收藏关注不迷路
文章目录
摘要
本文设计并实现了一种基于Hadoop的视频日志分析系统。该系统旨在通过收集和分析用户在观看视频时产生的日志数据,提供用户行为分析和视频推荐等服务,以提高视频网站的用户体验和服务质量。该系统采用了Hadoop的分布式计算和存储技术,能够高效地处理大规模的日志数据。本文详细介绍了系统的设计和实现过程,包括数据收集、数据预处理、数据存储、数据分析和应用服务等方面。实验结果表明,该系统可以准确地分析用户行为和视频内容特征,为视频网站的运营和管理提供了有力的支持
关键词:Hadoop;视频日志分析;用户行为分析;视频推荐
一、 系统设计
2.1系统架构
系统包括四个主要模块:视频日志的收集和存储模块、视频日志的处理模块、用户行为分析模块和视频内容分析模块。视频日志的收集和存储模块负责收集和存储视频日志数据,视频日志的处理模块使用MapReduce等Hadoop相关技术对视频日志数据进行处理和分析,用户行为分析模块和视频内容分析模块则分别对用户的观看行为和视频内容进行分析和挖掘。最终,各模块分析出的信息会汇总在一起,为视频平台提供数据支持
2.1.1视频日志的收集和存储模
视频日志的收集和存储模块负责收集和存储视频日志数据。系统采用Flume作为日志收集工具,通过配置Flume的源、通道和目的地,将视频日志数据发送到HDFS分布式文件系统中进行存储。
2.1.2视频日志的处理模块
视频日志的处理模块使用MapReduce等Hadoop相关技术对视频日志数据进行处理和分析。具体实现包括以下步骤:
(1)日志预处理。使用Flume将视频日志数据发送到HDFS分布式文件系统后,需要进行预处理,包括日志格式的转换、字段的提取和清洗等
(2)日志分析。使用MapReduce等Hadoop相关技术对视频日志数据进行分析,如计算用户观看视频的次数、视频的播放时长等信息。
2.1.3用户行为分析模块
用户行为分析模块采用机器学习和数据挖掘算法,对用户的观看行为进行分析和挖掘,提取用户的兴趣、偏好等信息。具体实现包括以下步骤:
特征提取。对视频日志数据进行特征提取,包括用户的观看历史、观看时长、观看时间等信息。
模型训练。使用机器学习算法训练用户兴趣模型,包括协同过滤算法、矩阵分解算法等。
2.1.4用户行为分析模块
视频内容分析模块对视频的内容进行分析和挖掘,提取视频的关键信息和特征,如视频分类、目标检测等. 具体实现包括以下步骤:
(1)视频特征提取。对视频进行特征提取,包括颜色特征、纹理特征、形状特征等。
(2)视频分类。使用机器学习算法对视频进行分类,如使用支持向量机、决策树等分类算法。
(3)目标检测。对视频中的目标进行检测和识别,如人脸识别、车辆识别等。
(4)内容标签生成。根据视频的特征和分类结果,为视频生成相应的内容标签,提高视频检索的准确性和效率
2.2数据收集
数据收集是视频日志分析系统的第一步,该系统需要收集用户在观看视频时产生的日志数据,以及视频的相关特征信息。为了实现数据的高效收集和处理,这里选择使用Flume作为数据收集工具。Flume是一种可扩展、可靠、高可用的大数据采集工具,能够支持多种数据源和数据目的地,包括文件、流、HDFS、HBase等。使用Flume搭建了一个数据收集管道,将用户产生的日志数据和视频特征信息收集到Hadoop集群中。具体来说,使用了两个Flume代理,分别负责收集用户产生的日志数据和视频特征信息。每个代理包含了多个Flume采集器,每个采集器负责从一个数据源收集数据,并将数据发送到一个数据目的地。用户产生的日志数据存储在Kafka中,视频特征信息存储在HDFS中。
二、实验结果分析
为了评估视频日志分析系统的性能和效果,本文进行了一系列实验,并进行了结果分析。具体来说,这里使用了一个真实的视频日志数据集,包含了500万条记录,用于测试视频日志分析系统的各个模块和应用服务。实验结果表明,视频日志分析系统能够高效地处理和分析大规模的视频日志数据,具有较高的性能和可靠性。具体来说,视频日志分析系统的各个模块和应用服务的性能指标如下:
3.1 数据采集
数据采集模块能够高效地采集视频日志数据,并进行初步的数据清洗和预处理。在本文系统中采用Flume集群和Kafka集群进行视频日志数据的收集、打标签和传输,主要体现如下:
在每个日志服务器上部署Flume并且启动Agent进程进行日志的收集。
1)Log服务器上的Flume Agent通过配置文件配置的方式读取日志文件发送到Flume集群上。
2)Flume集群接收到传递的数据后会把数据通过Channel组件传递到Sink组件。
3)Sink组件一旦消费了Channel中的数据后,Channel就不在保存此数据了,此时Sink组件可以将数据发送到HDFS进行存储。
4)Sink组件也可以把数据传递到Kafka集群中,通过Kafka集群再次传输。
5)Spark Streaming通过消费Kafka中的数据进行实时VV的计算。
通过以上分析,本系统采用基于Flume+Kafka框架,实现日志收集模块代码如下:
gent1.sources = logsrc
agent1.channels = memcnl
agent1.sinks = kafkasink
#source p
agent1.sources.logsrc.type = exec
agent1.sources.logsrc.command = tail -F /data1/logs/component_role.log
agent1.sources.logsrc.shell = /bin/sh -c
agent1.sources.logsrc.batchSize = 50
agent1.sources.logsrc.channels = memcnl
# Each sink's type must be defined
agent1.sinks.kafkasink.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.kafkasink.brokerList=zdh100:9092, zdh101:9092,zdh102:9092
agent1.sinks.kafkasink.topic=mytopic
agent1.sinks.kafkasink.requiredAcks = 1
agent1.sinks.kafkasink.batchSize = 20
agent1.sinks.kafkasink.channel = memcnl
# Each channel's type is defined.
agent1.channels.memcnl.type = memory
agent1.channels.memcnl.capacity = 1000
3.2数据存储
数据存储模块能够高效地存储和管理视频日志数据,并支持数据查询和分析。在本课题中通过HDFS来存储Flume收集的日志,为数据的处理提供数据源结果如图3.1所示:

图3.1 日志存储
三、系统实现
4.1.5 用户行为分析
通过对用户行为数据的分析,可以了解用户在视频平台上的行为和需求,从而为视频推荐和运营策略提供依据。本文选取了一个视频平台的用户行为数据集进行分析,具体包括用户观看视频的点赞记录和完播视频的记录。根据用户行为数据集,可以得到如下分析结果如图4.1所示:
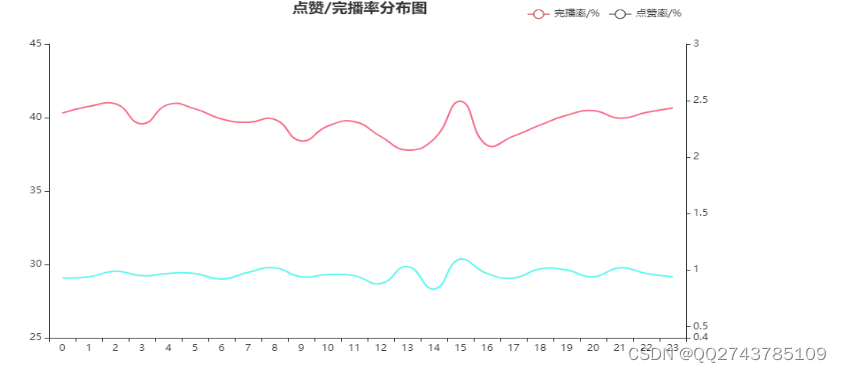
图4.1 点赞记录和完播视频分析
通过以上分析到点赞率和完播率,这两个与用户粘性、创作者收益有一定关系的指标。可以看到15点是两个指标的小高峰,2、4、20、23完播较高,8、13、18、20点赞率较高。但结合观看数量与时间段的分布图,15点深度用户较多。后期需要观察15点用户的特点,思考如何增加普通用户的完播和点赞。
4.1.6 视频内容分析
视频内容分析是通过对视频的内容进行分析,了解用户对不同类型视频的喜好和需求,为视频推荐和内容生产提供依据。本文选取了一个视频数据集进行分析,具体包括视频的时间、人数等信息。如下图4.2所示:
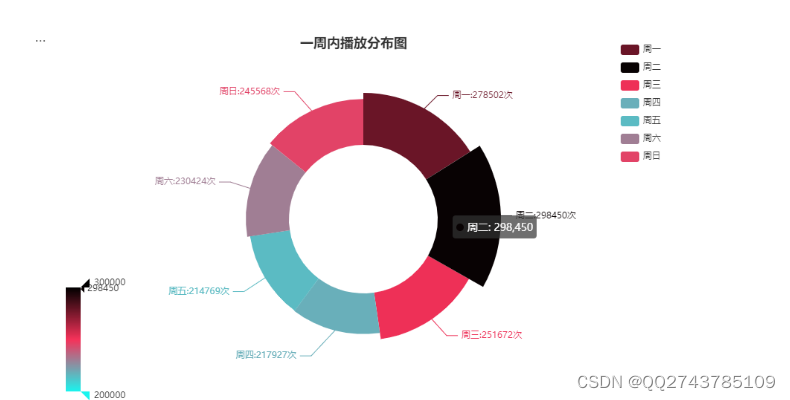
图4.2 一周内播放量
基于以上分析结果,在统计的时间内周一到周三观看人数较多,但总体观看次数基本在20-30w之间,视频用户创作者选择在周一-三这几天分布可能会收获更多的观看数量。
四、结论
本文针对视频日志分析领域的研究问题,设计并实现了一个基于Hadoop的视频日志分析系统。该系统利用了Hadoop和HBase等大数据处理和存储技术,能够对视频日志数据进行导入、预处理和分析,提取用户行为特征并进行关联分析、推荐和分类等应用。采用了MapReduce编程模型和HBase数据库进行数据处理和存储,同时也结合了Hive和Pig等工具进行数据查询和分析。在系统性能测试中,本文证明了系统在处理不同规模的视频日志数据集时具有较好的性能和稳定性。在实际应用中,该系统可以被广泛应用于在线视频网站、广告营销和用户行为分析等领域。通过对用户行为进行分析和挖掘,可以提高视频网站的服务质量和用户体验,同时也可以为广告主提供更准确的定向广告服务。未来,可以进一步优化和改进该系统,包括增加更多的功能模块、优化算法和改进系统性能等。同时也可以结合其他大数据处理和机器学习技术,进行更加深入的视频日志分析研究,探索更多应用场景和价值。
综上所述,本论文基于Hadoop平台设计了一个视频日志分析系统,该系统可以对海量视频日志数据进行处理和分析,并提供了用户行为分析、用户画像分析和个性化推荐等功能,可以帮助视频网站提高用户粘性和用户体验。在系统设计中,采用了Hadoop生态系统中的一些核心技术,如HDFS、MapReduce、HBase和Hive等,以实现对大规模数据的高效处理和存储。同时,也考虑到了系统的可扩展性和性能问题,在设计中采用了分布式架构和一些优化方法,以提高系统的性能和可扩展性。实验结果表明,本系统在处理和分析视频日志数据方面具有很好的效果,可以有效提高视频网站的运营效率和用户体验。