大家好,本文同步发布在公众号算法后花园,欢迎关注。
本文从三方面介绍,对比学习基本思想,对比学习范式,以及一些思考(个人认为这部分可以出面试题)。
1. 什么是对比学习?
对比学习有的paper中称之为自监督学习[1],有的paper称之为无监督学习[2],自监督学习是无监督学习的一种形式,现有的文献中没有正式的对两者进行区分定义,这两种称呼都可以用。
即对比学习不需要知道每张图的真实标签,只需要知道到谁与谁相似,谁与谁不相似。
假设三张图都通过一个网络,得到三张图片对应的特征f1、f2、f3,我们希望对比学习可以做到在特征空间中把f1和f2拉进,且远离f3。也就是说,对比学习要达到的目标是所有相似的物体在特征空间相邻的区域,而不相似的物体都在不相邻的区域。
上面说到,对比学习需要知道谁与谁相似,谁与谁不相似,那言外之意就是,对比学习不还得需要标签信息去做有监督学习吗?对比学习之所以被认为是一种无监督的训练方式,是因为人们可以使用代理任务(pretext task)来定义谁与谁相似,谁与谁不相似,代理任务通常是人为设定的一些规则,这些规则定义了哪张图与哪张图相似,哪张图与哪张图不相似,从而提供了一个监督信号去训练模型,这就是所谓的自监督。说到这里,同学们应该明白了为什么对比学习可以叫自监督也可以叫无监督了吧。
数据增强是代理任务的实现常见手段[1]。
2. 对比学习范式是什么?
对比学习的典型范式就是:代理任务+目标函数。代理任务和目标函数也是对比学习与有监督学习最大的区别(划重点!!!)。回忆一下有监督学习的流程,输入x,通过模型输出得到y,输出的y和真实label(ground truth)通过目标函数计算损失,以此进行模型训练。而对于无监督学习或自监督学习来说,是没有ground truth的,那怎么办呢?代理任务就是来解决这个问题的,我们用代理任务来定义对比学习的正负样本,无监督学习一旦有了输出yy和真实的label,就需要有一个目标函数来计算两者的损失从而指导模型的学习方向。
代理任务和目标函数在对比学习中如何起作用?下面通过SimCLR[3]提出的对比学习框架来说明。
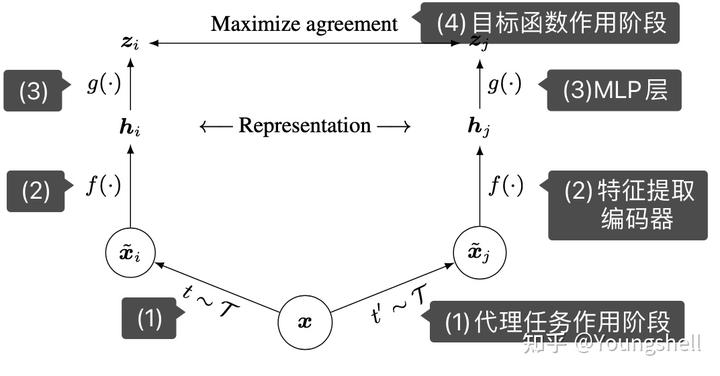
上面的框架一共包含了4部分。
(1)代理任务作用阶段。对于同一样本xx,经过两个代理任务分别生成 x ~ i \widetilde{x}_i x i和 x ~ j \widetilde{x}_j x j两个样本,simCLR属于计算机视觉领域的paper,文中使用数据增强手段来作为代理任务,例如图片的随机裁剪、随机颜色失真、随机高斯模糊, x ~ i \widetilde{x}_i x i和 x ~ j \widetilde{x}_j x j就称为一个正样本对。
(2)特征提取编码器。f(⋅)就是一个编码器,用什么编码器不做限制,SimCLR中使用的是ResNet, x ~ i \widetilde{x}_i x i和 x ~ j \widetilde{x}_j x j通过 f ( ⋅ ) f(⋅) f(⋅)分别得到 h i h_i hi和 h j h_j hj。
(3)MLP层。通过特征提取之后,再进入MLP层,SimCLR中强调了这个MLP层加上会比不加好,MLP层的输出就是对比学习的目标函数作用的地方,通过MLP层输出 z i z_i zi和 z j z_j zj。
(4)目标函数作用阶段。对比学习中的损失函数一般是infoNCE loss, z i z_i zi和 z j z_j zj的损失函数定义如下:
l i , j = − l o g e x p ( s i m ( z i , z j ) / τ ) ∑ k = 1 2 N 1 [ k ≠ i ] e x p ( s i m ( z i , z k ) / τ ) l_{i,j}=-log\frac{exp(sim(z_i,z_j)/\tau)}{\sum_{k=1}^{2N}1_{[k\neq i]}exp(sim(z_i,z_k)/\tau)} li,j=−log∑k=12N1[k=i]exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)
其中,N代表的是一个batch的样本数,即对于一个batch的N个样本,通过数据增强的得到N对正样本对,此时共有2N个样本,负样本是什么?SimCLR中的做法就是,对于一个给定的正样本对,剩下的2(N-1)个样本都是负样本,也就是负样本都基于这个batch的数据生成。上式中sim(zi,zj)sim(z_i,zj)其实就是cosin相似度的计算公式( s i m ( u , v ) = u T v / ∣ ∣ u ∣ ∣ ⋅ ∣ ∣ v ∣ ∣ sim(u,v)=u^Tv/||u||\cdot||v|| sim(u,v)=uTv/∣∣u∣∣⋅∣∣v∣∣), 1 [ k ≠ i ] 1_{[k\neq i]} 1[k=i]输入0或1,当k不等于i时,结果就为1否则为0。τ\tau是温度系数。
从上式可以看出,分子中只计算正样本对的距离,负样本只会在对比损失的分母中出现,当正样本对距离越小,负样本对距离越大,损失越小。
2. info NCE loss
对比学习损失函数有多种,其中比较常用的一种是InfoNCE loss,InfoNCE loss其实跟交叉熵损失有着千丝万缕的关系,下面我们借用恺明大佬在他的论文MoCo里定义的InfoNCE loss公式来说明。论文MoCo提出,我们可以把对比学习看成是一个字典查询的任务,即训练一个编码器从而去做字典查询的任务。假设已经有一个编码好的query (一个特征),以及一系列编码好的样本,那么可以看作是字典里的key。假设字典里只有一个key即(称为 positive)是跟是匹配的,那么和就互为正样本对,其余的key为q的负样本。一旦定义好了正负样本对,就需要一个对比学习的损失函数来指导模型来进行学习。这个损失函数需要满足这些要求,即当query 和唯一的正样本相似,并且和其他所有负样本key都不相似的时候,这个loss的值应该比较低。反之,如果和不相似,或者和其他负样本的key相似了,那么loss就应该大,从而惩罚模型,促使模型进行参数更新。
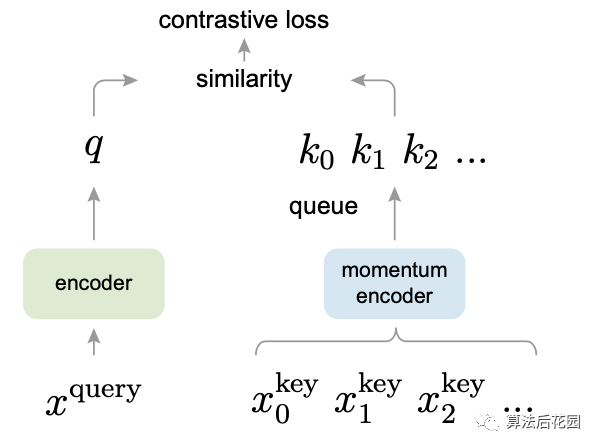
MoCo采用的对比学习损失函数就是InfoNCE loss,以此来训练模型,公式如下:
2.1 info NCE 与交叉熵
我们先从softmax说起,下面是softmax公式:
交叉熵损失函数如下:
在有监督学习下,ground truth是一个one-hot向量,softmax的结果取,再与ground truth相乘之后,即得到如下交叉熵损失:
上式中的在有监督学习里指的是这个数据集一共有多少类别,比如CV的ImageNet数据集有1000类,k就是1000。
对于对比学习来说,理论上也是可以用上式去计算loss,但是实际上是行不通的。为什么呢?
还是拿CV领域的ImageNet数据集来举例,该数据集一共有128万张图片,我们使用数据增强手段(例如,随机裁剪、随机颜色失真、随机高斯模糊)来产生对比学习正样本对,每张图片就是单独一类,那k就是128万类,而不是1000类了,有多少张图就有多少类。但是softmax操作在如此多类别上进行计算是非常耗时的,再加上有指数运算的操作,当向量的维度是几百万的时候,计算复杂度是相当高的。所以对比学习用上式去计算loss是行不通的。
2.2 NCE loss
怎么办呢?NCE loss可以解决这个问题。
NCE(noise contrastive estimation)核心思想是将多分类问题转化成二分类问题,一个类是数据类别 data sample,另一个类是噪声类别 noisy sample,通过学习数据样本和噪声样本之间的区别,将数据样本去和噪声样本做对比,也就是“噪声对比(noise contrastive)”,从而发现数据中的一些特性。但是,如果把整个数据集剩下的数据都当作负样本(即噪声样本),虽然解决了类别多的问题,计算复杂度还是没有降下来,解决办法就是做负样本采样来计算loss,这就是estimation的含义,也就是说它只是估计和近似。一般来说,负样本选取的越多,就越接近整个数据集,效果自然会更好。
NCE loss常用在NLP模型中,公式如下:
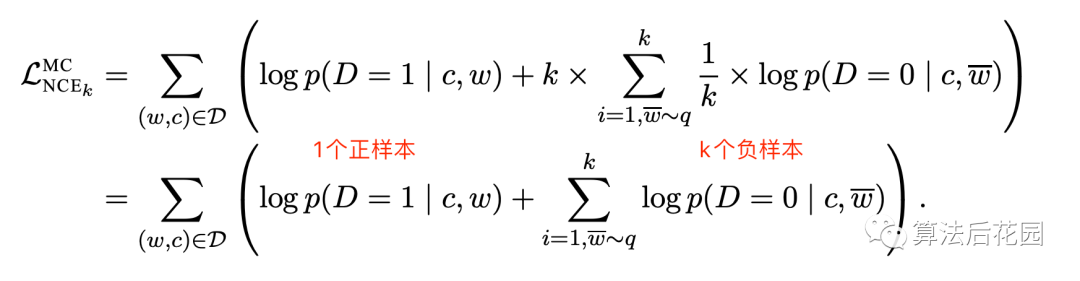
公式细节详见:https://arxiv.org/pdf/1410.8251.pdf
有了NCE loss,为什么还要用Info NCE loss呢?
Info NCE loss是NCE的一个简单变体,它认为如果只把问题看作是一个二分类,只有数据样本和噪声样本的话,可能对模型学习不友好,因为很多噪声样本可能本就不是一个类,因此还是把它看成一个多分类问题比较合理(但这里的多分类指代的是负采样之后负样本的数量,下面会解释)。于是就有了InfoNCE loss,公式如下:
上式中,是模型出来的logits,相当于上文softmax公式中的,是一个温度超参数,是个标量,假设我们忽略,那么infoNCE loss其实就是cross entropy loss。唯一的区别是,在cross entropy loss里,k指代的是数据集里类别的数量,而在对比学习InfoNCE loss里,这个k指的是负样本的数量。上式分母中的sum是在1个正样本和k个负样本上做的,从0到k,所以共k+1个样本,也就是字典里所有的key。恺明大佬在MoCo里提到,InfoNCE loss其实就是一个cross entropy loss,做的是一个k+1类的分类任务,目的就是想把这个图片分到这个类。
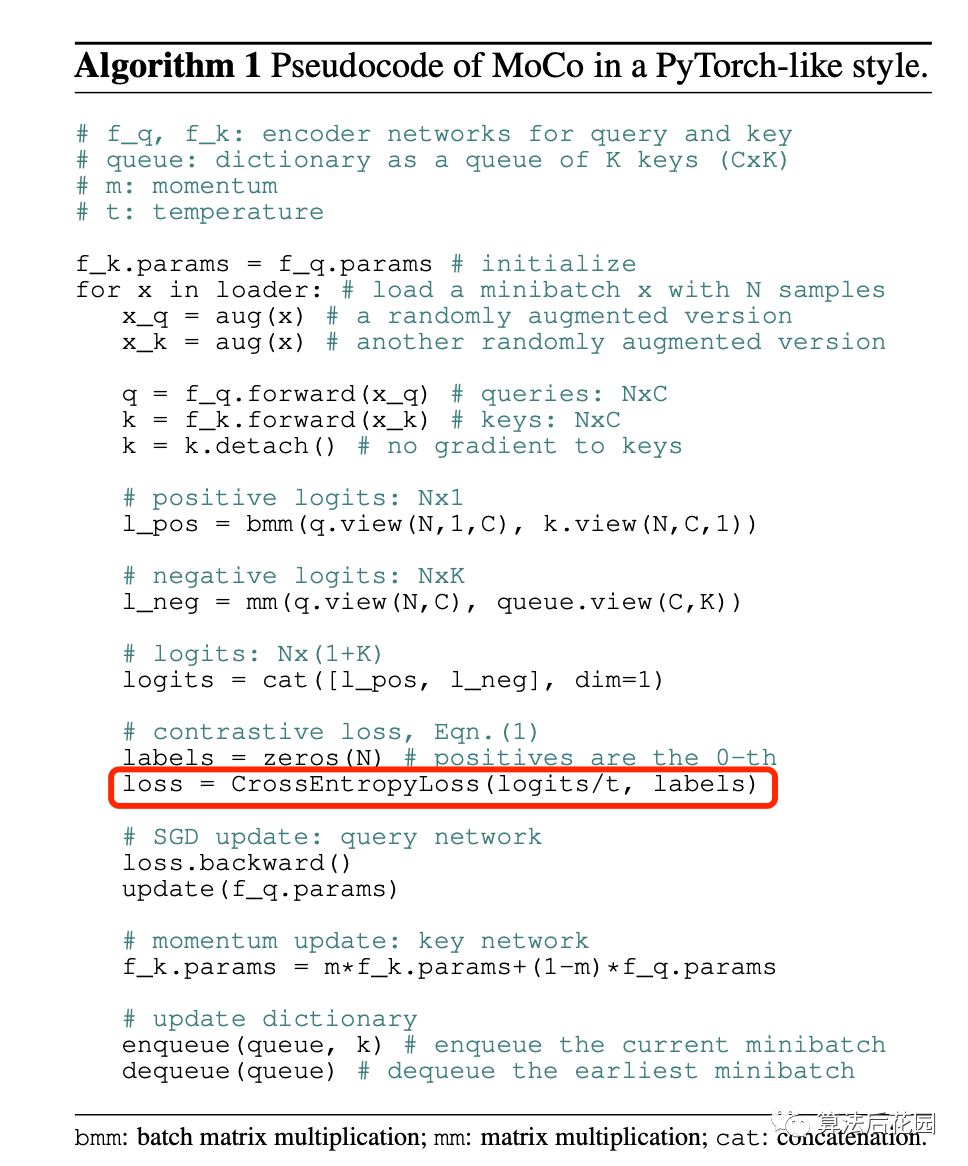
另外,我们看下图中MoCo的伪代码,MoCo这个loss的实现就是基于cross entropy loss。
3. 温度系数的作用
3.1 温度系数的作用
温度系数虽然只是一个超参数,但它的设置是非常讲究的,直接影响了模型的效果。上式Info NCE loss中的相当于是logits,温度系数可以用来控制logits的分布形状。对于既定的logits分布的形状,当值变大,则就变小,则会使得原来logits分布里的数值都变小,且经过指数运算之后,就变得更小了,导致原来的logits分布变得更平滑。相反,如果取得值小,就变大,原来的logits分布里的数值就相应的变大,经过指数运算之后,就变得更大,使得这个分布变得更集中,更peak。
如果温度系数设的越大,logits分布变得越平滑,那么对比损失会对所有的负样本一视同仁,导致模型学习没有轻重。如果温度系数设的过小,则模型会越关注特别困难的负样本,但其实那些负样本很可能是潜在的正样本,这样会导致模型很难收敛或者泛化能力差。
总之,温度系数的作用就是它控制了模型对负样本的区分度。
另外一种做法是:
只是因为对比学习是无监督的,我们没有先验知识知晓这一点,所以也会把这张猫的照片当作负例。而如果温度超参越小,则可能越会倾向把这些本来是潜在正例的数据在超球面上推远,而这并不是我们想要看到的。要想容忍这种误判,理论上应该把温度超参设置大一些。
参考
[1]Momentum Contrast for Unsupervised Visual Representation Learning.
[2]https://www.bilibili.com/video/BV1C3411s7t9
相关文章
对比学习(Contrastive Learning),必知必会
CIKM2021 当推荐系统遇上对比学习,谷歌SSL算法精读
https://zhuanlan.zhihu.com/p/471018370
[1] Self-supervised Learning for Large-scale Item Recommendations.
[2] Momentum Contrast for Unsupervised Visual Representation Learning.
[3] A Simple Framework for Contrastive Learning of Visual Representations.
[4] https://github.com/mli/paper-reading
[1]Momentum Contrast for Unsupervised Visual Representation Learning.
[2]https://www.bilibili.com/video/BV1C3411s7t9