OCR代表光学字符识别,指的是用于将扫描的图像、PDF或其他文档转换为可编辑和可搜索的文本文件的技术。通过OCR,从文档中捕捉字符和文本,将其转换为数字格式,然后转换为可编辑的文档,如可以编辑、搜索和共享的文字处理文件。

OCR的工作原理:
OCR过程始于将文档扫描成数字图像。一旦文档数字化,OCR软件会分析图像并识别每个字符或符号,如字母、数字和标点符号。这个过程是通过机器学习算法和模式识别技术来实现的。
一旦字符被识别,OCR软件使用各种算法将图像转换为文本。这个过程涉及识别文本的结构以及与页面上其他元素(如行、段落和列)的关系。
生成的文本文件然后经过清理,去除任何残留的不准确和格式问题,最终得到的是原始文档的准确、可编辑和可搜索的表示。
在这里,我们将使用一个名为EasyOCR的Python库,它提供了一个简单而准确的解决方案,用于从图像中识别文本。它构建在著名的OCR引擎Tesseract和Kraken之上,并为OCR任务提供了高级别的API。通过EasyOCR,你可以用几行代码从图像中提取文本,这使它成为那些希望快速轻松开始使用OCR的人的理想选择。
EasyOCR的主要优势之一是其准确性。它使用先进的OCR引擎以高准确度识别文本,并在广泛的真实世界图像上进行了测试。此外,EasyOCR支持多种语言,包括英语、西班牙语、德语、法语等等,使其成为各种应用的多功能工具。
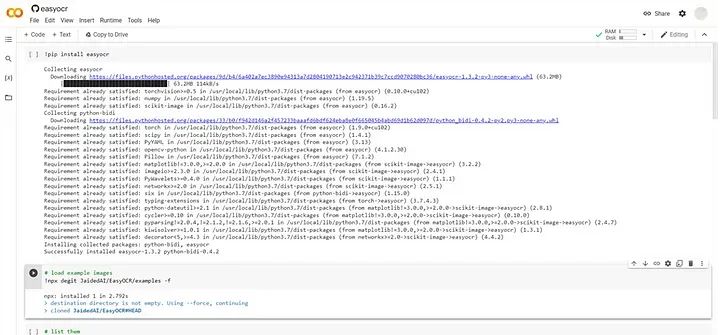
我们将使用Google Colab演示EASYOCR库的使用。运行第一个包含以下代码的单元格:
pip install easyocr这将安装库和所有其他必需的组件:
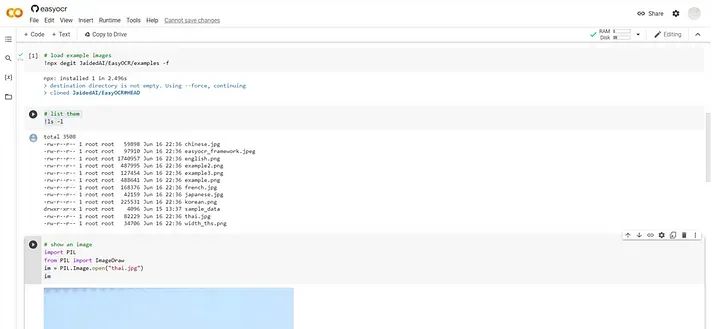
运行第二个包含以下代码的单元格:
!npx degit JaidedAI/EasyOCR/examples -f上述代码获取我们用于测试安装的示例图像。
以下代码列出了我们已下载用于测试安装的所有文件。
list them!ls -l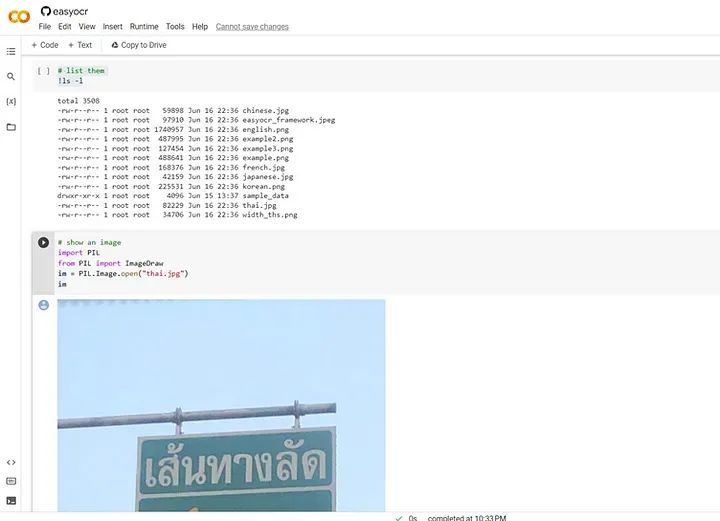
在一个新的单元格中运行以下代码,这将创建一个reader对象,用于执行光学字符识别。
import easyocr
reader = easyocr.Reader(['th','en'])将reader函数传递给它:
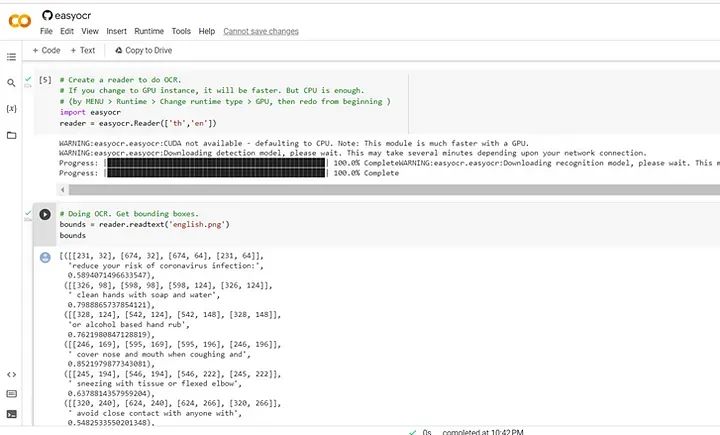
以下代码接受图像URL并输出检测到的文本及其边界:
bounds = reader.readtext('english.png')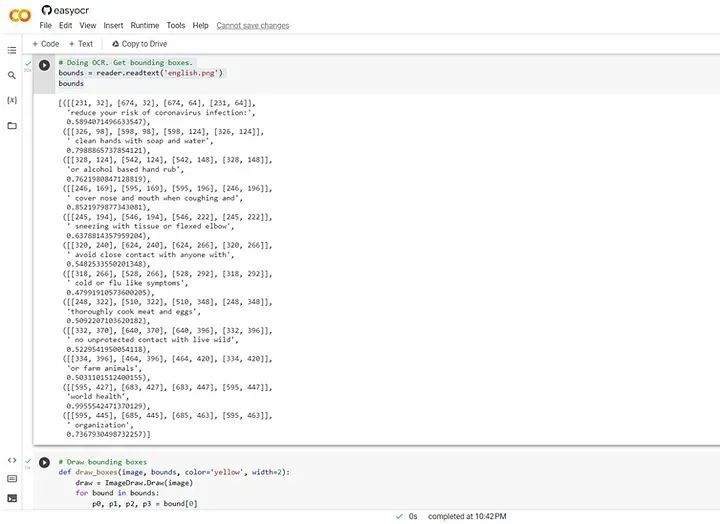
我们可以看到检测到的文本,以下是输入图像及其输出:

[([[231, 32], [674, 32], [674, 64], [231, 64]],
'reduce your risk of coronavirus infection:',
0.5894071496633547),
([[326, 98], [598, 98], [598, 124], [326, 124]],
' clean hands with soap and water',
0.7988865737854121),
([[328, 124], [542, 124], [542, 148], [328, 148]],
'or alcohol based hand rub',
0.7621980847128819),
([[246, 169], [595, 169], [595, 196], [246, 196]],
' cover nose and mouth when coughing and',
0.8521979877343081),
([[245, 194], [546, 194], [546, 222], [245, 222]],
' sneezing with tissue or flexed elbow',
0.6378814357959204),
([[320, 240], [624, 240], [624, 266], [320, 266]],
' avoid close contact with anyone with',
0.5482533550201348),
([[318, 266], [528, 266], [528, 292], [318, 292]],
' cold or flu like symptoms',
0.47991910573600205),
([[248, 322], [510, 322], [510, 348], [248, 348]],
'thoroughly cook meat and eggs',
0.5092207103620182),
([[332, 370], [640, 370], [640, 396], [332, 396]],
' no unprotected contact with live wild',
0.5229541950054118),
([[334, 396], [464, 396], [464, 420], [334, 420]],
'or farm animals',
0.5031101512400155),
([[595, 427], [683, 427], [683, 447], [595, 447]],
'world health',
0.9955542471370129),
([[595, 445], [685, 445], [685, 463], [595, 463]],
' organization',
0.7367930498732257)]以下是一些图像的更多示例:

另一个例子:

另一个例子,使用印地语:

另一个例子,使用法语:



· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除