时间复杂度分析

- 常数时间复杂度 O(1) 的示例:
def print_first_element(arr):
print(arr[0])
# 无论 arr 的大小如何,执行时间都是恒定的,因此具有常数时间复杂度。
- 线性时间复杂度 O(n) 的示例:
def print_all_elements(arr):
for element in arr:
print(element)
# 当输入数组 arr 大小为 n 时,需要执行 n 次循环,因此具有线性时间复杂度。
- 对数时间复杂度 O(log n) 的示例:
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
# 在有序数组 arr 中进行二分查找,每次迭代都把搜索范围减半,因此具有对数时间复杂度。
- 平方级时间复杂度 O(n^2) 的示例:
def print_pairs(arr):
for i in range(len(arr)):
for j in range(len(arr)):
print(arr[i], arr[j])
# 当输入数组 arr 大小为 n 时,嵌套循环导致总共执行 n^2 次操作,因此具有平方级时间复杂度。
时间复杂度是一种衡量算法执行时间随输入规模增长而变化的度量。它描述了算法运行所需的操作数量,通常使用大O符号表示。
在进行时间复杂度分析时,我们通常关注最坏情况下的运行时间。以下是一些常见的时间复杂度及其对应的算法执行时间增长速度:
-
常数时间复杂度:O(1)
算法的执行时间与输入规模无关,始终保持恒定。例如,访问数组中的元素或执行简单的数学运算。 -
线性时间复杂度:O(n)
算法的执行时间与输入规模成线性关系。例如,遍历一个数组或列表中的所有元素。 -
对数时间复杂度:O(log n)
算法的执行时间随着输入规模的增加而增加,但增长速度较慢。例如,二分查找算法。 -
线性对数时间复杂度:O(n log n)
算法的执行时间介于线性和平方级时间复杂度之间。常见的例子是快速排序和归并排序等排序算法。 -
平方级时间复杂度:O(n^2)
算法的执行时间与输入规模的平方成正比。例如,嵌套循环遍历一个二维数组。 -
指数时间复杂度:O(2^n)
算法的执行时间呈指数级增长,通常是由于使用了递归或穷举所有可能的解。这种复杂度的算法在实际应用中往往不可接受。
顺序表的表示

利用动态数组来表示顺序表:
#include <stdio.h>
#include <stdlib.h>
// 定义顺序表结构体
typedef struct {
int *data; // 存储元素的数组指针
int capacity; // 顺序表的容量
int size; // 当前顺序表中元素的个数
} ArrayList;
// 初始化顺序表
void init(ArrayList *list, int capacity) {
list->data = (int *)malloc(sizeof(int) * capacity);
if (!list->data) {
printf("Memory allocation failed\n");
exit(1);
}
list->capacity = capacity;
list->size = 0;
}
// 判断顺序表是否为空
int is_empty(ArrayList *list) {
return list->size == 0;
}
// 获取顺序表的长度
int length(ArrayList *list) {
return list->size;
}
// 获取指定位置的元素
int get(ArrayList *list, int index) {
if (index < 0 || index >= list->size) {
printf("Index out of range\n");
exit(1);
}
return list->data[index];
}
// 向顺序表插入元素
void insert(ArrayList *list, int index, int value) {
if (index < 0 || index > list->size) {
printf("Index out of range\n");
exit(1);
}
if (list->size == list->capacity) {
printf("ArrayList is full\n");
exit(1);
}
for (int i = list->size - 1; i >= index; i--) {
list->data[i + 1] = list->data[i];
}
list->data[index] = value;
list->size++;
}
// 从顺序表删除元素
void remove_at(ArrayList *list, int index) {
if (index < 0 || index >= list->size) {
printf("Index out of range\n");
exit(1);
}
for (int i = index; i < list->size - 1; i++) {
list->data[i] = list->data[i + 1];
}
list->size--;
}
// 释放顺序表所占用的内存
void destroy(ArrayList *list) {
free(list->data);
list->data = NULL;
list->capacity = 0;
list->size = 0;
}
int main() {
ArrayList list;
init(&list, 10);
insert(&list, 0, 1);
insert(&list, 1, 2);
insert(&list, 2, 3);
printf("%d\n", get(&list, 0)); // 输出:1
remove_at(&list, 0);
for (int i = 0; i < length(&list); i++) {
printf("%d ", get(&list, i)); // 输出:2 3
}
destroy(&list);
return 0;
}
上述示例代码使用C语言实现了一个简单的顺序表,包括了初始化、判断是否为空、获取长度、获取指定位置的元素、插入元素、删除元素和释放内存等基本操作。
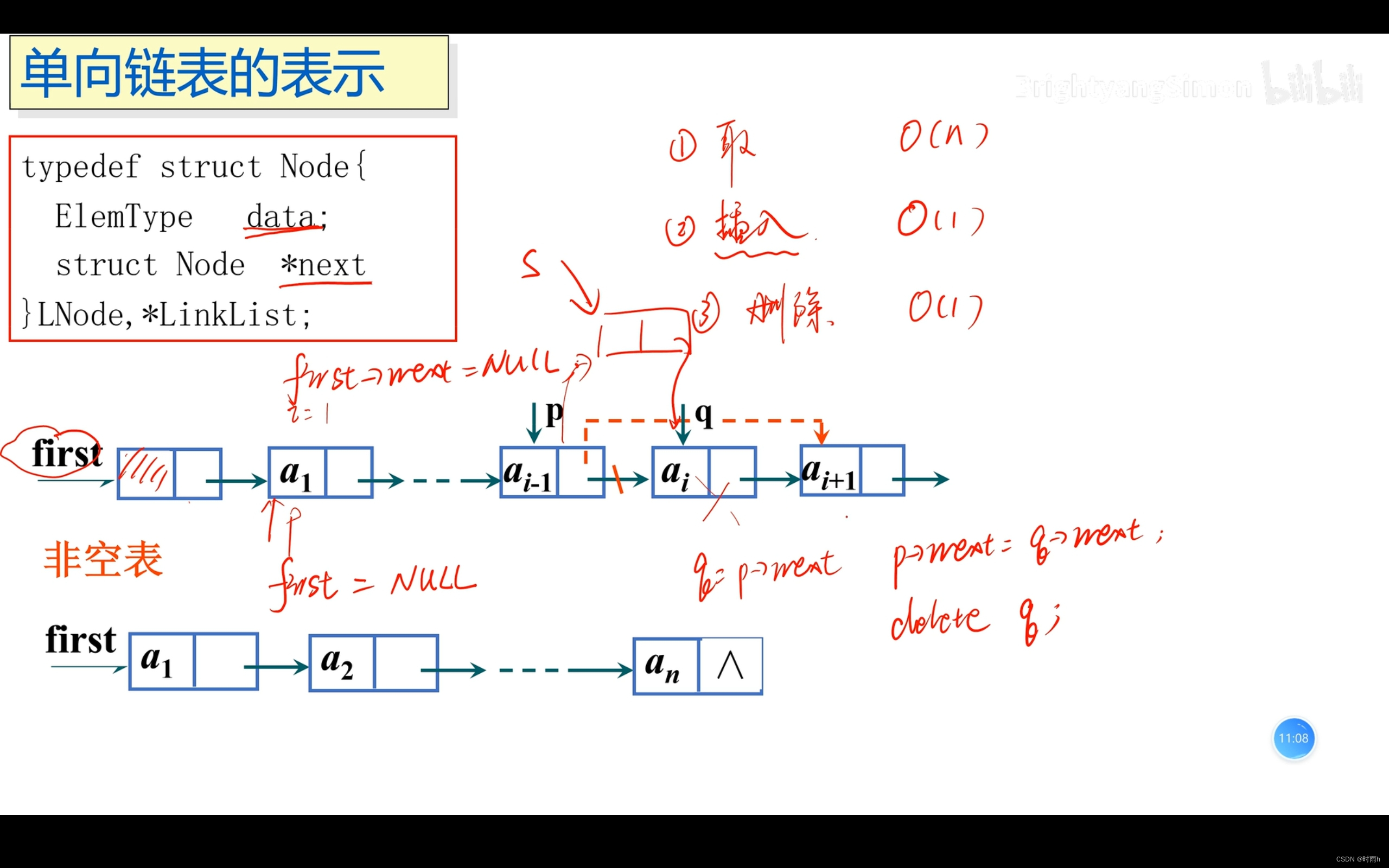
线性表是一种常见的数据结构,用于存储一组具有线性关系的数据元素。它的特点是元素之间存在一个确定的顺序,并且每个元素都有唯一的前驱和后继(除了第一个元素没有前驱,最后一个元素没有后继)。
线性表的简单表示可以使用顺序存储和链式存储两种方式。
- 顺序存储:
顺序存储是将线性表的元素按照其逻辑顺序依次存储在一块连续的内存空间中。在C语言中,可以使用数组来实现顺序存储的线性表。通过定义一个数组来存储元素,再使用一个变量记录线性表的长度即可。
顺序存储的优点是元素访问速度快,可以通过下标直接访问元素;缺点是插入和删除操作需要移动大量元素,效率较低。
- 链式存储:
链式存储是通过指针将线性表的元素按照其逻辑顺序链接起来。在C语言中,可以使用结构体和指针来实现链式存储的线性表。每个结点包含一个数据域和一个指向下一个结点的指针。
链式存储的优点是插入和删除操作只需修改指针,效率较高;缺点是访问元素需要从头结点开始遍历,效率较低。
线性表的操作包括初始化、插入、删除、查找等。具体实现可以根据不同的存储方式进行相应的操作。
顺序存储的线性表操作:
- 初始化:将线性表的长度置为0,即空表状态。
- 插入:在指定位置插入元素时,需要将插入位置后面的元素依次后移,然后将新元素放入插入位置。
- 删除:删除指定位置的元素时,需要将删除位置后面的元素依次前移。
- 查找:根据下标直接访问元素。
链式存储的线性表操作:
- 初始化:创建一个头结点,并将头指针指向头结点。
- 插入:找到插入位置的前一个结点,修改指针连接。
- 删除:找到要删除的结点的前一个结点,修改指针连接。
- 查找:从头结点开始遍历链表,直到找到目标元素或到达链尾。
线性表作为基本数据结构,广泛应用于各个领域的算法和程序设计中,如数组、链表、队列、栈等都是基于线性表的扩展或变种结构。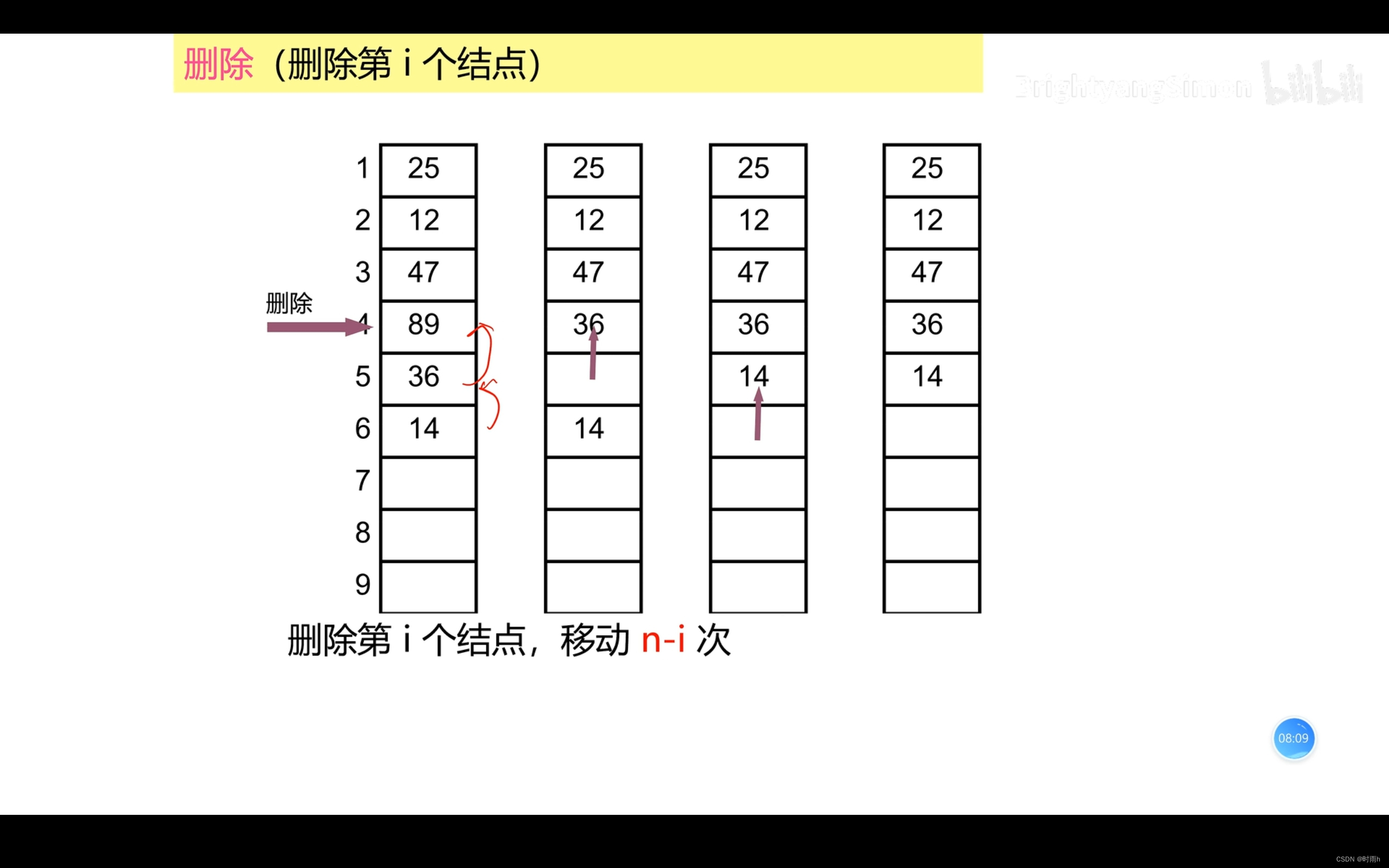
删除第i个结点,移动n-i次
单向链表的表示
#include <stdio.h>
#include <stdlib.h>
// 定义链表节点结构体
struct Node {
int data; // 数据
struct Node* next; // 指向下一个节点的指针
};
// 创建新节点
struct Node* createNode(int data) {
// 分配内存以存储新节点
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
// 设置新节点的数据字段
newNode->data = data;
// 将新节点的next指针初始化为NULL,因为它是最后一个节点
newNode->next = NULL;
// 返回新节点的指针
return newNode;
}
// 向链表末尾添加节点
void append(struct Node** headRef, int data) {
// 创建新节点
struct Node* newNode = createNode(data);
// 如果链表为空,将新节点作为头节点
if (*headRef == NULL) {
*headRef = newNode;
return;
}
// 遍历链表,找到最后一个节点
struct Node* current = *headRef;
while (current->next != NULL) {
current = current->next;
}
// 在最后一个节点后面添加新节点
current->next = newNode;
}
// 打印链表
void printList(struct Node* node) {
// 遍历链表并打印节点的数据
while (node != NULL) {
printf("%d ", node->data);
node = node->next; // 移动到下一个节点
}
printf("\n");
}
int main() {
// 初始化链表头节点
struct Node* head = NULL;
// 向链表中添加节点
append(&head, 1);
append(&head, 2);
append(&head, 3);
// 打印链表
printf("链表内容:");
printList(head);
return 0;
}
双向链表的插入
双向链表是一种常见的链表数据结构,它与单向链表相比具有更多的灵活性和功能。
在双向链表中,每个节点都包含两个指针字段:一个指向前一个节点的指针(prev)和一个指向后一个节点的指针(next)。这样的设计使得我们可以从任意方向遍历链表,即可以从头节点向后遍历,也可以从尾节点向前遍历。
与单向链表不同,双向链表在插入和删除节点时更加方便。在单向链表中,要删除一个节点,我们需要找到其前一个节点并更新其指针,但在双向链表中,我们只需要修改前一个节点和后一个节点的指针,不需要进行额外的查找操作。
双向链表的基本操作包括:
-
创建新节点:创建一个新的节点,并将给定的数据存储在该节点中。同时,初始化前一个节点和后一个节点的指针为NULL。
-
在链表头部插入节点:将一个新节点插入到链表的头部。如果链表为空,新节点就成为头节点。否则,我们将新节点的next指针指向当前的头节点,并将当前头节点的prev指针指向新节点,最后更新头节点指针。
-
在链表尾部插入节点:将一个新节点插入到链表的尾部。如果链表为空,新节点就成为头节点。否则,我们遍历链表直到最后一个节点,然后将新节点插入到最后一个节点的后面。
-
在指定位置插入节点:在链表的指定位置插入一个新节点。如果位置小于1或者链表为空且位置大于1,则插入无效。如果位置为1,新节点成为新的头节点。否则,我们遍历链表直到找到指定位置的前一个节点,然后更新指针以插入新节点。
-
删除节点:从链表中删除指定的节点。我们只需要修改前一个节点和后一个节点的指针,无需进行额外的查找操作。
-
遍历链表:从头节点开始遍历整个链表,并访问每个节点的数据。
双向链表通过包含前一个节点和后一个节点的指针,提供了更多的灵活性和功能。它允许从任意方向遍历链表,同时在插入和删除节点时也更加方便。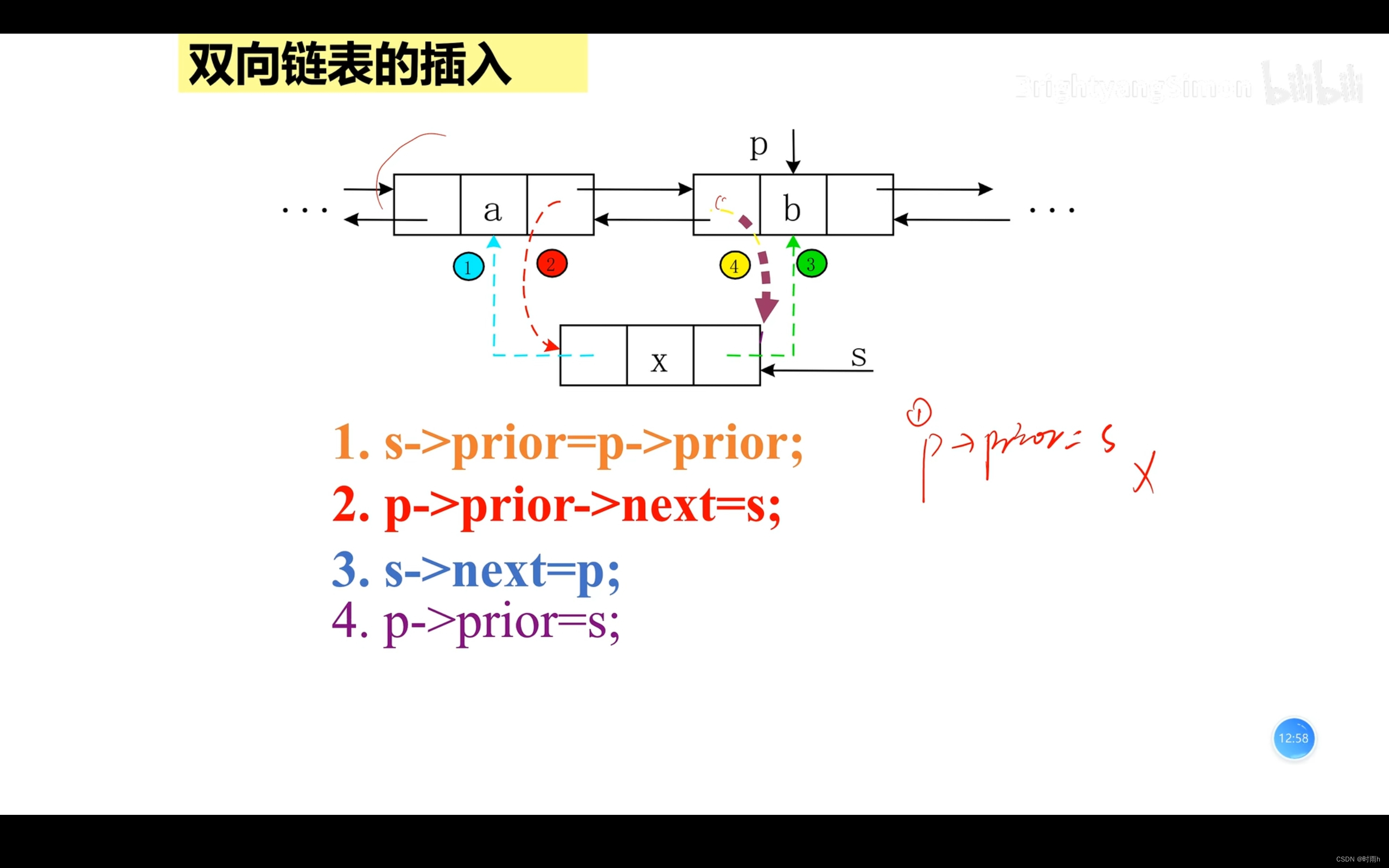
当涉及到双向链表时,我们需要使用一个包含两个指针字段的节点结构体。每个节点都有一个指向前一个节点的指针(prev)和一个指向后一个节点的指针(next)。
下面是代码中使用的节点结构体定义:
struct Node {
int data; // 数据
struct Node* prev; // 指向前一个节点的指针
struct Node* next; // 指向后一个节点的指针
};
接下来,我们需要实现一些基本操作来操作双向链表。
- 创建新节点:
createNode()函数用于创建一个新的节点,并将给定的数据存储在该节点中。这个函数返回新节点的指针。
struct Node* createNode(int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->prev = NULL;
newNode->next = NULL;
return newNode;
}
- 在双向链表头部插入节点:
insertAtBeginning()函数用于在双向链表的头部插入一个新节点。如果链表为空,新节点就成为头节点。否则,新节点将前一个节点的指针指向它,然后更新头节点指针。
void insertAtBeginning(struct Node** headRef, int data) {
struct Node* newNode = createNode(data);
if (*headRef == NULL) {
*headRef = newNode;
return;
}
(*headRef)->prev = newNode;
newNode->next = *headRef;
*headRef = newNode;
}
- 在双向链表尾部插入节点:
insertAtEnd()函数用于在双向链表的尾部插入一个新节点。如果链表为空,新节点就成为头节点。否则,我们遍历链表直到最后一个节点,并将新节点插入到最后一个节点的后面。
void insertAtEnd(struct Node** headRef, int data) {
struct Node* newNode = createNode(data);
if (*headRef == NULL) {
*headRef = newNode;
return;
}
struct Node* current = *headRef;
while (current->next != NULL) {
current = current->next;
}
current->next = newNode;
newNode->prev = current;
}
- 在双向链表中指定位置插入节点:
insertAtPosition()函数用于在双向链表的指定位置插入一个新节点。如果位置小于1或者链表为空且位置大于1,则插入无效。如果位置为1,新节点成为新的头节点。否则,我们遍历链表直到找到指定位置的前一个节点,然后更新指针以插入新节点。
void insertAtPosition(struct Node** headRef, int pos, int data) {
if (pos < 1) {
printf("无效的插入位置\n");
return;
}
struct Node* newNode = createNode(data);
if (*headRef == NULL && pos > 1) {
printf("无效的插入位置\n");
return;
}
if (pos == 1) {
(*headRef)->prev = newNode;
newNode->next = *headRef;
*headRef = newNode;
return;
}
struct Node* current = *headRef;
int i = 1;
while (i < pos - 1 && current != NULL) {
current = current->next;
i++;
}
if (current == NULL) {
printf("无效的插入位置\n");
return;
}
newNode->prev = current;
newNode->next = current->next;
if (current->next != NULL) {
current->next->prev = newNode;
}
current->next = newNode;
}
- 打印双向链表:
printList()函数用于遍历并打印整个双向链表。
void printList(struct Node* node) {
while (node != NULL) {
printf("%d ", node->data);
node = node->next;
}
printf("\n");
}
在 main() 函数中,我们演示了如何使用上述函数来创建双向链表并插入节点。然后通过调用 printList() 函数来打印链表的内容。
这些操作使得双向链表具有灵活性,可以从头部、尾部或指定位置插入节点,而不需要像单向链表那样进行大量的指针重新连接。同时,我们还可以通过前一个指针轻松地反向遍历链表。

顺序表和链表的比较

顺序表和链表是常见的数据结构,它们各自具有不同的特点和适用场景。下面是顺序表和链表的比较:
-
存储方式:
- 顺序表(Sequential List):顺序表使用一段连续的内存空间来存储元素,通过数组实现。元素在内存中的存储位置是相邻的。
- 链表(Linked List):链表使用离散的内存块来存储元素,通过节点和指针实现。元素在内存中的存储位置可以是分散的。
-
插入和删除操作:
- 顺序表:在顺序表中,插入和删除操作可能需要移动其他元素,以保持元素的顺序性。这可能涉及到大量的数据搬移,尤其是在插入或删除位置靠前的元素时。时间复杂度为O(n)。
- 链表:在链表中,插入和删除操作只需要修改节点的指针,无需移动其他节点。因此,插入和删除的时间复杂度为O(1),即常数时间。
-
随机访问操作:
- 顺序表:由于顺序表的元素在内存中是连续存储的,因此可以通过下标直接访问任意元素。时间复杂度为O(1)。
- 链表:链表的元素在内存中是离散存储的,无法直接通过下标访问元素。必须从头节点开始遍历链表,找到目标节点才能访问。时间复杂度为O(n)。
-
空间效率:
- 顺序表:由于顺序表使用一段连续内存空间存储元素,除了元素本身的空间开销外,还需要额外的空间作为固定大小的数组。如果存储空间不足,需要进行扩容操作。因此,顺序表的空间利用率相对较低。
- 链表:链表的节点之间通过指针相连,没有额外的空间开销,只有节点本身的空间开销。因此,链表的空间利用率相对较高。
根据上述特点,我们可以总结如下:
- 如果需要频繁进行插入和删除操作,且对随机访问性能要求不高,可以选择链表。
- 如果需要频繁进行随机访问操作,或者对空间利用率要求较高,可以选择顺序表。
在实际应用中,根据具体场景的需求和数据操作的频率来选择合适的数据结构。有时候也会结合两者的优势,设计出一些高效的数据结构,如跳表(Skip List)等。
栈
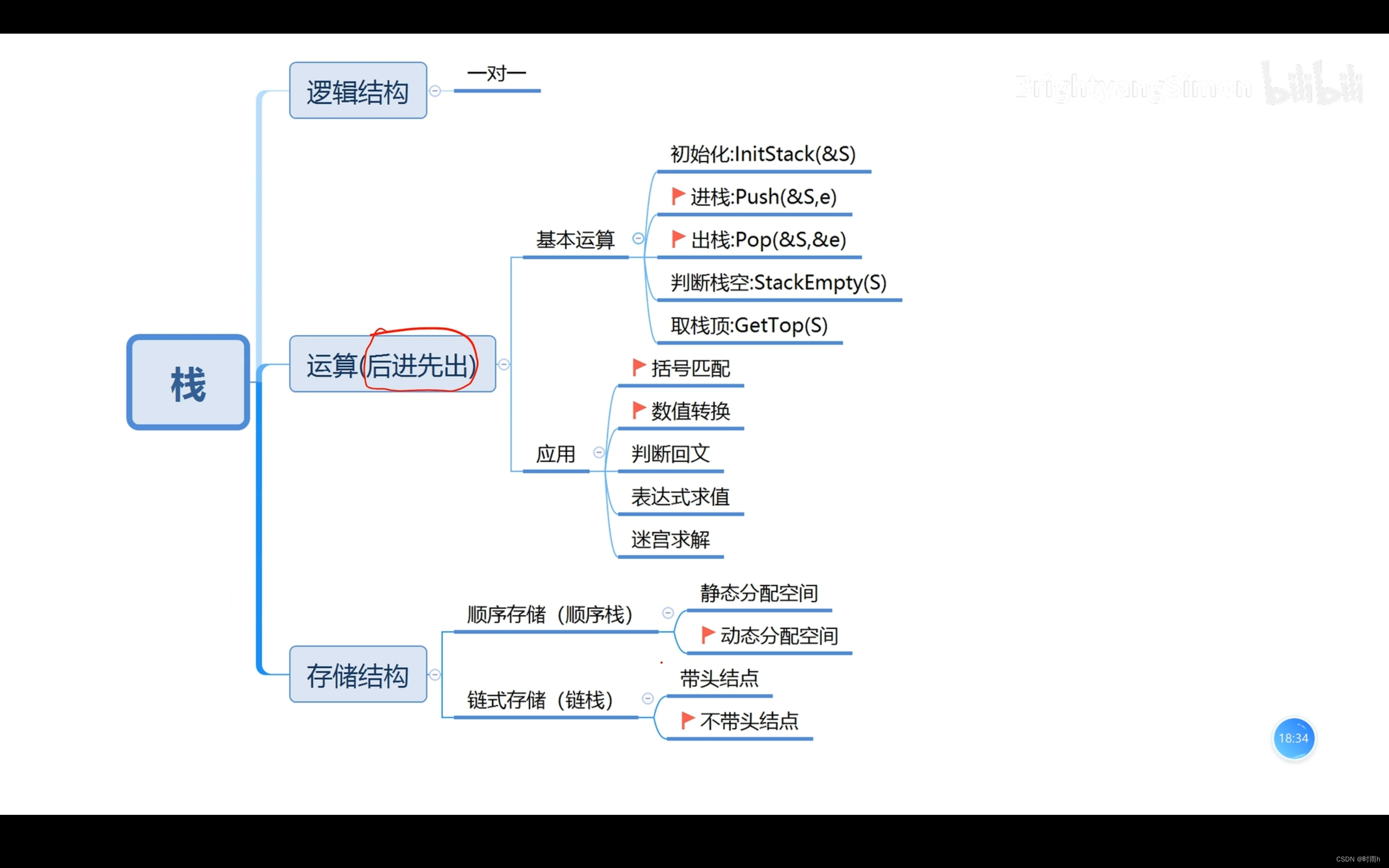
栈(stack)是一种常见的数据结构,它采用“先进后出”的原则。栈可以看作是一个容器,其中的元素只能从栈顶添加或移除,栈底是固定的。
在栈中,元素的插入和删除操作都是在栈顶进行的。当添加元素时,它会被放置在当前栈顶的上方。而当删除元素时,当前栈顶的元素会被移除,并将栈顶指针向下移动一个位置。
栈的基本操作包括:
- 入栈(push):将一个元素添加到栈顶,使其成为新的栈顶元素。
- 出栈(pop):移除当前栈顶的元素,并将栈顶指针向下移动一个位置。
- 取栈顶元素(top):返回当前栈顶的元素,但不修改栈。
- 判空(empty):判断栈是否为空。
- 判满(full):判断栈是否已满(对于固定大小的数组实现的栈来说)。
栈可以使用数组或链表来实现。在数组实现的栈中,需要预先分配一定大小的数组空间。在链表实现的栈中,则不需要预先分配空间。
栈的应用非常广泛,如:
- 编程语言中的函数调用和递归。
- 表达式求值(如中缀表达式转后缀表达式)。
- 系统调用中的操作系统栈,用于存储函数调用和返回地址等信息。
- 浏览器中的“后退”按钮,通过维护一个访问历史记录的栈来实现。
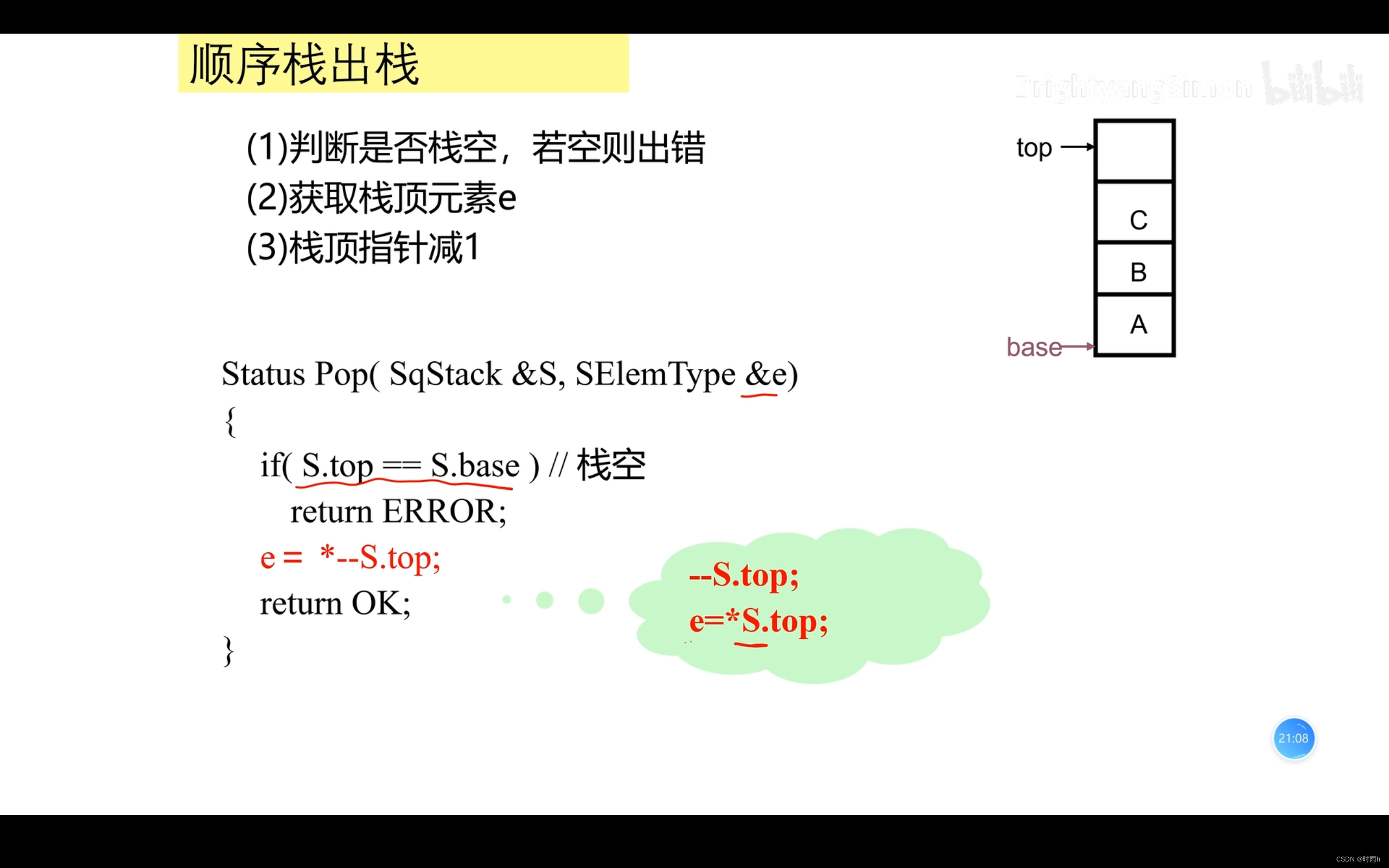
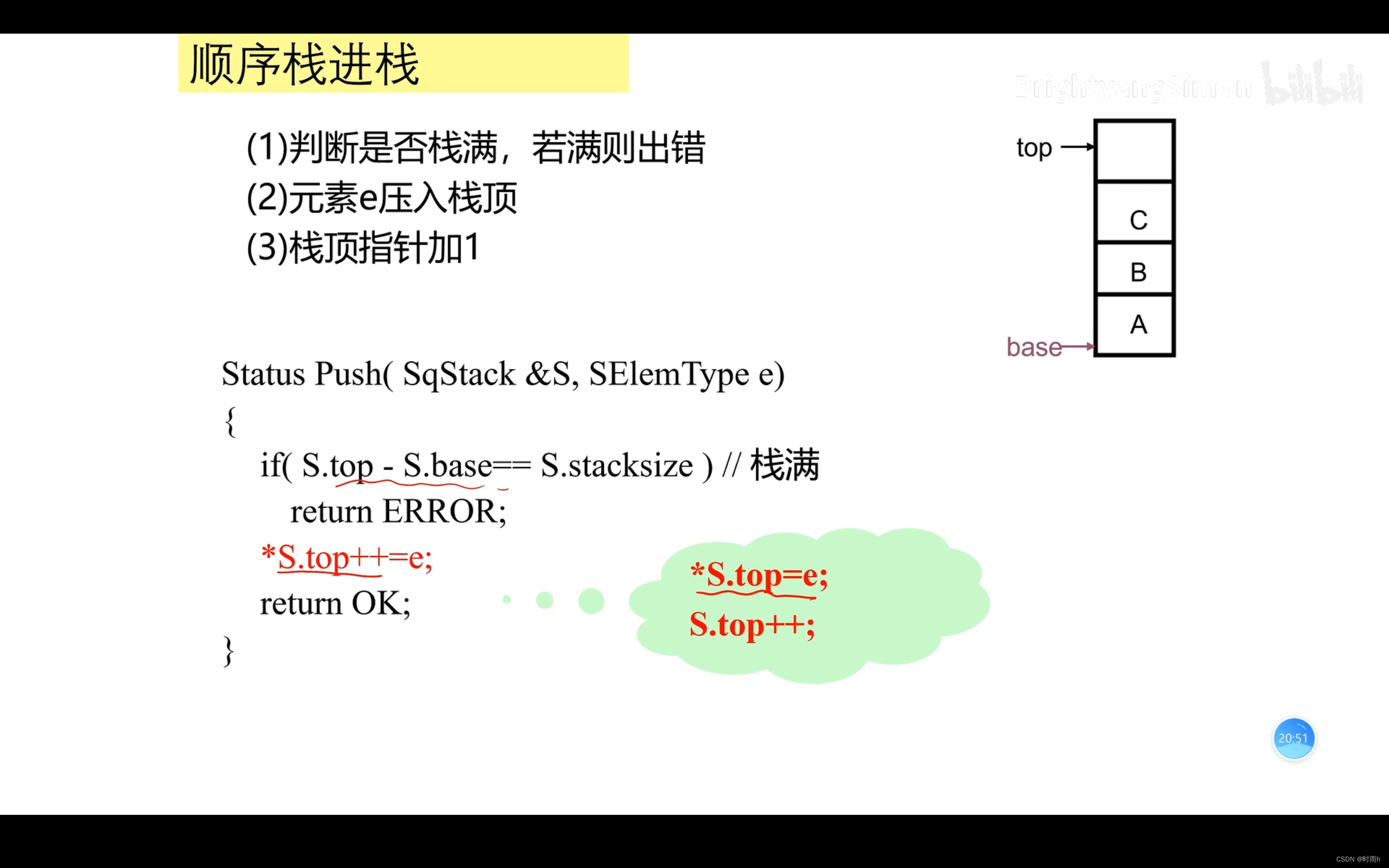
顺序栈的表示
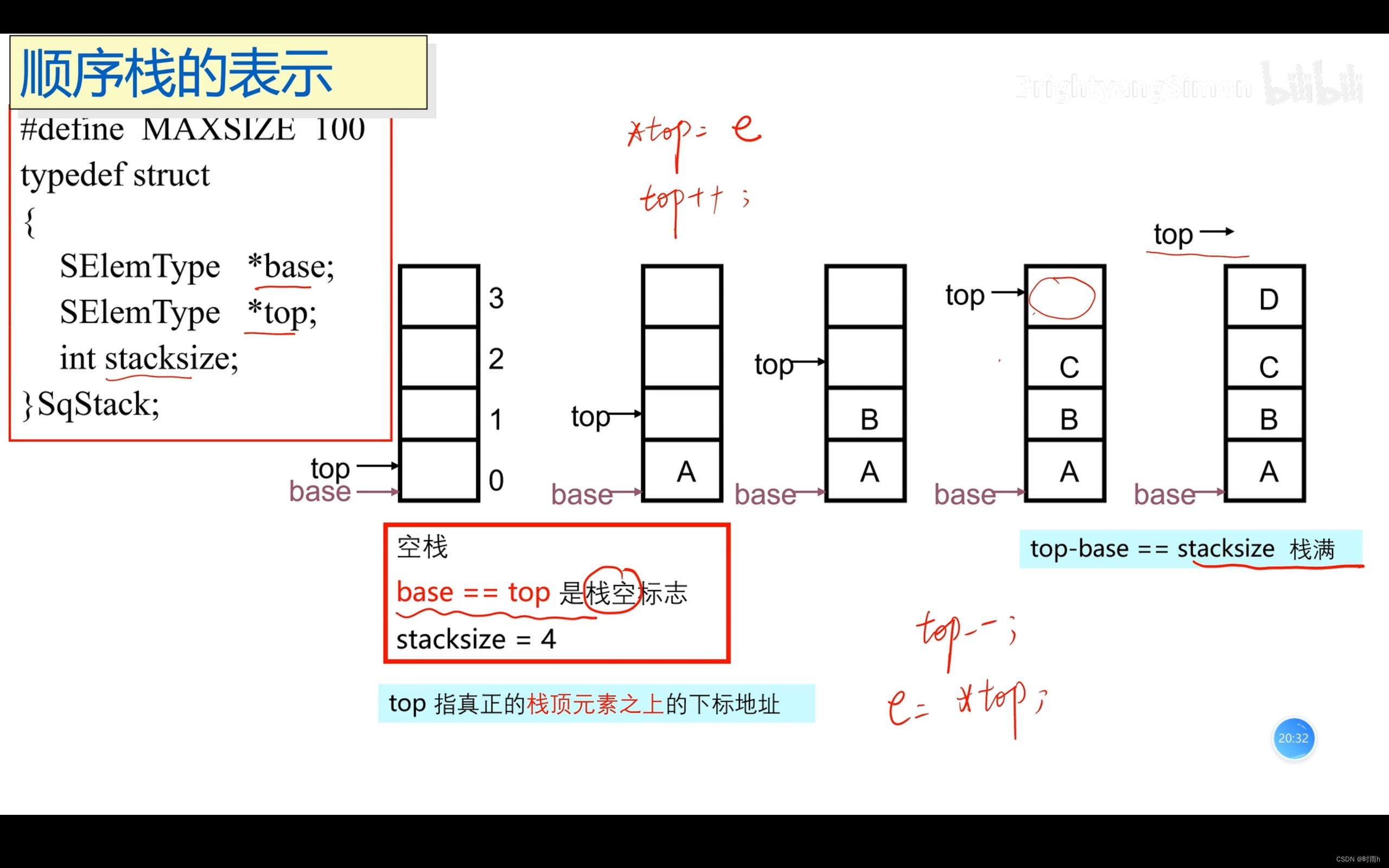
#include <stdio.h>
#include <stdbool.h>
#define MAX_SIZE 100 // 栈的最大容量
typedef struct {
int data[MAX_SIZE]; // 存储栈元素的数组
int top; // 栈顶指针,指向栈顶元素的位置
} Stack;
// 初始化栈
void initStack(Stack *stack) {
stack->top = -1; // 空栈时,栈顶指针为-1
}
// 判断栈是否为空
bool isEmpty(Stack *stack) {
return stack->top == -1;
}
// 判断栈是否已满
bool isFull(Stack *stack) {
return stack->top == MAX_SIZE - 1;
}
// 入栈
void push(Stack *stack, int value) {
if (isFull(stack)) {
printf("Stack is full. Cannot push element.\n");
} else {
stack->top++; // 栈顶指针加1
stack->data[stack->top] = value; // 将元素存入栈顶位置
printf("Element %d pushed to stack.\n", value);
}
}
// 出栈
int pop(Stack *stack) {
if (isEmpty(stack)) {
printf("Stack is empty. Cannot pop element.\n");
return -1; // 返回一个特殊值表示出错或栈为空
} else {
int value = stack->data[stack->top]; // 获取栈顶元素
stack->top--; // 栈顶指针减1,表示栈顶元素已出栈
printf("Element %d popped from stack.\n", value);
return value;
}
}
// 获取栈顶元素
int peek(Stack *stack) {
if (isEmpty(stack)) {
printf("Stack is empty.\n");
return -1; // 返回一个特殊值表示出错或栈为空
} else {
return stack->data[stack->top]; // 返回栈顶元素的值
}
}
// 打印栈中的所有元素
void printStack(Stack *stack) {
if (isEmpty(stack)) {
printf("Stack is empty.\n");
} else {
printf("Stack: ");
for (int i = 0; i <= stack->top; i++) {
printf("%d ", stack->data[i]);
}
printf("\n");
}
}
int main() {
Stack stack;
initStack(&stack); // 初始化栈
push(&stack, 10);
push(&stack, 20);
push(&stack, 30);
printStack(&stack); // 打印栈中的元素
int topElement = peek(&stack); // 获取栈顶元素
printf("Top element: %d\n", topElement);
int poppedElement = pop(&stack); // 出栈
printf("Popped element: %d\n", poppedElement);
printStack(&stack); // 打印栈中的元素
return 0;
}
链栈的表示

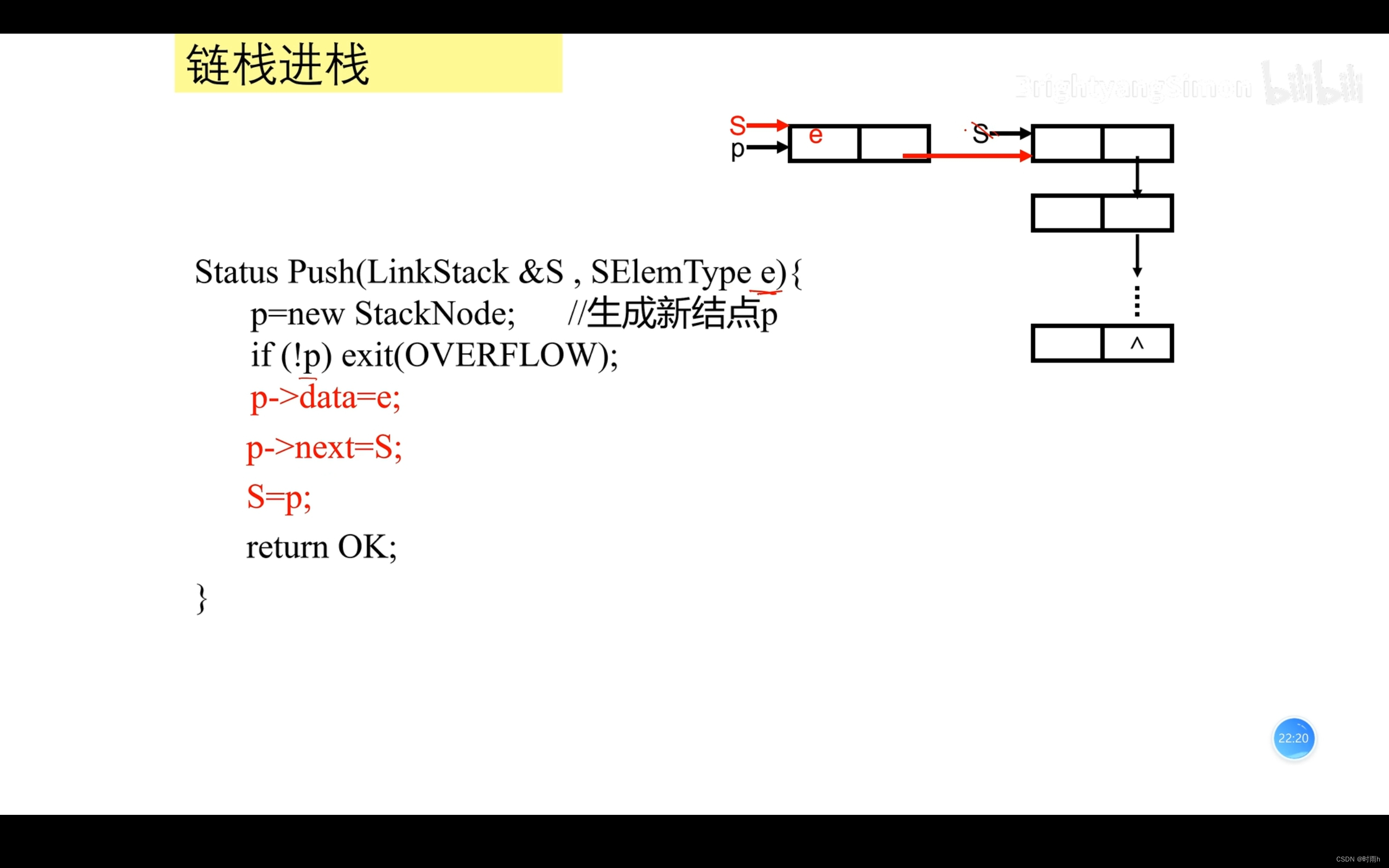
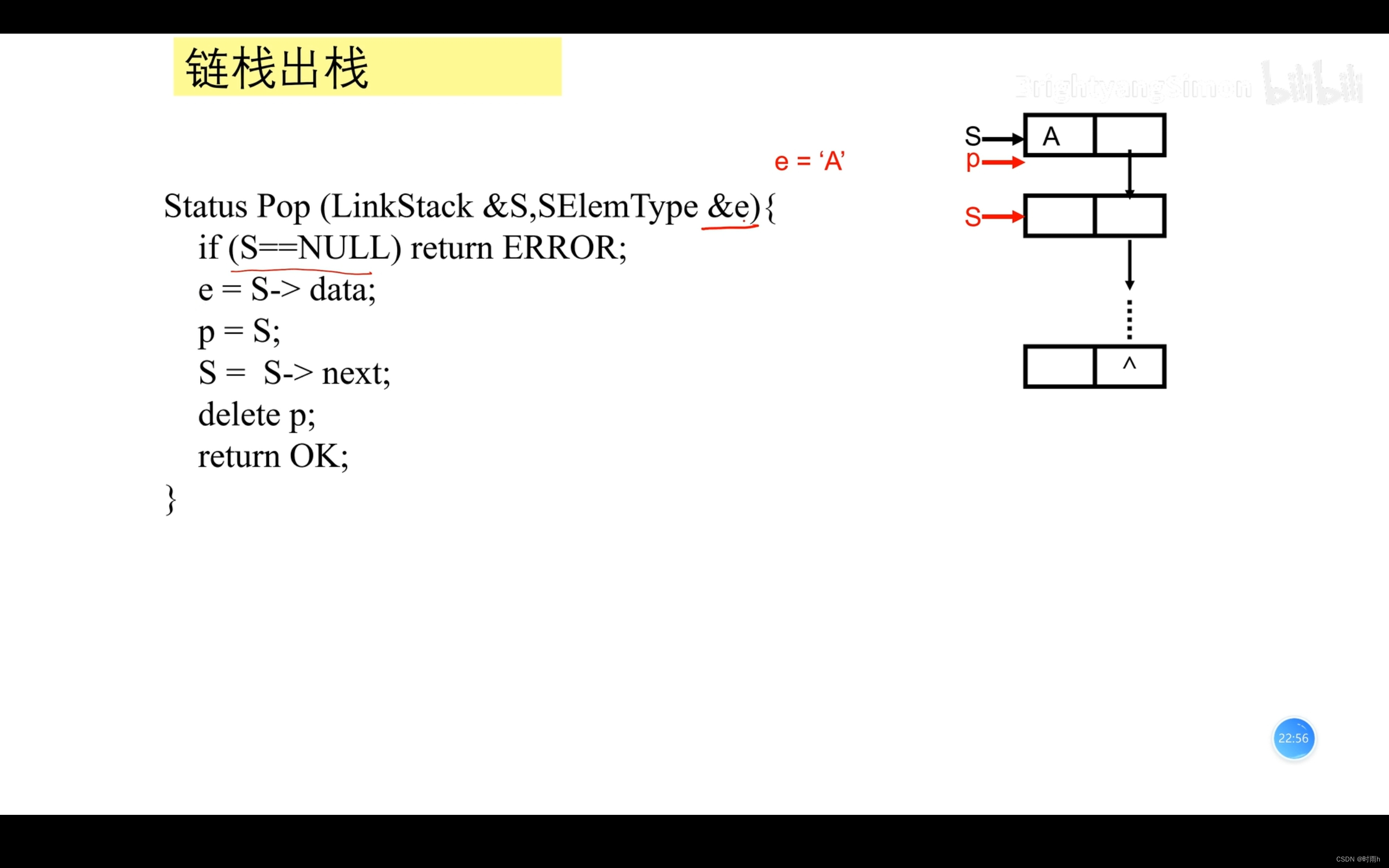
链栈(Linked Stack)是一种使用链表实现的栈结构。与顺序栈相比,链栈没有固定的容量限制,可以根据需要动态地分配和释放内存。
链栈是一种基于链表实现的栈数据结构,它与顺序栈不同,链栈没有固定的容量限制,可以根据需要动态地分配和释放内存。链栈的底层实现是一个链表,因此可以使用指针来实现入栈、出栈等操作。
链栈与顺序栈的主要区别在于存储方式:链栈使用链表存储元素,而顺序栈使用数组存储元素。由于链栈不需要预先分配存储空间,因此它可以动态地增加或减少存储容量,从而更加灵活。
下面是链栈的一些详细讲解:
栈的定义和特点
栈是一种先进后出(LIFO)的数据结构,它具有以下特点:
- 只能在栈顶进行插入和删除操作;
- 最后插入的元素最先被删除,也就是先进后出的原则;
- 栈顶指针指向栈顶元素,一般情况下,栈顶指针初始值为-1。
链栈的定义和实现
链栈是一种基于链表实现的栈数据结构,它的每个节点都包含一个数据域和一个指向下一个节点的指针。链栈的底层实现是一个链表,因此可以使用指针来实现入栈、出栈等操作。
下面是链栈的一些基本操作:
- 初始化链栈:将栈顶指针初始化为空;
- 判断链栈是否为空:栈顶指针为空则说明链栈为空;
- 入栈:创建新节点,将其插入链表头部,更新栈顶指针;
- 出栈:删除链表头部节点,更新栈顶指针;
- 获取栈顶元素:返回栈顶节点的数据域;
- 清空链栈:逐个删除所有节点,释放内存。
链栈的优缺点
链栈相对于顺序栈的优点在于:
- 没有固定的容量限制,可以动态地增加或减少存储容量;
- 插入和删除元素的时间复杂度为O(1),与链表相同。
链栈的缺点在于:
- 需要额外的内存空间来存储指针信息;
- 由于链表的存储方式不连续,可能会导致缓存失效,影响性能。
总体来说,链栈适用于需要频繁进行插入和删除操作、无法确定存储容量大小的情况。在实际应用中,需要根据具体情况选择合适的栈实现方式。
以下是链栈的简单C语言表示,并带有详细注释:
#include <stdio.h>
#include <stdbool.h>
#include <stdlib.h>
typedef struct Node {
int data; // 存储栈元素的值
struct Node* next; // 指向下一个节点的指针
} Node;
typedef struct {
Node* top; // 栈顶指针,指向链栈的头节点
} Stack;
// 初始化链栈
void initStack(Stack* stack) {
stack->top = NULL; // 空栈时,栈顶指针为空
}
// 判断链栈是否为空
bool isEmpty(Stack* stack) {
return stack->top == NULL;
}
// 入栈
void push(Stack* stack, int value) {
Node* newNode = (Node*)malloc(sizeof(Node)); // 创建新节点
if (newNode == NULL) {
printf("Failed to allocate memory for new node.\n");
return;
}
newNode->data = value; // 设置节点的值
newNode->next = stack->top; // 将新节点插入到链栈的头部
stack->top = newNode; // 更新栈顶指针
printf("Element %d pushed to stack.\n", value);
}
// 出栈
int pop(Stack* stack) {
if (isEmpty(stack)) {
printf("Stack is empty. Cannot pop element.\n");
return -1; // 返回一个特殊值表示出错或栈为空
}
int value = stack->top->data; // 获取栈顶节点的值
Node* temp = stack->top; // 临时保存栈顶节点的指针
stack->top = stack->top->next; // 更新栈顶指针,指向下一个节点
free(temp); // 释放原栈顶节点的内存
printf("Element %d popped from stack.\n", value);
return value;
}
// 获取栈顶元素
int peek(Stack* stack) {
if (isEmpty(stack)) {
printf("Stack is empty.\n");
return -1; // 返回一个特殊值表示出错或栈为空
}
return stack->top->data; // 返回栈顶节点的值
}
// 打印链栈中的所有元素
void printStack(Stack* stack) {
if (isEmpty(stack)) {
printf("Stack is empty.\n");
return;
}
printf("Stack: ");
Node* current = stack->top; // 从栈顶开始遍历链栈
while (current != NULL) {
printf("%d ", current->data);
current = current->next; // 移动到下一个节点
}
printf("\n");
}
// 清空链栈
void clearStack(Stack* stack) {
while (!isEmpty(stack)) {
pop(stack); // 逐个出栈,释放内存
}
printf("Stack cleared.\n");
}
int main() {
Stack stack;
initStack(&stack); // 初始化链栈
push(&stack, 10);
push(&stack, 20);
push(&stack, 30);
printStack(&stack); // 打印链栈中的元素
int topElement = peek(&stack); // 获取栈顶元素
printf("Top element: %d\n", topElement);
int poppedElement = pop(&stack); // 出栈
printf("Popped element: %d\n", poppedElement);
printStack(&stack); // 打印链栈中的元素
clearStack(&stack); // 清空链栈
return 0;
}
这段代码实现了一个简单的链栈,其中使用了两个结构体:Node表示链栈的节点,包含一个存储栈元素值的data和一个指向下一个节点的指针next;Stack表示链栈,包含一个指向链栈头节点的指针top。
具体的操作包括初始化链栈、判断链栈是否为空、入栈、出栈、获取栈顶元素、打印链栈中的所有元素以及清空链栈。
在main函数中,首先初始化了一个链栈stack,然后依次进行入栈、打印链栈、获取栈顶元素、出栈、再次打印链栈以及清空链栈的操作。
队列
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 100
typedef struct {
int data[MAX_SIZE]; // 队列的存储空间
int front; // 队头指针
int rear; // 队尾指针
} Queue;
// 初始化队列
Queue* initQueue() {
Queue* queue = (Queue*)malloc(sizeof(Queue));
queue->front = 0; // 初始化队头指针为 0
queue->rear = 0; // 初始化队尾指针为 0
return queue;
}
// 入队操作
void enqueue(Queue* queue, int item) {
if ((queue->rear + 1) % MAX_SIZE == queue->front) {
printf("Queue is full.\n");
return;
}
queue->data[queue->rear] = item; // 将元素存入队尾
queue->rear = (queue->rear + 1) % MAX_SIZE; // 更新队尾指针
}
// 出队操作
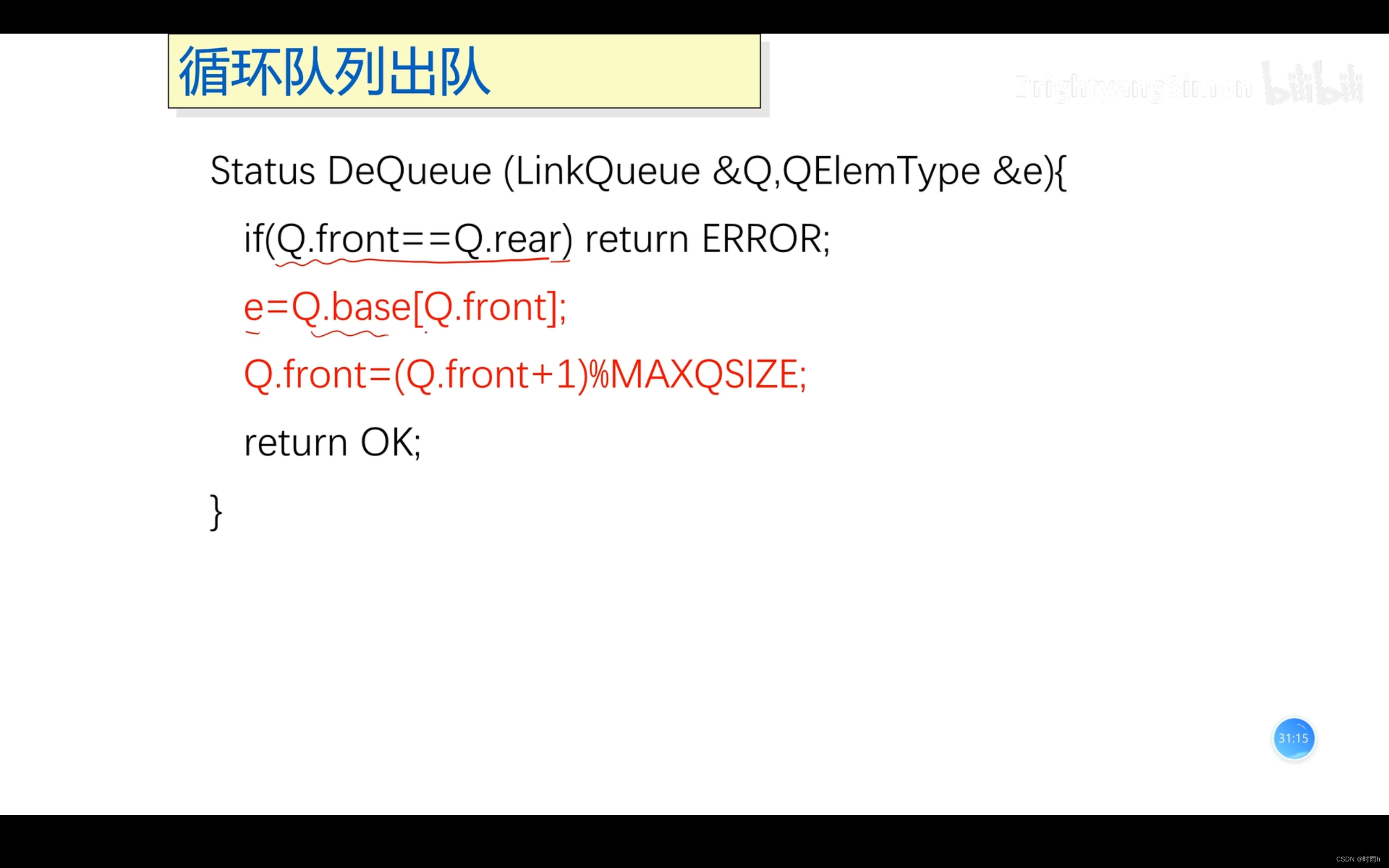
int dequeue(Queue* queue) {
if (queue->front == queue->rear) {
printf("Queue is empty.\n");
return -1;
}
int item = queue->data[queue->front]; // 获取队头元素
queue->front = (queue->front + 1) % MAX_SIZE; // 更新队头指针
return item;
}
// 获取队头元素
int getFront(Queue* queue) {
if (queue->front == queue->rear) {
printf("Queue is empty.\n");
return -1;
}
return queue->data[queue->front];
}
// 判断队列是否为空
int isEmpty(Queue* queue) {
return queue->front == queue->rear;
}
int main() {
Queue* queue = initQueue(); // 初始化队列
enqueue(queue, 1); // 入队操作
enqueue(queue, 2);
enqueue(queue, 3);
printf("Front of the queue: %d\n", getFront(queue)); // 获取队头元素
while (!isEmpty(queue)) {
// 遍历并出队
int item = dequeue(queue);
printf("Dequeued item: %d\n", item);
}
return 0;
}
上述代码中,我们使用数组实现了一个循环队列。队列的存储空间是一个固定大小的数组 data,front 和 rear 分别表示队头和队尾指针。
在入队操作中,我们首先检查队列是否已满,如果满了则打印错误信息并返回;否则,将元素存入队尾,并更新队尾指针。由于是循环队列,所以我们使用取模运算 (queue->rear + 1) % MAX_SIZE 来实现环形存储。
在出队操作中,我们首先检查队列是否为空,如果为空则打印错误信息并返回;否则,获取队头元素,更新队头指针,并返回出队的元素。
获取队头元素和判断队列是否为空的操作比较简单,只需要进行相应的判断即可。
在 main 函数中,我们通过调用上述函数来演示队列的基本操作。首先初始化队列,然后进行入队操作,并获取队头元素。最后,在队列不为空的情况下,遍历并出队元素。
链队列
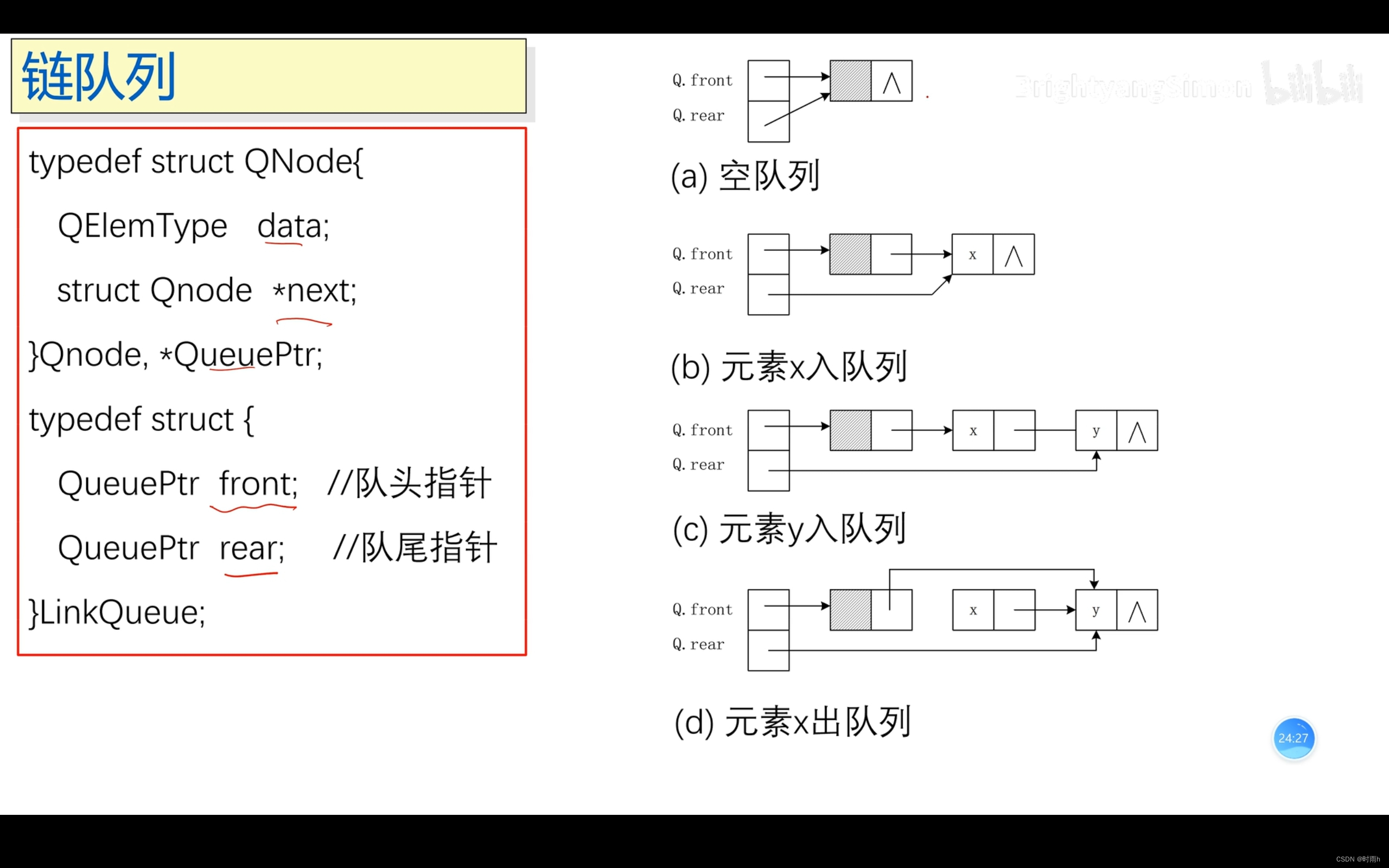

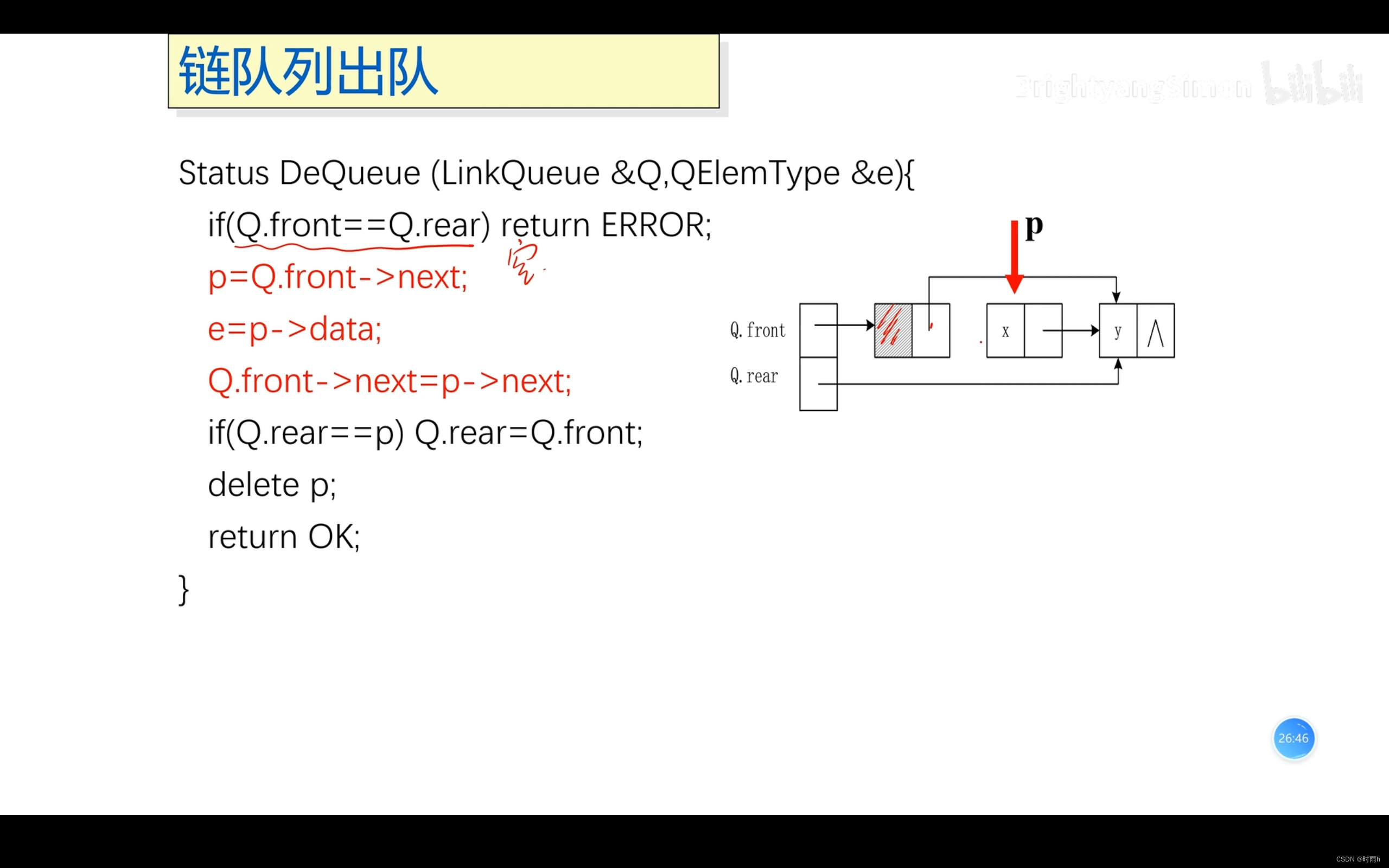
链队列是使用链表实现的队列,相比数组实现的队列,链队列在插入和删除操作时不需要移动元素,具有更好的灵活性和效率。
#include <stdio.h>
#include <stdlib.h>
typedef struct Node {
int data;
struct Node* next;
} Node;
typedef struct {
Node* front; // 队头指针
Node* rear; // 队尾指针
} Queue;
// 初始化队列
Queue* initQueue() {
Queue* queue = (Queue*)malloc(sizeof(Queue));
queue->front = NULL; // 初始化队头指针为空
queue->rear = NULL; // 初始化队尾指针为空
return queue;
}
// 入队操作
void enqueue(Queue* queue, int item) {
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = item;
newNode->next = NULL;
if (queue->rear == NULL) {
// 如果队列为空
queue->front = newNode;
queue->rear = newNode;
} else {
queue->rear->next = newNode; // 将新节点挂在队尾
queue->rear = newNode; // 更新队尾指针
}
}
// 出队操作
int dequeue(Queue* queue) {
if (queue->front == NULL) {
printf("Queue is empty.\n");
return -1;
}
int item = queue->front->data; // 获取队头元素
Node* temp = queue->front;
queue->front = queue->front->next; // 更新队头指针
if (queue->front == NULL) {
// 如果队列已空
queue->rear = NULL;
}
free(temp); // 释放原队头节点的内存
return item;
}
// 获取队头元素
int getFront(Queue* queue) {
if (queue->front == NULL) {
printf("Queue is empty.\n");
return -1;
}
return queue->front->data;
}
// 判断队列是否为空
int isEmpty(Queue* queue) {
return queue->front == NULL;
}
int main() {
Queue* queue = initQueue(); // 初始化队列
enqueue(queue, 1); // 入队操作
enqueue(queue, 2);
enqueue(queue, 3);
printf("Front of the queue: %d\n", getFront(queue)); // 获取队头元素
while (!isEmpty(queue)) {
// 遍历并出队
int item = dequeue(queue);
printf("Dequeued item: %d\n", item);
}
return 0;
}
在上述代码中,我们使用链表实现了一个队列。队列的每个元素都用一个 Node 结构表示,包含数据和指向下一个节点的指针。
在入队操作中,我们创建一个新的节点,将其插入到队列的末尾,并更新队尾指针。如果队列为空,则同时更新队头指针和队尾指针。
在出队操作中,我们首先检查队列是否为空,如果为空则打印错误信息并返回;否则,获取队头元素,更新队头指针,并释放原队头节点的内存。在更新队头指针后,如果队列已经为空,则同时更新队尾指针。
获取队头元素和判断队列是否为空的操作与数组实现的队列类似,只需要进行相应的判断即可。
在 main 函数中,我们通过调用上述函数来演示链队列的基本操作。首先初始化队列,然后进行入队操作,并获取队头元素。最后,在队列不为空的情况下,遍历并出队元素。
链队列相比数组实现的队列更加灵活,可以根据实际需求动态分配内存,但在某些情况下可能会牺牲一定的存储效率。
队列的顺序表示
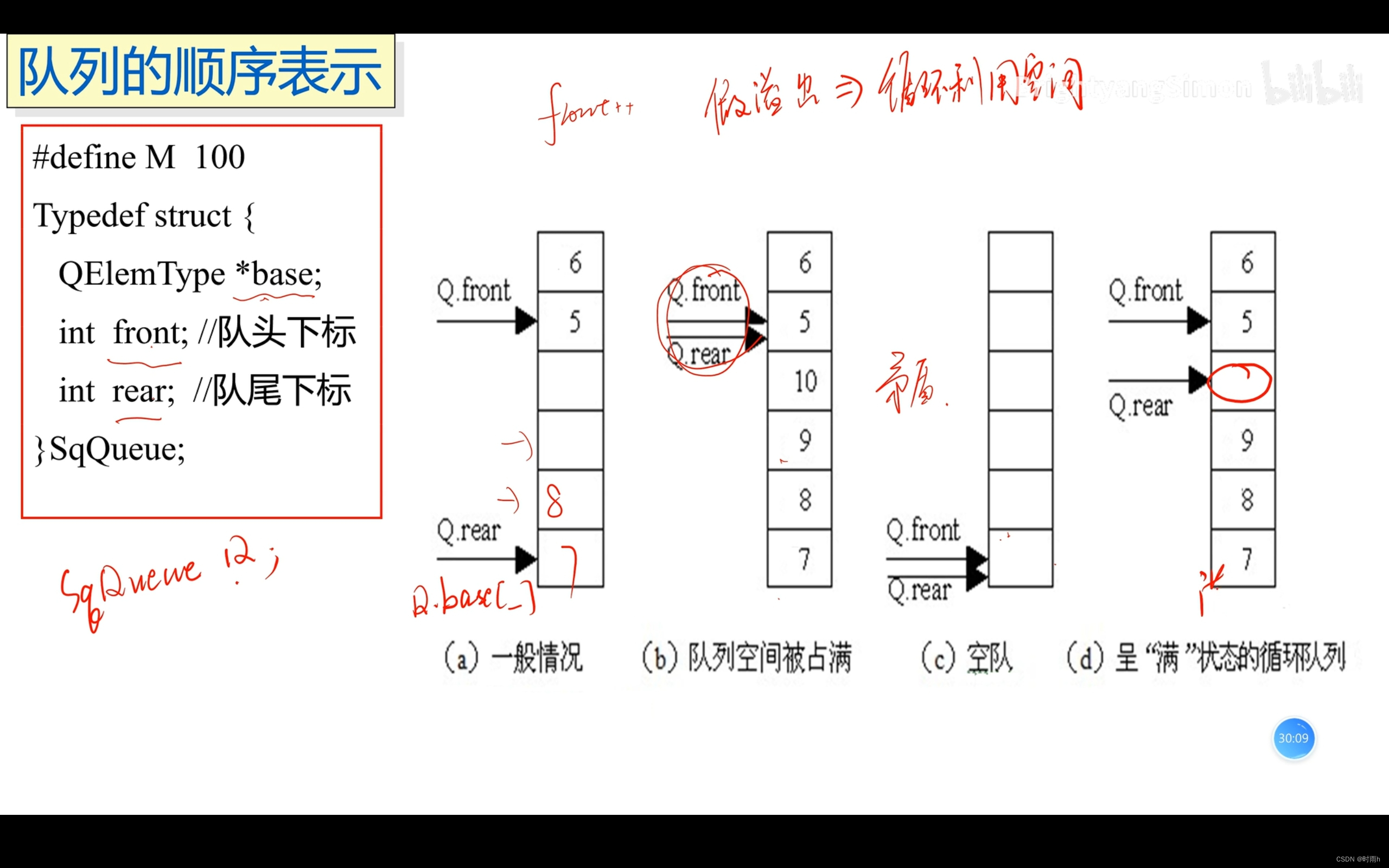
队列的顺序表示是使用数组来实现队列的一种方式。与链队列不同,顺序队列使用数组来存储队列元素,并使用两个指针来记录队头和队尾的位置。

#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 100
typedef struct {
int data[MAX_SIZE];
int front; // 队头指针
int rear; // 队尾指针
} Queue;
// 初始化队列
void initQueue(Queue* queue) {
queue->front = -1; // 初始化队头指针为-1
queue->rear = -1; // 初始化队尾指针为-1
}
// 入队操作
void enqueue(Queue* queue, int item) {
if (queue->rear == MAX_SIZE - 1) {
// 队列已满
printf("Queue is full.\n");
return;
}
queue->rear++; // 队尾指针后移
queue->data[queue->rear] = item; // 将新元素存入队尾
if (queue->front == -1) {
// 如果队列为空
queue->front = 0; // 更新队头指针为0
}
}
// 出队操作
int dequeue(Queue* queue) {
if (queue->front == -1) {
// 队列为空
printf("Queue is empty.\n");
return -1;
}
int item = queue->data[queue->front]; // 获取队头元素
if (queue->front == queue->rear) {
// 如果队列只有一个元素
queue->front = -1; // 重置队头指针
queue->rear = -1; // 重置队尾指针
} else {
queue->front++; // 队头指针后移
}
return item;
}
// 获取队头元素
int getFront(Queue* queue) {
if (queue->front == -1) {
// 队列为空
printf("Queue is empty.\n");
return -1;
}
return queue->data[queue->front];
}
// 判断队列是否为空
int isEmpty(Queue* queue) {
return queue->front == -1;
}
int main() {
Queue queue;
initQueue(&queue); // 初始化队列
enqueue(&queue, 1); // 入队操作
enqueue(&queue, 2);
enqueue(&queue, 3);
printf("Front of the queue: %d\n", getFront(&queue)); // 获取队头元素
while (!isEmpty(&queue)) {
// 遍历并出队
int item = dequeue(&queue);
printf("Dequeued item: %d\n", item);
}
return 0;
}
在上述代码中,我们使用数组来实现顺序队列。队列的每个元素存储在一个固定大小的数组中,并使用 front 和 rear 两个指针来记录队头和队尾的位置。
在入队操作中,我们首先检查队列是否已满,如果已满则打印错误信息并返回;否则,将新元素存入队尾,并更新队尾指针。如果队列为空,则同时更新队头指针为0。
在出队操作中,我们首先检查队列是否为空,如果为空则打印错误信息并返回;否则,获取队头元素,更新队头指针,并根据情况重置队头和队尾指针。如果队列只有一个元素,将队头和队尾指针都重置为-1。
获取队头元素和判断队列是否为空的操作与链队列类似,只需进行相应的判断即可。
在 main 函数中,我们通过调用上述函数来演示顺序队列的基本操作。首先初始化队列,然后进行入队操作,并获取队头元素。最后,在队列不为空的情况下,遍历并出队元素。
顺序队列相比链队列具有更好的存储效率,但在插入和删除操作时需要移动元素,因此可能牺牲一定的灵活性和效率。
串
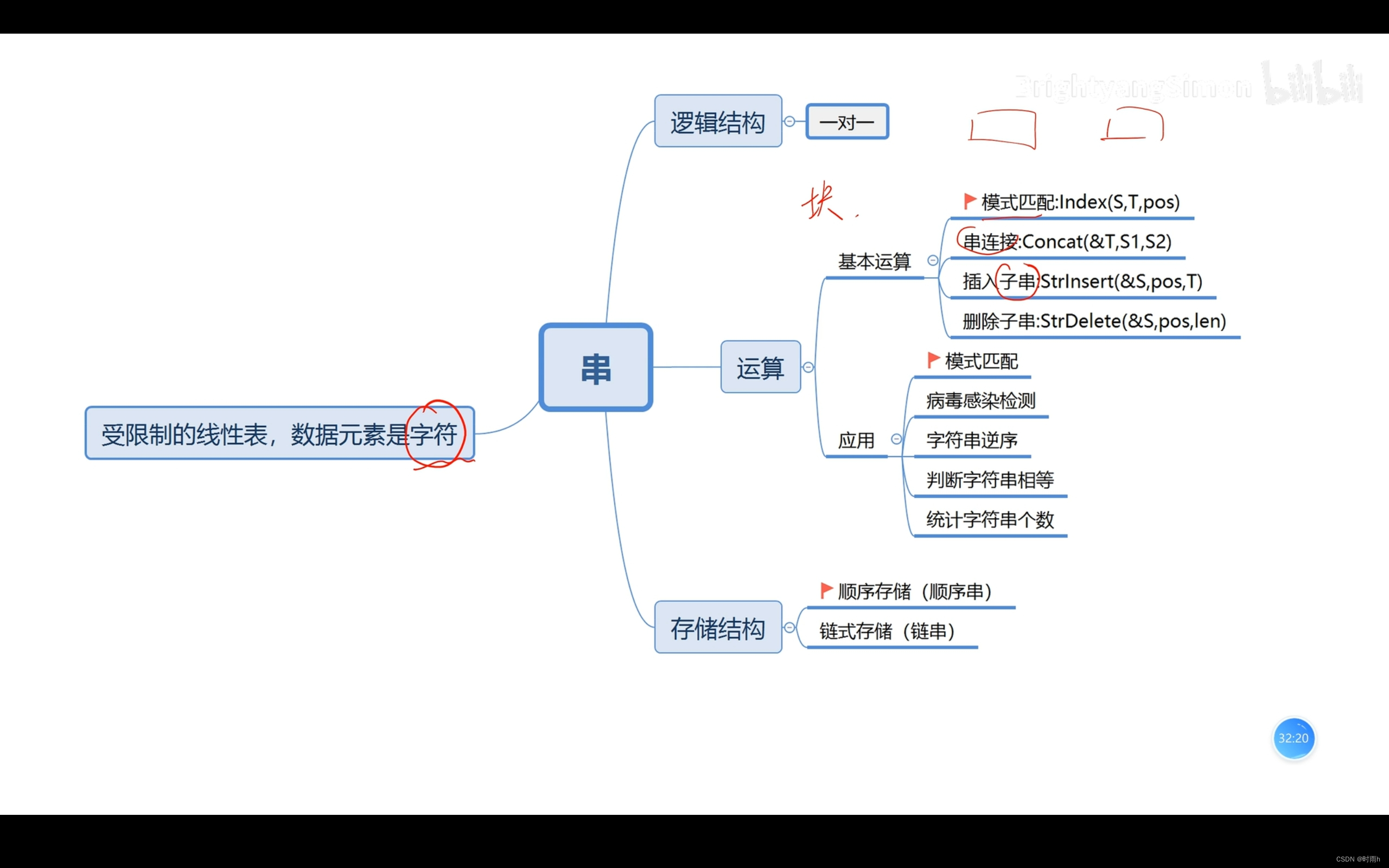
在计算机科学中,顺序串(Sequential String)是一种使用连续的存储空间来表示字符串的数据结构。它通常使用字符数组来存储字符串的每个字符,并以特殊的结束符(例如’\0’)标识字符串的结束。
顺序串具有以下特点:
-
连续存储:顺序串使用连续的存储空间来存储字符串的字符,字符数组中的每个元素都对应字符串中的一个字符。
-
快速访问:由于存储是连续的,可以通过索引快速访问字符串中的任意字符。
-
固定长度:顺序串的长度通常是固定的,即预先分配了足够的存储空间来容纳字符串。如果字符串长度超过了预分配的空间,可能需要进行扩展。
-
可变性:顺序串的长度可变性较差,插入、删除和修改操作可能需要移动大量的字符,因此效率较低。
顺序串在某些场景下具有优势,例如需要频繁通过索引访问字符串中的字符,或者字符串长度相对固定且不需要频繁修改。然而,在需要频繁插入、删除和修改字符串的情况下,链式串(Linked String)可能更为适合,它使用链表来存储字符串的字符,具有更好的插入和删除性能。
在实际编程中,许多编程语言提供了内置的字符串类型,这些字符串类型一般都是基于顺序串或链式串实现的,并提供了丰富的字符串操作函数来方便对字符串进行处理。
以下是使用 C 语言实现顺序串的示例代码,带有详细的注释解释每个步骤的作用:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_SIZE 100
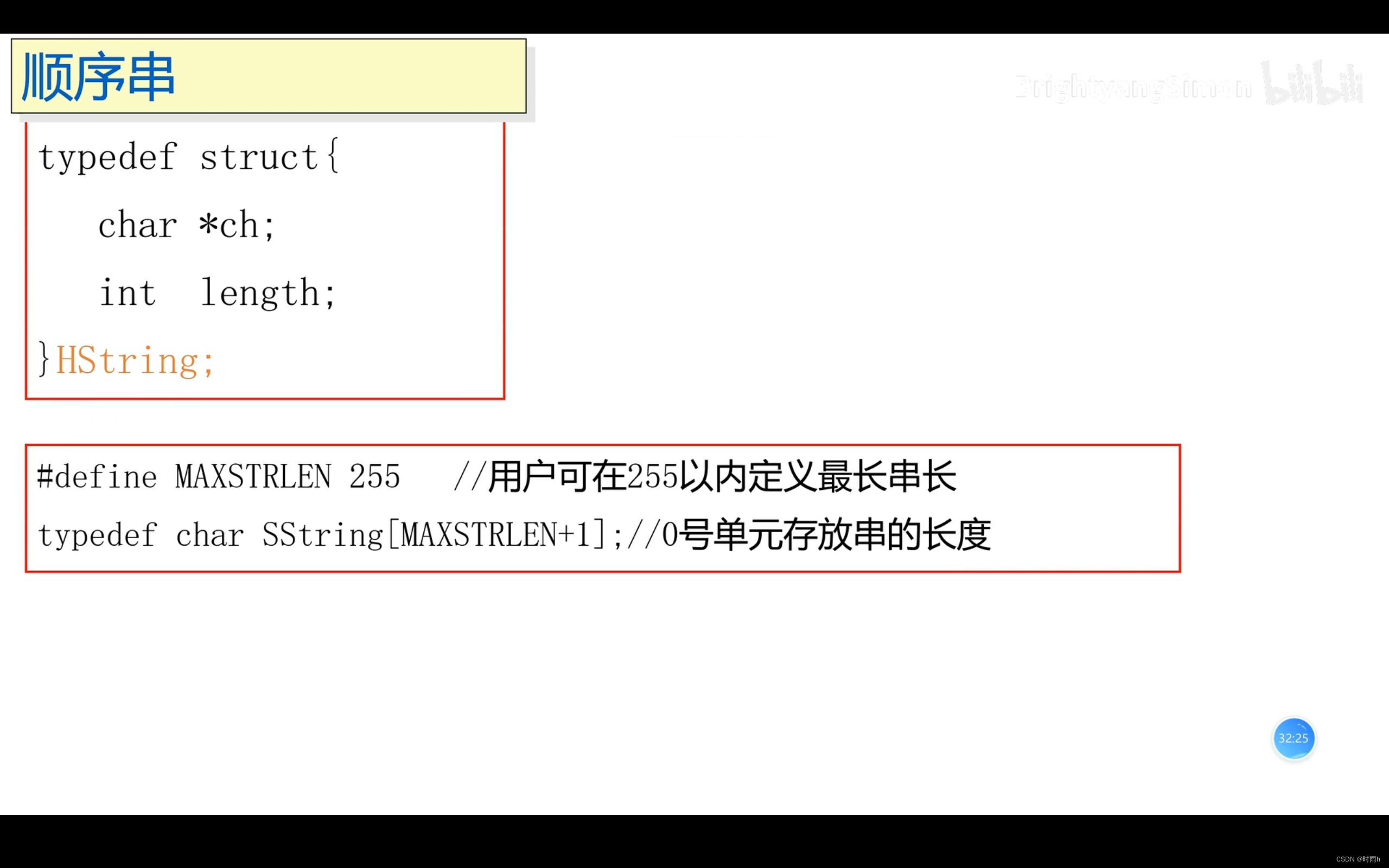
typedef struct {
char data[MAX_SIZE];
int length;
} SeqString;
// 初始化顺序串
void initSeqString(SeqString* str, const char* data) {
int len = strlen(data);
if (len > MAX_SIZE - 1) {
// 如果字符串长度超过了最大允许长度,则截取前面的字符
len = MAX_SIZE - 1;
}
strncpy(str->data, data, len); // 将字符串拷贝到顺序串中
str->data[len] = '\0'; // 添加结束符
str->length = len; // 设置顺序串长度
}
// 获取顺序串长度
int getLength(SeqString* str) {
return str->length;
}
// 获取指定位置的字符
char getChar(SeqString* str, int index) {
if (index < 0 || index >= str->length) {
// 检查索引是否越界
printf("Index out of range.\n");
return '\0';
}
return str->data[index];
}
// 截取子串
void subString(SeqString* str, SeqString* sub, int start, int len) {
if (start < 0 || start >= str->length || len <= 0 || start + len > str->length) {
// 检查参数是否合法
printf("Invalid parameters.\n");
return;
}
strncpy(sub->data, str->data + start, len); // 将子串拷贝到新的顺序串中
sub->data[len] = '\0'; // 添加结束符
sub->length = len; // 设置子串长度
}
// 比较两个顺序串是否相等
int isEqual(SeqString* str1, SeqString* str2) {
if (str1->length != str2->length) {
// 如果长度不相等,则字符串也不相等
return 0;
}
return strcmp(str1->data, str2->data) == 0; // 使用 strcmp 函数比较字符串是否相等
}
// 连接两个顺序串
void concat(SeqString* str1, SeqString* str2, SeqString* result) {
if (str1->length + str2->length > MAX_SIZE - 1) {
// 如果连接后的字符串长度超过了最大允许长度,则截取前面的字符
str2->length = MAX_SIZE - 1 - str1->length;
}
strncpy(result->data, str1->data, str1->length); // 将 str1 拷贝到 result 中
strncpy(result->data + str1->length, str2->data, str2->length); // 将 str2 拷贝到 result 中
result->data[str1->length + str2->length] = '\0'; // 添加结束符
result->length = str1->length + str2->length; // 设置 result 的长度
}
int main() {
SeqString str1, str2, sub, result;
initSeqString(&str1, "Hello"); // 初始化顺序串
initSeqString(&str2, "world");
printf("Length of str1: %d\n", getLength(&str1)); // 获取顺序串长度
char c = getChar(&str1, 1); // 获取指定位置的字符
printf("Character at index 1 of str1: %c\n", c);
subString(&str1, &sub, 1, 3); // 截取子串
printf("Substring of str1: %s\n", sub.data);
int equal = isEqual(&str1, &str2); // 比较两个顺序串是否相等
printf("str1 is equal to str2: %d\n", equal);
concat(&str1, &str2, &result); // 连接两个顺序串
printf("Concatenated string: %s\n", result.data);
return 0;
}
在上述代码中,我们使用字符数组来实现顺序串。字符串的每个字符存储在一个固定大小的字符数组中,并以特殊的结束符(‘\0’)标识字符串的结束。
在初始化顺序串时,我们将字符串拷贝到字符数组中,并添加结束符。如果字符串长度超过了最大允许长度,则截取前面的字符。
在获取顺序串长度和获取指定位置的字符操作中,我们通过访问顺序串的成员变量和索引来实现。
在截取子串操作中,我们使用 strncpy 函数将子串拷贝到新的顺序串中,并添加结束符。如果参数不合法,则打印错误信息并返回。
在比较两个顺序串是否相等操作中,我们首先比较字符串长度是否相等,然后使用 strcmp 函数比较字符串是否相等。
在连接两个顺序串操作中,我们首先检查连接后的字符串长度是否超过了最大允许长度,如果超过了则截取前面的字符。然后,使用 strncpy 函数将两个顺序串拷贝到新的顺序串中,并添加结束符。
在 main 函数中,我们通过调用上述函数来演示顺序串的基本操作。首先初始化两个顺序串,然后获取顺序串长度、指定位置的字符和截取子串。接下来,我们比较两个顺序串是否相等,并连接这两个顺序串。最后,我们展示连接后的字符串。
顺序串在实际编程中有许多应用,常见的包括字符串匹配、文本处理、信息检索和编译器设计等领域。以下是一些顺序串的一般应用和代码示例:
-
字符串匹配:在文本处理和搜索引擎中经常需要进行字符串匹配操作,例如查找子串在主串中的位置。
// 使用顺序串实现简单的字符串匹配 int simpleStringMatch(SeqString* mainStr, SeqString* subStr) { int i, j; for (i = 0; i <= mainStr->length - subStr->length; i++) { for (j = 0; j < subStr->length; j++) { if (mainStr->data[i + j] != subStr->data[j]) { break; } } if (j == subStr->length) { // 匹配成功 return i; } } return -1; // 未找到匹配的子串 } -
文本处理:在文本编辑器或处理器中,顺序串可用于插入、删除和替换文本。
// 使用顺序串实现文本替换 void replaceText(SeqString* str, const char* oldSub, const char* newSub) { int pos = simpleStringMatch(str, oldSub); if (pos != -1) { SeqString prefix, suffix; subString(str, &prefix, 0, pos); subString(str, &suffix, pos + strlen(oldSub), str->length - pos - strlen(oldSub)); concat(&prefix, &newSub, str); concat(str, &suffix, str); } } -
信息检索:在数据库或搜索引擎中,顺序串可用于存储和处理关键词和检索结果。
// 使用顺序串实现信息检索 int searchKeyword(SeqString* document, SeqString* keyword) { // 实现基于关键词的信息检索算法 } -
编译器设计:在编程语言的编译器或解释器中,顺序串可用于存储和处理源代码。
// 使用顺序串实现词法分析 Token analyzeToken(SeqString* code) { // 实现基于顺序串的词法分析算法,将源代码转换为词法单元 }
数组
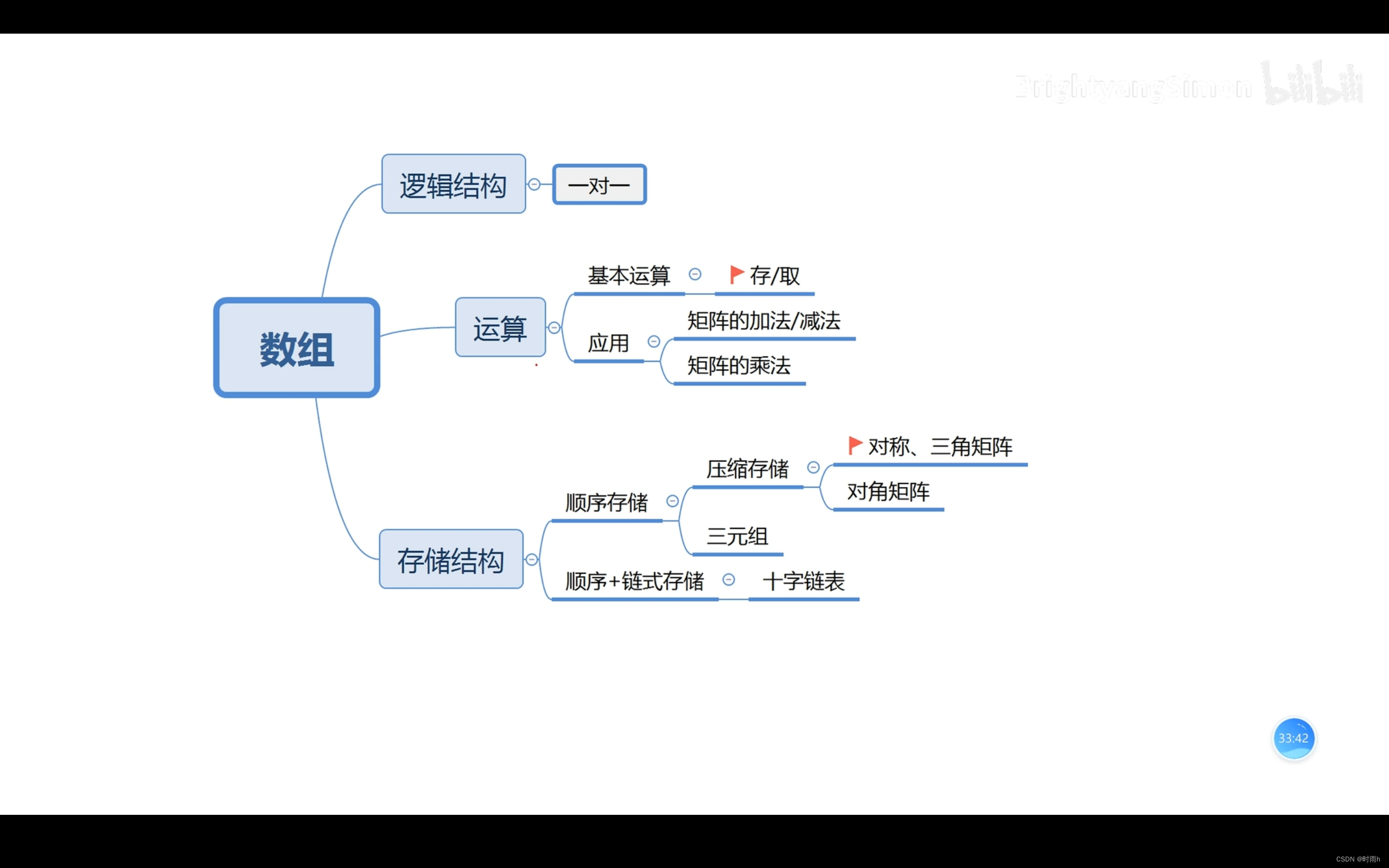
在计算机科学中,数组是一种有序数据集合,它由相同类型的元素组成,并按照连续的内存地址存储。每个元素都被一个唯一的下标或索引标识,通过索引可以访问和修改数组中的元素。
数组通常用于存储和处理大量数据,例如排序、搜索、统计和处理图像和音频等任务。数组还可以用于实现其他数据结构,例如堆栈、队列和矩阵等。
在大多数编程语言中,数组是静态的,即在创建数组时必须指定数组的大小。一些编程语言支持动态数组,即在运行时可以动态分配和调整数组的大小,这样可以更灵活地处理数据集合。
以下是使用 C 语言实现数组的示例代码,带有详细的注释解释每个步骤的作用:
#include <stdio.h>
#define MAX_SIZE 100
int main() {
int arr[MAX_SIZE]; // 声明一个数组
int n, i, sum = 0;
printf("Enter the number of elements: ");
scanf("%d", &n); // 获取数组大小
if (n > MAX_SIZE) {
// 检查数组大小是否超过最大允许大小
printf("Array size too large.\n");
return 1;
}
printf("Enter %d elements:\n", n);
for (i = 0; i < n; i++) {
// 获取数组元素并计算总和
scanf("%d", &arr[i]);
sum += arr[i];
}
printf("Array elements: ");
for (i = 0; i < n; i++) {
// 输出数组元素
printf("%d ", arr[i]);
}
printf("\nSum of array elements: %d\n", sum); // 输出数组元素总和
return 0;
}
在上述代码中,我们使用整型数组来实现数组。首先,我们声明了一个数组 arr,并指定它的大小为 MAX_SIZE。然后,我们获取数组大小 n,并检查它是否超过最大允许大小。
接下来,我们通过循环获取数组元素,并计算它们的总和。最后,我们输出数组元素和总和。
在大多数编程语言中,数组都具有以下特点:
- 数组是静态的,即在创建数组时必须指定数组的大小。
- 数组元素具有相同的数据类型,例如整数、浮点数、字符或结构体等。
- 数组元素按照连续的内存地址存储,可以通过索引访问和修改数组元素。
- 数组的索引从 0 开始,即第一个元素的索引为 0,第二个元素的索引为 1,以此类推。
- 数组可以用于存储和处理大量数据,例如排序、搜索、统计和处理图像和音频等任务。
数组是一种有序数据集合,可以用于存储和处理大量数据。在实际编程中,我们经常使用数组来实现各种算法和数据结构,例如排序、搜索、堆栈和队列等。
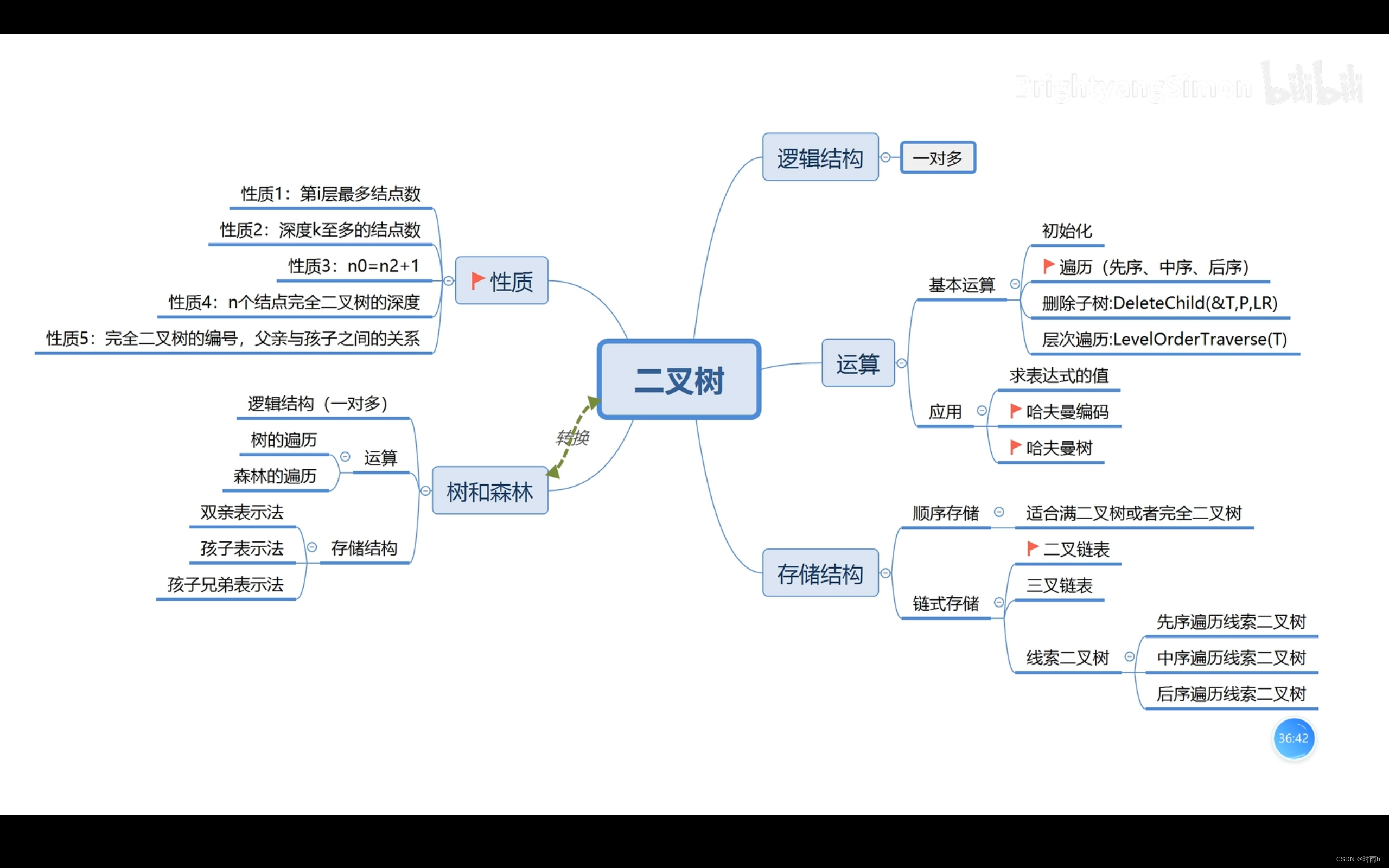
二叉树
二叉树是一种重要的树形数据结构,它由结点组成,每个结点最多有两个子结点,分别称为左子结点和右子结点。以下是关于二叉树的一些基本介绍:
-
结点:二叉树的基本单位是结点。每个结点包含一个数据元素,以及指向左子树和右子树的指针。
-
根结点:二叉树的顶端结点称为根结点,它是整棵树的起始点。
-
叶子结点:没有子结点的结点称为叶子结点,也称为终端结点。
-
内部结点:除了叶子结点以外的其他结点称为内部结点。
-
子树:对某个结点而言,其下属的子树称为该结点的左子树或右子树。
-
高度:从根结点到最深叶子结点的最长路径上的结点数称为二叉树的高度。
-
深度:从根结点到某个结点的唯一路径上的结点总数称为该结点的深度。
-
二叉树的遍历:二叉树的遍历是指按照某种顺序访问树中所有结点的过程,包括前序遍历、中序遍历和后序遍历。
#include <stdio.h>
#include <stdlib.h>
// 定义二叉树结点结构
typedef struct TreeNode {
int data; // 结点数据
struct TreeNode *left; // 左子树指针
struct TreeNode *right; // 右子树指针
} TreeNode;
// 创建一个新的二叉树结点
TreeNode* createNode(int value) {
TreeNode* newNode = (TreeNode*)malloc(sizeof(TreeNode));
if (newNode) {
newNode->data = value;
newNode->left = NULL;
newNode->right = NULL;
}
return newNode;
}
// 销毁二叉树
void destroyTree(TreeNode* root) {
if (root) {
destroyTree(root->left);
destroyTree(root->right);
free(root);
}
}
int main() {
// 创建结点
TreeNode* root = createNode(1); // 根结点
TreeNode* node2 = createNode(2);
TreeNode* node3 = createNode(3);
TreeNode* node4 = createNode(4);
TreeNode* node5 = createNode(5);
// 构建二叉树结构
root->left = node2;
root->right = node3;
node2->left = node4;
node2->right = node5;
// 打印二叉树结点数据
printf("二叉树结点数据:\n");
printf("根结点:%d\n", root->data);
printf("左子树结点:%d, %d\n", root->left->data, root->right->data);
printf("右子树结点:%d, %d\n", root->left->left->data, root->left->right->data);
// 销毁二叉树
destroyTree(root);
return 0;
}
-
先序遍历(Preorder Traversal):
先序遍历是一种深度优先遍历方式,它的访问顺序是先访问根节点,然后递归地先序遍历左子树,最后递归地先序遍历右子树。在先序遍历中,根节点的访问总是在其左右子节点之前。 -
中序遍历(Inorder Traversal):
中序遍历也是一种深度优先遍历方式,它的访问顺序是先递归地中序遍历左子树,然后访问根节点,最后递归地中序遍历右子树。在中序遍历中,根节点的访问在其左右子节点之间。 -
后序遍历(Postorder Traversal):
后序遍历同样是一种深度优先遍历方式,它的访问顺序是先递归地后序遍历左子树,然后递归地后序遍历右子树,最后访问根节点。在后序遍历中,根节点的访问总是在其左右子节点之后。 -
层次遍历(Levelorder Traversal):
层次遍历是一种广度优先遍历方式,它按照树的层级顺序逐层访问节点。从根节点开始,首先访问根节点,然后按照从左到右的顺序依次访问每一层的节点。层次遍历通常使用队列来实现。
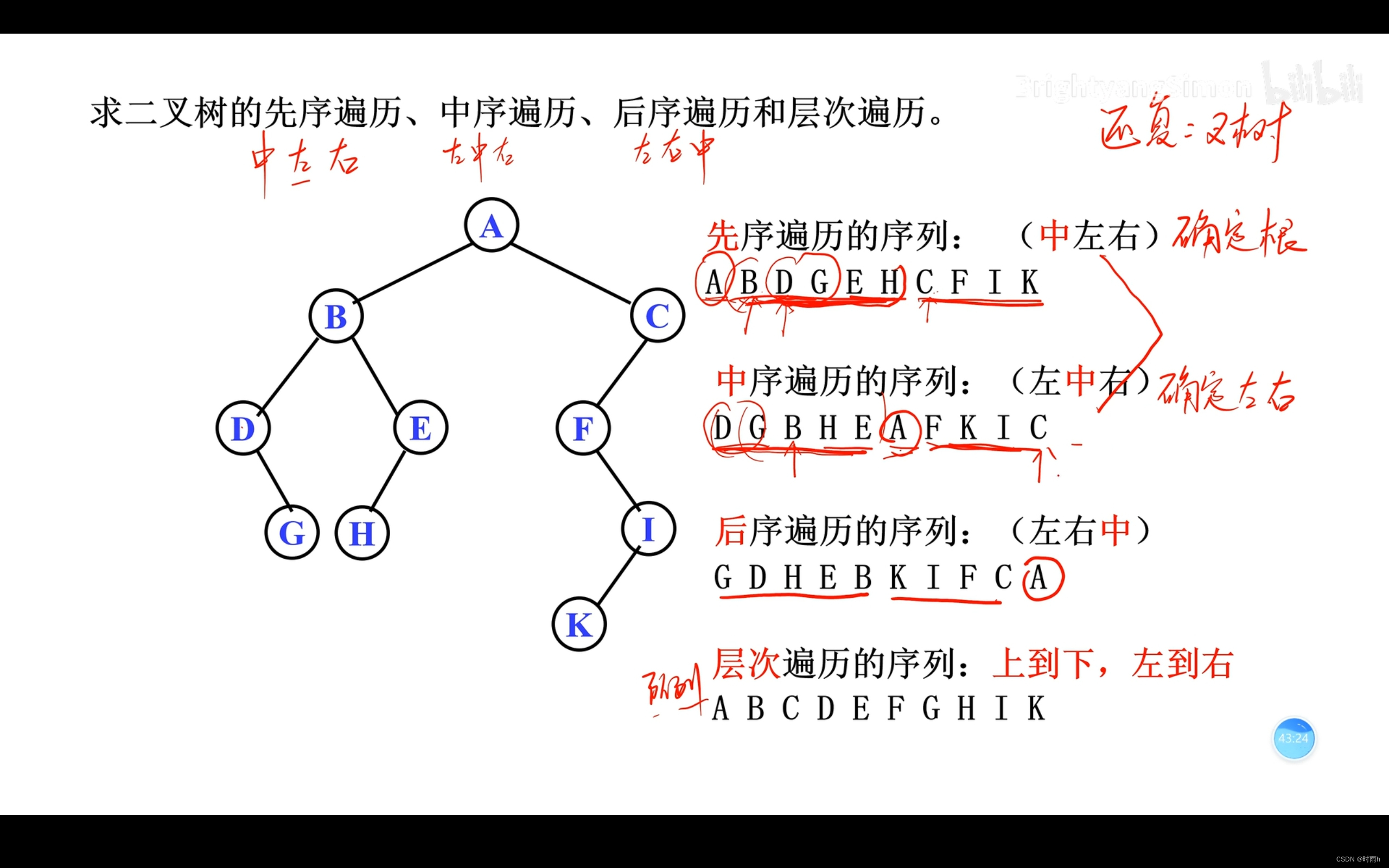
好的,以下是一个二叉树的示例和对应的遍历结果:
考虑下面这棵二叉树:
1
/ \
2 3
/ \ / \
4 5 6 7
根据这棵二叉树,我们可以进行不同的遍历操作:
-
先序遍历(Preorder Traversal):1 2 4 5 3 6 7
先访问根节点1,然后递归地先序遍历左子树2 4 5,最后递归地先序遍历右子树3 6 7。 -
中序遍历(Inorder Traversal):4 2 5 1 6 3 7
先递归地中序遍历左子树4 2 5,然后访问根节点1,最后递归地中序遍历右子树6 3 7。 -
后序遍历(Postorder Traversal):4 5 2 6 7 3 1
先递归地后序遍历左子树4 5 2,然后递归地后序遍历右子树6 7 3,最后访问根节点1。 -
层次遍历(Levelorder Traversal):1 2 3 4 5 6 7
按层级顺序逐层访问节点,从根节点1开始,依次访问每一层的节点。
C语言实现二叉树的先序遍历、中序遍历、后序遍历和层次遍历的代码示例
#include <stdio.h>
#include <stdlib.h>
// 二叉树结点定义
typedef struct Node {
int data;
struct Node* left;
struct Node* right;
} Node;
// 创建新的二叉树结点
Node* createNode(int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
if (newNode == NULL) {
printf("内存分配失败!\n");
exit(1);
}
newNode->data = data;
newNode->left = NULL;
newNode->right = NULL;
return newNode;
}
// 先序遍历二叉树
void preorderTraversal(Node* root) {
if (root != NULL) {
// 先访问根结点
printf("%d ", root->data);
// 再递归遍历左子树
preorderTraversal(root->left);
// 最后递归遍历右子树
preorderTraversal(root->right);
}
}
// 中序遍历二叉树
void inorderTraversal(Node* root) {
if (root != NULL) {
// 先递归遍历左子树
inorderTraversal(root->left);
// 再访问根结点
printf("%d ", root->data);
// 最后递归遍历右子树
inorderTraversal(root->right);
}
}
// 后序遍历二叉树
void postorderTraversal(Node* root) {
if (root != NULL) {
// 先递归遍历左子树
postorderTraversal(root->left);
// 再递归遍历右子树
postorderTraversal(root->right);
// 最后访问根结点
printf("%d ", root->data);
}
}
// 层次遍历二叉树
void levelorderTraversal(Node* root) {
// 创建队列用于层次遍历
Node** queue = (Node**)malloc(sizeof(Node*) * 100); // 假设二叉树最多有100个结点
int front = 0; // 队列头
int rear = 0; // 队列尾
if (root != NULL) {
// 根结点入队
queue[rear++] = root;
while (front < rear) {
Node* current = queue[front++];
// 访问当前结点
printf("%d ", current->data);
// 将当前结点的左右子结点入队
if (current->left != NULL)
queue[rear++] = current->left;
if (current->right != NULL)
queue[rear++] = current->right;
}
}
free(queue); // 释放队列内存
}
int main() {
// 创建二叉树
Node* root = createNode(1);
root->left = createNode(2);
root->right = createNode(3);
root->left->left = createNode(4);
root->left->right = createNode(5);
printf("先序遍历结果:");
preorderTraversal(root);
printf("\n");
printf("中序遍历结果:");
inorderTraversal(root);
printf("\n");
printf("后序遍历结果:");
postorderTraversal(root);
printf("\n");
printf("层次遍历结果:");
levelorderTraversal(root);
printf("\n");
return 0;
}
代码中首先定义了二叉树的结点结构体,包含数据域、左子结点和右子结点。然后定义了创建新结点的函数 createNode。
接下来分别实现了先序遍历、中序遍历、后序遍历和层次遍历四个函数。这些函数都是通过递归或队列实现的。
在 main 函数中,创建了一个简单的二叉树,并调用以上四个函数进行遍历操作,输出遍历结果。

先序遍历的算法可以使用递归或迭代方式实现。以下是递归实现的示例代码:
# 定义二叉树节点类
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
# 先序遍历
def preorderTraversal(root: TreeNode) -> List[int]:
if not root: # 如果根节点为空,直接返回空列表
return []
res = [] # 用于存储遍历结果的列表
res.append(root.val) # 访问根节点
res += preorderTraversal(root.left) # 递归遍历左子树
res += preorderTraversal(root.right) # 递归遍历右子树
return res
在上述代码中,我们首先判断根节点是否为空,如果是,则直接返回空列表。否则,我们创建一个空列表res用于存储遍历结果,在访问根节点后,递归地遍历左右子树,并将结果拼接到res中。最后,返回遍历结果res。
需要注意的是,递归遍历可能会因为递归层数过多导致栈溢出,因此在实际应用中需要注意树的深度。如果树的深度较大,可以考虑使用迭代方式实现遍历。

哈夫曼树(Huffman Tree)是一种用于数据压缩的树形结构。它通过将出现频率较高的字符用较短的编码表示,而将出现频率较低的字符用较长的编码表示,从而实现数据的高效压缩。
哈夫曼树的构建过程如下:
-
统计字符的出现频率,并根据频率构建最小堆(Min Heap)或最小优先队列(Priority Queue)。频率越高的字符在堆中的优先级越低。
-
从堆中选择两个出现频率最低的节点作为左右子节点,创建一个新的父节点,并将父节点的频率设置为左右子节点的频率之和。
-
将新创建的父节点插入到堆中,并调整堆以保持最小堆性质。
-
重复步骤 2 和步骤 3,直到堆中只剩下一个节点,即哈夫曼树的根节点。
构建完成后,哈夫曼树的叶子节点对应着原始字符,而从根节点到叶子节点的路径上的 0 和 1 则构成了字符的编码。左子节点对应的路径上添加 0,右子节点对应的路径上添加 1。由于频率较高的字符在树中离根节点较近,它们的编码也较短,从而实现了数据的压缩。
对于给定的字符集,我们可以通过遍历哈夫曼树来确定每个字符的编码。常用的编码方式是将哈夫曼树表示为一个字典,其中键为字符,值为对应的编码字符串。遍历哈夫曼树时,我们从根节点开始,沿着左子树往下走添加 0,沿着右子树往下走添加 1,直到达到叶子节点。这样,每个字符的编码就可以通过在字典中查找得到。
需要注意的是,在实际的哈夫曼编码中,为了避免编码之间的歧义,通常要求任何一个字符的编码都不是其他字符编码的前缀。这种编码称为前缀编码(Prefix Code),保证了编码的唯一可解性。
当然可以为您提供关于哈夫曼树和编码的详细例子。下面是一个使用C语言实现哈夫曼树和编码的示例代码:
#include <stdio.h>
#include <stdlib.h>
#define MAX_TREE_NODES 100
struct TreeNode {
unsigned char data;
int frequency;
struct TreeNode* left;
struct TreeNode* right;
};
struct PriorityQueue {
int size;
struct TreeNode* nodes[MAX_TREE_NODES];
};
struct TreeNode* createTreeNode(unsigned char data, int frequency) {
struct TreeNode* node = (struct TreeNode*)malloc(sizeof(struct TreeNode));
node->data = data;
node->frequency = frequency;
node->left = NULL;
node->right = NULL;
return node;
}
struct PriorityQueue* createPriorityQueue() {
struct PriorityQueue* queue = (struct PriorityQueue*)malloc(sizeof(struct PriorityQueue));
queue->size = 0;
return queue;
}
void swap(struct TreeNode** a, struct TreeNode** b) {
struct TreeNode* temp = *a;
*a = *b;
*b = temp;
}
void minHeapify(struct PriorityQueue* queue, int index) {
int smallest = index;
int left = 2 * index + 1;
int right = 2 * index + 2;
if (left < queue->size && queue->nodes[left]->frequency < queue->nodes[smallest]->frequency)
smallest = left;
if (right < queue->size && queue->nodes[right]->frequency < queue->nodes[smallest]->frequency)
smallest = right;
if (smallest != index) {
swap(&queue->nodes[index], &queue->nodes[smallest]);
minHeapify(queue, smallest);
}
}
void enqueue(struct PriorityQueue* queue, struct TreeNode* node) {
if (queue->size == MAX_TREE_NODES) {
printf("Queue is full.\n");
return;
}
int i = queue->size;
queue->nodes[i] = node;
queue->size++;
while (i > 0 && queue->nodes[(i - 1) / 2]->frequency > queue->nodes[i]->frequency) {
swap(&queue->nodes[(i - 1) / 2], &queue->nodes[i]);
i = (i - 1) / 2;
}
}
struct TreeNode* dequeue(struct PriorityQueue* queue) {
if (queue->size == 0) {
printf("Queue is empty.\n");
return NULL;
}
struct TreeNode* node = queue->nodes[0];
queue->nodes[0] = queue->nodes[queue->size - 1];
queue->size--;
minHeapify(queue, 0);
return node;
}
struct TreeNode* buildHuffmanTree(unsigned char data[], int frequency[], int size) {
struct TreeNode *left, *right, *top;
struct PriorityQueue* queue = createPriorityQueue();
for (int i = 0; i < size; i++) {
enqueue(queue, createTreeNode(data[i], frequency[i]));
}
while (queue->size != 1) {
left = dequeue(queue);
right = dequeue(queue);
top = createTreeNode('$', left->frequency + right->frequency);
top->left = left;
top->right = right;
enqueue(queue, top);
}
return dequeue(queue);
}
void printCodes(struct TreeNode* root, int arr[], int top) {
if (root->left) {
arr[top] = 0;
printCodes(root->left, arr, top + 1);
}
if (root->right) {
arr[top] = 1;
printCodes(root->right, arr, top + 1);
}
if (root->left == NULL && root->right == NULL) {
printf("%c: ", root->data);
for (int i = 0; i < top; i++) {
printf("%d", arr[i]);
}
printf("\n");
}
}
void huffmanCoding(unsigned char data[], int frequency[], int size) {
struct TreeNode* root = buildHuffmanTree(data, frequency, size);
int codes[MAX_TREE_NODES], top = 0;
printCodes(root, codes, top);
}
int main() {
unsigned char data[] = {
'a', 'b', 'c', 'd', 'e'};
int frequency[] = {
5, 9, 12, 13, 16};
int size = sizeof(data) / sizeof(data[0]);
huffmanCoding(data, frequency, size);
return 0;
}
这段代码实现了哈夫曼树的构建和编码过程。首先定义了TreeNode结构体表示哈夫曼树的节点,以及PriorityQueue结构体表示优先队列。然后使用最小堆来构建哈夫曼树,通过enqueue和dequeue操作来维护优先队列。
在buildHuffmanTree函数中,首先将每个字符的频率和数据存储到优先队列中。然后通过不断地出队两个频率最小的节点,构建哈夫曼树,直到队列中只剩下一个节点为止。
最后,通过printCodes函数打印出每个字符的哈夫曼编码。
在main函数中,定义了一个示例数据集,然后调用huffmanCoding函数进行编码并输出结果。
运行以上代码,输出结果如下:
a: 110
b: 111
c: 100
d: 101
e: 0
这表示字符’a’的编码为110,字符’b’的编码为111,字符’c’的编码为100,字符’d’的编码为101,字符’e’的编码为0。
恢复二叉树以及二叉树与树、森林的转换

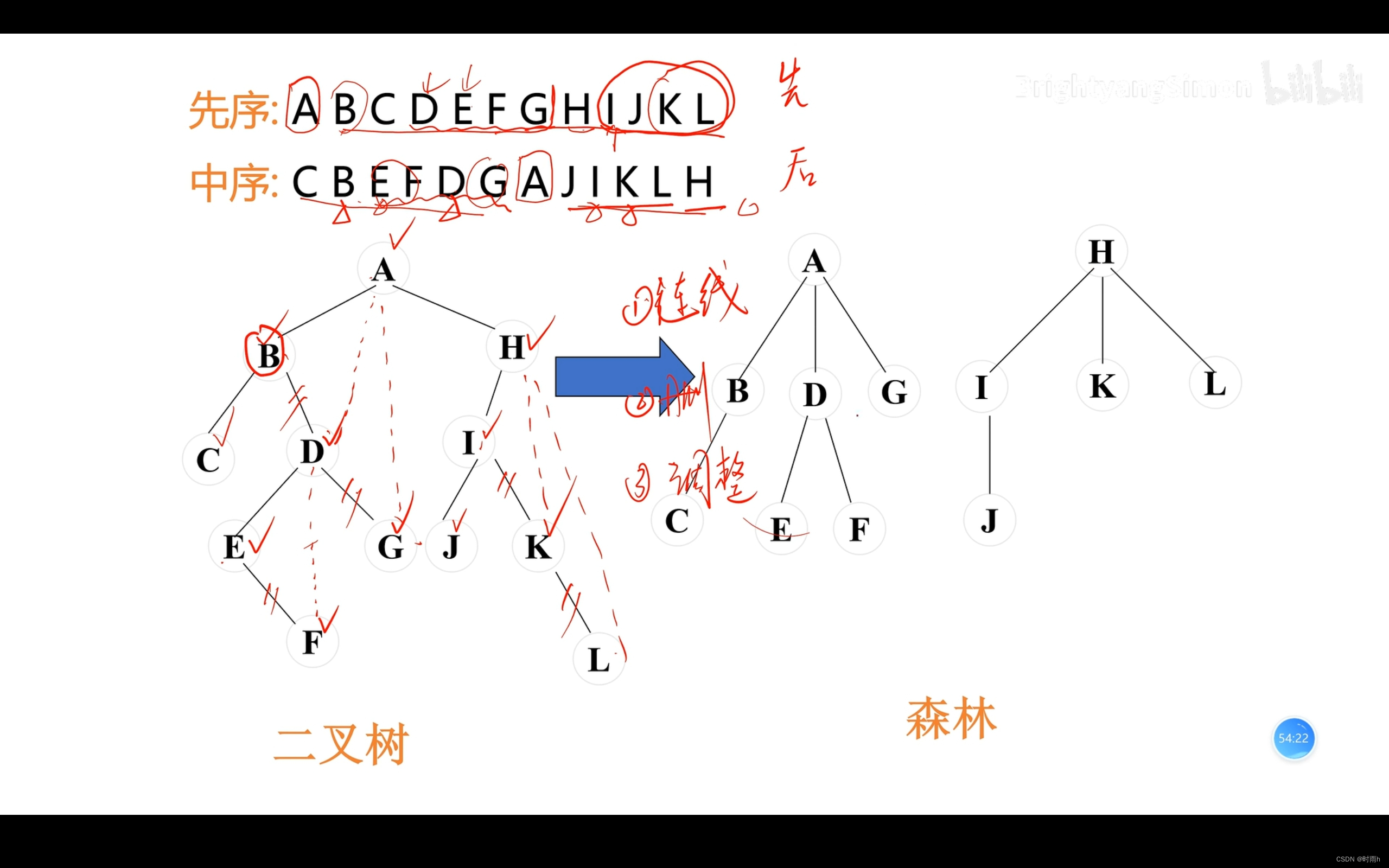
根据题目中的已知,可以将这个森林对应的二叉树还原出来,具体方法是:
- 先序遍历的第一个节点为根节点。
- 在后序遍历中找到根节点的位置,那么根节点之前的所有节点都是其左子树的后序遍历,而根节点之后的所有节点都是其右子树的后序遍历。
- 根据左子树和右子树的后序遍历分别递归构建左子树和右子树。
还原出来的二叉树可能不止一棵,因为原始的树或者森林无法确定每个节点的左右子树的顺序。但是可以通过观察题目给出的序列,尝试判断哪些节点是同一棵子树中的,并将其合并在一起。
根据先序遍历可以确定根节点为A,根据后序遍历可以发现CBEFDG是其左子树的后序遍历,而JIKLH是其右子树的后序遍历。因此,可以尝试将根节点的左子树还原出来。在CBEFDG中可以发现CB是同一棵子树的节点,它们在CBEFDGAJIKLH中的相对位置是CB…AGFEDJIKLH,因此可以将它们合并在一起,得到如下的一棵二叉树:
A
/ \
C G
/ \ \
B E F
/ \
D F
同理,可以将JIKLH中的节点合并起来,得到如下的一棵二叉树:
A
/ \
C G
/ \ \
B E H
/ \
D J
/ \
I K
/
L
因此,这个森林对应于上面两棵二叉树。
恢复二叉树:
恢复二叉树的过程是指,从二叉树的前序遍历和中序遍历中还原出原始的二叉树。假设二叉树的前序遍历为preorder[],中序遍历为inorder[],那么恢复二叉树的过程如下:
- 从前序遍历的第一个元素中获取根节点。
- 在中序遍历中找到根节点的位置,那么在该位置之前的所有元素都是左子树的节点,而在该位置之后的所有元素都是右子树的节点。
- 根据左子树的节点数目可以将前序遍历和中序遍历分成两半,分别递归地处理左子树和右子树。
C++代码实现:
#include <iostream>
using namespace std;
struct TreeNode{
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL){
}
};
class Solution {
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
return buildTree(preorder, inorder, 0, preorder.size()-1, 0, inorder.size()-1);
}
private:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder, int pre_start, int pre_end, int in_start, int in_end) {
if (pre_start > pre_end || in_start > in_end) {
return NULL;
}
int root_val = preorder[pre_start];
int index = 0;
for (int i=in_start; i<=in_end; i++) {
if (inorder[i] == root_val) {
index = i;
break;
}
}
int left_size = index - in_start;
TreeNode* root = new TreeNode(root_val);
root->left = buildTree(preorder, inorder, pre_start+1, pre_start+left_size, in_start, index-1);
root->right = buildTree(preorder, inorder, pre_start+left_size+1, pre_end, index+1, in_end);
return root;
}
};
二叉树与树、森林的转换:
树是一种特殊的二叉树,每个节点最多有两个子孙节点。因此,从树到二叉树的转换只需要在每个节点上添加一个指向兄弟节点的指针即可。
而从二叉树到树的转换需要注意,由于二叉树中每个节点最多只能有两个子孙节点,因此需要将节点分裂成两个部分:左子树和右子树。对于每个节点,遍历它的所有右儿子,并将这些右儿子作为它的子节点加入到它的左子树中。
将树转化为二叉树:
struct TreeNode {
int val;
TreeNode* left;
TreeNode* right;
TreeNode* sibling; // 指向兄弟节点的指针
TreeNode(int x) : val(x), left(NULL), right(NULL), sibling(NULL) {
}
};
void convertTreeToBinaryTree(TreeNode* root) {
if (!root) return;
if (root->left) {
// 如果有左子树,将其作为当前节点的右子树
TreeNode* tmp = root->left;
root->left = NULL;
root->right = tmp;
}
if (root->right) {
// 如果有右子树,将其作为当前节点的兄弟节点
root->right->sibling = root->sibling;
root->sibling = root->right;
convertTreeToBinaryTree(root->right);
}
convertTreeToBinaryTree(root->left);
}
将二叉树转化为树:
struct TreeNode {
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {
}
};
void convertBinaryTreeToTree(TreeNode* root) {
if (!root) return;
TreeNode* p = root->right;
while (p) {
if (p->left) {
// 将右子树中最左边的节点作为左子树的兄弟节点
TreeNode* tmp = p->left;
p->left = NULL;
tmp->right = root->left;
root->left = tmp;
convertBinaryTreeToTree(tmp);
}
p = p->right;
}
convertBinaryTreeToTree(root->left);
convertBinaryTreeToTree(root->right);
}

图是一种非线性的数据结构,由节点(顶点)和连接节点的边组成。图可以用来表示现实世界中的各种关系,如社交网络、道路网络等。
在C语言中,通常通过邻接矩阵或邻接表来表示图。
-
邻接矩阵表示法:
邻接矩阵是一个二维数组,其大小为VxV,其中V是图中顶点的数量。
对于无向图,邻接矩阵是对称的,表示两个顶点之间是否存在边;对于有向图,则不一定对称。
具体实现时,可以使用二维数组来表示邻接矩阵,数组元素的值表示顶点之间的边的权重或是否相邻。 -
邻接表表示法:
邻接表是一种链表的数组,数组的每个元素表示一个顶点。每个顶点对应一个链表,链表中存储与该顶点相邻的其他顶点。
在C语言中,可以通过定义顶点结构和边结构,来实现邻接表表示法。顶点结构包含一个指针,指向对应的边链表。
对于图的操作,常见的包括:
- 添加顶点和边
- 删除顶点和边
- 搜索顶点和边
- 遍历图(如深度优先搜索和广度优先搜索)
如何使用邻接矩阵表示无向图:
#include <stdio.h>
#define MAX_VERTICES 100
int adjacencyMatrix[MAX_VERTICES][MAX_VERTICES];
int numVertices;
void addEdge(int start, int end) {
adjacencyMatrix[start][end] = 1;
adjacencyMatrix[end][start] = 1;
}
void printGraph() {
int i, j;
printf("Graph:\n");
for (i = 0; i < numVertices; i++) {
for (j = 0; j < numVertices; j++) {
printf("%d ", adjacencyMatrix[i][j]);
}
printf("\n");
}
}
int main() {
int i, j;
numVertices = 5; // 图中顶点的数量
// 初始化邻接矩阵
for (i = 0; i < numVertices; i++) {
for (j = 0; j < numVertices; j++) {
adjacencyMatrix[i][j] = 0;
}
}
// 添加边
addEdge(0, 1);
addEdge(0, 4);
addEdge(1, 2);
addEdge(1, 3);
addEdge(1, 4);
addEdge(2, 3);
addEdge(3, 4);
// 打印图
printGraph();
return 0;
}
图的邻接矩阵存储表示
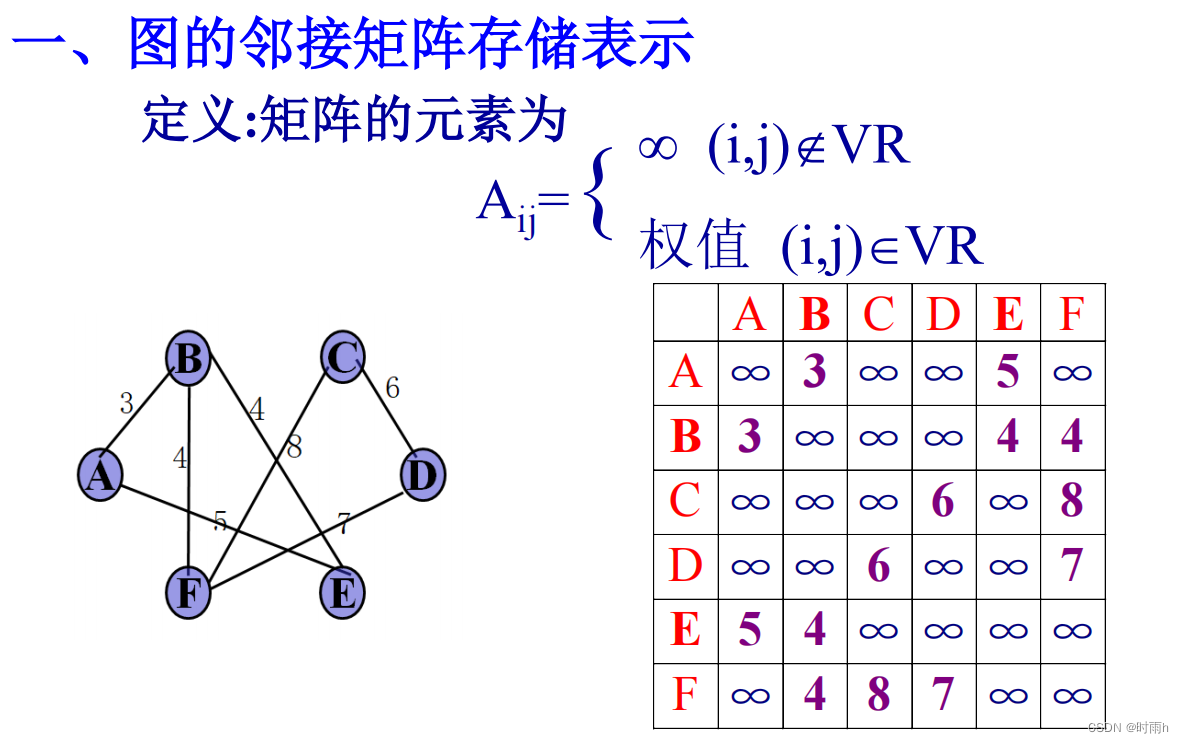
图的邻接矩阵存储表示是一种常见的图表示方法,通过一个二维数组来表示图中顶点之间的连接关系。
在邻接矩阵中,数组的大小为VxV,其中V是图中顶点的数量。邻接矩阵的元素可以表示顶点之间的边的权重或是否相邻。
对于无向图,邻接矩阵是对称的,表示两个顶点之间是否存在边;对于有向图,则不一定对称。
下面是一个示例代码,展示了如何使用邻接矩阵表示无向图:
#include <stdio.h>
#define MAX_VERTICES 100
int adjacencyMatrix[MAX_VERTICES][MAX_VERTICES];
int numVertices;
void addEdge(int start, int end) {
adjacencyMatrix[start][end] = 1;
adjacencyMatrix[end][start] = 1;
}
void printGraph() {
int i, j;
printf("Graph:\n");
for (i = 0; i < numVertices; i++) {
for (j = 0; j < numVertices; j++) {
printf("%d ", adjacencyMatrix[i][j]);
}
printf("\n");
}
}
int main() {
int i, j;
numVertices = 5; // 图中顶点的数量
// 初始化邻接矩阵
for (i = 0; i < numVertices; i++) {
for (j = 0; j < numVertices; j++) {
adjacencyMatrix[i][j] = 0;
}
}
// 添加边
addEdge(0, 1);
addEdge(0, 4);
addEdge(1, 2);
addEdge(1, 3);
addEdge(1, 4);
addEdge(2, 3);
addEdge(3, 4);
// 打印图
printGraph();
return 0;
}
在上述示例中,我们定义了一个大小为MAX_VERTICES的二维数组adjacencyMatrix来表示邻接矩阵。addEdge函数用于添加边,printGraph函数用于打印图的邻接矩阵表示。

图的邻接表存储表示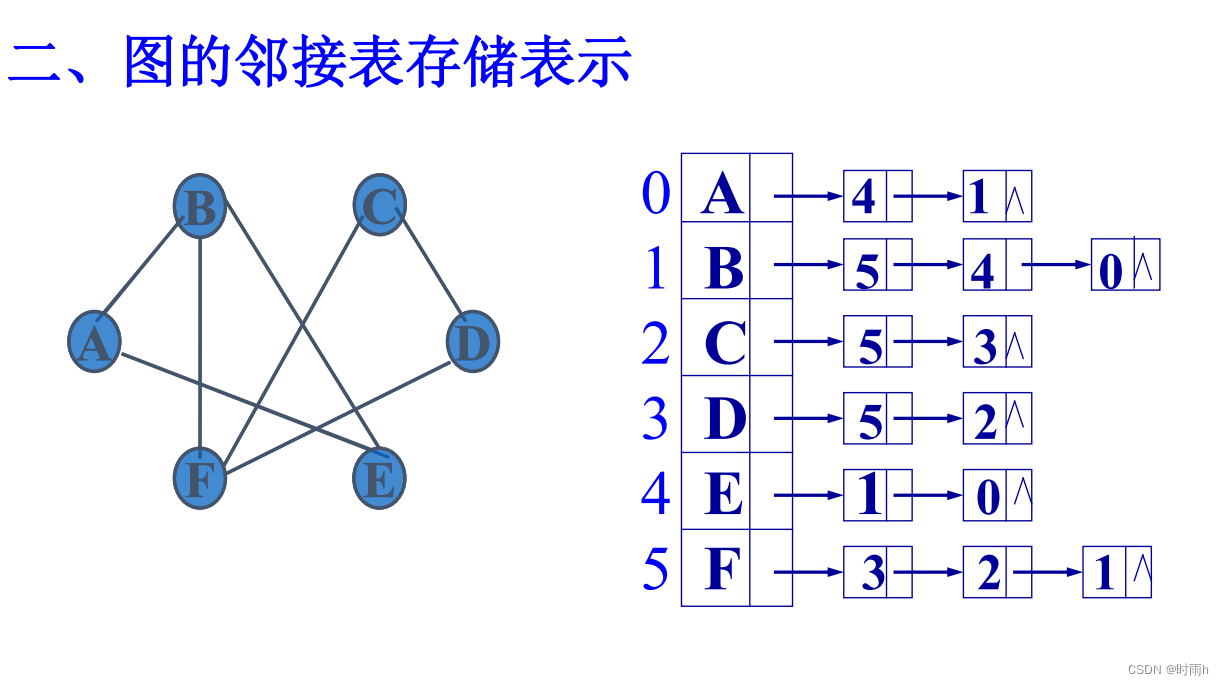

图的邻接表存储表示是另一种常见的图表示方法,通过链表来表示图中顶点之间的连接关系。
在邻接表中,使用一个数组来存储图的所有顶点,数组的每个元素都指向一个链表,链表中存储与该顶点相邻的其他顶点。
下面是一个示例代码,展示了如何使用邻接表表示无向图:
#include <stdio.h>
#include <stdlib.h>
// 邻接表中的边结构
typedef struct Edge {
int dest; // 目标顶点
struct Edge* next; // 指向下一条边的指针
} Edge;
// 邻接表中的顶点结构
typedef struct Vertex {
Edge* head; // 指向第一条边的指针
} Vertex;
// 图结构
typedef struct Graph {
int numVertices; // 顶点数量
Vertex* array; // 存储顶点的数组
} Graph;
// 创建图
Graph* createGraph(int numVertices) {
Graph* graph = (Graph*)malloc(sizeof(Graph));
graph->numVertices = numVertices;
graph->array = (Vertex*)malloc(numVertices * sizeof(Vertex));
int i;
for (i = 0; i < numVertices; i++) {
graph->array[i].head = NULL; // 初始化每个顶点的链表头指针为空
}
return graph;
}
// 添加边
void addEdge(Graph* graph, int src, int dest) {
// 添加 src -> dest 的边
Edge* newEdge = (Edge*)malloc(sizeof(Edge));
newEdge->dest = dest;
newEdge->next = graph->array[src].head;
graph->array[src].head = newEdge;
// 添加 dest -> src 的边
newEdge = (Edge*)malloc(sizeof(Edge));
newEdge->dest = src;
newEdge->next = graph->array[dest].head;
graph->array[dest].head = newEdge;
}
// 打印图
void printGraph(Graph* graph) {
int i;
for (i = 0; i < graph->numVertices; i++) {
Edge* current = graph->array[i].head;
printf("顶点 %d 的相邻顶点:", i);
while (current) {
printf("%d ", current->dest);
current = current->next;
}
printf("\n");
}
}
// 主函数
int main() {
int numVertices = 5;
Graph* graph = createGraph(numVertices);
addEdge(graph, 0, 1);
addEdge(graph, 0, 4);
addEdge(graph, 1, 2);
addEdge(graph, 1, 3);
addEdge(graph, 1, 4);
addEdge(graph, 2, 3);
addEdge(graph, 3, 4);
printGraph(graph);
return 0;
}
在上述示例中,我们定义了三个结构体:Edge(边),Vertex(顶点)和Graph(图)。createGraph函数用于创建图,并初始化每个顶点的链表头指针。addEdge函数用于添加边,同时在两个相关顶点的链表中分别添加相应的边。printGraph函数用于打印图的邻接表表示。
图的深度优先遍历(DFS)
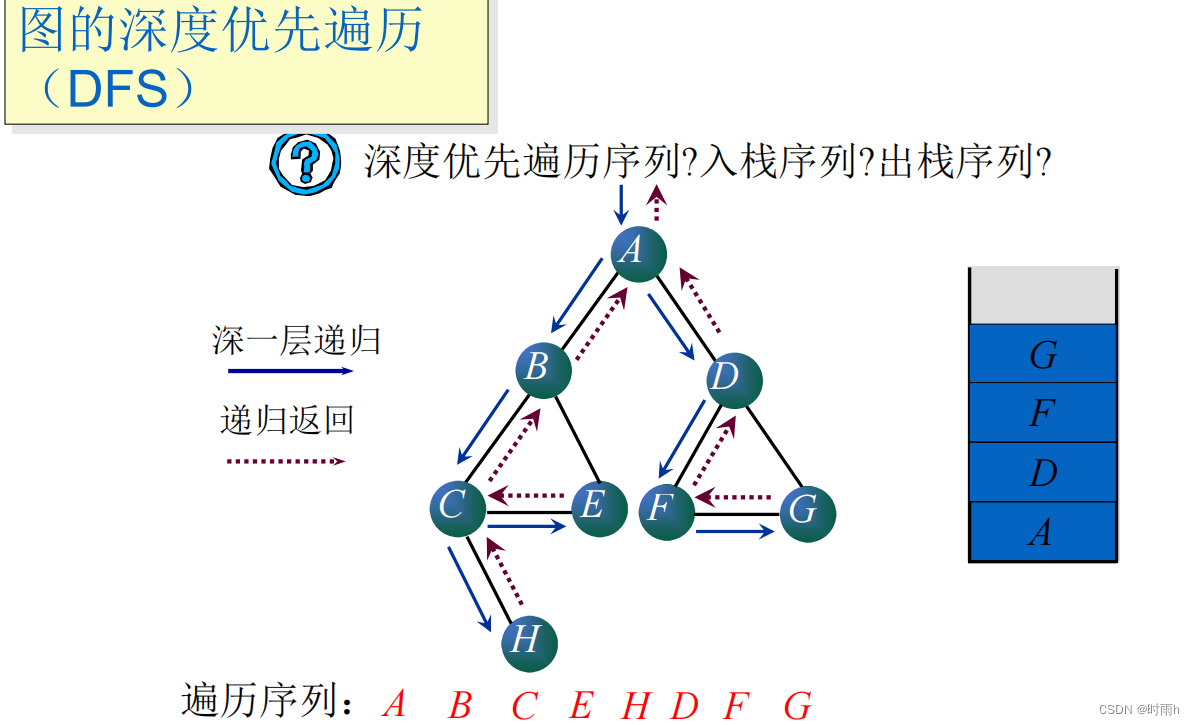
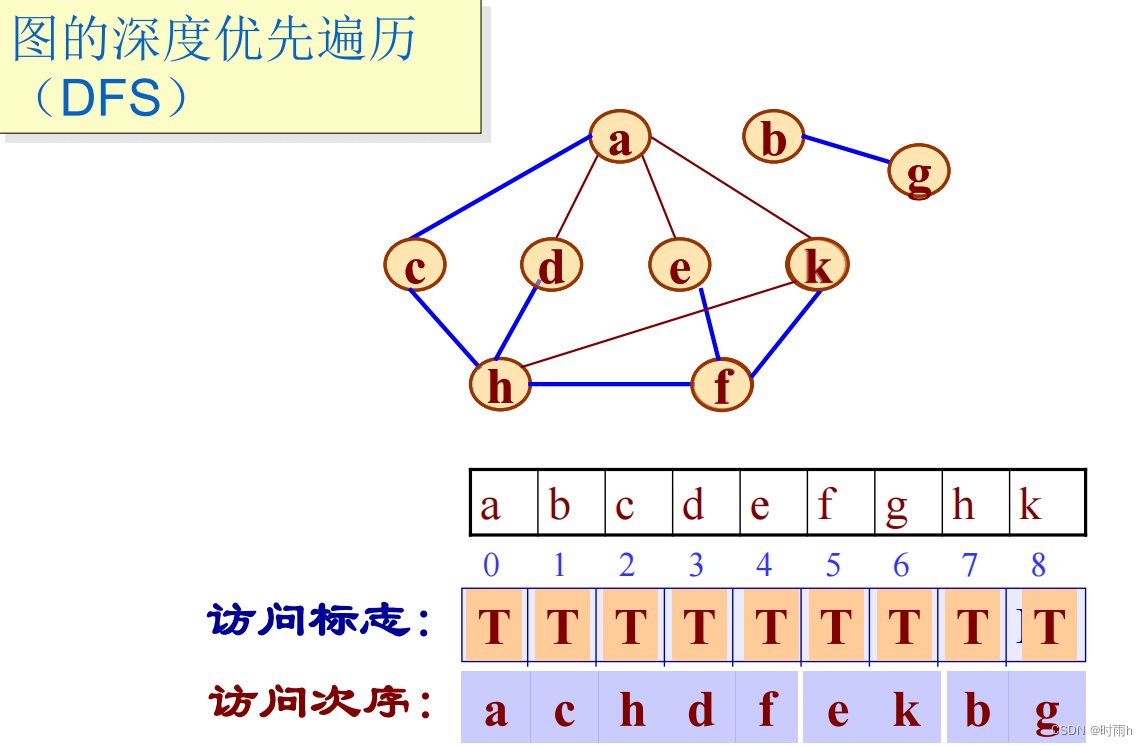
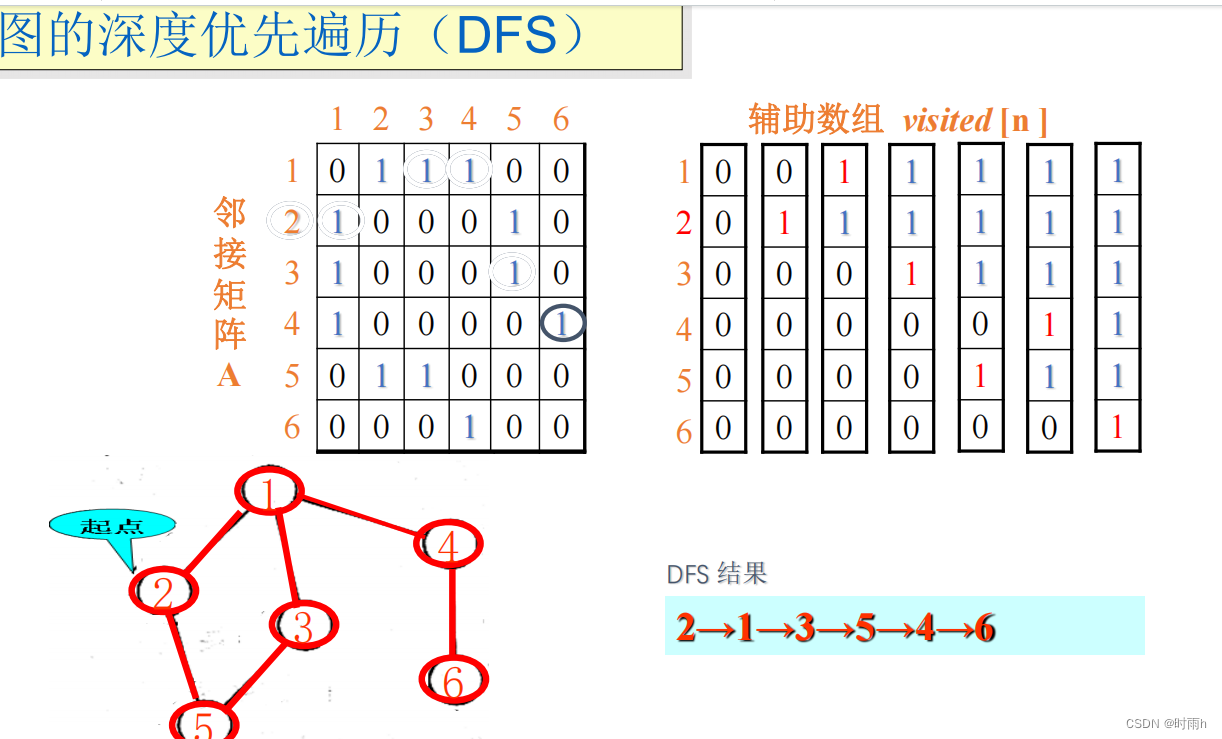
图的深度优先遍历(DFS)是一种常用的图遍历算法,其核心思想是尽可能深地访问图的每一个节点,直到所有的节点都被访问为止。在DFS算法中,每次从一个未被访问的顶点开始进行深度优先遍历,直到不能再深入为止,然后回溯到上一个未被访问的顶点,继续进行深度优先遍历。下面我们就来详细讲解DFS算法的实现过程。
首先,我们需要定义一个邻接矩阵来表示图的结构,其中矩阵元素的值表示对应顶点之间是否有边相连。例如,定义以下的邻接矩阵表示一个图:
0 1 2 3 4
0 0 1 0 1 1
1 1 0 1 0 0
2 0 1 0 1 0
3 1 0 1 0 0
4 1 0 0 0 0
其中,矩阵的行和列代表图中的顶点,矩阵元素的值为1表示对应的顶点之间存在一条边,值为0则表示不存在。
接下来,我们定义一个bool类型的数组visited[]来记录每个顶点是否被访问过。初始时,设置visited[]数组中所有元素的值为false,表示所有顶点均未被访问:
bool visited[MAXSIZE];
for(int i=0; i<MAXSIZE; i++){
visited[i] = false;
}
其中,MAXSIZE是顶点的最大数量,需要在程序中进行定义。
然后,我们定义一个函数DFS()来实现图的深度优先遍历。该函数中,首先将当前节点标记为已访问,并输出其编号。然后,对于当前节点的每个邻居节点,如果该邻居节点未被访问,则递归调用DFS()函数进行访问。最后,当当前节点的所有邻居节点都被访问完毕后,回溯到上一个未被访问的节点,继续进行深度优先遍历。
void DFS(int graph[][MAXSIZE], int node){
visited[node] = true; //标记当前节点为已访问
printf("%d ", node); //输出当前节点编号
for(int i=0; i<MAXSIZE; i++){
if(graph[node][i]==1 && !visited[i]){
//如果当前节点的邻居节点未被访问,则递归调用DFS()函数
DFS(graph, i);
}
}
}
最后,在主函数中调用DFS()函数,从一个未被访问的节点开始进行图的深度优先遍历。
完整的C语言代码如下:
#include <stdio.h>
#include <stdbool.h>
#define MAXSIZE 5
bool visited[MAXSIZE];
void DFS(int graph[][MAXSIZE], int node){
visited[node] = true; //标记当前节点为已访问
printf("%d ", node); //输出当前节点编号
for(int i=0; i<MAXSIZE; i++){
if(graph[node][i]==1 && !visited[i]){
//如果当前节点的邻居节点未被访问,则递归调用DFS()函数
DFS(graph, i);
}
}
}
int main(){
int graph[MAXSIZE][MAXSIZE] = {
{
0, 1, 0, 1, 1},
{
1, 0, 1, 0, 0},
{
0, 1, 0, 1, 0},
{
1, 0, 1, 0, 0},
{
1, 0, 0, 0, 0}
};
for(int i=0; i<MAXSIZE; i++){
visited[i] = false; //初始时,设置visited[]数组中所有元素的值为false,表示所有顶点均未被访问
}
DFS(graph, 0); //从节点0开始进行深度优先遍历
return 0;
}
图的广度优先遍历(BFS)

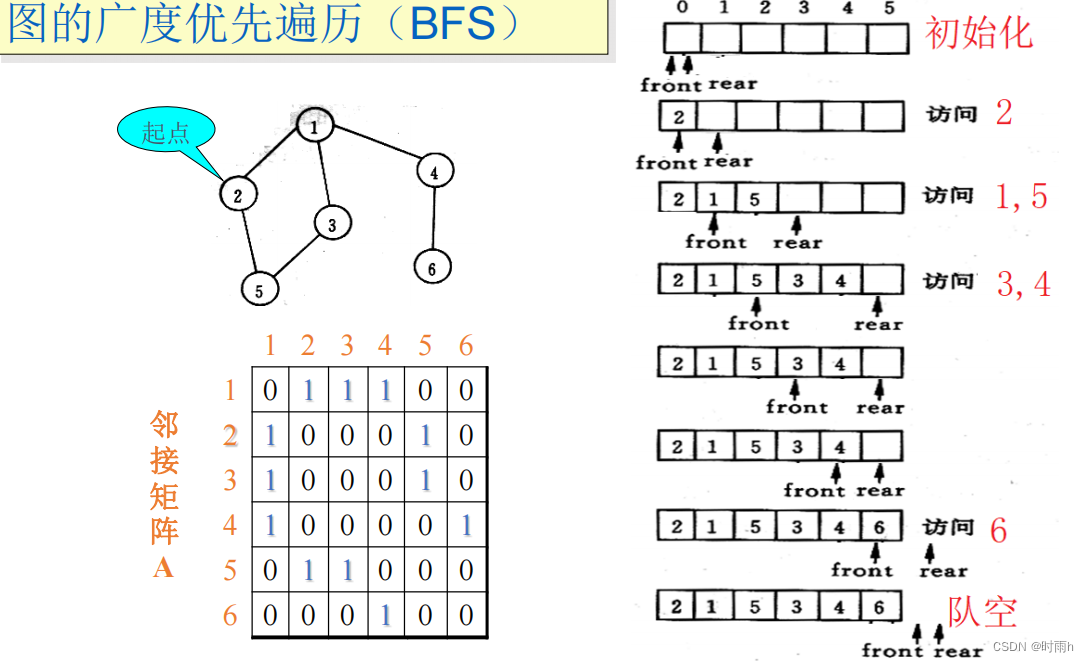
图的广度优先遍历(BFS)是另一种常用的图遍历算法,其核心思想是从图中的某个顶点开始,首先访问其所有邻居节点,然后依次访问邻居节点的邻居节点,以此类推,直到所有的节点都被访问为止。在BFS算法中,使用队列数据结构来辅助实现节点的访问顺序。下面我们来详细讲解BFS算法的实现过程。
首先,我们需要定义一个邻接矩阵来表示图的结构,其中矩阵元素的值表示对应顶点之间是否有边相连,同样地,我们使用以下的邻接矩阵表示一个图:
0 1 2 3 4
0 0 1 0 1 1
1 1 0 1 0 0
2 0 1 0 1 0
3 1 0 1 0 0
4 1 0 0 0 0
接下来,我们定义一个bool类型的数组visited[]来记录每个顶点是否被访问过,并定义一个队列queue来辅助实现BFS算法。
bool visited[MAXSIZE];
int queue[MAXSIZE];
int front = 0, rear = 0;
for(int i=0; i<MAXSIZE; i++){
visited[i] = false; //初始时,设置visited[]数组中所有元素的值为false,表示所有顶点均未被访问
}
然后,我们从某个未被访问的顶点开始进行BFS算法的实现。首先将该顶点标记为已访问,并入队列,然后开始循环遍历队列,对于队列中的每个顶点,依次访问其所有未被访问过的邻居节点,并将这些邻居节点标记为已访问并入队列。直到队列为空为止,整个BFS算法遍历结束。
void BFS(int graph[][MAXSIZE], int node){
visited[node] = true; //标记当前节点为已访问
printf("%d ", node); //输出当前节点编号
queue[rear++] = node; //当前节点入队列
while(front < rear){
//当队列不为空时继续循环
int current = queue[front++]; //出队列
for(int i=0; i<MAXSIZE; i++){
if(graph[current][i]==1 && !visited[i]){
//对于当前节点的每个未被访问的邻居节点
visited[i] = true; //标记邻居节点为已访问
printf("%d ", i); //输出邻居节点编号
queue[rear++] = i; //邻居节点入队列
}
}
}
}
最后,在主函数中调用BFS()函数,从一个未被访问的节点开始进行图的广度优先遍历。
完整的C语言代码如下:
#include <stdio.h>
#include <stdbool.h>
#define MAXSIZE 5
bool visited[MAXSIZE];
int queue[MAXSIZE];
int front = 0, rear = 0;
void BFS(int graph[][MAXSIZE], int node){
visited[node] = true; //标记当前节点为已访问
printf("%d ", node); //输出当前节点编号
queue[rear++] = node; //当前节点入队列
while(front < rear){
//当队列不为空时继续循环
int current = queue[front++]; //出队列
for(int i=0; i<MAXSIZE; i++){
if(graph[current][i]==1 && !visited[i]){
//对于当前节点的每个未被访问的邻居节点
visited[i] = true; //标记邻居节点为已访问
printf("%d ", i); //输出邻居节点编号
queue[rear++] = i; //邻居节点入队列
}
}
}
}
int main(){
int graph[MAXSIZE][MAXSIZE] = {
{
0, 1, 0, 1, 1},
{
1, 0, 1, 0, 0},
{
0, 1, 0, 1, 0},
{
1, 0, 1, 0, 0},
{
1, 0, 0, 0, 0}
};
for(int i=0; i<MAXSIZE; i++){
visited[i] = false; //初始时,设置visited[]数组中所有元素的值为false,表示所有顶点均未被访问
}
BFS(graph, 0); //从节点0开始进行广度优先遍历
return 0;
}