机里边掷骰子,我们不妨给 i 也加上互斥。
例程3:
我新增了一个新的用于互斥的变量mut_i,并在两个线程函数的循环中都改用lock和unlock来保护记录循环迭代的i++语句。
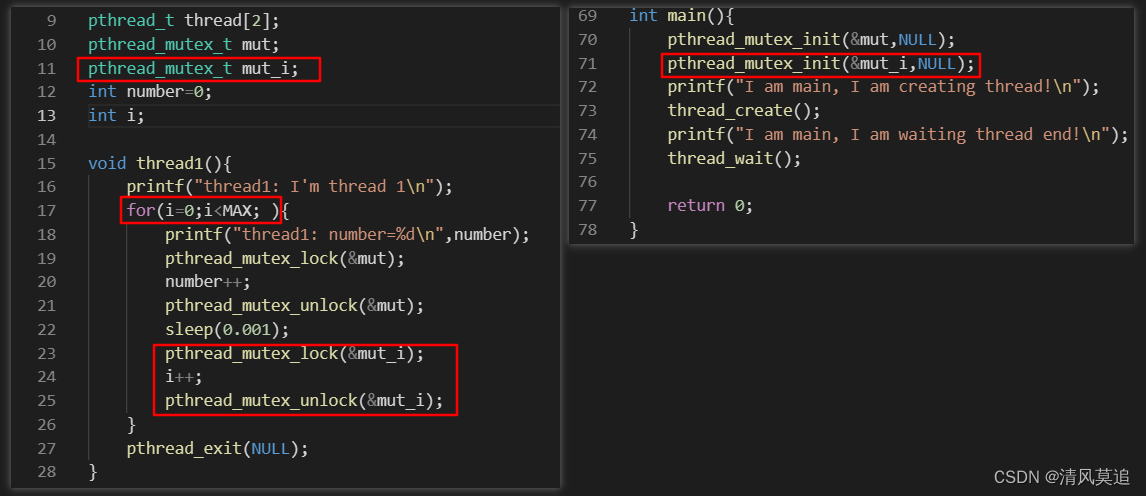
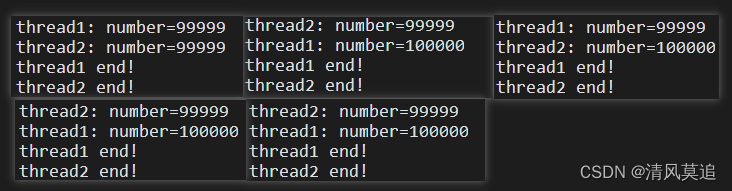
我同样将这个修改后的例程3运行了5次,其中有四次是正确的结果number=100000。可很遗憾,我也不知道在第一次运行中为什么会出现连续两个number=99999,不过我觉得这不一定是资源互斥中所导致的问题。
总之,凡有赋值的操作在多线程环境都要加锁,不论是上述的number++,还是i++。因为,它们都不是原子操作,从机器指令的层面来看,一个高级语言中的i++包含多个步骤,而一条语句还没执行完,可能就已经发生中断,转而去执行另一个线程了。
4、在例程2和例程3的执行结果中,每次最终的number值都是偏大,为什么不会偏小呢?
例程4:
下面我解除了对于变量 number 的互斥保护,而保持对 i 的互斥保护。
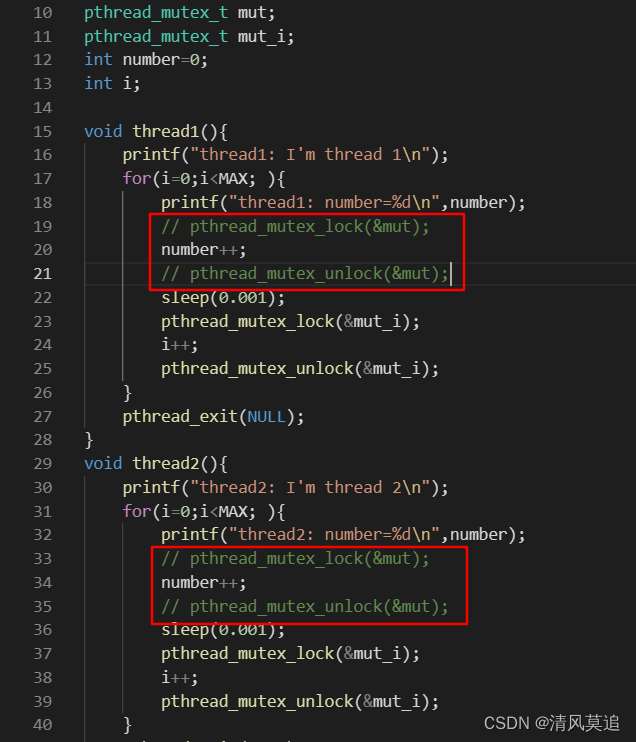
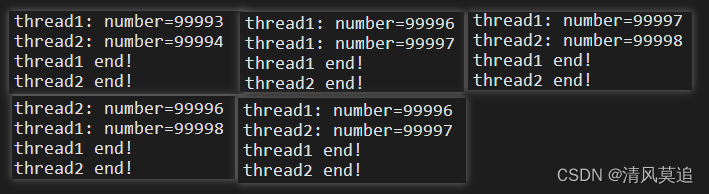
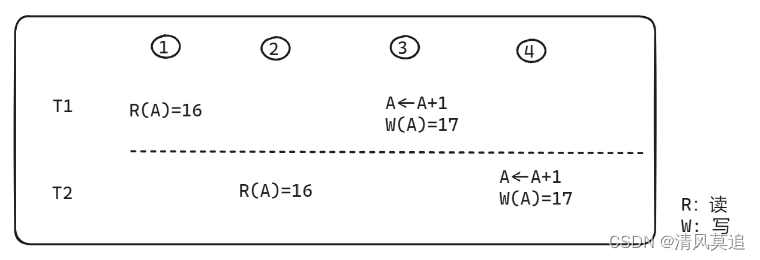
可以看到我连续运行五次结果中,number 每次都是比10万要偏小。这个具体的细节,其实回忆一下以前数据库并发控制中丢失修改导致的数据不一致问题,就明白了,情况如下图所示。而当 i 偏小的时候,i 的递增次数就小于实际迭代次数,于是导致了 number 的结果偏大。
参考:
- https://blog.csdn.net/JMW1407/article/details/108318960 - int i =1 是原子操作吗?i++是原子操作吗?