Harp:面向跨空间域的分布式事务优化算法
庄琪钰1,2,李彤1,2,卢卫1,2, 杜小勇1,2
1 中国人民大学信息学院,北京 100872
2 数据工程与知识工程教育部重点实验室,北京 100872
摘要:近数据计算范式驱动了银行、券商在全国或全球范围内建设多个数据中心。在传统的业务模式中,事务聚焦单个数据中心的数据访问。随着业务模式的变化,跨数据中心的分布式事务成为常态,例如,银行账户之间的转账、游戏账户之间的装备交换等,而这些账户的数据存储在不同区域的数据中心上。分布式事务处理需要两阶段提交协议来保证各参与节点子事务提交的原子性。在跨空间域场景下,节点之间的网络时延更长且存在差异性,传统的事务处理技术需要拓展,以保证系统能够提供较高的吞吐量。在分析了跨域事务存在的问题和优化空间后,提出了一种新的分布式事务处理算法Harp。Harp在保证可串行化隔离级别的前提下,根据网络时延的差异,将部分子事务延迟执行,减少了事务的锁争用时长,提升系统并发度和吞吐量。实验表明,在YCSB负载下,Harp的性能比传统算法提升了1.39倍。
关键词:跨空间域分布式事务 ; 网络差异 ; 事务调度 ; 锁争用

论文引用格式:
庄琪钰, 李彤, 卢卫, 等. Harp:面向跨空间域的分布式事务优化算法[J]. 大数据, 2023, 9(4): 16-31.
ZHUANG Q Y, LI T, LU W, et al. Harp: optimization algorithm for cross-domain distributed transactions[J]. Big Data Research, 2023, 9(4): 16-31.

0 引言
2022年年初,国家完成了全国一体化大数据中心体系总体布局设计,正式启动“东数西算”工程,在京津冀、长三角、粤港澳等八大区域部署国家算力枢纽节点,建设全国一体化算力网络。数据管理正在从面向或限定于单空间域(单一数据中心)的孤立服务发展到跨空间域(跨数据中心)的协同服务阶段。分布式数据库因其高可扩展、高可用以及低成本等特点,在大规模数据的管理和分析中有着广泛应用。为了确保近数据计算,银行、电商、云计算厂商等往往会建设多个数据中心,例如,亚马逊建设有38个数据中心,苹果建设有11个数据中心(6个在美国,2个在丹麦,3个在中国)。通过这种方式,可以将用户的数据存储在最近的数据中心,当用户发起事务的读写操作仅局限于其个人数据时,近数据计算可以保证该事务具备较高的性能。然而,跨域交易打破了近距离计算的假设。跨域交易指的是一个事务涉及处在两个不同区域的用户发生的交易。例如,一个位于广东的用户需要转账10 000元给一个位于北京的用户,由于两个用户的数据存放在不同的数据中心,需要对这两个用户之间的数据进行协调。
在处理跨空间域分布式事务时,数据库的并发控制将会遇到新的挑战。两阶段封锁(two-phase lock,2PL)协议是分布式数据库并发控制的经典协议,影响该协议性能的重要指标是锁争用时长(contention span)。锁争用时长指的是从事务在执行阶段获取数据项上的锁到事务释放锁的这段时间。在网络时延的影响下,分布式事务的锁争用时长将远大于单机事务,这会限制系统的并发度并且增加系统的回滚率。在跨空间域场景下,分布式事务可能会涉及不同数据中心的多个节点,它们之间的网络时延更长,同时差异性更大。分布式事务的执行通常需要等待最“慢”的子事务(子事务所在参与者节点和协调者节点间的网络时延较大)执行完成后才可以被提交,这会导致锁争用时长进一步变长,给跨空间域分布式事务处理带来了较大的挑战。
为了在保证正确性前提下,最小化跨空间域分布式事务的锁争用时长,本文提出了新的事务处理算法Harp。Harp遵循两阶段封锁协议,因此可以保证事务的正确性。此外,Harp充分考虑了网络差异性,根据实时评估的网络时延调整子事务的执行时刻,推迟“快”子事务的执行时刻(子事务所在参与者节点和协调者节点间的网络时延较小),从而减少“快”子事务因等待“慢”子事务产生的不必要的锁争用,提高锁资源的利用率,提升系统并发度和吞吐量。实验表明,在某些场景下,Harp的吞吐量能达到传统算法的2.39倍,同时回滚率下降了32%。
1 从单空间域分布式事务到跨空间域分布式事务
1.1 单空间域分布式事务
事务是用户定义的一组数据库操作组成的序列,是数据库管理系统中的最小执行单元。分布式事务是指在事务中包含对不同节点上的数据项的操作,当服务端收到一个分布式事务时,通常将其交由一个协调者来负责。
在执行阶段,协调者将事务拆分成多个子事务并分发给各个参与者,参与者根据并发控制算法执行事务。例如,如果采用2PL作为并发控制协议,参与者将在执行阶段对数据项进行加锁,这适用于高冲突场景,但会降低系统的并发度,并且需要考虑死锁问题。如果采用乐观并发控制(optimistic concurrency control,OCC)协议,参与者在执行阶段不需要对数据项加锁,在提交前对数据项进行验证,这适用于低冲突场景。在执行阶段结束后,分布式数据库通常采用两阶段提交(two-phase commit, 2PC)协议来保证数据库的一致性。2PC协议将事务提交分成了两个阶段。在准备阶段中,协调者收集各参与者的执行状态,并根据各子事务的执行结果确定事务的最终状态。如果所有参与者都可以提交事务,那么协调者将事务状态设置为“提交”(commit)并通知各参与者;任何一个参与者无法提交,协调者都会将事务状态设置为“回滚”(rollback),同时通知所有的参与者将子事务回滚。
接下来,用实例更直观地介绍数据中心内分布式事务的执行方式。例如,事务T1可以被划分成3个子事务T11~T13,分别访问分区N1~N3,同时N1作为T1的协调者。如果使用2PL协议和2PC协议,那么事务的执行情况如图1所示,T1的子事务T12和T13,在执行阶段经过1个往返时延(round trip time, RTT)后执行完毕。又经过了1个RTT的准备阶段,协调者获得了各子事务的执行结果。在提交阶段,协调者根据各子事务的执行结果确定事务的最终状态(提交/回滚),将事务的最终状态发给参与者。参与者在收到结束信息后释放锁。因为N1→N2和N1→N3的网络差异较小,所以T12和T13的时间节点基本是同步的。在图1中, 表示数据项上的锁争用时长,在这段争用时间内,其他想对这个数据项进行操作并且锁的类型冲突的事务,都会被阻塞或者回滚。
表示数据项上的锁争用时长,在这段争用时间内,其他想对这个数据项进行操作并且锁的类型冲突的事务,都会被阻塞或者回滚。
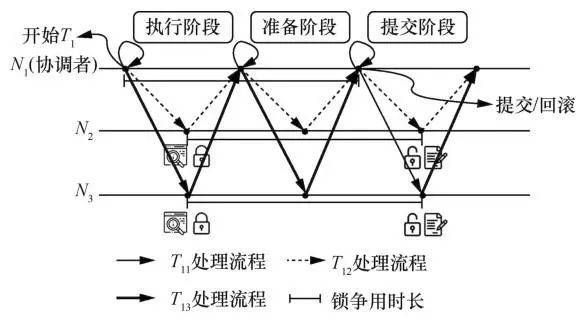
图1 单空间域分布式事务执行流程
1.2 跨空间域分布式事务
近年来,“两地三中心”“三地五中心”等概念被提出,这意味着数据库将会处理越来越多的跨空间域分布式事务。图2给出了“三地五中心”的一种示例,在纽约和北京分别部署了两个数据中心,在伦敦部署了一个数据中心,这样的架构设计满足了大规模数据增长的需求,同时保证了更高的可用性。
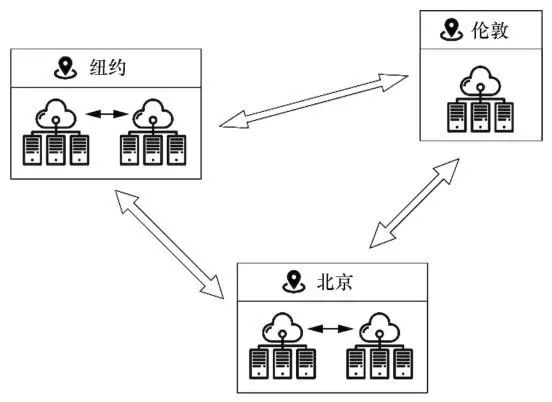
图2 “三地五中心”示意图
在分布式事务处理中,需要引入多轮的网络调度,包括两阶段提交、副本同步等。从数据中心内到跨数据中心的转变,地域间的距离决定了跨空间域网络传输具有较高的基础时延。在数据中心内部可以利用基于RDMA的高速网络技术(InfiniBand (IB)或RoCE v2)实现稳定低时延,而广域网数据的端到端传输和介质共享特性为数据传输时延带来了不确定性。如图3所示,在跨空间域网络中,通信时延通常是10 ms或更高,而数据中心内网络时延通常是微秒级,IB专用网络甚至可以达到十微秒级。相比数据中心内部,跨空间域节点之间的网络时延不可忽略,因此,跨空间域节点间的网络传输将成为制约数据库系统性能的瓶颈。
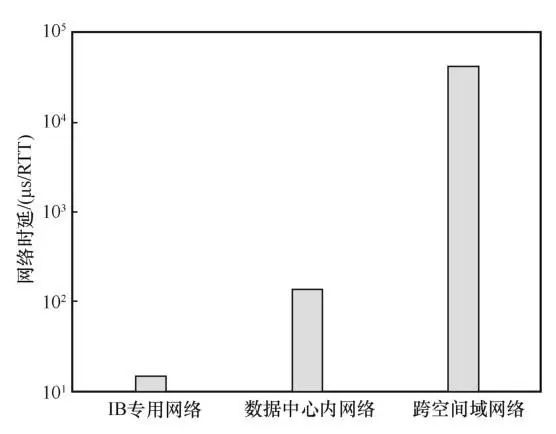
图3 不同场景下网络时延
考虑到跨空间域网络通信时延远大于数据中心内部,而分布式事务需要等待所有的子事务完成后才能确定事务最终的状态,那么跨空间域分布式事务相比于数据中心内的分布式事务,时延将进一步变长。在跨空间域场景下,图1中实例的执行情况将发生改变。如图4所示,假设N1→N3的RTT远大于N1→N2的RTT,在子事务T12执行结束后,需要等待T13返回结果后才能确定T1的最终状态。而T13的执行结果需要经过较长网络时延才能被N1知晓,这给T11和T12引入了不必要的锁争用时长。在高争用场景下,被阻塞或者回滚的事务也会随之增多。
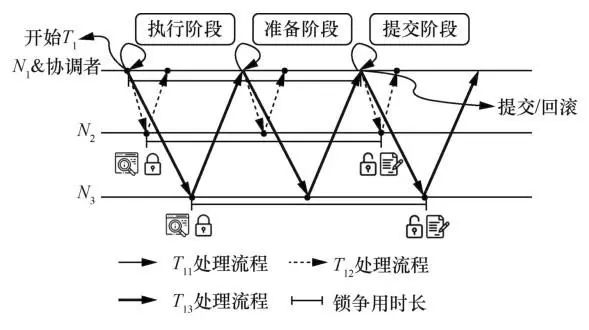
图4 跨数据中心分布式事务执行流程
2 跨空间域分布式事务的挑战
第1节以单事务场景为例,初步讨论了跨空间域场景下,网络差异对分布式事务的影响。接下来,将问题扩展到更通用的多事务场景,分析跨空间域分布式事务的问题和优化空间。
2.1 问题描述
分布式数据库将数据划分成不同的分区,为了保证近数据计算,用户数据通常被部署在距离用户较近的数据中心中。在第1节中,笔者介绍了分布式事务需要2PC协议来保证事务的原子性和隔离性,在Early-Prepare方法中,参与者节点在执行阶段后直接进入准备阶段,而无须等待协调者的通知消息。因此,锁争用时长可以从图3和图4中的2轮网络通信简化为1轮网络通信,即事务在执行阶段对数据项加锁并完成原先准备阶段的工作,在经过1轮网络通信并收到协调者的事务状态信息后,对数据项解锁并提交(回滚)事务。本文将在这种执行模型下对跨空间域分布式事务进行分析和优化。接下来,通过一个实例来更清晰地描述跨空间域分布式事务处理面临的问题。如图5所示,有3个数据库节点N1、N2和N3,其中N1与N2间的网络时延为10 ms,N1与N3间的网络时延为30 ms,N2与N3间的网络时延为25 ms。数据项x和y位于N1,数据项z位于N2,数据项u和v位于N3。
N1作为协调者来处理来自客户端的4个事务请求,其中T1涉及N1~N33个节点,其操作为R1(x)W1(y)W1(z)R1(v)W1(u);T2和T3涉及N1和N2两个节点,其中T2的操作序列为R 2(x)W2(v)W2(z);T3的操作序列为R3(x) R3(z);T4为单机事务,其操作为W4(x)。
如图6所示,数据库遵循2PL协议和2PC协议对上述实例进行调度。协调者按照操作涉及节点将T1划分成子事务T11~T12,并将它们发送给对应参与者(消息1和消息2)。在执行T2~T4时,同样会将它们拆分成多个子事务并发送给参与者(为了图片更清晰,在图中没有画出T2~T4分发子事务的消息)。接下来,在执行T11时,事务分别获得了数据项x和y上的共享锁和排他锁。同样地,T12和T13在执行时获取对应的锁,并将执行结果返回协调者(消息3和消息4)。接下来,在执行T2~T4时会发现,需要获取的数据项上的锁已经被T1占有,并且锁的类型冲突,那么T2~T4会被T1阻塞,直到T1将锁释放。
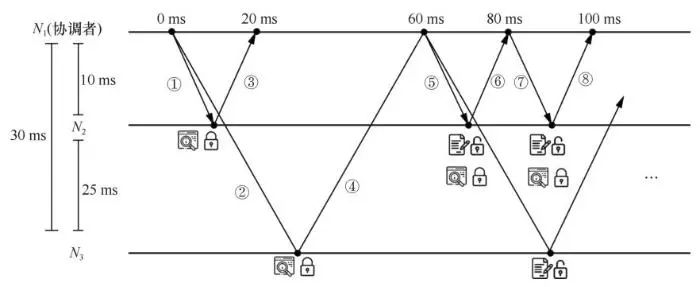
图6 2PL协议+2PC协议的执行逻辑
经过60 ms后,协调者收到了T13返回的执行结果(消息4),根据子事务执行结果确定T1的最终状态,并向各参与者节点发送(消息5)。参与者N2在10 ms后收到消息,在修改了T1的事务状态后释放其获得的锁,并从锁的等待队列中取出T22继续执行。在T22执行完毕后,向N1发送T22的执行结果(消息6)。N1在收到T2所有子事务的执行结果后,可以确定T2的最终状态并通知各参与者(消息7)。T3和T4的执行逻辑类似,可以看到,利用2PL协议和2PC协议进行事务调度时,T1~T4的执行时间为100 ms。根据锁争用时长的定义,T1~T4各数据项上锁争用时长之和分别为300 ms、60 ms、40 ms和0 ms。
2.2 优化空间
如果不通过副本迁移方法改变数据分布,分布式事务的锁争用时长至少为RTT(参与者在事务执行完毕后通知协调者,协调者在收到消息后可以随即确定事务的状态,并通知参与者释放锁)。在图6中,子事务T11和T12在执行结束后,需要等到T13的执行结果后才能确定事务的最终状态。在这段时间里,与T11和T12在数据项上存在冲突的事务都将被阻塞或者回滚,这限制了系统的并发度。本文将锁争用时长等于网络RTT的情况称为“必要锁争用”;如果锁争用时长大于网络RTT,则认为其存在“无效锁争用”现象。
在理想情况下,所有子事务的锁争用时长都不存在“无效锁争用”,即事务在单个数据项上的锁争用时长等于对应网络的RTT。那么,事务T1~T4各数据项上锁争用时长之和分别为80 ms、20 ms、20 ms和0 ms。不难看出,这与实际场景中的执行情况差异较大。随着网络时延和差异性的增大,这种现象将会更加凸显。
在跨空间域分布式事务中,各参与者节点间的时延有较大差异,会出现大量的“无效锁争用”现象。为了缓解跨空间域分布式事务对系统性能的影响,本文在不影响正确性的前提下,提出了一种新的事务处理算法Harp,通过延迟子事务的执行,减少锁争用时长,提升数据库系统的吞吐量。
3 Harp:跨空间域分布式事务优化算法
3.1 算法式描述
在图6的实例中,子事务T11和T12分别在0 ms和20 ms时刻执行完毕,但是需要等到T13返回结果才可以进入提交阶段,过早的执行T11和T12不会减少事务T1的执行时延,反而会增加数据项上的争用时长。假设本地事务的执行时间远小于跨空间域节点间网络时延,通过延迟一部分子事务的执行,可以有效地减少事务的锁争用时长。但子事务的延迟时间并不是没有约束的,以T1为例,如果T12延迟到50 ms处执行,那么它将在70 ms返回N1。在这种情况下,T1事务状态的确定时间会从原先的60 ms延长到70 ms,这是Harp不希望发生的。
Harp希望最大限度地减少事务的锁争用时长。对于事务而言,锁争用时长可以表示为:
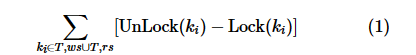
其中,ki是T需要操作的数据项,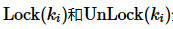 分别是T对该数据项加锁和解锁的时刻。
分别是T对该数据项加锁和解锁的时刻。
此外,Harp对加锁逻辑进行了修改。在远程事务TI的加锁过程中与当前持锁的事务TJ存在冲突时,如果TJ是本地事务,则TI可以等待,否则将TI回滚。由于本地事务的执行通常较快,在修改了加锁逻辑后,远程事务可以很快执行完毕,并将执行结果返回协调者。
根据2PC协议,在协调者收到所有子事务的执行结果后才可以确定事务的最终状态,即事务的执行时延取决于最慢的子事务。如果用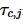 表示协调者Nc和参与者Nj之间的网络时延,根据Harp的加锁逻辑, T的执行时间可以近似表示为
表示协调者Nc和参与者Nj之间的网络时延,根据Harp的加锁逻辑, T的执行时间可以近似表示为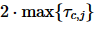 。用DelayTime(ki)表示ki所在子事务ti的延迟发送时间,那么Lock(ki)可以用
。用DelayTime(ki)表示ki所在子事务ti的延迟发送时间,那么Lock(ki)可以用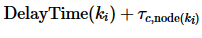 表示,而UnLock(ki)可以用
表示,而UnLock(ki)可以用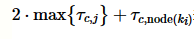 表示。可以将式(1)改写为:
表示。可以将式(1)改写为:
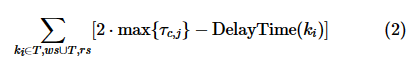
此外,Harp不希望子事务延迟执行导致事务的执行时延大于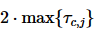 ,因此各子事务应在
,因此各子事务应在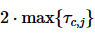 之前返回结果。结合式(2),可以写出Harp的优化目标和约束方程:
之前返回结果。结合式(2),可以写出Harp的优化目标和约束方程:
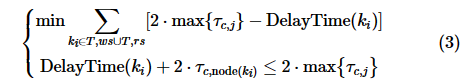
由于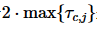 是一个常量,可以将式(3)进一步改写为式(4):
是一个常量,可以将式(3)进一步改写为式(4):
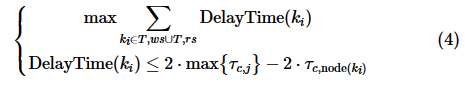
将约束方程代入目标函数得到式(5):

可以看出,在满足式(5)的取等条件时,目标函数取得最大值。设数据项ki属于子事务ti,那么的延迟时间应该满足:
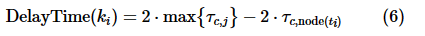
在事务进入执行阶段之前,Harp根据式(6)对子事务的发送时间进行调整,调整算法如算法1所示,该算法的时间复杂度为O(n)。
算法1:调整子事务的发送时间
输入:G:网络时延图;T:事务
输出:子事务的发送时间
1.Function Calculate Send Time (G, T)
2.max_latentcy←0, start_time←get_sys_clock()
3.for ti∈T.subtxn do
4.j←get_node (ti)
5.ti.lat←G[c][j]
6.max_latentcy←max{max_latentcy, ti.lat}
7.for ti∈T.subtxn do
8.ti.send_time←start_time+2·(max_latentcy-ti.lat)
在Harp调度下,图6中实例的执行过程将发生改变。如图7所示,在事务执行前,通过算法1计算得出T12和T13的发送时间分别为40 ms和0 ms,T11将在60 ms时执行,T21和T31延迟20 ms执行,T4为单机事务不做调整。经过调整后,T1~T4可以在60 ms内执行完毕。
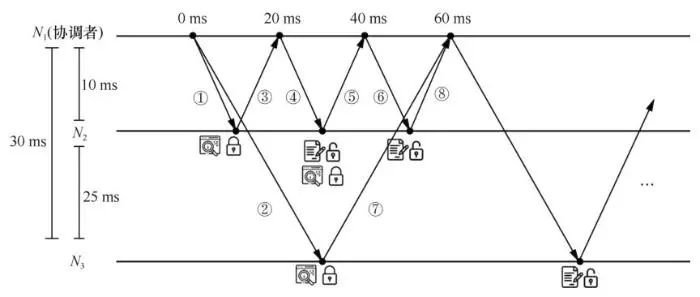
图7 优化后的执行逻辑
在0 ms处,T1~T3子事务(包括本地子事务)的延迟执行使得T4在执行W4(x)时,数据项x上并没有锁,故T4的执行不会被阻塞,并且可以立刻提交。同时,N1会将子事务T21发送给N2(消息1)、T13发送给N3(消息2)。在20 ms处,N1接收到子事务T22的返回结果(消息3),同时执行T2的本地子事务T21,并根据T21和T22的执行结果确定事务状态,并将事务状态发给N2(消息4)。经过10 ms后,N2收到该消息。在修改了T2的事务状态后,释放了数据项u的锁。此时, T32获取了数据项u的锁,并且返回执行结果(消息5)。至此,T2~T4在40 ms内执行完毕。此时,协调者N1向N2发送子事务T12(消息6)。在60 ms时,N1执行本地子事务T11,并收到了T12和T13的执行结果(消息7和消息8)。根据各子事务的执行结果确定T1的最终状态。见表1,在2PL协议和2PC协议的调度下,T2~T4需要被阻塞直到T1执行完毕。Harp将T1的子事务T11和T12延迟执行,在不影响T1的情况下,减少了T1在数据项x、y和z上的锁争用时长,使T1~T4都可以在较短的时间内执行完成。
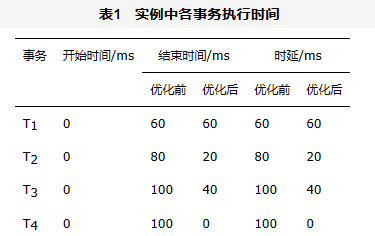
同时,Harp还调整了数据库系统发送消息的相关逻辑,如图8所示。在队列中有消息需要处理时,从消息队列的队首取出消息,比较当前系统时间和消息的发送时间。如果当前系统时间大于消息的发送时间,说明子事务需要被执行,立刻发送该消息;否则该消息包含的子事务仍可以推迟执行,将其压入队尾,并继续处理队列中的其他消息。为了进一步优化锁争用时长,在接收消息时,对涉及锁操作的消息赋予一个较高的优先级,优先将这些消息分配给工作线程进行处理。
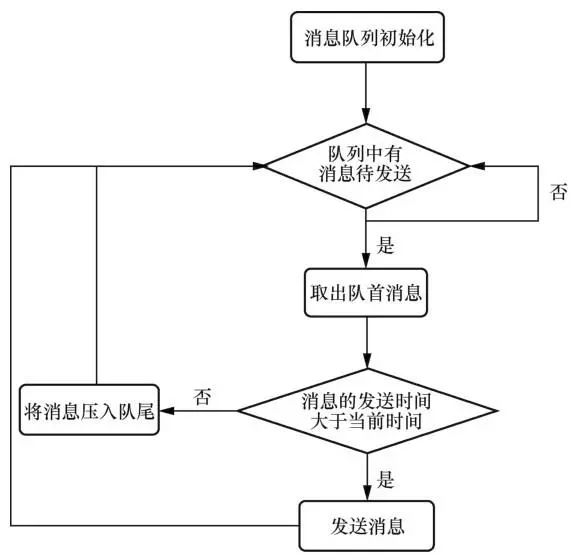
图8 发送消息流程
3.2 正确性分析
可串行化是保证事务正确调度的黄金法则。Harp会根据网络差异调整子事务执行的顺序,优化事务的锁争用时长,但加锁方式仍然遵循两阶段封锁协议。同时, Harp利用No-Wait和Wait-Die策略进行死锁预防,不会出现依赖成环的情况。众所周知,遵循两阶段封锁协议的调度满足冲突可串行化,因此利用Harp进行事务调度,仍然可以达到可串行化的隔离级别。
3.3 可行性分析
在跨空间域场景下,节点间的网络时延和差异均比较大,Harp根据操作涉及数据项的分布情况和网络特点,在不影响事务时延的基础上延迟执行部分子事务,以此缩短热点数据的锁争用时长,提高系统的并发度。Harp与确定性数据库最大的不同是Harp不需要对事务进行批处理。此外,对于不存在逻辑谓词的存储过程、单语句的交互式事务以及多语句的交互式事务的第一条语句,仍然可以利用Harp对它们进行优化。
此外,DTP模型也是当前数据库应用中处理跨域事务的方法。事务的调度可以在多个层面上实现,包括在数据库内核层面、中间件层面以及客户端层面。在DTP模型中,客户端应用通过中间件连接各数据库,并通过事务管理器(transaction manager,TM)完成2PC/3PC以保证事务的原子性和独立性。在分布式数据库中,由协调者节点负责事务的调度,而在DTP模型中,由中间件负责协调各个数据库中的事务,中间件在感知各目标节点的网络时延差异的基础上,使用本文的算法思想判断子事务的延迟时间,并延迟发送子事务,同样可以达到减少锁争用时长、提高系统并发度的效果。因此,本文算法思想在DTP模型中仍然是有效的。
3.4 针对性讨论
Harp的目标是在跨空间域场景下,利用网络时延差异,延迟部分子事务的执行时间,减少热点数据的锁争用时长。然而, Harp延迟发送的子事务可能因为数据项被其他并发的分布式事务占有而无法立刻返回,从而达不到算法预期的效果。目前的工作在遇到这种情况时会直接回滚,避免等待分布式事务。这是一种较为激进的方法,在后续的工作中可以增加元信息记录历史数据,预测各子事务从被工作线程处理到获取锁之间的时延,并对式(3)进行修正。
除了悲观并发控制算法2PL,乐观并发控制算法(OCC)、多版本并发控制(multi-version concurrency control, MVCC)等都是数据库系统中常用的并发控制算法,它们在跨空间域场景下也会遇到性能较差、回滚率较高等问题。MVCC只能支持快照隔离级别,其与2PL、OCC等结合才能够达到可串行化隔离级别,如MV2PL、MVOCC等。OCC为了保证事务的原子性和隔离性,在事务提交前会验证该事务的读写集,如果其他并发事务在此期间修改了相关数据项,会导致事务验证失败从而被回滚。在跨空间域场景下,节点之间的网络时延较长,事务从访问数据项到验证该数据项需要经历至少一轮网络通信,在这期间该数据项被修改的可能性变大,从而系统的回滚率会上升。利用Harp的技术思想,可以根据网络时延差异延迟部分子事务的执行,可以缩短对应子事务从执行到验证的时间间隔,从而减小数据项被其他并发事务修改的可能性,降低系统的回滚率。
此外,在多副本系统中副本一致性的开销在2PC协议中,而Harp的优化针对事务的执行阶段。因此,Harp的优化与副本一致性是正交的,同样可以应用在多副本系统中。在传统的2PC+Paxos事务执行逻辑中,Harp仍然可以延迟执行阶段的加锁时刻,从而缩短事务的锁争用时长。如果采用TAPIR和G-PAC这类对执行阶段进行了调整的事务执行逻辑,Harp是同样有效的。在执行阶段,TAPIR会将读写操作发给每一个副本,并在每一个副本中进行并发控制。在这种场景下,Harp在向各个副本发送读写操作前,会考虑协调者节点到各个副本的时延,将其代入算法1获得各子事务的延迟时间,通过延迟子事务的执行,仍然可以减少事务的锁争用时长,提高系统的并发度。
4 实验评估
4.1 环境测试
本文使用C++语言在分布式事务测试平台Deneva[21]中对Harp进行了实现,在相同的实验环境和实验负载下比较算法间的性能差异。共有8台服务器参与实验,每台服务器的参数见表2。其中,使用4台服务器作为客户端,另外4台作为服务端,客户端负责生成事务并发送给服务端执行。通过在网卡上增加网络时延模拟跨空间域场景,将4台服务器分为2组模拟“两地三中心”场景,城市间(跨国)的网络时延设置为300 ms,同城市的不同数据中心间的网络时延设置为25 ms,数据中心内的网络时延设置为10 ms。

本文基于YCSB负载进行性能测试。YCSB是一个模拟大规模互联网应用的综合基准测试,其数据集是1个包含10个属性的关系,其中1个属性为主键。在这个关系中,每条记录大小约为1 KB,数据集通过水平分区分布在不同节点上。2PL是悲观并发控制的经典算法,可以采用Wait-Die策略避免死锁问题,在数据库产品中有着广泛应用,例如,MySQL、OceanBase等。因此,本文的实验选择在YCSB上对2PL和Harp进行性能测试。
4.2 性能测试
首先,笔者测试了倾斜因子对吞吐量和回滚率的影响,并将结果绘制在图9中,倾斜因子越大代表热点数据的争用越严重。可以看出,Harp在测试的所有场景中性能都优于Wait-Die。通过计算,发现Harp在倾斜因子为0.8时的吞吐量相比2PL提升了1.36倍,同时回滚率下降了11%。
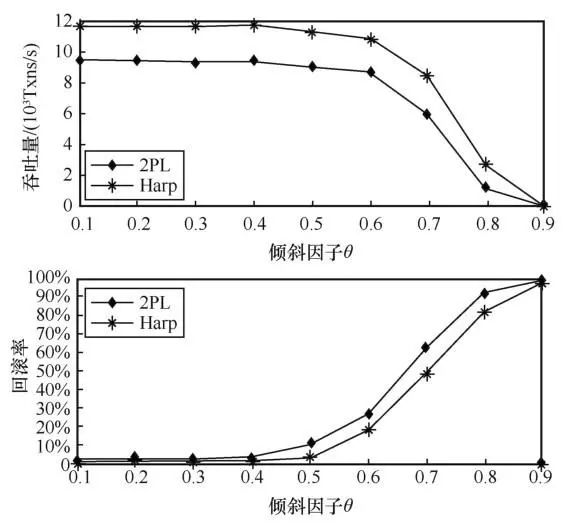
图9 不同倾斜因子的性能测试
接着,笔者在分布式事务比例固定为50%的情况下,测试了Harp和2PL在不同读写比下的性能,结果如图10所示。随着写操作比例的增加,Harp和2PL都会遇到吞吐量下降和回滚率上升的问题。可以看出,Harp的性能下降较为缓和,在写读比为0时,系统处理的事务均为只读事务, 2PL算法对读操作需要加共享锁,因此在这种场景下不会出现事务冲突,两者性能接近。随着读写事务比例的增加,Harp的性能优势逐渐明显,在写读比为100%时,即全是写事务时,Harp的性能达到了2PL的2.39倍,回滚率也远低于Wait-Die。
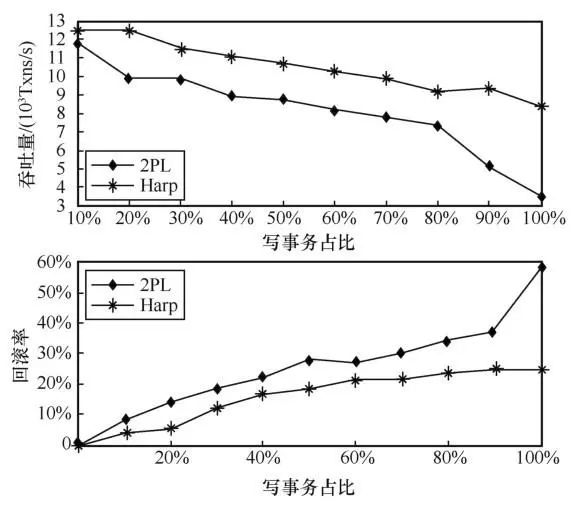
图10 不同写事务占比的性能测试
最后,在中等争用场景下(θ=0.6),测试了Harp和2PL在多种分布式事务比例中的吞吐量和回滚率,结果如图11所示。因为Harp并没有对单机事务进行优化,在处理单机事务负载时(分布式事务占比为0) 2PL的性能略好于Harp,这说明Harp的额外开销较小(2.7%)。随着分布式事务占比上升,两种算法的性能都在下降,但是Harp的吞吐量一直高于2PL。在处理跨空间域分布式事务,Harp根据网络差异推迟子事务的执行,缩短了锁争用时间。在实验中笔者统计了数据项的平均锁争用时长。实验结果表明,Harp的锁争用时长远低于2PL,在分布式事务占比为100%时,Harp的平均锁争用时长为2PL平均锁争用时长的26.8%。
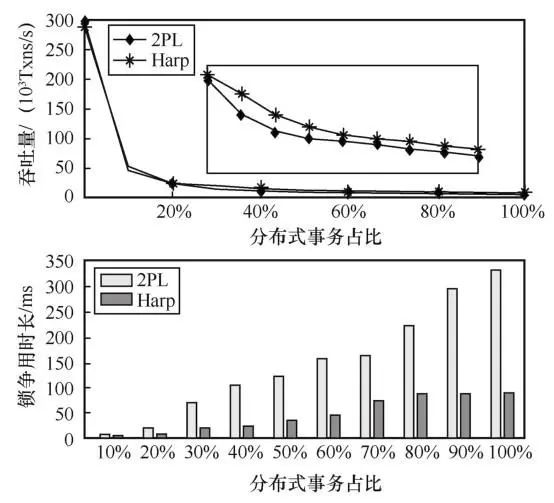
图11 不同分布式事务占比的性能测试
Harp的性能提升得益于3个方面:①Harp根据网络差异性延迟执行部分子事务,这样可以缩短事务的锁争用时长,提高了系统的并发度,同时锁资源也得到了充分的利用;②Harp修改了加锁逻辑,不会出现远程事务相互等待的现象,虽然会发生不必要的回滚,但避免了事务过长的等待时间,并且实验表明Harp的回滚率在多种场景下都低于2PL;③Harp对消息队列进行了改进,使涉及锁操作的消息能更快地被响应,进一步缩短了事务的锁争用时长。
5 相关工作
分布式并发控制算法通常可以分为静态定序算法和动态定序算法。在静态定序算法中静态地确定事务的顺序。OCC的主体思想就是在事务提交时检查数据项是否被修改或者是否能修改,通常将进入验证阶段的时间戳作为依据确定顺序。Tu等人提出的Slio就是OCC的变体,Silo维护了事务的读集和写集,在验证阶段通过检测自己的读集是否被其他事务修改来判断是否存在冲突。悲观并发控制算法,如2PL,通过对冲突数据项授予的锁的顺序对事务排序。此外,Thomson等人提出的Calvin、Aria和 Caracal等是确定性并发控制算法。在Calvin中,以批(batch)为单位处理事务,将一段时间内的事务静态定序之后按照事务顺序为事务加锁。动态定序算法会为每个事务分配一个时间戳区间,并按一定的规则在区间中选择提交时间戳。在提交事务时,动态更新调整与它有关的事务时间戳区间。Boksenbaum等人首次在分布式并发控制中使用动态时间戳调整。近年来,围绕动态时间戳调整算法的工作也有很多,如MaaT、Sundial和TicToc等。其中, MaaT利用额外的元数据和事务队列来维护数据项的访问痕迹,并记录了并发事务间的依赖关系,通过调整事务的逻辑时间戳区间的上界和下界,选择一个合理的提交区间,从而动态地确定事务之间的顺序。近年来,为了充分利用各种并发控制的优势,Liu等人基于Actor模型提出了结合确定性并发控制和非确定性并发控制的混合并发控制算法。
在高争用场景下,并发事务之间存在大量的冲突和依赖,为了保证事务的ACID原则,避免数据异常,将会导致大量的事务被回滚。产业界也提出了一些针对高争用场景下锁争用时长优化的方案。Faleiro等人提出了惰性执行方案(lazy execution scheme)和早期写可见性(early write visibility),旨在减少这些系统中的数据争用。Guo等人在Bamboo中打破了两阶段锁协议的约束,在事务执行过程中有条件的释放锁,减少了争用现象,提高了事务执行的效率。Li等人提出了SwitchTx,将部分事务逻辑下放到可编程交换机,减少网络调度的开销和数据争用。此外,Zamanian等人提出了Chiller,在事务执行之前通过事务依赖图分析得出热点数据,将热点数据放置在本地,以此减少热点数据的锁争用。
在跨空间域场景下,数据库将数据项进行分区以实现可扩展性,并利用多副本技术以实现高可用性。在处理访问多个分区的分布式事务时,Megastore、Spanner和CockroachDB需要引入多轮网络通信以完成事务的执行、2PC、日志同步以及事务状态的复制。广域网中的多轮通信导致了事务的高延迟。为了缩短延迟, MDCC、RedT和TAPIR等并行执行2PC和日志同步。Yang等人提出的Natto考虑了跨空间域网络差异,在预估事务到达最远参与者的时刻后,根据该时刻分配时间戳,以此降低高优先级事务的延迟。此外,有大量的工作聚焦于优化跨空间域的数据分布。CLOCC在客户端使用缓存。然而,客户端的缓存有限,但某些工作负载需要大量的缓存,并且保持缓存一致性会引入额外的开销。Cloud SQL Server通过限制事务只能访问单节点上的数据来避免2PC。此外,在工作负载变化时Akkio在数据中心之间移动数据,以增加数据局部性,但其并没有提供事务保证。
6 结束语
在跨空间域场景下,节点之间的网络时延更长且存在差异性,传统的事务处理算法会遇到新的挑战。本文在分析了分布式事务存在的问题和优化空间后,提出了面向跨空间域的分布式事务优化算法Harp。Harp根据网络的差异性,延迟部分子事务的执行,减少了事务的锁争用时长,同时提高了锁资源的利用率,使分布式数据库的性能得到明显提升。作为跨空间域分布式事务优化的初步研究,Harp可以为后续的跨域数据管理研究提供一定的参考价值。
作者简介
庄琪钰(2000-),男,中国人民大学信息学院博士生,主要研究方向为分布式数据库系统、事务处理。
李彤(1989-),男,博士,中国人民大学信息学院副教授,主要研究方向为新一代互联网体系结构、跨域数据管理和大数据。
卢卫(1981-),男,博士,中国人民大学信息学院教授、博士生导师,中国计算机学会数据库专业委员会委员,主要研究方向为数据库基础理论、大数据系统研制、时空背景下的查询处理和云数据库系统和应用。
杜小勇(1963-),男,博士,中国人民大学信息学院二级教授、博士生导师,主要研究方向为数据库系统、大数据管理与分析、智能信息检索。
联系我们:
Tel: 010-81055490
010-81055534
010-81055448
E-mail:[email protected]
http://www.infocomm-journal.com/bdr
http://www.j-bigdataresearch.com.cn/
转载、合作:010-81055307
大数据期刊
《大数据(Big Data Research,BDR)》双月刊是由中华人民共和国工业和信息化部主管,人民邮电出版社主办,中国计算机学会大数据专家委员会学术指导,北京信通传媒有限责任公司出版的期刊,已成功入选中国科技核心期刊、中国计算机学会会刊、中国计算机学会推荐中文科技期刊,以及信息通信领域高质量科技期刊分级目录、计算领域高质量科技期刊分级目录,并多次被评为国家哲学社会科学文献中心学术期刊数据库“综合性人文社会科学”学科最受欢迎期刊。

关注《大数据》期刊微信公众号,获取更多内容