-
第1节 指针的基本概念
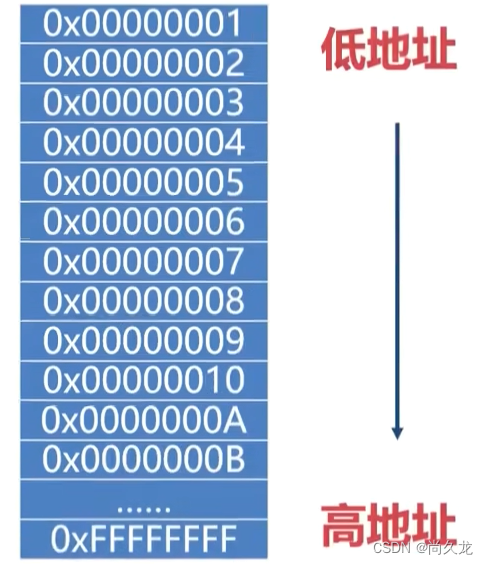
0x01、变量的地址:
变量是内存地址的简称,在C++中,每定义一个变量,系统就会给变量分配一块内存,内存是有地址的。
C++用运算符&获取变量在内存中的起始地址。
语法: &变量名
0x02、指针变量:
指针变量简称指针,他是一种特殊的变量,专用于存放变量在内存中的起始地址。
语法: 数据类型 *变量名;数据类型必须是合法的C++数据类型(int,char,double或其他自定义的数据类型)。
星号*与乘法中的星号是相同的,但是,在这个场景中,星号用于表示这个变量是指针。
0x03、对指针赋值
不管是整型、浮点型、字符型,还是其他的数据类型的变量,他的地址都是一个十六进制数。我们用整型指针存放整数类型变量的地址;
用字符型指针存放字符型变量的地址;用浮点型指针存放浮点型变量的地址。
语法: 指针=&变量名;
0x04、指针占用的内存
指针也是变量,是变量就要占用内存空间。
在64位系统中,不管什么类型的指针,占用的内存都是8字节。注意:
对指针的赋值操作也通俗的呗称为“指向某变量”,被指向的变量的数据类型称为“基类型”。
如果指针的数据类型与基类型不符,编译会出现警告。但是,可以强制转换他们的类型。在C++中,指针是复合数据类型,复合数据类型是指基于其他类型而定义的数据类型,在程序中,int是整型类型,int * 是整型指针类型,
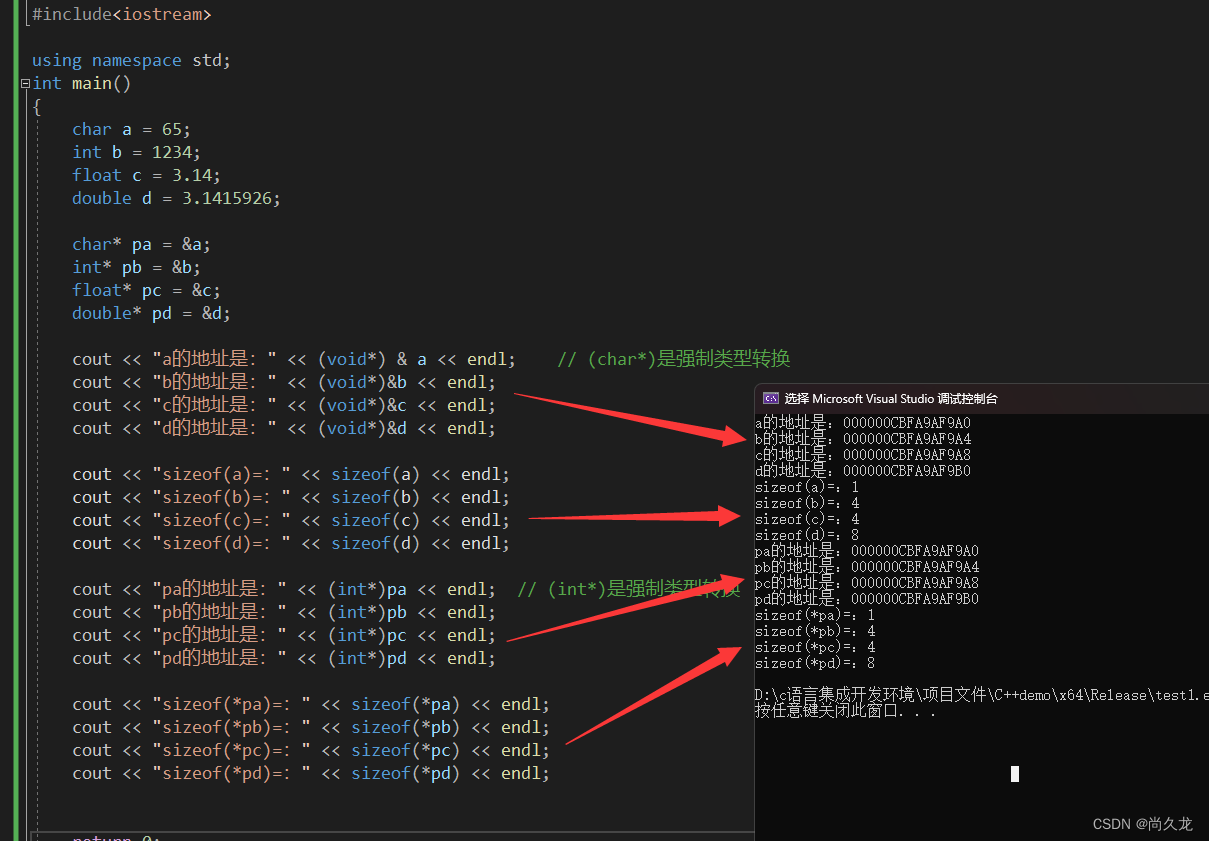
int * 可以用于声明变量,可以用于sizeof运算符,可以用于数据类型的强制转换,总的来说,把int * 当成一种数据类型就是了。#include<stdio.h> #include<iostream> using namespace std; int main() { char a = 65; int b = 1234; float c = 3.14; double d = 3.1415926; char* pa = &a; int* pb = &b; float* pc = &c; double* pd = &d; cout << "a的地址是:" << (void*) & a << endl; // (char*)是强制类型转换 cout << "b的地址是:" << (void*)&b << endl; cout << "c的地址是:" << (void*)&c << endl; cout << "d的地址是:" << (void*)&d << endl; cout << "sizeof(a)=:" << sizeof(a) << endl; cout << "sizeof(b)=:" << sizeof(b) << endl; cout << "sizeof(c)=:" << sizeof(c) << endl; cout << "sizeof(d)=:" << sizeof(d) << endl; cout << "pa的地址是:" << (int*)pa << endl; // (int*)是强制类型转换 cout << "pb的地址是:" << (int*)pb << endl; cout << "pc的地址是:" << (int*)pc << endl; cout << "pd的地址是:" << (int*)pd << endl; cout << "sizeof(*pa)=:" << sizeof(*pa) << endl; cout << "sizeof(*pb)=:" << sizeof(*pb) << endl; cout << "sizeof(*pc)=:" << sizeof(*pc) << endl; cout << "sizeof(*pd)=:" << sizeof(*pd) << endl; return 0; }
-
第2节 使用指针
声明指针变量后,在没有赋值之前,里面是乱七八糟的值,这时候不能使用指针。
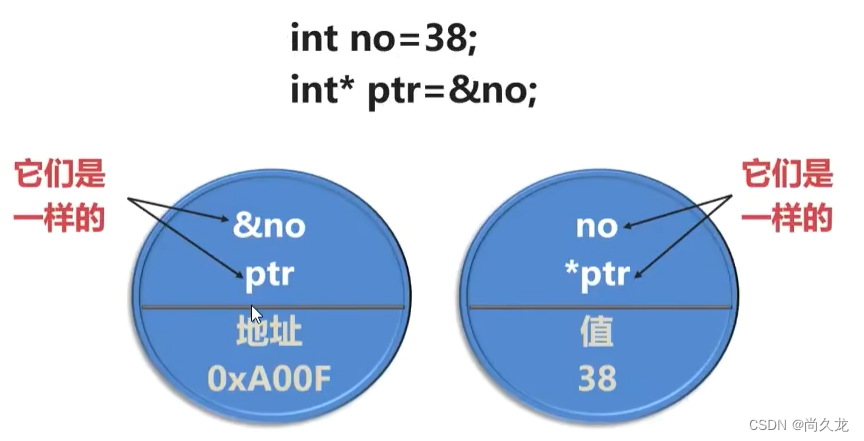
指针存放变量的地址,因此,指针名表示的是地址(就像变量名可以表示变量一样)
*运算符被称为间接值或解除引用(解引用)运算符,将它用于指针,可以得到该地址的内存中存储的值,*也是乘法符号,C++根据上下文来确定所指的是乘法还是解引用。
变量和指向变量的指针就像同一枚硬币的两面。
#include<iostream> using namespace std; int main() { int a = 8; int* pa = &a; cout << "a=" << a << endl; cout << "*pa=" << *pa << endl; *pa = 9; cout << "a=" << a << endl; cout << "*pa=" << *pa << endl; a = 12; cout << "a=" << a << endl; cout << "*pa=" << *pa << endl; return 0; }

-
第3节 指针用于函数的参数
如果把函数的形参声明为指针,调用的时候把实参的地址传进去,形参中存放的是实参的地址,在函数中通过解引用的方法直接操作内存中的数据,
可以修改实数的值,这种方法被通俗的称为地址传递或传地址。
值传递:函数的形参是普通变量。
传地址的意义:
可以在函数中修改实参的值。
减少内存拷贝,提升性能。#include<iostream> using namespace std; void bijiao(int a, int b, int *max, int* min); int main() { int a = 5, b = 9, max = 0, min = 0; bijiao(a, b, &max, &min); cout << "max=" << max << "\nmin=" << min << endl; return 0; } void bijiao(int a, int b, int* max, int* min) { *max = a > b ? a : b; *min = a < b ? a : b; }

-
第4节 用const修饰指针
0x01、常量指针
语法:const 数据类型 * 变量名;
不能通过解引用的方法修改内存地址中的值(用原始的变量名是可以修改的)。注意:
指向的变量(对象)可以改变(之前是指向变量a的,后来可以改为指向变量b)。
一般用于修饰函数的形参,表示不希望在函数里修改内存地址中的值。
如果用于形参,虽然指向的对象可以改变,但这么做没有任何意义。
如果形参的值不需要改变,建议加上const修饰,程序可读性更好。0x02、指针常量
语法:数据类型 * const 变量名
指向的变量(对象)不可改变。注意:
在定义的同时必须初始化,否则没有意义。
可以通过解引用的方法修改内存地址中的值。0x03、常指针常量
语法:const 数据类型 * const 变量名
指向的变量(对象)不可改变,不能通过解引用的方法修改内存地址中的值。
常引用。常量指针:指针可以改,指针指向的值不可以更改。
指针常量:指针指向不可以改,指针指向的值可以更改。
常指针常量:指针指向不可以改,指针指向的值不可以更改。记忆秘诀:*表示指针,指针在前先读指针;指针在前指针就不允许改变。
常量指针:const 数据类型 * 变量名
指针常量:数据类型 * const 变量名#include<iostream> using namespace std; int main() { int a = 3, b = 8; //常量指针 const int* p = &a; //*p = 6; 不能通过解引用的方法修改内存地址中的值(用原始的变量名是可以修改的)。 a = 6; cout << "a=" << a << endl; p = &b; cout << "b=" << b << endl; //指针常量 int* const p2 = &a; *p2 = 7; cout << "a=" << a << endl; //*p2 = &b; 指向的变量(对象)不可改变 cout << "b=" << b << endl; //常指针常量 const int* const p3 = &a; //*p3 = 4; 指针指向的值不可以更改 //p3 = &b; 指针指向不可以改 }

-
第5节 void 关键字
在C++中,void表示为无类型,主要有三个用途:
函数的返回值用void,表示函数没有返回值。
void func(int a,int b)
{
//函数体代码
return;
}函数的参数填void,表示函数不需要参数(或者让参数列表空着)。
int func(void)
{
//函数体代码。
return 0;
}函数的形参用void*,表示接受任意数据类型的指针。
注意:
不能用void声明变量,他不能代表一个真实的变量。
不能对void*指针直接解引用(需要转换成其他类型的指针)。
把其他类型的指针赋值给void*指针不需要转换。
把void*指针赋值给把其他类型的指针需要转换。#include<iostream> using namespace std; void fun(string name, void* p) { cout << name << "的地址是:" << p << endl; cout << name << "的值是:" << *(char *)p << endl; // char*强制类型转换,只能解引用char类型的值,想解引用a的值就要int*强制转换 cout << name << "的值是:" << *(int *)p << endl; } int main() { int a = 8; char b = 'X'; cout << "a的地址是:" << &a << endl; cout << "b的地址是:" << &b << endl; cout << "b的地址是:" << (void *) & b << endl; // 这样就能正确显示地址了 //下面调用函数 fun("a", &a); fun("b", &b); fun("B", &b); return 0; }

-
第6节 C++内存模型
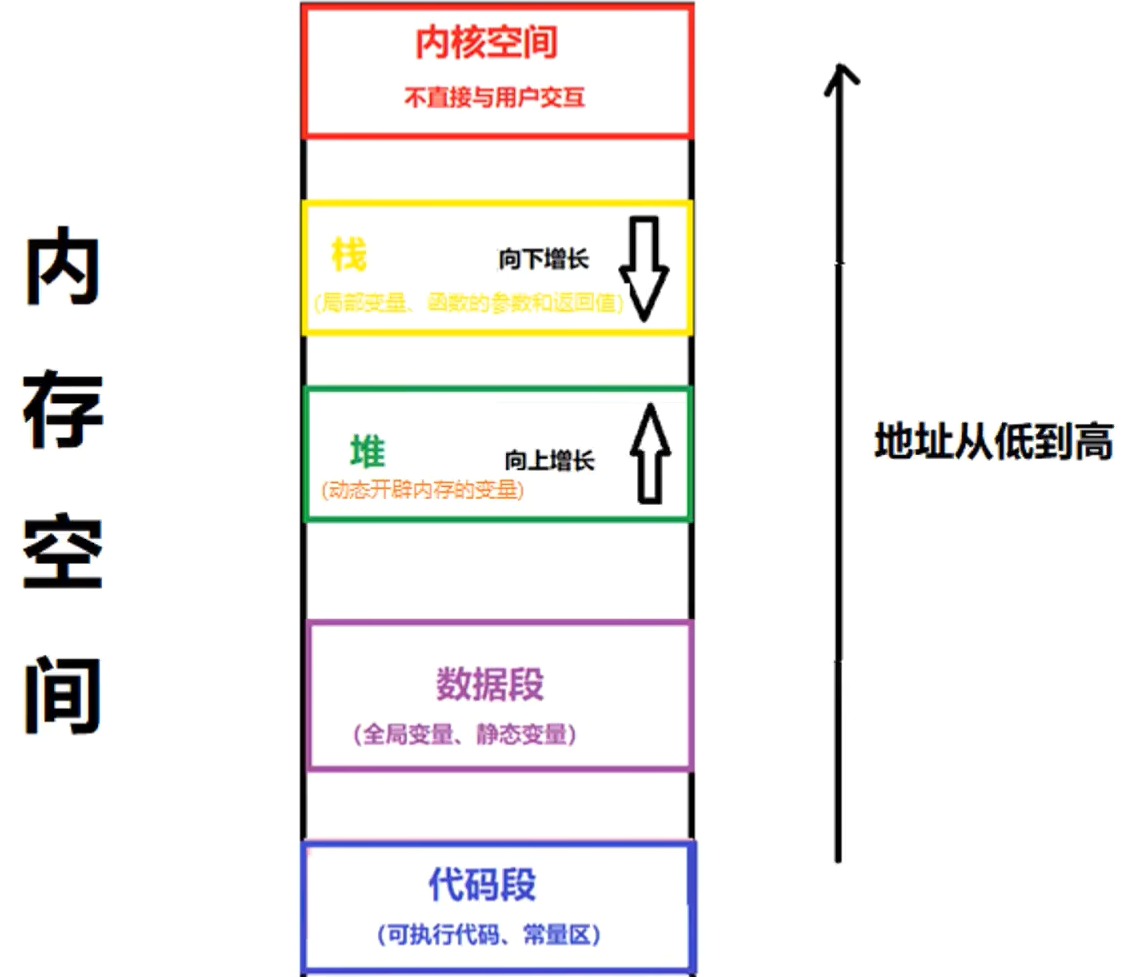
栈和堆的主要区别:
1、管理方式不同:栈是系统自动管理的,在出作用域时,将自动释放;堆需手动释放,若程序中不释放,程序结束时由操作系统回收。
2、空间大小不同:堆内存的大小受限于物理内存空间;而栈就小的可怜,一般只有8M(可以修改系统参数)
3、分配方式不同:堆是动态分配;栈有静态分配和动态分配(都是自动释放)。
4、分配效率不同:栈是系统提供的数据结构,计算机在底层提供了对栈的支持,进栈和出栈有专门的指令,效率比较高;堆是由C++函数库提供的。
5、是否产生碎片:对于栈来说,进栈和出栈都有严格的顺序(先进后出),不会产生碎片;而堆频繁的分配和释放,会造成内存空间的不连续,容易产生碎片,
太多的碎片会导致性能的下降。
6、增长方式不同:栈向下增长,以降序分配内存地址;堆向上增长,以升序分配内存地址。
-
第7节 动态分配内存new和delete
使用堆内存有四个步骤
1、声明一个指针;
2、用new运算符向系统申请一块内存,让指针指向这块内存;
3、通过对指针解引用的方法,向使用变量一样使用这块内存;
4;如果这块内存不用了,用delete运算符释放他;申请内存的语法:new 数据类型(初始值);//c++11支持{}
如果申请成功,返回一个地址,如果申请失败,返回一个空地址(暂时不考虑失败的情况)。
释放内存的语法: delete 地址;
释放内存不会失败(还钱不会失败)。注意:
动态分配出来的内存,没有变量名,只能通过指向他的指针来操作内存中的数据。
如果动态分配的内存不用了,必须用delete释放他,否则有可能用尽系统的内存。
动态分配的内存声明周期与程序相同,程序退出时,如果没有释放,系统将自动回收。
就算指针的作用域已失效,所指向的内存也不会释放。
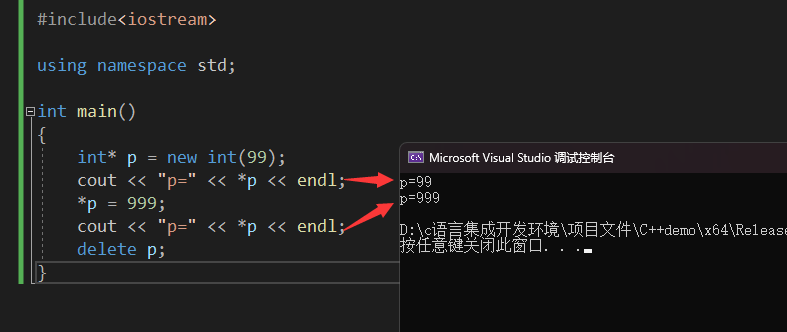
用指针跟随已分配的内存时,不能跟丢。#include<iostream> using namespace std; int main() { int* p = new int(99); cout << "p=" << *p << endl; *p = 999; cout << "p=" << *p << endl; delete p; }
-
第8节 二级指针
指针是指针变量的简称,也是变量,是变量就有地址。
指针用于存放普通变量的地址。
二级指针用于存放指针变量的地址。
声明二级指针的语法:
数据类型 ** 指针名;
使用指针有两个目的:
1、传递地址;
2、存放动态分配的内存的地址。
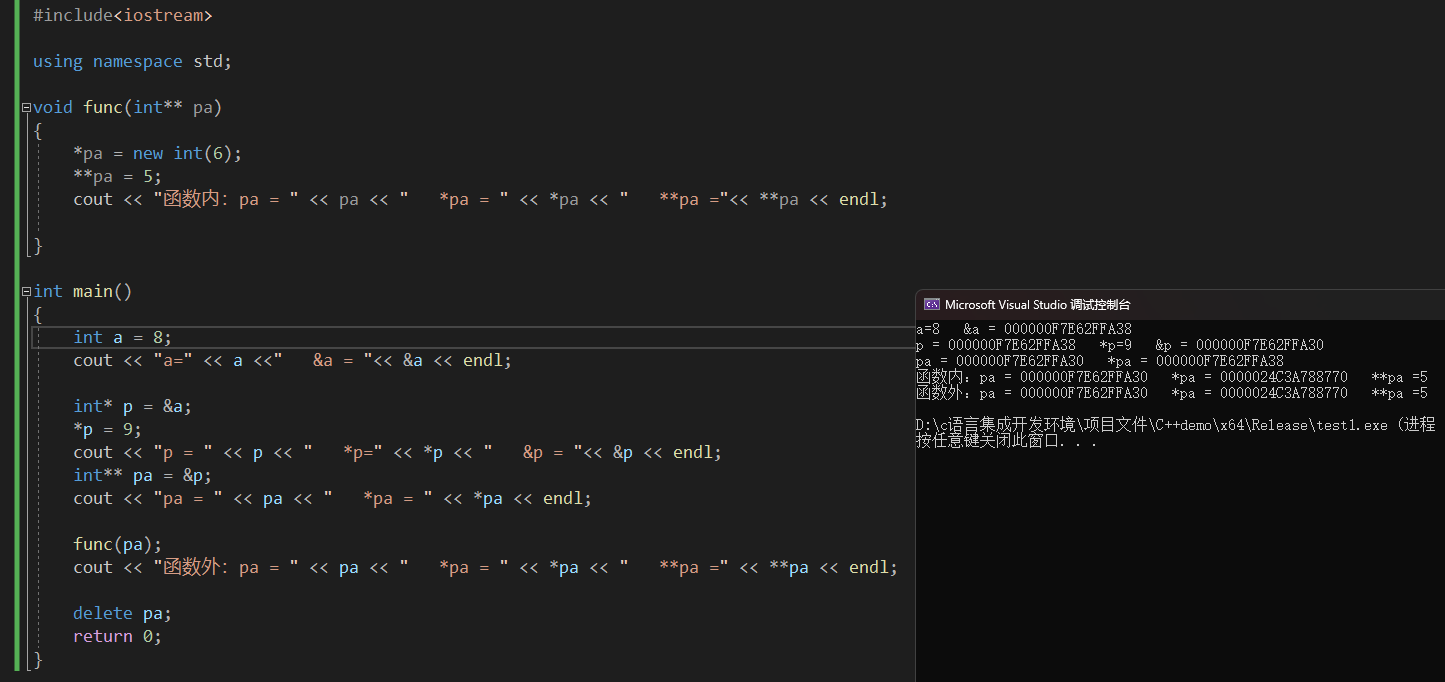
在函数中,如果传递普通变量的地址,形参用指针;传递指针的地址的地址,形参用二级指针。#include<iostream> using namespace std; void func(int** pa) { *pa = new int(6); **pa = 5; cout << "函数内:pa = " << pa << " *pa = " << *pa << " **pa ="<< **pa << endl; } int main() { int a = 8; cout << "a=" << a <<" &a = "<< &a << endl; int* p = &a; *p = 9; cout << "p = " << p << " *p=" << *p << " &p = "<< &p << endl; int** pa = &p; cout << "pa = " << pa << " *pa = " << *pa << endl; func(pa); cout << "函数外:pa = " << pa << " *pa = " << *pa << " **pa =" << **pa << endl; delete pa; return 0; }
-
第9节 空指针
在C和C++中,用0或NULL都可以表示空指针。
声明指针后,在赋值之前,让他指向空,表示没有指向任何地址。1、使用空指针的后果
如果对空指针解引用,程序会崩溃。
如果对空指针使用delete运算符,系统将忽略该操作,不会出现异常。所以内存释放后,也应该把指针指向空。
在函数中,应该有判断形参是否为空指针的代码,目的是保证程序的健壮性。为什么在空指针访问会出现异常?
NULL指针分配的分区:其范围是从0x00000000到0x0000FFFF。这段空间是空闲的,对于空闲的空间而言,没有相应的物理存储器与之相对应,所以对这段空间来说,
任何写操作都是会引起异常的。空指针是程序无论在何时都没有物理存储器与之对应的地址。为了保证无论何时这个条件,需要人为划分一个空指针的区域,固有上面
NULL指针分区。2、用0和NULL表示空指针会产生歧义,C++11建议用nullptr表示空指针,(void*)0.
NULL在C++中就是0,这是因为C++中void*类型是不允许隐式转换成其他类型的,所以之前C++中用0来代表空指针,但是在重载整型的情况下,会出现上述的问题。所以
C++11加入了nullptr,可以保证在任何情况下都代表空指针,而不会出现上述的情况,因此,建议用nullptr代替NULL吧,而NULL就当做0使用。注意:在Linux平台下,如果使用nullptr,编译时需要加-std=c++11参数。
#include<iostream> using namespace std; int main() { int* p = 0; cout << "p=" << p << " *p=" << *p << endl; // 会在* p 解引用的时候,程序意外退出。 return 0; }

-
第10节 野指针
野指针就是指针指向的不是一个有效(合法)的地址。
在程序中,如果访问野指针,可能会造成程序的崩溃。
出现野指针的情况主要有三种:
1、指针在定义的时候,如果没有进行初始化,他的值是不确定的(乱指一气)。
2、如果用指针指向了动态分配的内存,内存被释放后,指针不会置空,但是,指向的地址已失效。
3、指针指向的变量已超越变量作用域(变量的内存空间已被系统回收)。
规避方法:
1、指针在定义的时候,如果没有地方指,就初始化为nullptr。
2、动态分配的内存被释放后,将其置为nullptr。
3、函数不要反回局部变量的地址。
注意:野指针的危害比空指针要大很多,在程序中,如果访问野指针,可能会造成程序的崩溃。是可能,不是一定,
程序的表现是不稳定,增加了调试程序的难度。
#include<iostream> using namespace std; int main() { int* p = new int{ 8 }; cout << "p = " << p << "*p= " << *p << endl; delete p; p = nullptr; cout << "p = " << p << "*p= " << *p << endl; return 0; }

-
第11节 函数指针和回调函数
函数的二进制代码内存四区中的代码段,函数的地址它在内存中的开始地址。
如果把函数的地址作为参数,就可以在函数中灵活的调用其他函数。使用函数指针的三个步骤:
a、声明函数指针;
声明普通指针时,必须提供指针的类型。同样声明函数指针时,也必须提供函数类型,函数的类型是指返回值和参数列表(函数名和形参名不是);
函数指针的声明是: 类型(*函数指针名称)(参数类型1,参数类型2)
int(*p)(int,int,n)b、让函数指针指向函数的地址;
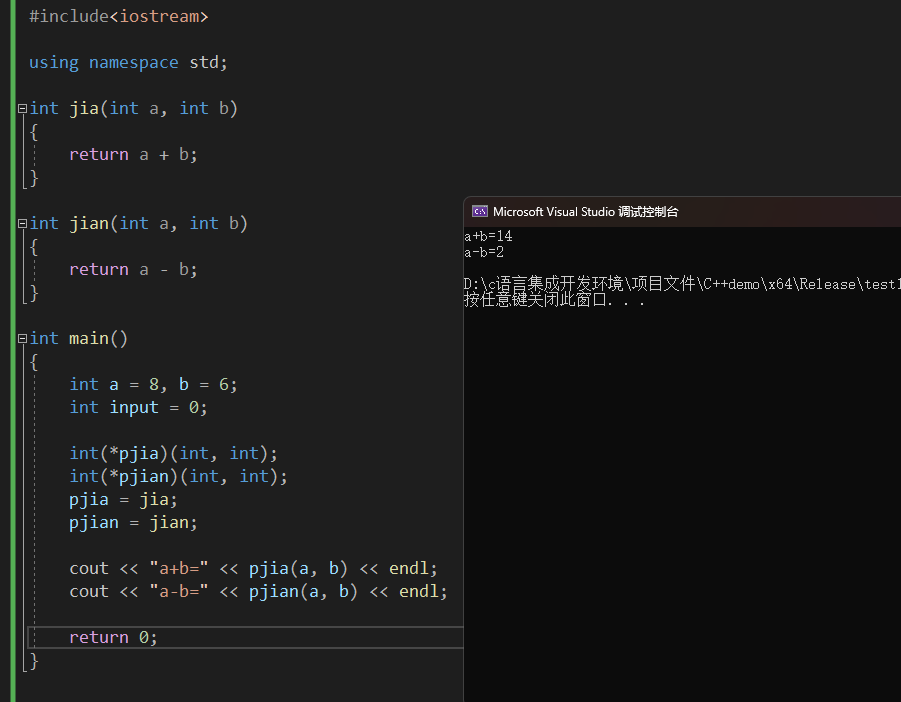
c、通过函数指针调用函数;#include<iostream> using namespace std; int jia(int a, int b) { return a + b; } int jian(int a, int b) { return a - b; } int main() { int a = 8, b = 6; int input = 0; int(*pjia)(int, int); int(*pjian)(int, int); pjia = jia; pjian = jian; cout << "a+b=" << pjia(a, b) << endl; cout << "a-b=" << pjian(a, b) << endl; return 0; }
-
第12节 一维数组的基本概念
1、数组的基本概念
定义:数组是一组数据类型相同的变量,可以存放一组数据。
声明数组的语法: 数据类型 数组名[数组长度];
注意: 数组长度必须是整数,可以是常量,也可以是变量和表达式。C90规定必须用常量表达式知名数组的大小,C99允许使用整型非常量表达式。经测试,在VS中
可以用整型非常量表达式,不能用变量;但是,Linux中还可以用变量。2、数组的使用:
可以通过下标访问数组中的元素,数组下标从0开始。
数组中每个元素的特征和使用方法与单个变量完全相同。
语法:数组名[数组下标]
注意:
数组下标也必须是整数,可以是常量,也可以是变量。
合法的数组下标取值是:0~(数组长度-1)。3、数组占用内存的情况
数组在内存中占用的空间是连续的。
用sizeof(数组名)可以得到整个数组占用内存空间的大小(只适用于C++基本数据类型)。4、数组的初始化
声明的时候初始化:
数组类型 数组名[数组长度] = {值1,值2......}
数据类型 数组名[] = {值1,值2......}
数组类型 数组名[数组长度] = {0}; //把全部元素初始化为0
数组类型 数组名[数组长度] = {}; //把全部元素初始化为0
注意:
如果{}内不足数组长度个数据,剩余数据用0补全,但是,不建议这么用,你可能在数组中漏了某个值。
如果想把数组中全部的元素初始化为0,可以在{}内只填一个0或什么也不填。
C++11标准可以不写等于号。
5、清空数组
用menset()函数可以把数组中全部的元素清0.(只使用于C++基本数据类型)
函数原型: void *menmset(void* s,int C,size_t n);
注意,在Linux下,使用memcpy函数需要包含头文件#include<string.h>
6、复制数组
用memcpy()函数可以把数组中全部的元素复制到另一个相同大小的数组。(只使用于C++基本数据类型)
函数原型:void * menmcpy(void *dest, const void* src,size_t n);
注意,在Linux下,使用memcpy()函数需要包含头文件#include<string.h>#include<iostream> using namespace std; void print(int arr[], int len) { for (int i = 0; i < len; i++) { cout << "------------------------------------------"<<endl; cout << "arr[" << i << "]=" << arr[i] << endl; cout << "取地址arr[" << i << "]=" << &arr[i] << endl; } } int main() { int arr[3] = { 1,2,3}; print(arr, 3); memset(arr, 0, sizeof(arr)); //清空数组 最后一个参数最好用sizeof()查询字节数,要么输入数组的字节数,否则失败 print(arr, 3); return 0; }

-
第13节 一维数组和指针
1、指针的算术
将一个整型变量加1后,其值将增加1.
但是,将指针变量(地址的值)加1后,增加的量等于它指向的数据类型的字节数。
2、数组的地址
a、数组在内存中占用的空间是连续的。
b、C++将数组名解释为数组第0个元素的地址。
c、数组第0个元素的地址和数组首地址的取值是相同的。
d、数组第n个元素的地址是:数组首地址+n
e、C++编译器把 数组名[下标] 解释为 *(数组首地址 + 下标)3、数组的本质
数组是占用连续空间的一块内存,数组名解释为数组第0个元素的地址。C++操作这块内存有两种方法:
数组解释法和指针法,他们是等价的。4、数组名不一定会被解释为地址
在多数情况下,c++将数组名解释为数组的第0个元素的地址,但是,将sizeof运算符用于数据名时,
将返回真个数组占用内存空间的字节数。
可以修改指针的值,但数组名是常量,不可以改。
-
第14节 一维数组用作函数的参数
1、指针的数组表示
在C++内部,用指针来处理数组
C++编译器把 数组名[下标] 解释为 *(数组首地址+下标)
C++编译器把 地址[下标] 解释为 *(地址+下标)2、一维数组用于函数的参数
一维数组用于函数的参数时,只能传数组的地址,并且把数组长度也传进去,除非数组中有最后一个元素的标志。
书写方法有两种:
void func(int * arr, int len);
void func(int arr[], int len);
注意:
在函数中,可以用数组表示法,也可以用指针表示法。
在函数中,不要对指针用sizeof运算符,它不是数组名。
在其用int*arr替换了int arr[]。这证明两个函数头都是正确的,因为在C++中,当(且仅当)
用于函数头或函数原型中,int*arr 和 int arr[] 的含义才是相同的。他们都意味着arr是一个int
指针。然而,数组表示法(int arr[])提醒用户,arr不仅指向int,还指向int数组的第一个int。
当指针指向数组的第一个元素时,本书使用数组表示法;当指针指向一个独立的值时,使用指针表示
法。别忘了,在其他的上下文中,int*arr 和 int arr[] 的含义并不相同。例如,不能在函数体中
使用int tip[]来声明指针。#include<iostream> using namespace std; void func(int* p, int len, int a[]) { cout << "这是在函数里面:" << endl; cout << "sizeof(a)="<<sizeof(a) << endl; for(int i=0;i<len;i++) { cout << "a[" << i << "]的地址是:" << &a[i] << "值是:" << a[i] << endl; cout << "p[" << i << "]的地址是:" << p + i << "值是:" << *(p + i) << endl; } } int main() { int a[] = { 8,9,2,5,7,3,6 }; int* p = a; for (int i = 0; i < sizeof(a) / sizeof(a[0]); i++) { cout << "a[" << i << "]的地址是:" << &a[i] << "值是:" << a[i] << endl; cout << "p[" << i << "]的地址是:" << p+i << "值是:" << *(p+i) << endl; } cout << "下面是把数组a的第2个元素的地址赋值给p2,结果会不同p2从下标为2的元素开始,a还是从0开始" << endl; int * p2 = &a[2]; for (int i = 0; i < 5; i++) { cout << "a[" << i << "]的地址是:" << &a[i] << "值是:" << a[i] << endl; cout << "p2[" << i << "]的地址是:" << p2 + i << "值是:" << *(p2 + i) << endl; } cout << "这是在函数外面:" << endl; cout << "sizeof(a)=" << sizeof(a) << endl; func(p, sizeof(a) / sizeof(a[0]), a); }
