作为 AutoDev 的核心开发,我们不仅在不断丰富 AutoDev 的功能以满足不同公司的定制需求,还在与各种团队进行持续交流。在处理遗留系统时,我们发现程序员们日常工作中需要面对大量使用过时技术、基础设施混乱的系统。
在这个背景下,探索如何利用人工智能增强这些系统的演进成为一项极富挑战性的任务。毕竟,大佬们都说:所有的应用都要重写一遍。
PS:当然了,大佬也在说:未来不会有应用~~。
为什么场景驱动?
Thoughtworks 与其他大多数模型厂商不同,一直在探索最佳的编程实践。因此,在 AutoDev 中,我们考虑融入各种实践,而不仅仅是代码生成。我们在设计功能时一直关注不同的场景,以满足不同场景的需求。
在有了大模型加持之后,AI + IDE 有了更多的可能性:
代码增强。即让 AI 来加快开发人员的日常编码速度,诸如代码补全、生成文档、生成测试等等。
普通活动增强。即让 AI 来修复错误、生成提交信息、进行代码检视等等。
融入其他活动。即以 IDE 为媒介,持续将其他的开发活动集成到 IDE 中,诸如文档查询、API 接入等等。
而这些都是基于能力所设计的,位于其背后其实包含了一系列的场景:编码、调试、测试、联调等等,每个场景背后都需要不同的功能来连动,以完成连贯的场景体验。
这就意味着,我们需要能够更好地:理解和适应开发者在不同场景时面临的复杂情境,并提供更智能、个性化的开发体验。诸如于,在遗留系统场景下,它通常具有复杂的代码结构和多语言混合使用,往往需要由人来分析和指令,让 AI 做一些繁琐和重复的工作。
场景:遗留系统改造
对于编码和其它场景,在我先前的《上下文工程:基于 Github Copilot 的实时能力分析与思考》 等文档,以及 NJSD 大会的《从个人到组织, AIGC技术的工程化落地》上的分享里,已经做了详细的介绍。而作为一个开发团队,我们每天不可能有大量的新增代码,大部分人还是工作在遗留系统上 —— 一个你可能不知道某个功能、某块业务是如何实现的?
生成式 AI 增强 :“遗留系统改造”
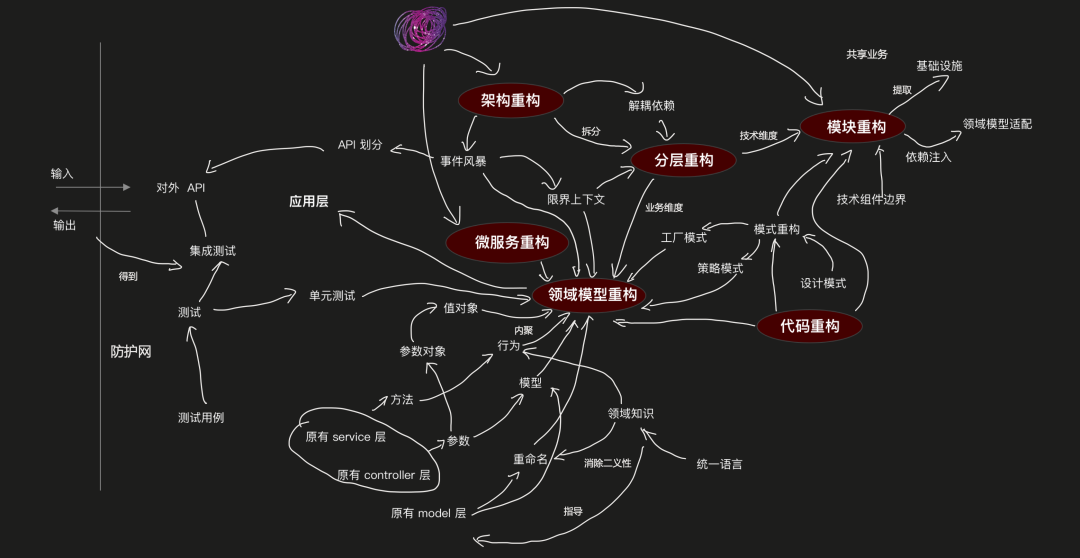
在我开源的那本《系统重构与迁移指南》(https://github.com/phodal/migration,stars:3.3k)电子里,详细介绍了如何分析、评估现有系统、制定重构策略、探索可行重构方案等一系列的遗留系统重写与重构模式。
基于经典的遗留系统重构范式,在代码层面我们要做这么一些事情:
建立评估与度量
搭建测试防护网
重新设计系统架构。诸如于 DDD 用于改善模块化架构
业务提取与服务重构。
进行细粒度的重构。诸如于代码等等
而在有了生成式 AI 之后,在我们做完了顶层设计之后,它可以大大加速我们的落地实践。
创意阶段:增强环节分析
基于这个场景之下,我们就需要思考哪些功能可以借助生成式 AI 来辅助。如下我们是会在头脑风暴时产生的一些想法:
改造方案设计。即通过聊天的方式,获得一些创意式的输入,以帮助我们更好地编写解决方案。
测试防护网搭建。根据系统的复杂度,需要创建不同维度的测试数据、测试用例等。
系统架构设计。即通过聊天的方式,获得一些创意式的输入,以知道什么是更好的架构。
业务信息提取。即通过文档生成、调用链分析等方式,分析某一个 API 的业务与实现逻辑。
基础设施重写。诸如 Maven 迁移到 Gradle,上云基础设施改造(Dockerfile 生成 等)。
代码重写。适用于语言翻译(如 js 转换 ts)、逻辑优化等场景。
文档重新生成。即针对于现有的旧文档,重新生成一份新的文档。
……
除了,这些通用的功能之后,事实上还存在大量的复杂场景,诸如于:
存储过程代码的分析与迁移。
复杂构建脚本的迁移。
领域特定语言的重写。
根据不同的场景,我们都需要有选择地进行设计和强化。但是,显然我们可以看到生成式 AI 可以大大加速这一过程。
端到端定制方案

而对于更复杂的场景而言,我们则需要构建专有的工具来实现这个过程。诸如于 IBM 在设计针对于 COBOL 语言迁移时,将重构过程分为了三大阶段:
理解。即理解 COBOL 代码中的代码、数据、依赖部分,采用诸如可视化等方式设计。
重构。将已有的 COBOL 代码解耦,并重构为模块化的方式。
转换。将模块化的代码翻译为 Java 代码。
而过程中,还需要针对于已有的业务编写对应的 Java 测试代码,以方便进行手动和自动化的验证。
AI 如何增强遗留系统改造?
在对遗留系统进行改造时,智能 IDE 的升级将是一个关键因素。然而,如何将新功能转化为易于操作和高效的组件,以及如何在不同场景中提供最佳的用户体验,是一项具有挑战性的任务。
在功能与场景的设计中,我们需要回答一些关键问题:
何时开发新功能? 确定新功能的开发时机,使其与遗留系统的改造需求相匹配。
何时开放定制化能力? 确定定制化的灵活性在哪些场景下是必要的,以满足用户的个性化需求。
何时交由开发人员决定? 确定哪些场景下,完全交由开发人员决定,以保持系统的灵活性。
并且,我们还应该确保这些功能应该是方便使用的。当然了,最简单的方式就是完全开放这种定制能力。基于这些思考,以我们开源 AutoDev 插件为例来介绍。
如何验证生成的代码?
在引入 AIGC 来生成代码时,都需要考虑的一个点是:如何验证生成代码的准确性?。这是一个复杂的问题,通常来说,应该是再由人去验证一遍的,但是有各种取巧的方式。诸如:
结合人工智能进行检查: 利用人工智能辅助验证生成的代码,提高验证效率。
生成测试以验证业务代码: 通过生成测试用例,确保生成的代码在业务场景中的正确性。
基于测试用例文档生成单元测试: 利用测试用例文档生成单元测试,使验证过程更加规范化。
当然了,这些都是规范化的团队所做的事情,实在不行就如我们在 Unit Mesh 架构所说的,由人来验证 AI 生成的代码。而在进行遗留系统改造时,有时这个问题就显得比较简单了 —— 只需要验证输入和输出,诸如于 Http API 的输入和输出。
所以,对应到功能上,只需要一键生成测试或者生成测试的方式,也就可以分为专有和自定义能力。
完成自定义:自定义语言转换

自定义是三种模式里最懒的方案,然而也是在实现上最复杂的,采用何种的交互方式,如何提供这一类灵活的接口。
作为工具的设计者,其实我们是无法枚举语言间的转换,常用的语言都有十几个,他们之间可以随意转换。这也就是最开始的是一个自定义 Action(https://ide.unitmesh.cc/custom/action),让开发人员可以通过 JSON 来配置这种转换:
{
"title": " Translate to Kotlin",
"autoInvoke": false,
"matchRegex": ".*",
"priority": 0,
"template": "将如下的代码翻译为 Kotlin.\n${SIMILAR_CHUNK}\nCompare these snippets:\n${METHOD_INPUT_OUTPUT}\n原始代码如下:\n${SELECTION}"
}并将相似的代码块 ${SIMILAR_CHUNK} 和函数的输入和输出 {METHOD_INPUT_OUTPUT} 作为上下文的一部分。
部分定制:活文档生成

开放定制是三种模式最复杂的,如何去平衡应该由程序的某一部分来完成,这并不是一件容易的事情。并且也有可能,它会变成一种不三不四的方案。
对于复杂的遗留系统来说,我们还需要理解现有的业务,需要了解业务的各种信息。而我们所推荐的一种方式就是活文档。活文档的方式有多种多样的,在代码中一种比较简单的实现方式就是通过注解。
而由于注释本身就是文档,所以活文档的功能在实现时是与注释生成一起的,其自定义方式如下:
{
"title": "Living Documentation",
"prompt": "编写 Living Documentation。按如下的格式返回:",
"start": "",
"end": "",
"type": "annotated",
"example": {
"question": "public BookMeetingRoomResponse bookMeetingRoom(@RequestBody BookMeetingRoomRequest request) {\n MeetingRoom meetingRoom = meetingRoomService.bookMeetingRoom(request.getMeetingRoomId());\n BookMeetingRoomResponse response = new BookMeetingRoomResponse();\n BeanUtils.copyProperties(meetingRoom, response);\n return response;\n }",
"answer": " @ScenarioDescription(\n given = \"there is a meeting room available with ID 123\",\n when = \"a user books the meeting room with ID 123\",\n then = \"the booking response should contain the details of the booked meeting room\"\n )"
}
}这里的 example 是为 LLM 提供一个示例,以更符合生成的结果。从实现上,远比先前的完成自定义复杂得多。
专有的新特性:API 测试数据生成
专有特性是三种模式中最简单的,也是最不对用户负责的。我们直接将功能放入到了系统中,用户的系统菜单和交互变得异常臃肿。
在实现上,也只需要根据这些场景做一些简单的接口和实现即可。
总结
开发一个 AI 原生应用并不是一件简单的事。我们应该思考:如何将生成式 AI 应用对更有价值的日常活动中?我们应该思考:如何将更多的自主性和决定权交由用户?
如果你也有兴趣来探索,欢迎来 AutoDev 探索:https://github.com/unit-mesh/auto-dev 。
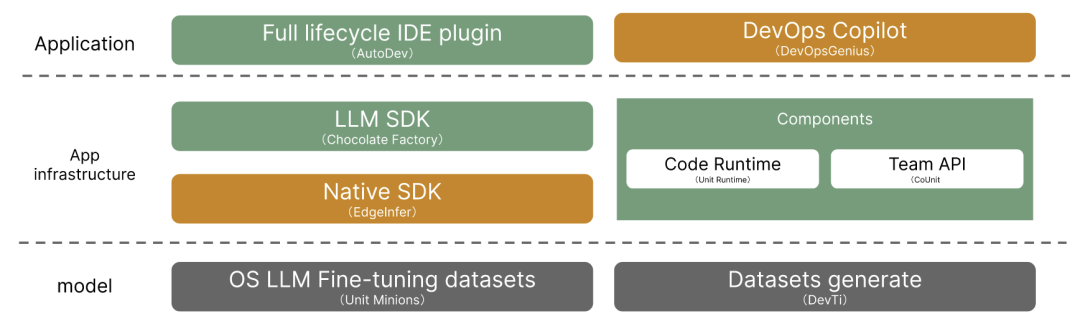
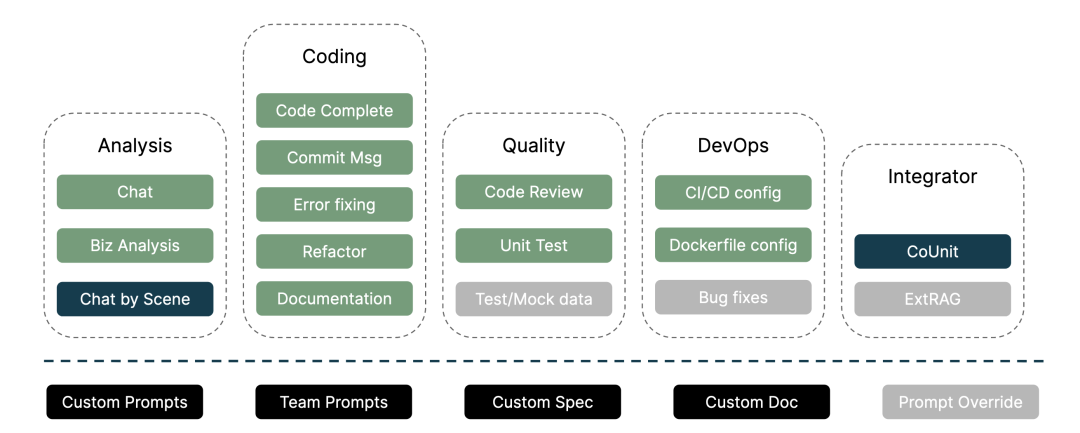
AutoDev 功能全景
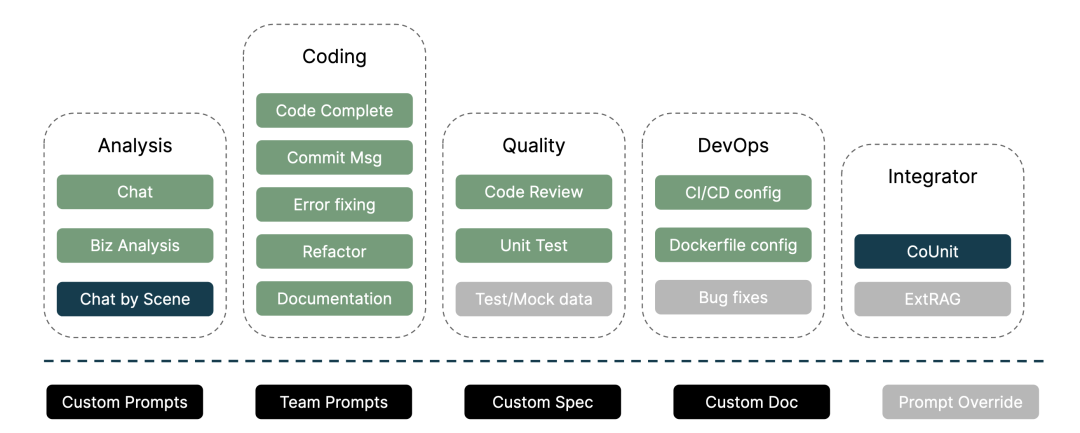
Unit Mesh 开源项目全景(https://github.com/unit-mesh/)