目前,本人写的scitb包1.5版本已经正式在R语言官方CRAN上线,scitb包是一个为生成专业化统计表格而生的R包。目前只能绘制基线表一。
可以使用以下代码安装
install.packages("scitb")

安装过旧版本的从新安装一次就可以升级了
scitb包1.5版本修正了上个版本的一些小错误,根据粉丝的建议,增加了两个新功能,一个是返回了统计值的结果,因为咱们国内的论文投稿的时候经常需要上报一些卡方值,F值等什么的,其实scitb包计算的时候已经生成这个值了,只是没有列出来,这次增加了这个功能,还有一个是增加了自动判断数据是否是正态分布,然后根据是否是正态分布返回相应的结果,如果不是正态分布的话返回的是中位数和四分位数表示,P值也是使用秩和检验计算出来。
下面我来演示一下,scitb包生成结果需要stringi包和nortest包支持,这两个包你可以不导入,但要先安装好。
install.packages(stringi)
install.packages(nortest)
安装好需要的包后我们就可以开始了,先导入R包和数据,scitb包自带有我既往的早产数据,咱们直接从包调用
library(scitb)
bc<-prematurity
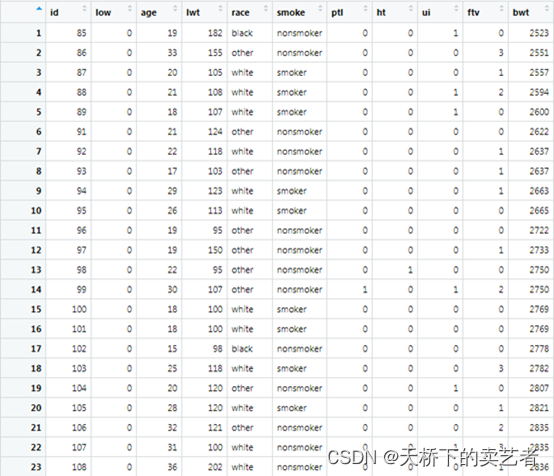
这是一个关于早产低体重儿的数据,低于2500g被认为是低体重儿。数据解释如下:low 是否是小于2500g早产低体重儿,age 母亲的年龄,lwt 末次月经体重,race 种族,smoke 孕期抽烟,ptl 早产史(计数),ht 有高血压病史,ui 子宫过敏,ftv 早孕时看医生的次数,bwt 新生儿体重数值
Sci包中绘制基线表的主要是scitb1函数(以后会有更多其他表格函数),咱们来看下它的函数体
scitb1(vars,fvars=NULL,strata,data,dec,num,nonnormal=NULL,type=NULL,
statistic=F,atotest=T,NormalTest=NULL)
咱们先来看一下,vars是变量的意思,你基线表中的变量放进去,fvars是分类变量,就是你vars变量中的分类变量,如果没有的话就留空。strata,就是分层的意思,这里填入你要研究的变量,data这里填入你的数据,dec就是你生成结果的小数点位数,默认是3位,其他的变量我在后面部分穿插来讲。
咱们先来个分类变量的
假设咱们想race为研究目标,因为它是分类变量,咱们最好把它转成因子,因为scitb包有一定对数据类型的判定能力,如果你的分类变量类别大于5个,而你不转成因子的话,它可能自动判定为连续变量,处理方式不一样的,所以这里最好自己设定一下
bc$race<-as.factor(bc$race)
接下来就是定义全部变量,分类变量和分层变量,这和tableone包一模一样,如果你会使用tableone包,使用scitb包起来完全无压力。
allVars <-c("age", "lwt", "smoke", "ptl", "ht", "ui", "ftv", "bwt")
fvars<-c("smoke","ht","ui")
strata<-"race"
一键生成统计结果
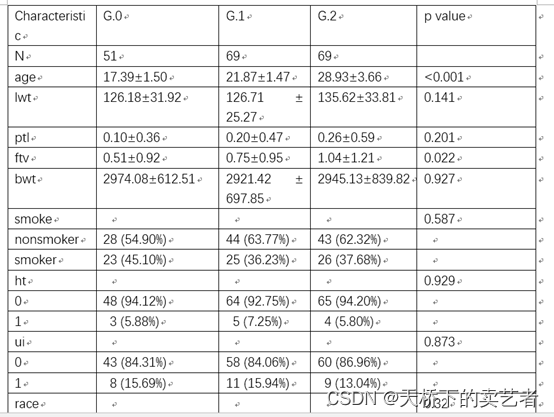
out<-scitb1(vars=allVars,fvars=fvars,strata=strata,data=bc)
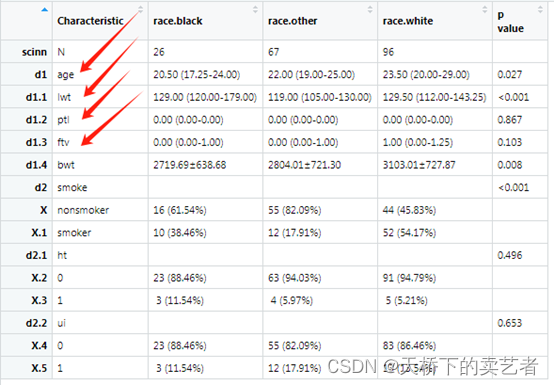
咱们看下上图,这里我要好好讲一下,“age”, “lwt”,“ptl”,“ftv”,这4个变量被函数判断成了非正态分布,bwt被判定成了正态分布。咱们先看"ptl","ftv"这两个的结果非常奇怪好像不怎么对,咱们从新看下数据
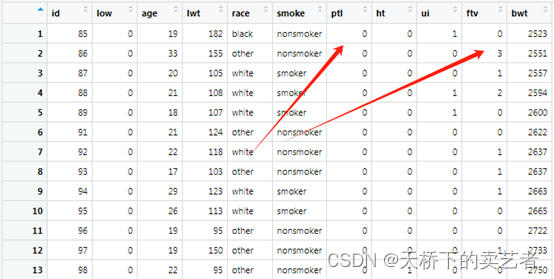
"ptl"只有两个分类应该是定义成分类变量,我们把它定义成连续变量搞错了,ftv是看医生的次数,1-6次,虽然看起来好像个连续变量,但是只有6个分类变量,我觉得该是定义为分类变量比较好,可以改成3次一下和3次以上的,咱们从新跑一下
fvars<-c("smoke","ht","ui","ptl","ftv")
out<-scitb1(vars=allVars,fvars=fvars,strata=strata,data=bc)
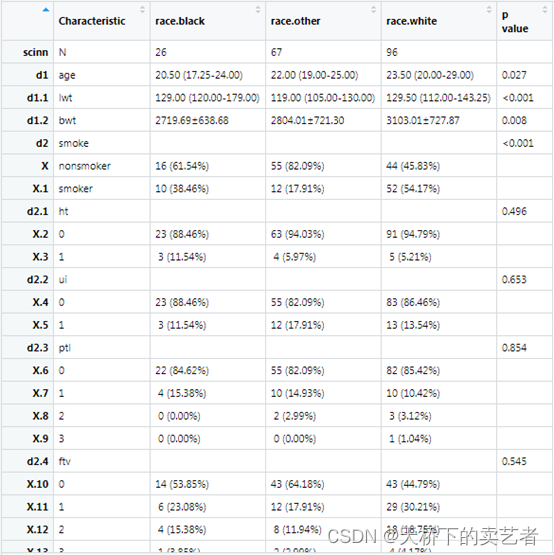
我们可以看到age,lwt这两个变量还是被判定为非正态分布,咱们来看下它算的对不对,画个直方图
hist(bc$age)
hist(bc$lwt)
hist(bc$bwt)
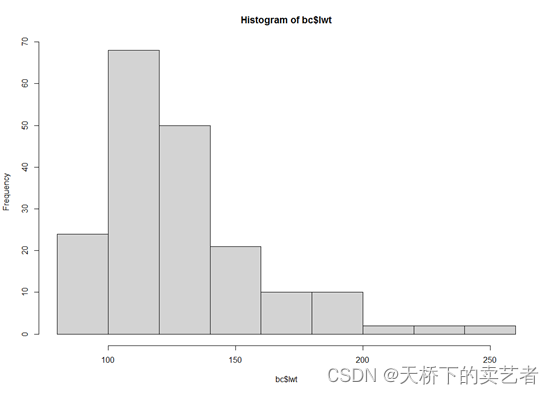
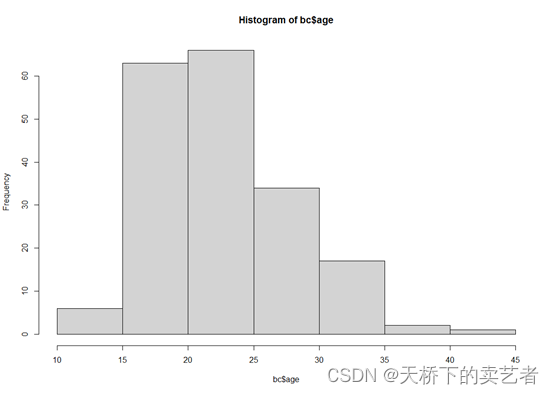
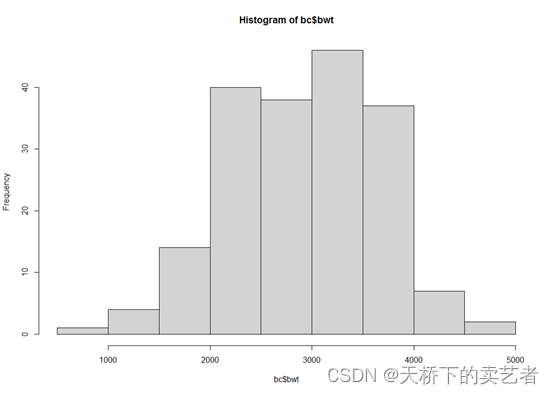
我们可以看到前两个不是正态分布,而bwt是明显的正态分布,算得还是比较准的。我这里介绍一下我是怎么算正态分布的,我参照了SPSS的算法。

我们可以看到,SPSS对于正态分布提供2种算法Shapiro-Wilk 检验和Kolmogorov–Smirnov检验。Shapiro-Wilk 检验是用于样本量小于3500的。
而我在scitb包中提供了5种算法,默认的是:当样本量小于3500使用Shapiro-Wilk 检验,样本量大于3500使用Kolmogorov–Smirnov检验。你要是觉得这两种检验算得不准的话,我这里还提供有"ad", “cvm”, "pearson"3种检验,使用NormalTest参数控制,比如
out<-scitb1(vars=allVars,fvars=fvars,strata=strata,data=bc,NormalTest="ad")
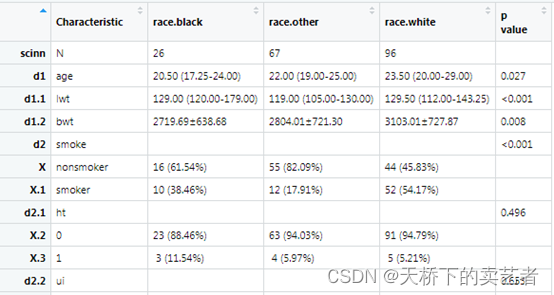
近年来有文献表明"ad", "cvm"这两种方法优于前面两种,但前两种是经典算法,被大众接受,所以我默认了前两种。
自动计算正态分布受到atotest参数控制,默认是atotest=T,比如你不想使用函数自动帮你计算正态分布,你想自己定义你可以关了,通过nonnormal这个参数来定义非正态参数
out<-scitb1(vars=allVars,fvars=fvars,strata=strata,data=bc,nonnormal =c("lwt"),atotest = F)
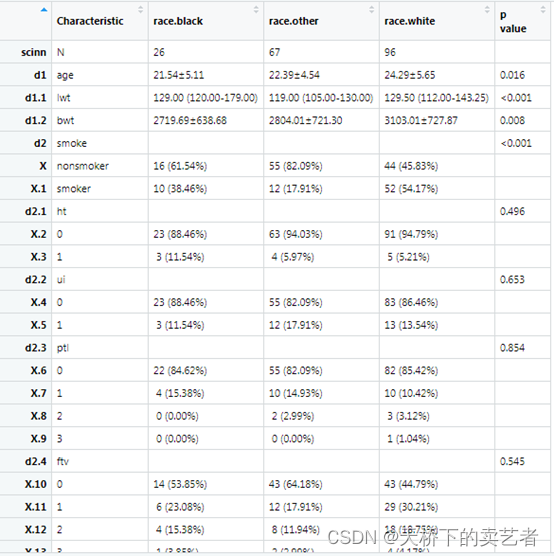
我们可以看到就只有lwt定义为非正态分布。
我这里要重点说一下,如果你使用nonnormal这个参数来定义非正态分布的参数,一定要设置atotest = F,把自动判定关掉,不然是没有用的,还是会自动判定的。
接下来说一下统计值,默认是不返回统计值,统计值由参数statistic控制,默认是statistic=F,如果你的文章需要统计值,可以
out<-scitb1(vars=allVars,fvars=fvars,strata=strata,data=bc,statistic=T)
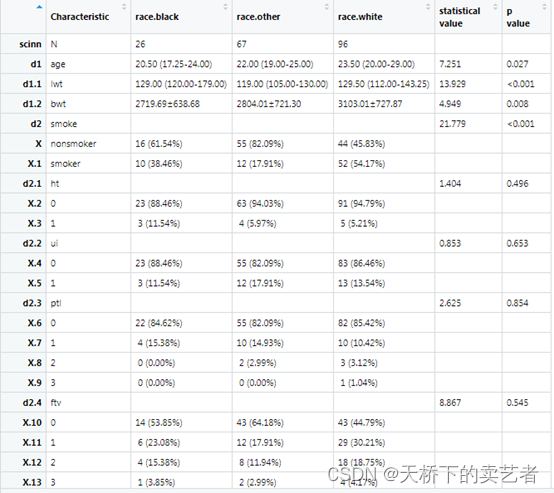
这里我解释一下,如果是分类变量这里的方法是卡方,一律是卡方值(χ2),如果是连续变量的,如果是正态分布的话就是使用单因素方差分析,它的值是F值,如果是非正态分布的话,使用的是秩和检验,也有叫克鲁斯卡尔-沃利斯检验(Kruskal-Wallis),在SPSS中叫做K检验,算出来的结果和tableone一模一样的,有兴趣可以自己取算一下。
下面我来介绍一下连续变量和上一篇差不多的(详细的可以翻看上一篇),这里我简单介绍一下。
我们这里假设研究年龄age这个连续变量,默认分层3组
allVars <-c("race", "lwt", "smoke", "ptl", "ht", "ui", "ftv", "bwt")
fvars<-c("smoke","ht","ui","race")
strata<-"age"
一键生成结果
out<-scitb1(vars=allVars,fvars=fvars,strata=strata,data=bc)
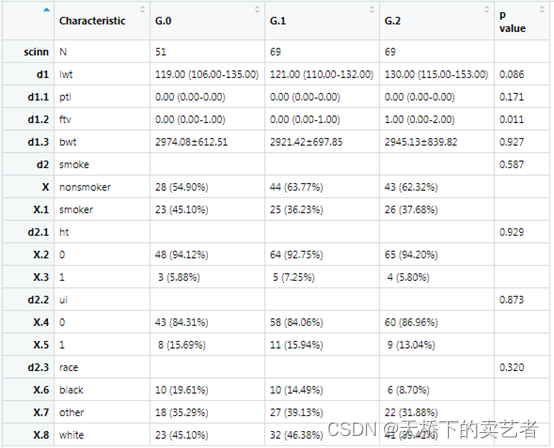
在新版本中,除了介绍分割点外,还会出现红字温馨提醒你,分层变量也就是目标变量被当做一个连续变量来处理了

加入统计值也是一样的
out<-scitb1(vars=allVars,fvars=fvars,strata=strata,data=bc,statistic=TRUE)
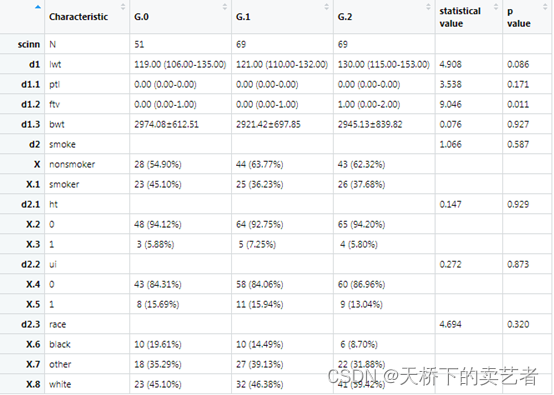
其他的都和上一篇差不多,就不详细介绍了,有兴趣的看下上一篇。最后导出数据
write.csv(out,file = "1.csv",row.names = F)
这里要说一下,如果你导出的是乱码,可以使用如下代码纠正
write.csv(out,file = "1.csv",fileEncoding = "GB18030",row.names = F)

打开看一下

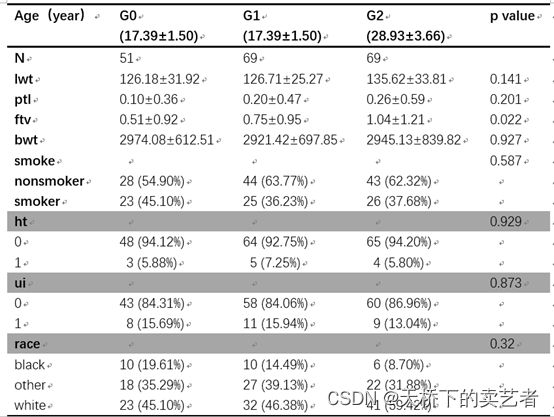
把它拷贝入word
把它整理一下,这样一个专业表格就做好啦。
如果你还是不会也没有关系,下周我再出个操作视频。