前文介绍了非功能性需求里的可靠性和可用性,
本文对非功能性需求里的性能,进行一些详细的说明,和如何度量系统的性能问题。
1、概念
性能通常是指一个软件系统的处理能力和速度,一般通过 延迟 和 吞吐量 这两个指标进行度量。
不同的软件系统,对于性能的要求也是不一样的,下面列举了三种系统的指标要求:
- Rest API系统
- 延迟:每个请求消耗的时间
- 吞吐量:一个周期内多少请求可以被处理(QPS)
- 大数据系统
- 延迟:数据从输入到输出的时间(事务处理时间)
- 吞吐量:处理了多少MB数据
- 存储系统
- 延迟:读写数据需要的时间
- 吞吐量:一个周期内读写了多少MB/次
2、常见性能指标
简单介绍一下常见的性能指标含义和作用:
基础硬件指标
- CPU使用率:系统正常运转时的CPU占用情况,一般建议平稳运行时不超过70%;
超过80%要进行预警,经常出现 大幅度波动也应引起警惕; - 内存使用率:系统正常运转时的内存占用情况,一般应当在80%以下;
如果内存持续上升,应考虑内存泄露可能;经常出现波动也应排查处理; - 网络IO:系统正常运转时的网络输出流量和输入流量;
网络带宽占用波动较大应考虑优化;
注意:带宽占用呈一条直线时,应考虑故障是否因为达到带宽上限导致; - 磁盘IO:系统正常运转时的磁盘读写情况;
服务性能指标
- TPS:Transactions Per Second,每秒传输的事务处理个数,用于衡量系统的吞吐量
TPS在提出时,一般用于数据库,后续也被引申到其它场景 - QPS:Queries Per Second,每秒查询次数,用于衡量系统的吞吐量
- RT:Response Time,每次请求的响应时间(含请求时间)
- 并发数:系统同时处理的请求数
比如某一时刻,某个服务有100个请求还在处理中没有响应,则此刻,该服务的并发就是100 - HPS:Hit Per Second,每次点击次数
- PV:Page View,页面浏览次数
- UV:Unique Visitor,独立用户访问次数,一般根据IP或登录用户ID进行统计
- DAU:Daily Active User,日活跃用户数,简称日活
你的系统有一万个注册用户,某天的登录用户有100个,那日活就是100 - RPS:Requests Per Second,每次请求数
注:用的很少,一般可以理解为QPS; - 响应错误率:每100个请求的平均错误次数,在Web服务压力较大时,出错的概率。
TPS与QPS的差异:
- TPS一般是一批相关联的操作进行统一计数,而QPS是对每个操作进行计数,举几个例子:
- 在web站点里,打开网站首页,向服务器发起了3个请求:首页、登录状态、新闻列表,
此时可以理解为:TPS加1,QPS加3 - 在MySql数据库里,执行一个SQL,QPS加1;执行一个事务(多条SQL),TPS加1
- 用户发起购买,一般会经历:创建订单入库、订单商品快照入库、商品库存冻结、调用支付系统去支付
那么这个购买过程,可以理解为:整个过程TPS加1,具体的4个步骤 QPS加4
- 在web站点里,打开网站首页,向服务器发起了3个请求:首页、登录状态、新闻列表,
并发数与QPS的关系:
通常情况下,并发越高,可能会导致响应时间变长,相对应的QPS也会变小,
但是这2个性能指标,都受到服务器状态、网络状态、磁盘等的影响,并不存在能互相转换的关系,
所以网上的很多文章说 并发数 = QPS * 平均响应时间,这其实是不准确的。
3、性能度量
系统性能状态介绍
参考下图:
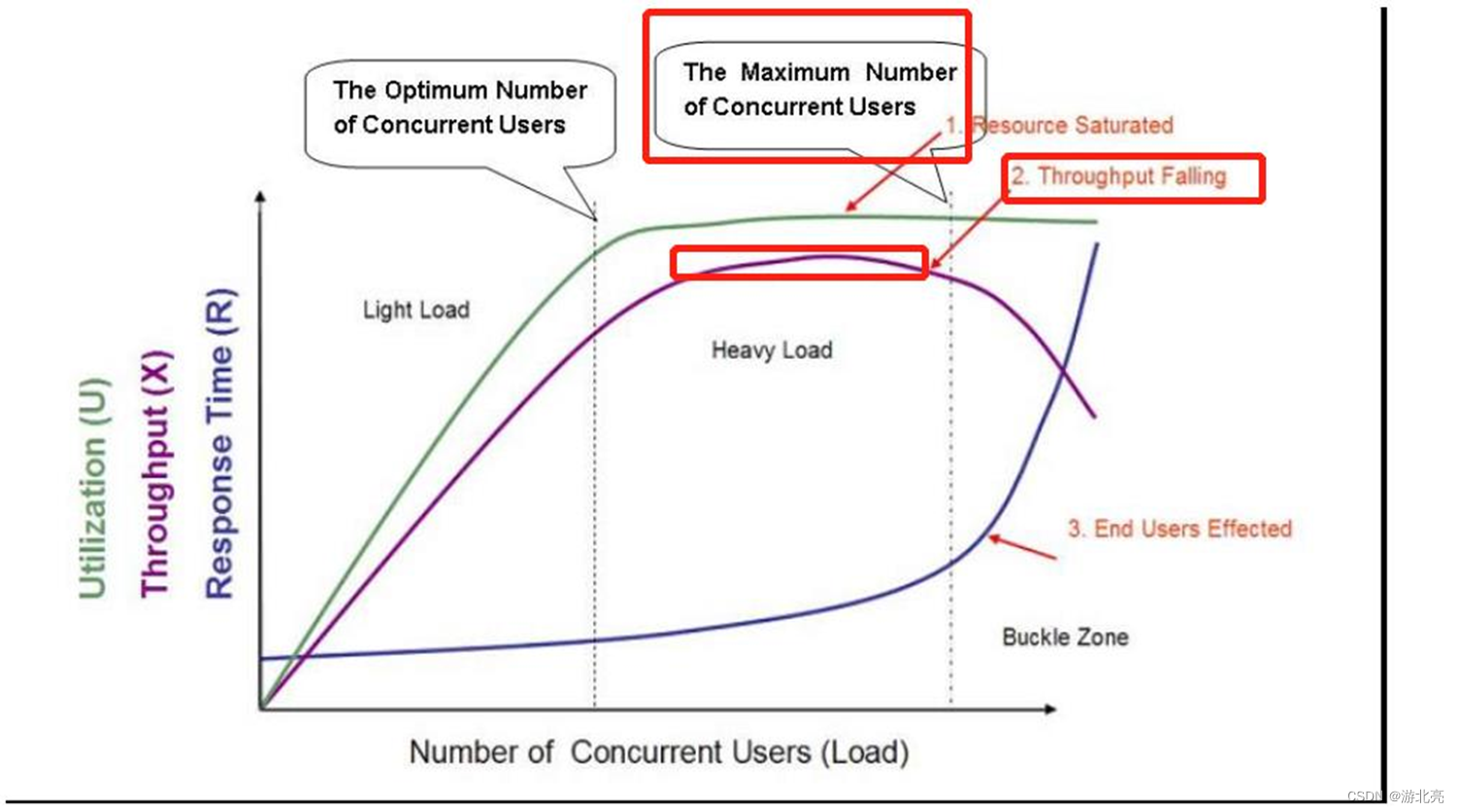
这是一个系统,随着并发用户数的增长情况,系统的状态变化过程图示,简要说明如下:
- 横坐标是并发用户数,纵坐标是有3个指标:
- Utilization绿色线:表示资源利用率,就是CPU、内存、网络IO、磁盘IO等资源的利用情况
- Throughput紫色线:表示吞吐量,比如QPS
- Response Time蓝色线:表示响应时间
- 坐标域分成三个部分:
- Light Load轻负载区,并发用户比较少
- 资源利用率比较低,存在浪费
- 吞吐量也比较低
- 响应时间最快
- 随着并发用户数的增长,资源利用率和吞吐量增长较快,响应时间变化不大
- Heavy Load重负载区,并发用户较多
- 资源利用率开始达到瓶颈
- 吞吐量也增长变缓,且后半段反而开始降低
- 响应时间有一定的变慢影响
- Buckle Zone塌陷区,并发用户数已经超负荷
- 资源利用率已达到瓶颈,基本处于高位,不变化
- 吞吐量崩溃式下跌
- 响应时间快速加大,用户无法承受或大量超时
- Light Load轻负载区,并发用户比较少
- 坐标域有两条竖线:
- The Optimum Number of Concurrent Users最优并发用户数
- The Maximum Number of Concurrent Users最大并发用户数
- 同时有三个状态描述
- Resource Saturated资源饱和:到达重负载区时,资源基本达到瓶颈
- Throughput Falling吞吐下降:重负载区红色框住的区域,系统的吞吐量开始从上升转为下降
- End Users Effected用户受影响:塌陷区,用户响应时间快速加大,已经影响我们终端用户
性能如何度量
数据收集方案:
- 压力测试
我们的系统上线前,应对系统进行压测。
我们的压测,就是希望模拟生产环境,找到我们的系统的这2条竖线:最优并发用户数、最大并发用户数
至少也要找到最优并发用户数及相关的性能指标(QPS等),并保证我们的系统负荷,尽量保持在这条竖线左右,
以达到资源的较佳利用率,同时达到较高的吞吐量和较低的响应时间。 - 生产环境监控
如果没有条件,可以收集生产环境的数据。
找出系统高峰期的QPS、RT等指标
数据收集类型:
- avg平均值:比如一天内的平均QPS、平均响应时间;
- max最大值:比如一天内的峰值QPS、最慢响应时间;
- min:比如一天内的最小QPS、最快响应时间;
- 95分位:指涵盖了95%的用户,对我们系统的使用情况
以响应时间为例,所有用户的响应时间从小到大排序,排在总数据量的95%位置的数据的值,比如1000个用户,那么排序后的响应时间,第950~959,这10个数据都可以认为是95分位,类似指标还有90分位、99分位; - 平均差:是一种衡量系统稳定性和一致性的指标。它衡量了一组数据的值与这组数据的平均值之间的差距,
公式为:(∑|x-x‘|) ÷ n,该值越小,表示所有用户的体验基本越接近;该值越大,表示不同用户的体验差距也越大。
举个螺帽的例子,要求直径1厘米±0.1,那么:- A厂生产的全是0.9厘米和1.1厘米,合规;
- B厂生产的全是0.99厘米和1.01厘米,也合规;
- 显然B厂的平均差更小,也更受客户的喜欢。
考虑一个问题:平均数能否代表我们系统的绝大多数用户?
答案是否定的,举个例子:
- 我们的系统在1小时内,收到了1000个请求
- 这1000个请求的平均响应时间是100毫秒(总耗时100秒)
- 但是有 1%的请求,响应时间超过5秒(10个请求,耗时50秒)
- 由以上推出,99%的请求,响应时间平均为50毫秒
4、性能的长尾问题
长尾的概念:
以Web系统为例,总会有一些请求的响应时间特别长,虽然这些慢请求出现的概率比较低,但是也会对系统性能和用户体验造成比较大的影响,这些慢请求的响应时间就被称之为长尾延迟。
性能指标,在实际的生产运行过程中,甚至是压测过程中,都不可避免会出现抖动:
- 网络抖动
- 磁盘IO影响
- CPU波动
- 其它(磁盘、同机器的其它APP影响等等)
我们假设,有一个业务API,它依赖了100个底层API,
假设落到最终底层API的请求,平均响应10ms,1%的响应为1s
理想情况:该业务API平均响应时间是 10ms*100 = 1s
但是:100次请求<=1s的概率只有 (99%)100 = 36.6%
请求2S,即99次<1S, 1次>=1S的概率公式 C(100,1) * 1% * (99%)99 = 36.97%
请求3S,即98次<1S, 2次>=1S的概率 C(100,2) * (1%)2 * (99%)98 = 13.23%
依赖的API越多,抖动越频繁,长尾对用户的影响越明显。
对于速度慢的系统、抖动很厉害的系统,用户会更喜欢哪个?
• avg中百分位50%:体现系统的普遍情况,表征系统的基础性能,一般仅用于参考;
• 高百分位95%/99%:体现了最差情况,表征系统的稳定、可靠程度
指标的分布越分散,用户受到长尾请求的影响越明显,举个例子:
- 有2个系统A和B,在1小时内,各收到了1000个请求
- 2个系统的平均响应时间均为1秒
- A系统有500个请求,响应时间为1毫秒,另外500个请求响应时间为1999毫秒
- B系统有500个请求,响应时间为999毫秒,另外500个请求响应时间为1001毫秒
- 这2个极端例子时,显然B系统对绝大多数用户的体验是稳定不变的,而A系统的体验是起伏不定的
一般更推荐B系统,让用户对系统的期望处于一个平衡的状态
所以,作为架构师,甚至普通程序员,对系统的关注点,一定要重点关注:
高百分位,即95分位/99分位
5、经验与实战
这里,结合我个人的经验,作一些实战方面的说明。
定义性能指标
根据我们的系统实际,定义我们的系统需要达到的性能指标,如:
- 基本模板: 如99%的user_login api应当50ms内完成
- 关注性能曲线,如所有api请求的响应时间:
- 90%<20ms
- 99%<50ms
- 99.9%<500ms
- 不同类型系统的负载分别处理
- OLTP: 小于3KB的请求<50ms
- OLAP: 95%的请求 <1s
- 引入误差预算,避免波动导致误报
- 比如1小时内,请求超过500ms的不超过10次
数据收集
- 对于核心系统,如订单模块、支付模块,建议要安排压力测试,
使用与生产环境同等配置的服务器或容器部署,测试出较优并发用户数、以及对应的QPS、响应时间等指标 - 非核心系统,如果限于资源、时间等因素,可以参考生产环境历史数据,没有历史数据则参考类似系统、API的历史数据
系统监控
常用方案:
-
增加监控,当系统的指标达到或超出收集的数据时,配置系统进行自动扩容;
我之前的经验,仅供参考:- 假设单机/单实例最优QPS为100,则在QPS超过90时,进行扩容
- QPS下跌低于60时,进行缩容
-
增加限流方案,当单机的指标超出时,进行降级处理,避免突发流量或扩容失效,导致系统宕机
我之前的经验,仅供参考:- 使用Spring Cloud Gateway作为系统网关,并使用漏斗算法进行限流
- 限流方案分几个维度:
- 系统总QPS不超过100 * 实例数,超过时返回HTTP状态码429 Too Many Requests
- 核心API按需,逐个配置限流,如果支付API,不超过 50 * 实例数
- 按模块进行限流,比如 推荐服务,非核心业务,限制为20 * 实例数
-
出现扩容、缩容、限流时,相关的事件记录,并提供每日报表输出到钉钉
扩缩容出现频次超过3次/小时,进行告警