收藏关注不迷路
文章目录
摘要
近年来,随着网络技术的发展,在线音乐平台成为人们听歌曲的首选。面对海量的音乐数据,用户们往往显得无从选择。听歌作为日常的娱乐放松方式,一首首的试听明显不太现实,所以需要进行一定程度的筛选。本论文根据此需求,设计并实现了一个音乐推荐系统。该系统是基于Spring Boot框架,运用到Hadoop平台中HDFS进行存储,Map Reduce进行计算。该系统前端由首页管理、歌曲歌手管理及个人信息管理等主要功能模块构成,能够满足用户想要的歌单推荐和歌曲推荐。本文首先对音乐推荐系统的发展现状和相关理论进行了介绍,然后对推荐系统进行了分析与研究,使用了基于协同过滤的推荐算法;接下来详细介绍了系统模块的具体功能和实现步骤;最后测试了音乐推荐系统,系统各功能都能够正确执行并达到预期效果。
关键词:Hadoop;推荐系统;音乐推荐;协同过滤
一、 相关技术和基本理论
2.1相关技术
2.1.1Hadoop集群
Hadoop是Apache基金会旗下一套开源的软件产品。可以为用户提供可靠稳定的分布式计算服务。一个Hadoop集群主要有三个模块:MapReduce,hdfs,yarn。它不同于其他计算机程序,Hadoop提供一套成熟的高可用处理方案,它可以自己检测并处理失败的案例来保证程序的正常运行。它还具备有成熟的生态圈,而且集群负载均衡。图2-1为Hadoop的框架示意图:
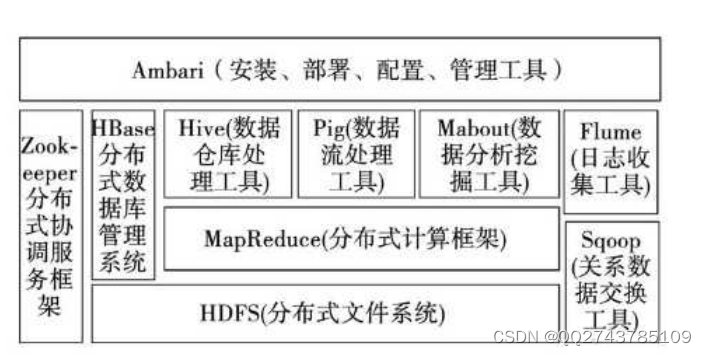
图2-1Hadoop框架示意图
其中HDFS是一个分布式文件系统,作用就是存放数据。而Map Reduce是一个编程框架,就是为海量的数据提供计算[3]。HDFS的显著特点是具有高容错性,而且它提供访问应用程序数据的高吞吐量,适用于数据集非常大的应用程序,集群会把很大的文件拆分成多个小文件,然后存放在不同的节点上。但是HDFS适合一次写入,多次读取的情形。Map Reduce,它的主要思想是分而治之。分为两个阶段,Map也叫映射,它的作用就是把一个复杂的任务分解成若干个小的任务;Reduce被称为规约,在此阶段就是完成数据的聚合。在这个过程中,任务调度、负载均衡、容错处理等问题均由Map Reduce框架完成。但是它不能像mysql一样很快的返回结果,即不擅长实时计算。图2-2为MapReduce的示意图:
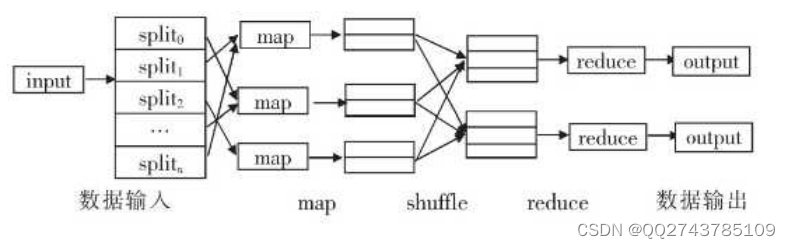
图2-2MapReduce示意图
2.1.2Spring Boot框架
Spring Boot是Pivotal公司在2014年开发的开源Java框架,它的出现大大的简化了部署Java企业级Web应用程序的难度。这是一个在Spring框架之上构建的框架,它提供了一种有效的方法来设置和运行应用程序。它的优点是使编码变得容易,而且配置也相对简单很多,因为它提供很多默认配置。如果需要自定义配置,只需对默认值进行修改即可,不需要配置xml,开箱即用。作为一个一站式的开发环境,方便开发者快速构建一个企业级应用,而且开发效率较高,部署简单。使用maven配置来导入相应的jar包,不需要手动导入[4]。而且相比于普通的spring框架开发,spring boot框架的开发效率是其数倍。对于各种关系以及非关系数据库都能很好地兼容。
2.1.3Vue框架
随着互联网的发展,现在我们的网页变得更加强大和动态化。网页中提供的信息,包含的内容都增加了很多,而且更加注重美观性。本文使用的Vue是一款好的、功能多样的JavaScript框架,允许一个网页分割成可复用的组件,每个组件包含自己的风格。它也可以实现前后端的分离,节约开发成本。它的架构更简单,人们可以快速学习,并且投入使用。它的核心是响应式原理,它具有以下优点:
(1)Vue的学习成本相比较其他框架较低,简单易学。
(2)Vue模板中的指令、过滤器等,使得开发者对DOM的操作非常方便。
(3)对于逻辑交互复杂的前端应用,Vue可以提供基础的架构抽象,同时还可以保证前端良好的用户交互。
2.2开发环境和技术框架
2.2.1技术框架
核心框架:Spring Boot
视图框架:Spring MVC
JS框架:VUE
2.2.2开发环境
IDE:IDEA2019.3.3
数据库:Mysql5.5
JDK:Java8
Jar包管理工具:Maven4.0.0
操作系统:Windows
2.3推荐系统
推荐系统是一项工程技术解决方案,是一种为用户提供感兴趣信息的一个便捷渠道,它的目的就是适当解决信息过载的问题。下面主要介绍与其相关的理论和技术[5]。
协同过滤算法是一种比较知名和常用的推荐算法,它的主要功能是预测和推荐。通过挖掘用户历史行为数据发现用户的喜好,基于不同的偏好对用户进行划分并推荐相似的商品。分为基于用户的协同过滤和基于物品的协同过滤。其中,基于物品的协同过滤算法主要分为两步,首先根据用户对不同物品的评分来获取物品间的关系,之后基于物品之间的关系对用户进行相似物品的推荐。
基于用户的协同过滤算法是通过用户的历史行为数据,如购买物品、收藏或者音乐点赞等,发现用户对商品内容的喜欢。通过分析这些行为,找到相似兴趣度的用户群体,然后在具有相同喜好的用户之间进行推荐。就本文而言,算法的步骤如下:首先收集用户对音乐的各种操作,记录用户的历史行为;之后对所选用户评分、收藏等数据进行处理,生成用户-评分矩阵,评分可以视为一个数值,不同数值代表推荐用户的不同偏好;其次就是用户间相似度的计算,计算方法主要包括余弦相似性、相关性相似性和修正的余弦相似性等;在本项目中最后使用协同过滤算法创建音乐推荐列表[6]。通俗解释就是:若A,B两个用户都收藏了x,y,z三首歌曲,那么A,B就属于同一类用户。可以将A听取的歌曲推荐给B。以下图2-3解释了基于用户协同过滤算法:

图2-3基于用户的协同过滤
二、系统设计
4.1总体流程设计
项目的总体流程设计是以一定的时间间隔将最新的音乐数据集上传到HDFS文件系统中;接着,使用Map Reduce进行协同过滤计算,之后读取最新的推荐结果到内存;最后,用户可借助浏览器向服务器发送一个需要获取推荐的网站列表,由网页程序从数据中读取推荐结果呈现出来[7]。
4.2功能模块设计
4.2.1数据来源
数据来源是依靠网络资源,结合大数据平台,寻找所需的数据集。本项目采用音乐数据集data.zip,里面包含许多歌曲。数据存储在HDFS中,并使用Map Reduce进行计算,在此基础上开始后期的数据处理及最后的可视化。
4.2.2数据存储
本项目中的数据存储涉及两方面。注册新用户,数据库会自动保存用户和密码;还存储用户登录时的信息、歌手歌曲信息、以及用户个性化评分数据等。数据库存储数据设计如图4-1所示:
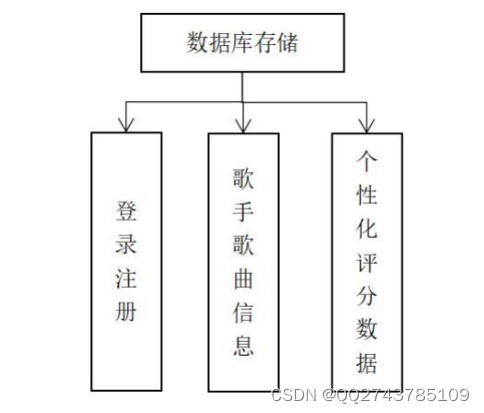
图4-1数据库存储图
Hadoop的HDFS用来存储数据集、以及使用Map Reduce计算后的推荐结果。Hadoop中数据存储如图4-2所示:
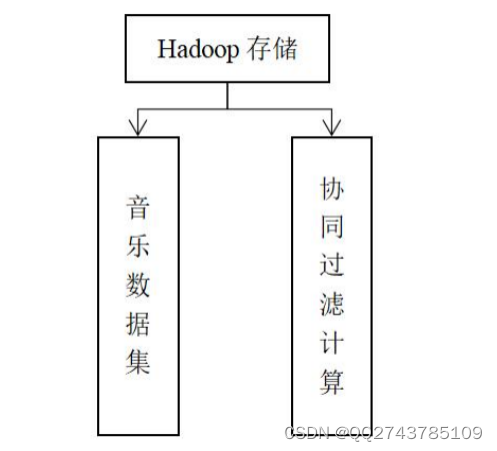
图4-2Hadoop数据存储图
三、系统实现
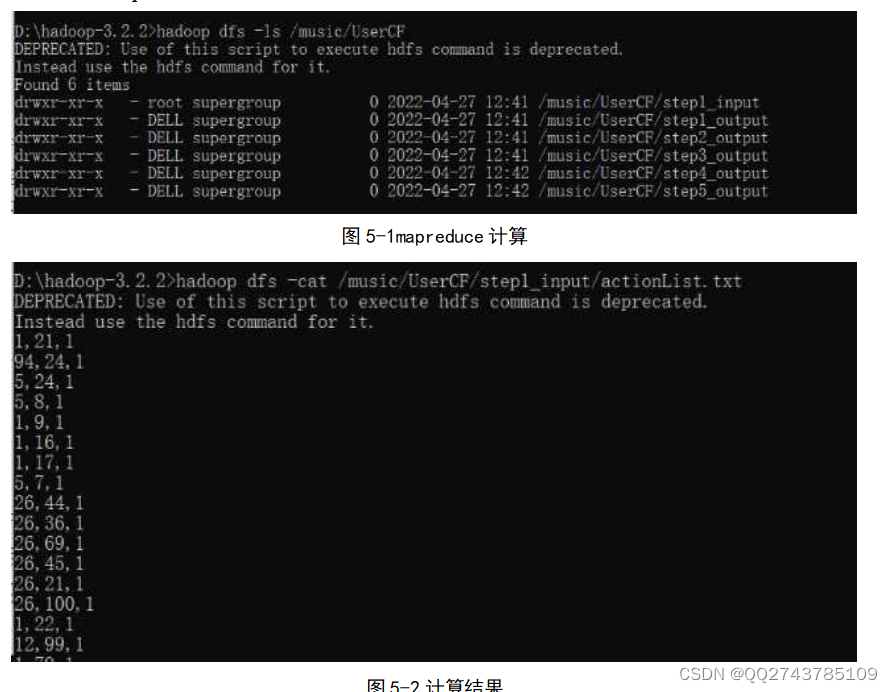
数据处理模块主要是使用Hadoop中的Map Reduce对数据进行计算,从而根据用户间的相似度推荐歌曲歌单列表。Map Reduce的计算分为五步,首先根据用户对歌曲或者歌单的各种操作得到用户、物品评分矩阵,第二步是利用评分矩阵构建用户和用户之间的相似度矩阵,第三步将评分矩阵转置,第四步就是将前两步得到的矩阵相乘,最后一步就是在前面输出的矩阵中将用户已经有过行为的评分置零,得出最终的计算结果。图5-1为Map Reduce五步计算,5-2为计算结果显示:

四、结论
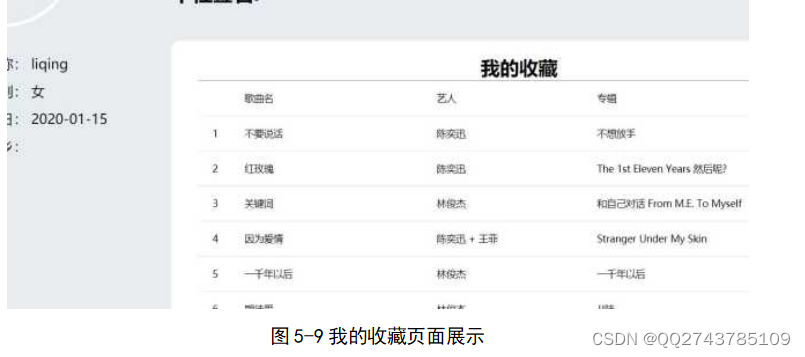
为了能够更好并且及时准确的给用户推送歌曲,设计了这个基于Hadoop的音乐推荐系统,该系统主要应用Vue框架进行前端页面的设计和编写,后端使用SSM框架,数据库使用mysql对系统中的数据进行存储和处理。整个音乐推荐系统包含有登录注册功能,歌曲、歌手管理功能,有基于用户的歌单推荐功能,用户登录之后还可以对歌曲进行相关操作,如收藏、评论、下载等,能够给用户提供一个较好的音乐体验[12]。
本文中除了详细介绍了系统的功能,还从操作可行性、经济可行性方面对该系统的构建做了全面的分析和规划;第二章节详细介绍了所用相关技术,之后的概要设计说明了各个功能模块设计的目的以及它们各自可以实现的功能;并对mysql数据库存储表进行了展示,各个部分之间的联系也使用ER图进行了说明;之后在系统的详细设计过程中,给出了功能实现的核心代码,并对前端页面进行了展示。