转载自:https://blog.csdn.net/soonfly/article/details/70677138
在开发中,为了降低单点压力,通常会根据业务情况进行分表分库,将表分布在不同的库中(库可能分布在不同的机器上)。在这种场景下,事务的提交会变得相对复杂,因为多个节点(库)的存在,可能存在部分节点提交失败的情况,即事务的ACID特性需要在各个不同的数据库实例中保证。比如更新db1库的A表时,必须同步更新db2库的B表,两个更新形成一个事务,要么都成功,要么都失败。
那么我们如何利用mysql实现分布式数据库的事务呢?Mysql 为我们提供了分布式事务解决方案(https://dev.mysql.com/doc/refman/5.7/en/xa.html 这是mysql5.7的文档)
这里先声明两个概念:
- 资源管理器(resource manager):用来管理系统资源,是通向事务资源的途径。数据库就是一种资源管理器。资源管理还应该具有管理事务提交或回滚的能力。
- 事务管理器(transaction manager):事务管理器是分布式事务的核心管理者。事务管理器与每个资源管理器(resource
manager)进行通信,协调并完成事务的处理。事务的各个分支由唯一命名进行标识。
mysql在执行分布式事务(外部XA)的时候,mysql服务器相当于xa事务资源管理器,与mysql链接的客户端相当于事务管理器。
分布式事务原理:分段式提交
分布式事务通常采用2PC协议,全称Two Phase Commitment Protocol。该协议主要为了解决在分布式数据库场景下,所有节点间数据一致性的问题。分布式事务通过2PC协议将提交分成两个阶段:
- prepare;
- commit/rollback
阶段一为准备(prepare)阶段。即所有的参与者准备执行事务并锁住需要的资源。参与者ready时,向transaction manager报告已准备就绪。
阶段二为提交阶段(commit)。当transaction manager确认所有参与者都ready后,向所有参与者发送commit命令。
如下图所示:
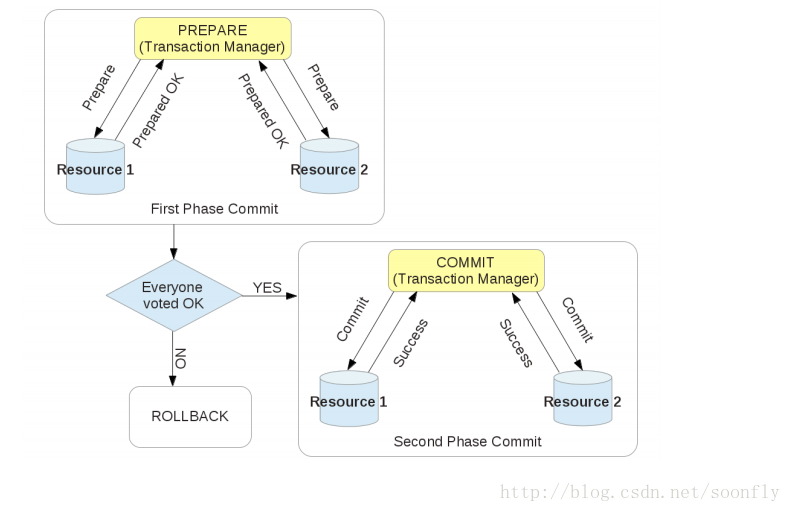
事务协调者transaction manager
因为XA 事务是基于两阶段提交协议的,所以需要有一个事务协调者(transaction manager)来保证所有的事务参与者都完成了准备工作(第一阶段)。如果事务协调者(transaction manager)收到所有参与者都准备好的消息,就会通知所有的事务都可以提交了(第二阶段)。MySQL 在这个XA事务中扮演的是参与者的角色,而不是事务协调者(transaction manager)。
Mysql的XA事务分为外部XA和内部XA
- 外部XA用于跨多MySQL实例的分布式事务,需要应用层作为协调者,通俗的说就是比如我们在PHP中写代码,那么PHP书写的逻辑就是协调者。应用层负责决定提交还是回滚,崩溃时的悬挂事务。MySQL数据库外部XA可以用在分布式数据库代理层,实现对MySQL数据库的分布式事务支持,例如开源的代理工具:网易的DDB,淘宝的TDDL等等。
- 内部XA事务用于同一实例下跨多引擎事务,由Binlog作为协调者,比如在一个存储引擎提交时,需要将提交信息写入二进制日志,这就是一个分布式内部XA事务,只不过二进制日志的参与者是MySQL本身。Binlog作为内部XA的协调者,在binlog中出现的内部xid,在crash recover时,由binlog负责提交。(这是因为,binlog不进行prepare,只进行commit,因此在binlog中出现的内部xid,一定能够保证其在底层各存储引擎中已经完成prepare)。
MySQL XA事务基本语法
XA {START|BEGIN} xid [JOIN|RESUME] 启动xid事务 (xid 必须是一个唯一值; 不支持[JOIN|RESUME]子句)
XA END xid [SUSPEND [FOR MIGRATE]] 结束xid事务 ( 不支持[SUSPEND [FOR MIGRATE]] 子句)
XA PREPARE xid 准备、预提交xid事务
XA COMMIT xid [ONE PHASE] 提交xid事务
XA ROLLBACK xid 回滚xid事务
XA RECOVER 查看处于PREPARE 阶段的所有事务
PHP调用MYSQL XA事务示例
1、首先要确保mysql开启XA事务支持
SHOW VARIABLES LIKE '%xa%'- 1
如果innodb_support_xa的值是ON就说明mysql已经开启对XA事务的支持了。
如果不是就执行:
SET innodb_support_xa = ON- 1
开启
2、代码如下:
<?PHP
$dbtest1 = new mysqli("172.20.101.17","public","public","dbtest1")or die("dbtest1 连接失败");
$dbtest2 = new mysqli("172.20.101.18","public","public","dbtest2")or die("dbtest2 连接失败");
//为XA事务指定一个id,xid 必须是一个唯一值。
$xid = uniqid("");
//两个库指定同一个事务id,表明这两个库的操作处于同一事务中
$dbtest1->query("XA START '$xid'");//准备事务1
$dbtest2->query("XA START '$xid'");//准备事务2
try {
//$dbtest1
$return = $dbtest1->query("UPDATE member SET name='唐大麦' WHERE id=1") ;
if($return == false) {
throw new Exception("库[email protected]执行update member操作失败!");
}
//$dbtest2
$return = $dbtest2->query("UPDATE memberpoints SET point=point+10 WHERE memberid=1") ;
if($return == false) {
throw new Exception("库[email protected]执行update memberpoints操作失败!");
}
//阶段1:$dbtest1提交准备就绪
$dbtest1->query("XA END '$xid'");
$dbtest1->query("XA PREPARE '$xid'");
//阶段1:$dbtest2提交准备就绪
$dbtest2->query("XA END '$xid'");
$dbtest2->query("XA PREPARE '$xid'");
//阶段2:提交两个库
$dbtest1->query("XA COMMIT '$xid'");
$dbtest2->query("XA COMMIT '$xid'");
}
catch (Exception $e) {
//阶段2:回滚
$dbtest1->query("XA ROLLBACK '$xid'");
$dbtest2->query("XA ROLLBACK '$xid'");
die($e->getMessage());
}
$dbtest1->close();
$dbtest2->close();
?>XA的性能问题
XA的性能很低。一个数据库的事务和多个数据库间的XA事务性能对比可发现,性能差10倍左右。因此要尽量避免XA事务,例如可以将数据写入本地,用高性能的消息系统分发数据。或使用数据库复制等技术。只有在这些都无法实现,且性能不是瓶颈时才应该使用XA。
查询缓存
MySQL查询缓存保存查询返回的完整结果。当查询命中缓存,MySQL会立刻返回结果,跳过了解析,优化和执行阶段。
查询缓存执行过程:
1.通过一个大小写不敏感的检查看看SQL语句是不是以SEL开头。
2.若是以SEL开头则获取缓存数据,若是命中则直接返回结果。
3.若没有命中,则通过SQL语句查询数据。
4.返回查询结果给客户端。同时存入查询缓存,但不是所有的查询结果都会存入查询缓存,详细见下面。
缓存未命中可能的情况:
1.由于查询语句中包含不确定的函数,或者查询结果太大,超过query_cache_limit的值,查询结果无法缓存。
2.MySQL从未处理过这个查询,查询结果没有缓存过。
3.之前缓存了查询结果,但是由于查询缓存内存不足,MySQL将某些缓存逐出,导致未命中。
4.缓存失效操作太多。数据修改,内存不足,缓存碎片都会导致缓存失效。
5.查询缓存还没有完成预热,MySQL还没有机会将查询结果都缓存起来。
不会缓存结果的情况:
1.当查询语句中有一些不确定的数据时,则不会被缓存。如包含函数NOW(),CURRENT_DATE()等类似的函数,或者用户自定义的函数,存储函数,用户变量等都不会被缓存。
2.当查询的结果大于query_cache_limit设置的值时,结果不会被缓存。
3.对于InnoDB引擎来说,当一个语句在事务中修改了某个表,那么在这个事务提交之前,所有与这个表相关的查询都无法被缓存。因此长时间执行事务,会大大降低缓存命中率。
4. 查询缓存系统会跟踪查询中涉及到的每个表,如果这些表发生变换,那么和这个表相关的所有的缓存数据都将失效。(这种机制看起来效率较低,因为数据变化时很有可能对应的查询结果并没有变更,但是这种简单实现代价很小,而这点对于一个非常繁忙的系统来说非常重要)
查询缓存带来的额外消耗:
1.在查询之前必须先检查是否命中缓存。
2.如果这个查询可以被缓存,那么执行完成后,MySQL发现查询缓存中没有这个查询,则会将结果存入查询缓存,这会带来额外的系统消耗。
3.写入或更新数据时,MySQL必须将对应表的所有缓存都设置失效。如果查询缓存很大或者碎片很多时,这个操作可能带来很大的系统消耗。
查询缓存内存使用:
在查询开始返回结果的时候就分配空间,而此时无法预知查询结果有多大,所以MySQL无法为每一个查询结果精确的分配缓存空间。
当需要将查询结果缓存的时候,MySQL先申请一个数据块存储结果,不论结果大小,都会至少申请一个query_cache_min_res_unit的空间,然后将结果写入数据块,若申请的数据块不足以存储结果,那么再申请一个数据块,直到全部存储完成。
当查询完成后,如果申请的内存空间还有剩余,MySQL会将其释放,并放入空闲内存部分,这样是不会产生碎片。
通过下面的步骤来验证这个问题:
设置的分配内存块的最小单位为4kb。
首先执行 show status like 'qcache%'; 查看缓存使用情况。
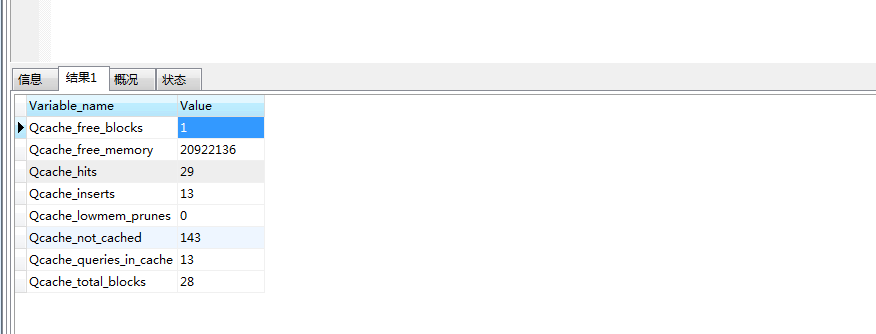
此时可以看到Qcache_free_blocks的值为1,说明有一个空闲块。
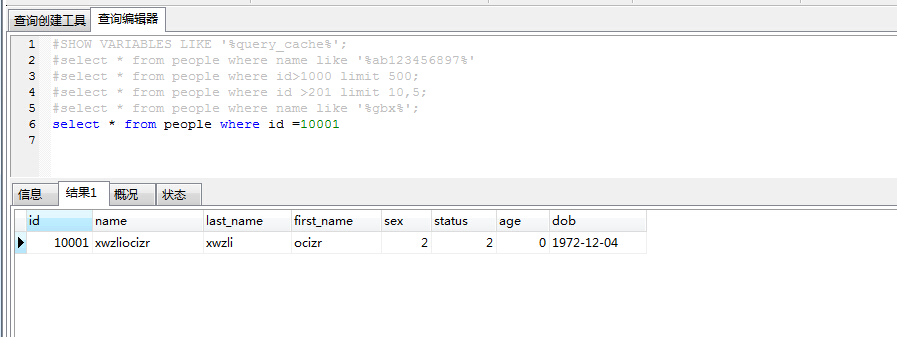
现在执行一条查询语句 select * from people where id =10001,数据远远小于4kb,且之前没有被缓存。
然后再执行 show status like 'qcache%'; 查看缓存使用情况。
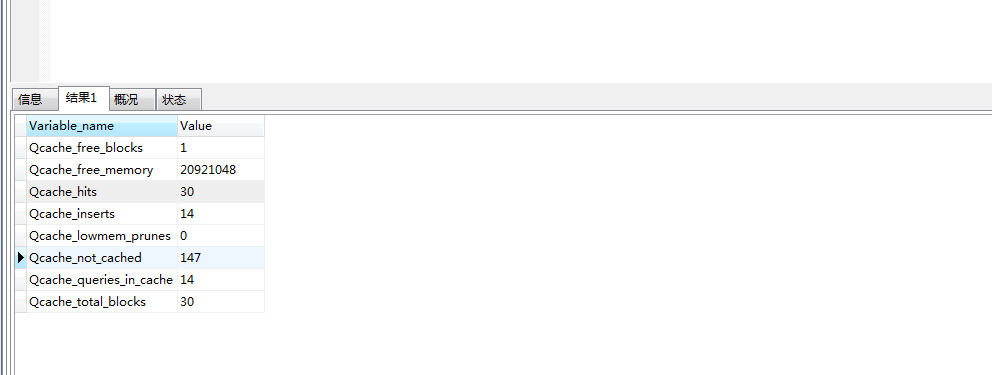
而此时还是只有一个空闲块,说明在没有并发查询的情况下,MySQL会将存储查询结果后产生的剩余空间释放,不会产生碎片。
碎片如何产生:
假设查询的结果非常小,服务器在并发的向两个链接返回结果,这是在向A和B两个内存块写入数据,返回完结果后回收剩余的空间时,A剩余的空间小于query_cache_min_res_unit设置的值,这样就不能再次被查询缓存使用,从而产生了碎片,B剩余的空间则会释放,并入空闲内存部分。
除此之外,如果在缓存失效时,可能导致留下太小的数据块无法在后续缓存中使用(就是小于query_cache_min_res_unit了)
具体的关于查询缓存和缓存内存使用和分配信息请阅读高性能mysql第309-317页
如何减少碎片:
1)选择合适的query_cache_min_res_unit,减少有碎片导致的内存空间浪费。设置合适的值可以平衡每个数据块的大小和每次存储结果时内存块申请的次数。值太小浪费的空间少,但是内存申请会比较频繁;值太大,那么碎片会太多,浪费内训资源
2)使用flush query cache 完成碎片整理。这个命令会将查询缓存重新排序,并将所有的空闲空间都聚集到查询缓存的一块区域上。该命令不会将查询缓存清空,该命令会访问所有的查询缓存,在这期间任何其他的链接都无法访问查询缓存,从而会导致服务器僵死一段时间,使用这个命令需要异常小心这一点。建议保持查询空间小一点,以便维护时可以将服务器僵死控制在非常短的时间内