数仓理论
数据仓库进阶 《阿里大数据之路》第二篇 数据模型篇 (完整版)
说一下你对DWD和DWS的理解,为什么这一块要分两层?

DWD层都是什么类型的事实表?

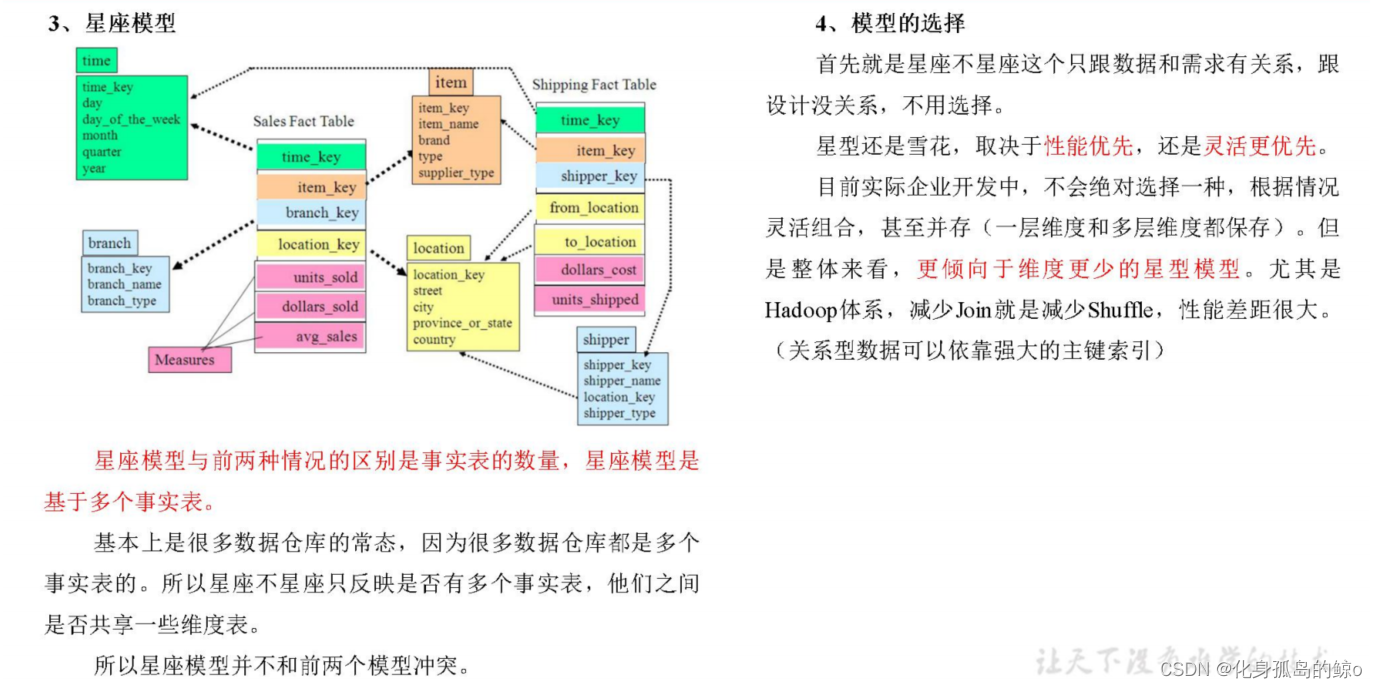
说一下三种事实表的区别

DWS层是周期快照型事实表还是事务型事实表?
你知道无事实的事实表吗?
含义: 即不包含事实或度量的事实表
分类:
(1)第一种是事实类的,记录事件的发生。例如日志类事实表,比如用户的浏览日志,对于每一次点击,其事实为1,但一般不会保存此事实。
(2)第二种是条件、范围或资格类的,记录维度与维度多对多之间的关系
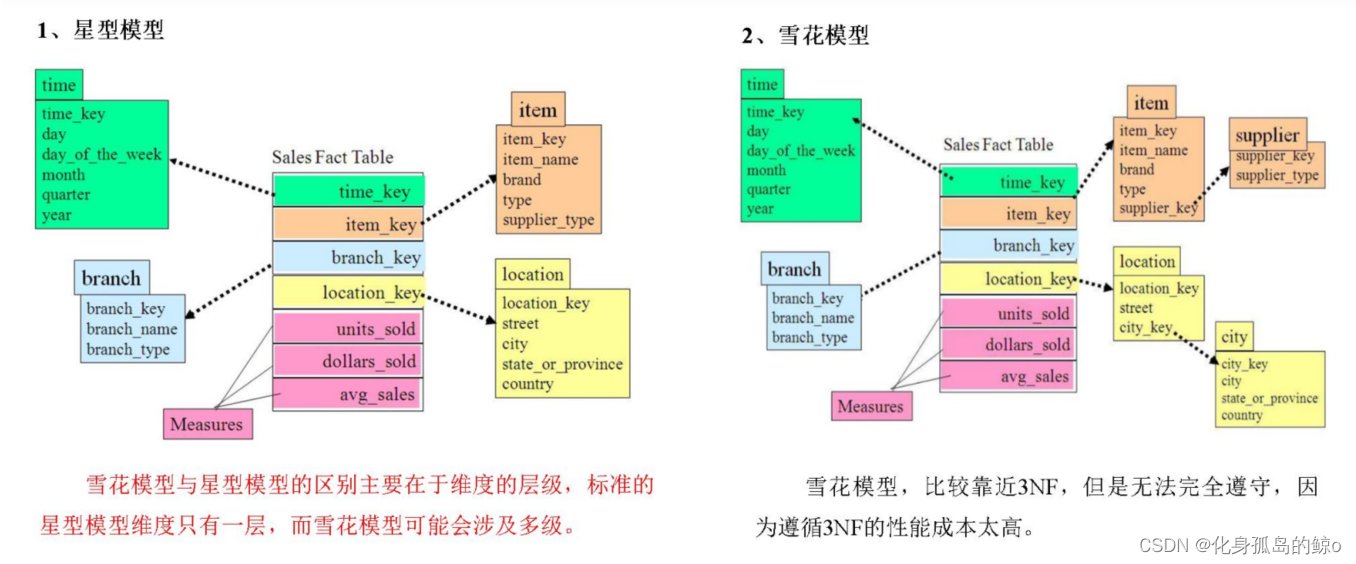
星型模型和雪花模型的各自的特点以及优缺点
数仓分层的价值在哪,为什么是分5层而不是3层或者2层?

维度退化
Hive
Hive、SparkSQL哪个更熟悉一些
Hive
Hive调优方法
Hive分桶表相关
大表join时,使用SMB join,一个分桶一个没分通,会有优化效果吗
一个表分了1000个桶,一个表分了2000个桶,有优化效果吗
HiveSQL底层执行逻辑(SQL到MR的过程)
HiveSQL题()
(1)DWD层如何向启动表导入三级嵌套的json格式数据,以及如何将表数据导出到json格式数据?
将Hive表中数据转为json:
hive正常数据转化为json数组
将hive表数据查询出来转为json对象和json数组输出
重点关注向表中导入三级嵌套的json格式数据:
考察get_json_object函数和自定义函数的使用
ods_start_log到dwd_start_log,首先创建ods层启动日志表 ods_start_log:

(1)创建输入数据是 lzo 输出是 text,支持 json 解析的分区表
DROP TABLE IF EXISTS ods_start_log;
CREATE EXTERNAL TABLE ods_start_log (`line` string)
PARTITIONED BY (`dt` string)
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_start_log';
(2)加载数据
LOAD DATA inpath '/origin_data/gmall/log/topic_start/2020-03-10'
INTO TABLE gmall.ods_start_log PARTITION(dt='2020-03-10');
注意:时间格式都配置成 YYYY-MM-DD 格式,这是 Hive 默认支持的时间格式
(3)查看是否加载成功
select * from ods_start_log where dt='2020-03-10' limit 2;
(4)为 lzo 压缩文件创建索引
hadoop jar /opt/module/hadoop-2.7.2/share/hadoop/common/hadoop-lzo-0.4.20. jar com.hadoop.compression.lzo.DistributedLzoIndexer /warehouse/gmall/ods/ods_start_log/dt=2020-03-10
创建dwd层启动日志表 dwd_start_log:

创建启动表:
DROP TABLE IF EXISTS dwd_start_log;
CREATE EXTERNAL TABLE dwd_start_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
# 下面是与启动相关的字段
`entry` string,
`open_ad_type` string,
`action` string,
`loading_time` string,
`detail` string,
`extend1` string
)
PARTITIONED BY (dt string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_start_log/'
TBLPROPERTIES('parquet.compression'='lzo');
说明:数据采用 parquet 存储方式,是可以支持切片的,不需要再对数据创建索引。
get_json_object 函数使用:
(1)输入数据 xjson
Xjson=[
{
"name":" 大郎 ", "sex":"男", "age":"25"},
{
"name":" 西门庆 ", "sex":"男", "age":"47"}
]
(2)取出第一个 json 对象:
SELECT get_json_object(xjson,"$.[0]") FROM person;
结果是:{
"name":"大郎","sex":"男","age":"25"}
(3)取出第一个 json 的 age 字段的值
SELECT get_json_object(xjson,"$.[0].age") FROM person;
结果是:25
向启动表导入数据:
INSERT OVERWRITE TABLE dwd_start_log
PARTITION (dt='2020-03-10')
SELECT
get_json_object(line,'$.mid') mid_id,
get_json_object(line,'$.uid') user_id,
get_json_object(line,'$.vc') version_code,
get_json_object(line,'$.vn') version_name,
get_json_object(line,'$.l') lang,
get_json_object(line,'$.sr') source,
get_json_object(line,'$.os') os,
get_json_object(line,'$.ar') area,
get_json_object(line,'$.md') model,
get_json_object(line,'$.ba') brand,
get_json_object(line,'$.sv') sdk_version,
get_json_object(line,'$.g') gmail,
get_json_object(line,'$.hw') height_width,
get_json_object(line,'$.t') app_time,
get_json_object(line,'$.nw') network,
get_json_object(line,'$.ln') lng,
get_json_object(line,'$.la') lat,
get_json_object(line,'$.entry') entry,
get_json_object(line,'$.open_ad_type') open_ad_type,
get_json_object(line,'$.action') action,
get_json_object(line,'$.loading_time') loading_time,
get_json_object(line,'$.detail') detail,
get_json_object(line,'$.extend1') extend1
FROM ods_start_log
WHERE dt='2020-03-10';
ods_event_log到dwd_event_log:

自定义函数UDF和UDTF:
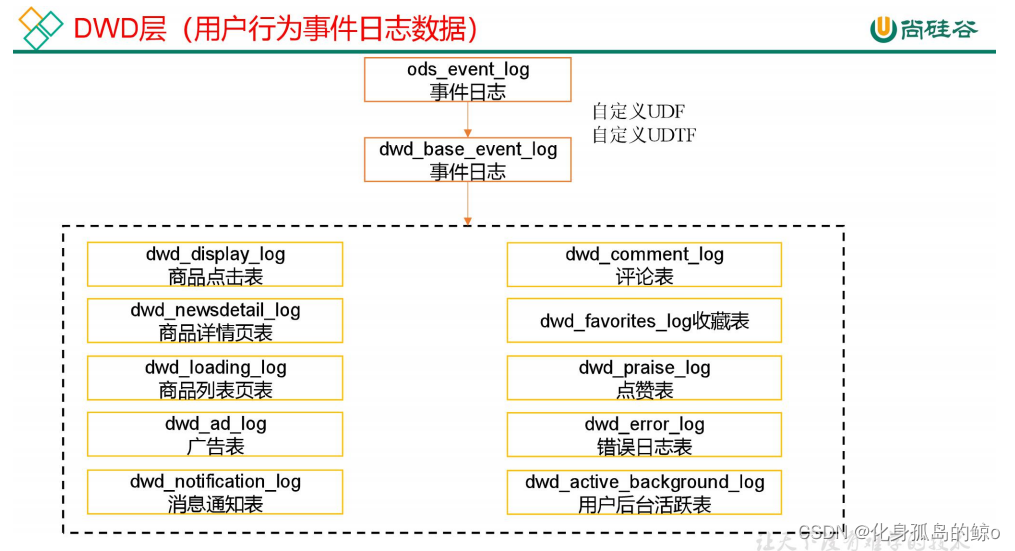
 创建基础明细表:明细表用于存储 ODS 层原始表转换过来的明细数据。
创建基础明细表:明细表用于存储 ODS 层原始表转换过来的明细数据。
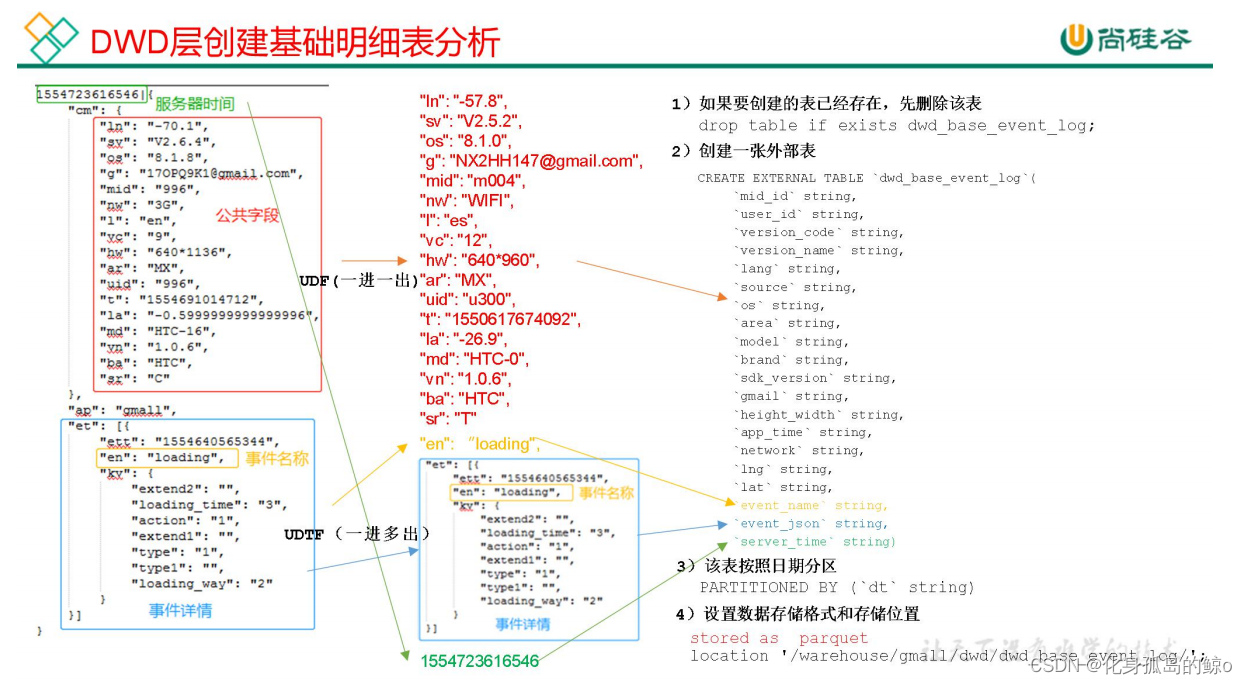
(1)创建事件日志基础明细表
DROP TABLE IF EXISTS dwd_base_event_log;
CREATE EXTERNAL TABLE dwd_base_event_log(
`mid_id` string,
`user_id` string,
`version_code` string,
`version_name` string,
`lang` string,
`source` string,
`os` string,
`area` string,
`model` string,
`brand` string,
`sdk_version` string,
`gmail` string,
`height_width` string,
`app_time` string,
`network` string,
`lng` string,
`lat` string,
# 下面是与事件相关的字段
`event_name` string,
`event_json` string,
`server_time` string)
PARTITIONED BY (`dt` string)
stored as parquet
location '/warehouse/gmall/dwd/dwd_base_event_log/'
TBLPROPERTIES('parquet.compression'='lzo');
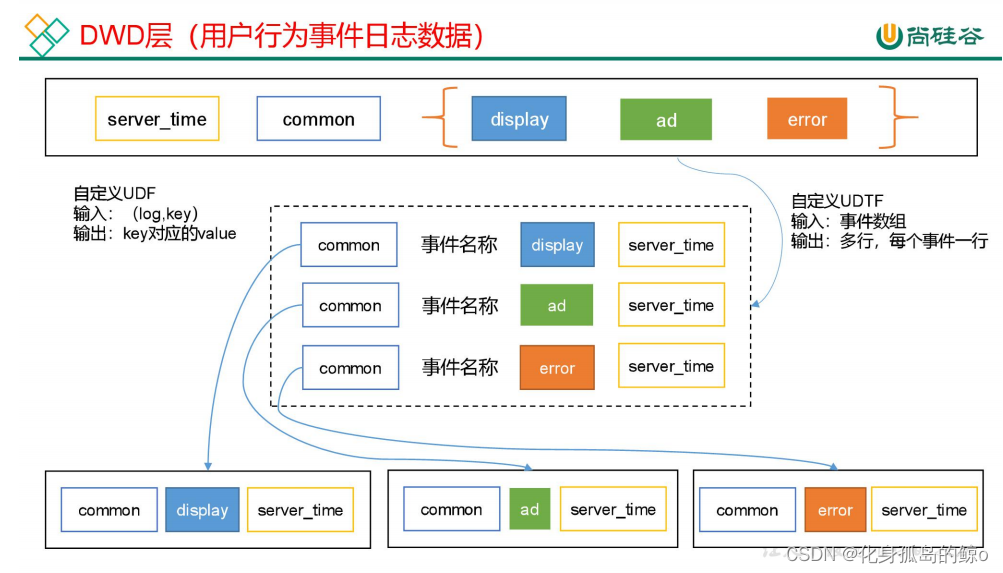
说明:其中 event_name 和 event_json 用来对应事件名和整个事件。这个地方将原始日志1对多的形式拆分出来了。操作的时候我们需要将原始日志展平,需要用到 UDF 和 UDTF。
UDF 函数特点:一行进一行出。简称,一进一出。

UDF 用于解析公共字段
package com.atguigu.udf;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.json.JSONException;
import org.json.JSONObject;
public class BaseFieldUDF extends UDF {
public String evaluate(String line, String key) throws JSONException {
String[] log = line.split("\\|");
if (log.length != 2 || StringUtils.isBlank(log[1])) {
return "";
}
JSONObject baseJson = new JSONObject(log[1].trim());
String result = "";
// 获取服务器时间
if ("st".equals(key)) {
result = log[0].trim();
} else if ("et".equals(key)) {
// 获取事件数组
if (baseJson.has("et")) {
result = baseJson.getString("et");
}
} else {
JSONObject cm = baseJson.getJSONObject("cm");
// 获取 key 对应公共字段的 value
if (cm.has(key)) {
result = cm.getString(key);
}
}
return result;
}
public static void main (String[] args) throws JSONException {
String line ="1583776223469|{
\"cm\":{
\"ln\":\"-48.5\",\"sv\":\"V2.5.7\",\"os\":\"8.0.9\",\"g\":\
"6F76AVD5@gmail.com\",\"mid\":\"0\",\"nw\":\"4G\",\"l\":\"pt\",\"vc\":\"3\",\"hw\":
\"750*1134\",\"ar\":\"MX\",\"uid\":\"0\",\"t\":\"1583707297317\",\"la\":\"-52.9\",\
"md\":\"sumsung-18\",\"vn\":\"1.2.4\",\"ba\":\"Sumsung\",\"sr\":\"V\"},\"ap\":\"app
\",\"et\":[{
\"ett\":\"1583705574227\",\"en\":\"display\",\"kv\":{
\"goodsid\":\"0\",
\"action\":\"1\",\"extend1\":\"1\",\"place\":\"0\",\"category\":\"63\"}},{
\"ett\":\
"1583760986259\",\"en\":\"loading\",\"kv\":{
\"extend2\":\"\",\"loading_time\":\"4\",
\"action\":\"3\",\"extend1\":\"\",\"type\":\"3\",\"type1\":\"\",\"loading_way\":\"1
\"}},{
\"ett\":\"1583746639124\",\"en\":\"ad\",\"kv\":{
\"activityId\":\"1\",\"displa
yMills\":\"111839\",\"entry\":\"1\",\"action\":\"5\",\"contentType\":\"0\"}},{
\"ett
\":\"1583758016208\",\"en\":\"notification\",\"kv\":{
\"ap_time\":\"1583694079866\",
\"action\":\"1\",\"type\":\"3\",\"content\":\"\"}},{
\"ett\":\"1583699890760\",\"en\
":\"favorites\",\"kv\":{
\"course_id\":4,\"id\":0,\"add_time\":\"1583730648134\",\"u
serid\":7}}]}";
String mid = new BaseFieldUDF().evaluate(line, "mid");
System.out.println(mid);
}
}
注意:使用 main 函数主要用于模拟数据测试。
自定义 UDTF 函数(解析事件字段)
UDTF 函数特点:多行进多行出。 简称,多进多出。

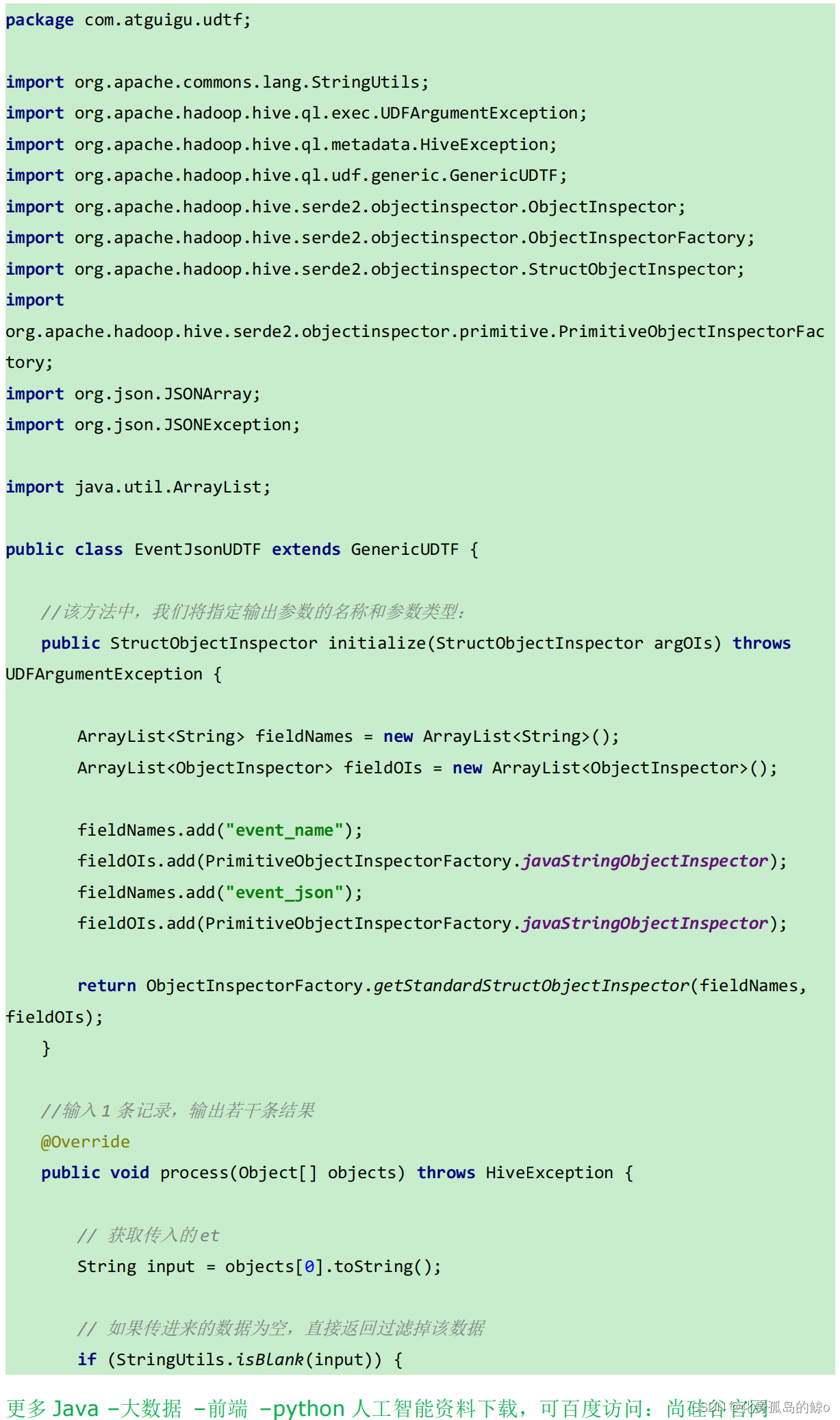

打包:

将 hivefunction-1.0-SNAPSHOT.jar 上传到 hadoop102 的/opt/module,然后再将该 jar 包上传到 HDFS 的/user/hive/jars 路径下:
[atguigu@hadoop102 module]$ hadoop fs -mkdir -p /user/hive/jars
[atguigu@hadoop102 module]$ hadoop fs -put
hivefunction-1.0-SNAPSHOT.jar /user/hive/jars
创建永久函数与开发好的 java class 关联:
hive (gmall)>
create function base_analizer as 'com.atguigu.udf.BaseFieldUDF'
using jar 'hdfs://hadoop102:9000/user/hive/jars/hivefunction-1.0-SNAPSHOT.jar';
create function flat_analizer as 'com.atguigu.udtf.EventJsonUDTF'
using jar 'hdfs://hadoop102:9000/user/hive/jars/hivefunction-1.0-SNAPSHO T.jar';
注意: 如果修改了自定义函数重新生成 jar 包怎么处理?只需要替换 HDFS 路径上的旧jar 包,然后重启 Hive 客户端即可。
解析事件日志基础明细表:
insert overwrite table dwd_base_event_log partition(dt='2020-03-10')
select
base_analizer(line,'mid') as mid_id,
base_analizer(line,'uid') as user_id,
base_analizer(line,'vc') as version_code,
base_analizer(line,'vn') as version_name,
base_analizer(line,'l') as lang,
base_analizer(line,'sr') as source,
base_analizer(line,'os') as os,
base_analizer(line,'ar') as area,
base_analizer(line,'md') as model,
base_analizer(line,'ba') as brand,
base_analizer(line,'sv') as sdk_version,
base_analizer(line,'g') as gmail,
base_analizer(line,'hw') as height_width,
base_analizer(line,'t') as app_time,
base_analizer(line,'nw') as network,
base_analizer(line,'ln') as lng,
base_analizer(line,'la') as lat,
event_name,
event_json,
base_analizer(line,'st') as server_time
from ods_event_log lateral view flat_analizer(base_analizer(line,'et')) tmp_flat as event_name, event_json
where dt='2020-03-10' and base_analizer(line,'et')<>'';
HDFS
MapReduce
MR的执行过程(MR任务的流程)
其他
你认为平台开发和数据开发的区别在哪里,哪个更有价值?
两者的主要区别:
大数据研发需要你对数据仓库理论要有一定的经验,这个岗位偏向数据处理类技能。
大数据平台开发则是需要你对Java技术栈要熟练掌握使用,这个岗位更偏向于工程类代码开发。
大数据研发偏向于数仓方面的技术理论,要能够熟练使用SQL语言。
首先,先说一下大数据研发的主要职能,就是结合公司业务数据,为公司构建数据仓库,通过业务指标数据指导运营同学,更好的运营业务,同时帮助上层领导,通过数据看清目前公司的业务发展情况,帮助其作出正确的决策。
大数据研发需要结合数据仓库理论,对于公司的数据进行加工处理,然后进行分层存储。分层的含义具体是指按照数据不同的类型,对其进行规范化命名和存储。
常见的数据分层,ODS层、DWD层、DWS层、DM层。ODS层代表原始数据层,这部分数据完全来自线上,没有经过加工处理。DWD和DWS层表示能够进行通用的公共数据明细层和公共指标数据层,这两层一般代表着公共的统一业务口径数据。DM层则是具体的业务定制化数据层,一般数据来源于DWD层和DWS层。
大数据平台开发,需要对Java技术栈掌握的扎实,同时需要对大数据组件能够使用
大数据平台开发,顾名思义,就是开发数据平台,给数据研发以及其他开发同学使用,开发数据任务。常见的两类大数据平台:离线计算平台和实时计算平台。
目前很多公司的大数据平台都是使用Java技术栈来进行开发的,首先你需要对Java语言的基础和使用要有很深入的理解。其次,目前大数据平台会使用 Spring Boot框架来进行开发,Spring 的框架你要学会使用。如果有数据治理、数据服务的经验更好。
针对不同数据平台的类型,你还需要对相关的大数据组件要有一定的使用经验和原理理解。比如你开发大数据离线计算平台,你需要对 Hadoop、Hive、Spark、Flume、HBase组件的实践要有一定的经验。
对于实时计算平台,你需要对Flink、Spark Streaming、Storm、Kafka组件要有一定的理解。
数据仓库与数据库的区别是什么?
SQL常用优化技巧
sql优化的15个小技巧
Sql优化总结!详细!(2021最新面试必问)