2023年,生成式AI的创新力量正加速席卷全球,通过图像视频生成、人机对话等多个领域的创新实践,向全世界展示了它的强大能力。然而,企业践行生成式AI的过程中往往会遇到缺乏足够算力、难以完成大模型训练的问题,成为生成式AI商业落地的最后一个壁垒。

在re:Invent 2023大会上,亚马逊云科技从企业级生成式AI的算力痛点出发,发布了强大且能耗更低的Amazon Graviton4、用于模型训练的高性能Amazon Trainium2等多款全新硬件芯片,覆盖处理器、模型训练、虚拟化系统架构以及超算等多个领域,以强势之力为生成式AI发展引入了基础设施的革新,拉开了企业级生成式AI新时代的帷幕。
新一代自研处理器芯片Amazon Graviton4
带来更强性能实例
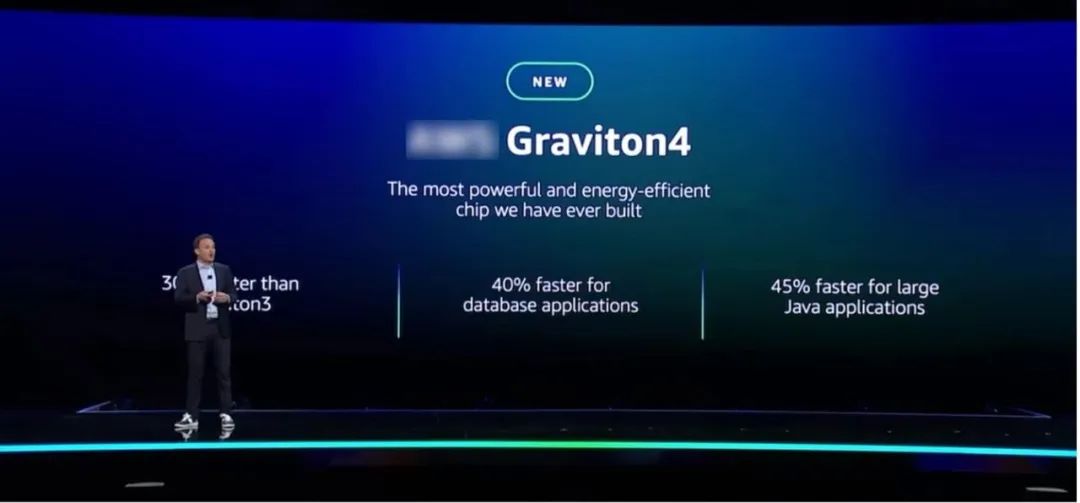
生成式AI的落地,离不开强大的算力,而处理器芯片自然是算力的主要来源之一。亚马逊云科技最新发布的处理器芯片Amazon Graviton4相比Amazon Graviton3,处理速度快30%、内核增加50%、内存带宽增加了75%,能将数据库应用提速40%、将处理大型Java应用的速度提升45%。

Amazon Graviton4
在核心方面,Amazon Graviton4使用的是基于ARM v9架构的“Demeter” Neoverse V2核心,而Amazon Graviton3使用的是“Zeus” V1核心。V2核心在每时钟周期指令数上比V1提高了13%,叠加Amazon Graviton内核数量的增加,带来了最终30%的性能增长(同时每瓦性能与Amazon Graviton3基本持平);
在内核数量方面,Amazon Graviton4 套件上有 96 个 V2 内核,比 Amazon Graviton3 和Amazon Graviton3E 提升了 50%;
在内存控制器方面,Amazon Graviton4 上封装有 12 个 DDR5 控制器,而Amazon Graviton3之前只有 8 个 DDR5 内存控制器。此外,Amazon Graviton4 使用的 DDR5 内存速度也提升了 16.7%,达到 5.6 GHz。综上所述,Amazon Graviton4 每个插槽的内存带宽为 536.7 GB/秒,比之前的Amazon Graviton3 和Amazon Graviton3E 处理器的 307.2 GB/秒高出 75%。目前,Amazon Graviton4可在最新的R8g实例中提供预览;与R7g相比,它拥有3倍的vCPU和内存。

Amazon Graviton历代芯片对比,从左到右依次是1~4代
与此同时,由于全系列Amazon Graviton处理器采用的都是ARM架构,与基于 x86 的亚马逊云科技同类实例相比,使用Amazon Graviton芯片的Amazon EC2实例成本可降低至多20%,与同类Amazon EC2实例相比,在实现相同性能的情况下最多可节省60%的能源。
目前,已有150个亚马逊云科技计算实例类型使用了Amazon Graviton处理器,超过50000名客户、其中包含Top100的客户,正在使用这些实例。Amazon Graviton4的推出,将进一步提升基于Amazon Graviton 处理器芯片实例的性能,助力企业获得更有性价比的算力。
新一代训练芯片Amazon Trainium2
提升大模型训练效率
另一方面,许多企业已经开始训练自己的生成式AI大模型,这个时候它们会发现自己需要有专门的模型训练芯片。亚马逊云科技发布的新一代训练芯片Amazon Trainium2,专门为大模型的训练做了优化,与上一代芯片相比性能提高到4倍、内存容量提高到3倍、能效提高到2倍。

此前,亚马逊云科技已经推出了专门用于大模型训练的芯片Amazon Trainium。使用Amazon Trainium的Amazon EC2 Trn1实例,采用 BERT-Large 模型进行测试的前提下,相比亚马逊云科技的P4d实例从单节点扩展到 16节点集群的过程中,训练的吞吐量与P4d集群相比提升达1.2 ~ 1.5倍,同时每百万序列的训练成本仅为同规模P4d集群的约40%。Amazon Trainium2的推出,将会进一步强化亚马逊云科技最新Amazon EC2 Trn2训练实例的性能,让客户只用几周时间就能训练出有3000亿个参数的大模型,加速步入生成式AI时代。
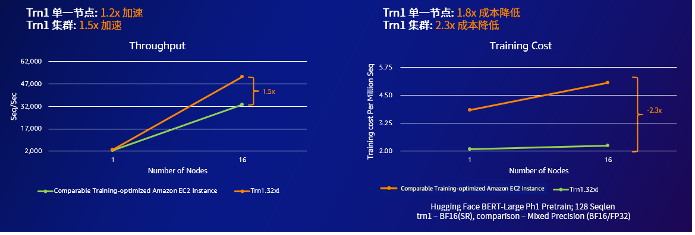 Trn1与同类实例在吞吐量及成本方面的比较
Trn1与同类实例在吞吐量及成本方面的比较
目前,生成式AI独角兽公司Anthropic,已计划用Amazon Trainium2芯片训练自己的生成式AI产品Claude。
Amazon Nitro
重新定义虚拟化
系统架构设计也是企业级生成式AI落地过程中的一大难点。因为随着算力需求的不断增加,实例中GPU等芯片的数量逐渐增多,大量的系统资源将消耗在联结芯片以及调度任务等各个方面,系统性能提升出现边际效应,这时虚拟化就成为了一种选择。
亚马逊云科技的Amazon Nitro系统是新一代Amazon EC2 实例的基础平台,通过专用的Amazon Nitro芯片卡,它能将CPU、存储、联网、管理等功能转移到专用的硬件和软件上,而使服务器的几乎所有资源都用于实例,从而提升资源利用率、降低成本。

Amazon Nitro 系统包含一个非常轻量级的Hypervisor,与传统Hypervisor会占用大约30%的系统资源相比,它的资源占用不到1%。这样,通过将虚拟化功能从服务器转移到亚马逊云科技自研的Amazon Nitro专用芯片上运行,把虚拟化对物理服务器的性能损耗降到最小。
与此同时,Amazon Nitro能够提供硬件级别的安全机制。Amazon Nitro安全芯片隔离了用户Amazon EC2实例对底层硬件的写操作,用户的数据能够得到很好的保护。此外,通过多样化的Amazon Nitro网卡和存储卡,存储虚拟化、网络I/O虚拟化与服务器硬件的更新迭代之间能够实现解耦,从而保证I/O性能。

如今,Amazon Nitro 系统已经发展到第五代,网络性能提升到了100Gbps。在Amazon Nitro 的帮助下,用户能提升Amazon EC2实例运行管理的安全性和稳定性,意味着Amazon EC2的实例设计可以更加灵活,最重要的是能够几乎完全消除虚拟化本身所带来的系统开销,让系统资源完全作用于工作负载,提升算力使用效率。
英伟达X亚马逊云科技
打造“云上最强超算”
最后,让我们来看一个企业级生成式AI通过亚马逊云科技落地的实际案例:英伟达超算。基于Amazon Nitro和Amazon EFA,16384个英伟达GH200芯片可以连接成为人工智能工厂“Nvidia DGX Cloud”。
这可以看成是一个巨大的虚拟化GPU集群,能提供65 exaflops的算力(目前全球第一的超算Frontier的算力约为1.1 exaflops),它将是全球首款搭载 NVIDIA Grace Hopper 超级芯片和亚马逊云科技可扩展性 UltraCluster 的,全球最快的云 AI 超级计算机,英伟达打算把它用于NVIDIA AI的研发和自定义模型开发。
其他企业也可以此为参考,通过Amazon Nitro构建出拥有特定级别算力、符合自身需求的虚拟化集群,用于落地自身的生成式AI需求应用。

作为全球最大的云服务商,亚马逊云科技拥有遍及全球的基础设施,能够通过各种硬件和实例,满足企业客户不同需求。本次re:Invent 2023大会上,亚马逊云科技所推出的硬件、芯片等基础设施的创新,相信能够进一步提升基础设施的性能,从算力角度重构云计算,帮助企业用户快速进入生成式AI新时代。
点击“阅读原文”,一链速看亚马逊云科技 re:Invent 2023 所有热门发布!

申耀的科技观察,由资深科技媒体人申斯基创办,20年企业级科技内容传播工作经验,长期专注产业互联网、企业数字化、ICT基础设施、汽车科技等内容的观察和思考。
