前面的话:这次的实验是分为ABC三级,如图,大部分同学都会选择A或B级,本组选择微博管控(B级),但也成功实现对图片和视频的分析(A级)加入数据库,界面友好,对一种功能进行多种实现方式,选择最优效果(加分项),由于整个项目很大,这里仅提供我们小组的实验报告,对每一个模块都提供链接,学弟学妹根据实际情况按需参考。
B级主体下载链接:https://download.csdn.net/download/weixin_45937957/85596578

目录
第一章 摘要
本系统是基于python机器学习的微博流量分析与管控系统,主要针对微博的所有文字信息、图像信息和音视频信息进行捕获、分析和管控等。
本系统会针对微博热搜榜进行爬虫,并预处理过滤筛除热搜榜单上的广告信息,且针对每个有效的热搜词条进行链接提取,分别进入其话题广场通过热文提取其主要内容(包括图像、视频)等,针对主要内容不健康、不正常的话题可以在话题中发正能量内容的帖子进行话题管控。
本系统同时还会针对一个微博用户所发过的所有微博内容进行爬虫(包括主页信息、个人资料、文字、视频、图像、每条微博的url等),通过预处理将不同类型的信息分类后保存并显示,针对其每个微博的内容进行特征词提取和文本分类,主要分类为:是否色情敏感、是否暴力敏感、是否人身攻击、是否不良价值导向,若有相应风险微博将予以警报,用户可将发出警报的微博的url复制到举报或评论区淹没处,举报将对应类型举报到微博服务器,评论区淹没则会从正能量评论库中取出内容进行评论区淹没。
本系统对色情、犯罪(抢劫,枪击,打架斗殴)、异常(车祸、爆炸)等音视频进行检测与分类,对色情图片以概率,从0到1,作为输出;对犯罪、异常视频将得到可视化结果,经过训练,已经得到94%的准确率。
本组在完成了实验的基本要求后,附加了数据库、生成词云、拥有精致界面、图像的分类识别、视频的分类识别等多项附加功能。
第二章 项目介绍
2.1背景分析
微博网页版是微博各种版本中最不易爬取的动态网页,虽然微博已经针对内容进行了大量的管控使得大部分不良信息不得以出现,但仍有一些信息通过稍隐晦方式逃避了微博的内容识别得以展现在大众视野,例如饭圈文化中的粉丝互撕、擦边色情图片、抑郁悲观情绪渲染等。
除这些不良价值信息外,还有一部分信息值得我们关注,2021年11月25日一个25岁的年轻摄影师在微博平台发布自己的遗书后跳海自杀,当被人发现时已经去世,除了他之外,几乎每天都有一些抑郁患者在微博宣泄情绪,如果能即使发现在这些人的呼救,给予正能量的鼓励,也许会挽救一条条鲜活的生命。
在网络上也可能会有异常的音视频流出,如厂房爆炸,车祸现场,打劫斗殴等,若这种异常的视频能够被管理员尽早检测,就可能争取更多人生存下去的机会
本系统正基于以上背景,创新性基于机器学习、深度学习、图像视频识别等多项技术推出了文字信息、音视频信息、图像信息的识别及分类,各类信息的多方管控功能。
2.2特色描述
1.基于selenium和微博api接口的动态网页安全爬虫
微博网页版在安全性方面有一定的限制,因此当selenium在测试时频繁通过chorme浏览器测试访问微博网页时,微博会限制访问,导致访问次数变慢,同时基于selenium的爬虫需要自动登陆账号(chorme不会记住登陆状态)并通过安全验证,安全验证必须人为手机扫码验证(防止恶意刷),因此selenium会影响一些功能的效率,而且有被限流的风险。
微博api是微博为开发人员专门准备的接口,但功能是有限的,本系统中的评论功能是通过微博api评论写入接口完成的,但同时也不能放发送的太过频繁否则容易产生丢包、服务器不接受等问题,同时微博api自最近一次更新后要求发送微博的接口需要安全域名,需要下载特定文件到二级域名服务器,对于个人开发来说不易实现,因此这里仅用其提供的写评论api接口。
2.基于WM算法的模式识别
在给文本信息分类前首先要进行特征词提取,本系统使用WM多模式匹配算法进行特征词的提取,WM算法速度快、效率高、正确率高。
3.基于机器学习朴素贝叶斯的文本分类算法
分类算法使用的朴素贝叶斯分类器,将四类不同文本的特征词和结果作为学习集输入,当从某篇微博提取到的特征词输入时,算法会自动进行分类并计算类别概率,分类准确率较高。
4.词云的生成
输入某篇微博的url,系统将爬取该微博的前30+条评论内容,并通过结巴分词、语气词剔除后生成多彩词云图
5. 对微博某固定用户的爬虫
输入某用户的微博id号,可以爬取从近期开始的所有该用户发表过的文本和图片,全部保存在本地文件夹下。
参考链接:https://www.omegaxyz.com/2018/02/13/python_weibo/
6. 数据库的设计
设计数据库存储热搜和热搜详情,在爬取热搜的时候存入数据库,但是用户个人的微博文本、图片、视频将会存储在本地。
7. 基于grb颜色模式识别色情图片
使用 Python3 去识别图片是否为色情图片,我们会使用到 PIL 这个图片处理库,会编写算法来划分图像的皮肤区域。
根据颜色(肤色)找出图片中皮肤的区域,然后通过一些条件判断是否为色情图片。
输入: python erotic_picture.py -v 3.jpeg 其中,3.jpeg是文件路径
输出: True 3.jpeg JPEG 482×464: result=True message=‘Nude!!’
判断出此图是一个色情图片
8. 基于卷积神经网络的图片识别
需要指定色情图片的路径作为参数,经过测试就可以生成测试结果,例如:
输入:python nsfw_predict.py /tmp/test/test.jpeg
输出:{‘class’: ‘sexy’, ‘probability’: {‘drawings’: 0.008320281, ‘hentai’: 0.0011919827, ‘neutral’: 0.13077603, ‘porn’: 0.13146976, ‘sexy’: 0.72824186}},类别后面的是该类别的概率,0为概率为零,1为概率为1
其中:

9. 监控视频中的现实世界异常检测
用两种方式实现,都有可视化输出。
在弱监督下训练,在一段视频中,只关心是否有异常事件的存在,而不关心具体的异常类型以及异常发生在哪些帧内。一个实际的异常检测系统的目标是及时发出偏离正常模式的活动的信号,并识别所发生的异常的时间窗。因此,异常检测可以看作是粗糙层次的视频理解,它可以过滤掉正常模式中的异常。一旦检测到异常,可以使用分类技术将其归为特定活动之一。
只需要在config里指定需要检测的视频路径,就可以在output文件夹里获得视频分析后的gif图像化页面。
10. QT的设计
使用QT设计GUI页面,连接上述功能的接口使之成为一个完整的整体,使得页面有好。
下面展示一些:
欢迎页面:
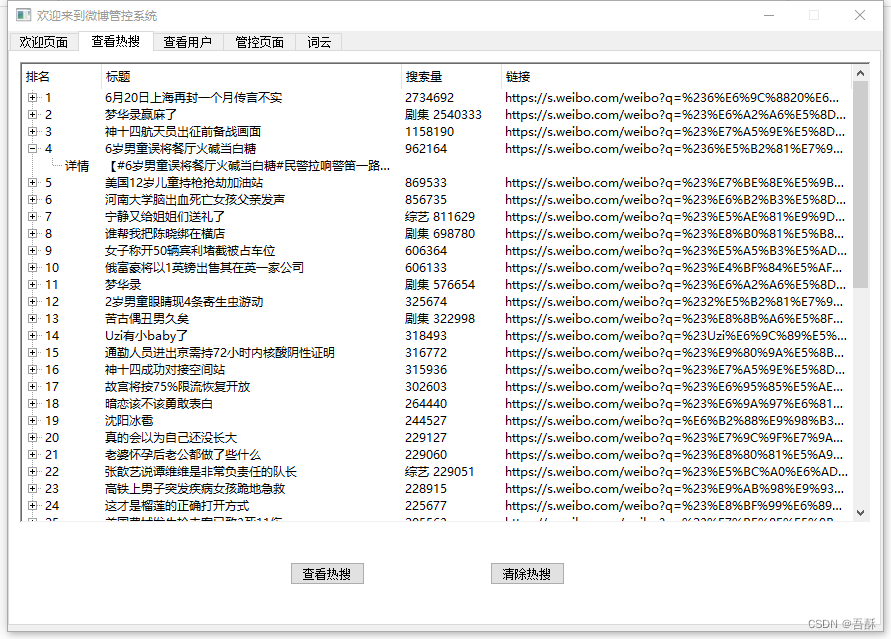
查看热搜:
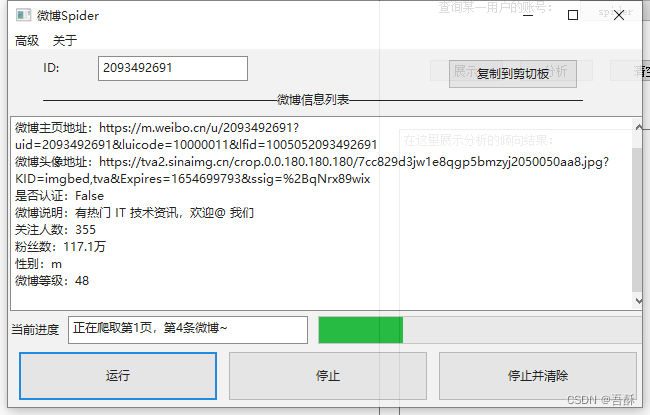
爬取某一指定用户的微博(图片和文字),这个是借鉴大神spider,参考链接:https://www.omegaxyz.com/2018/02/13/python_weibo/
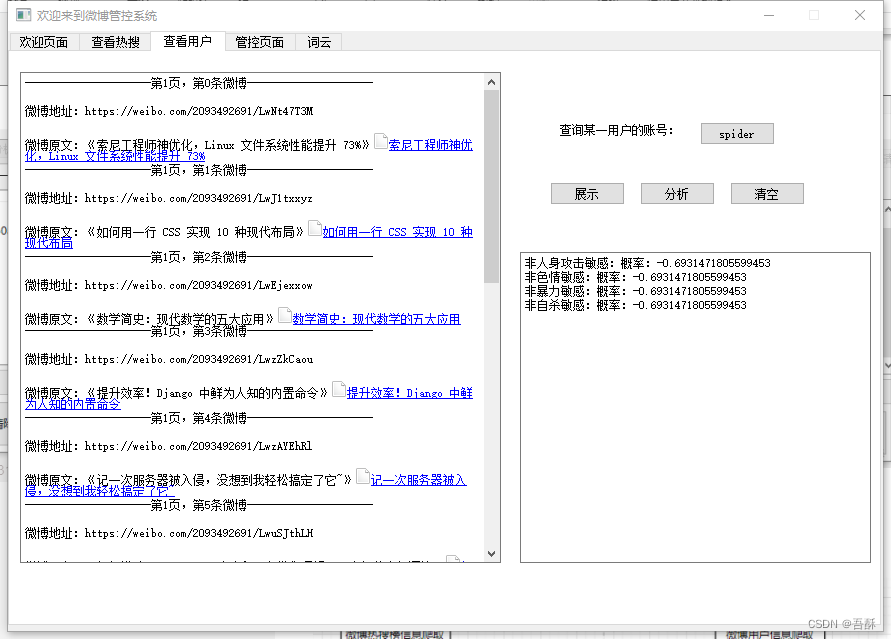
分析该用户
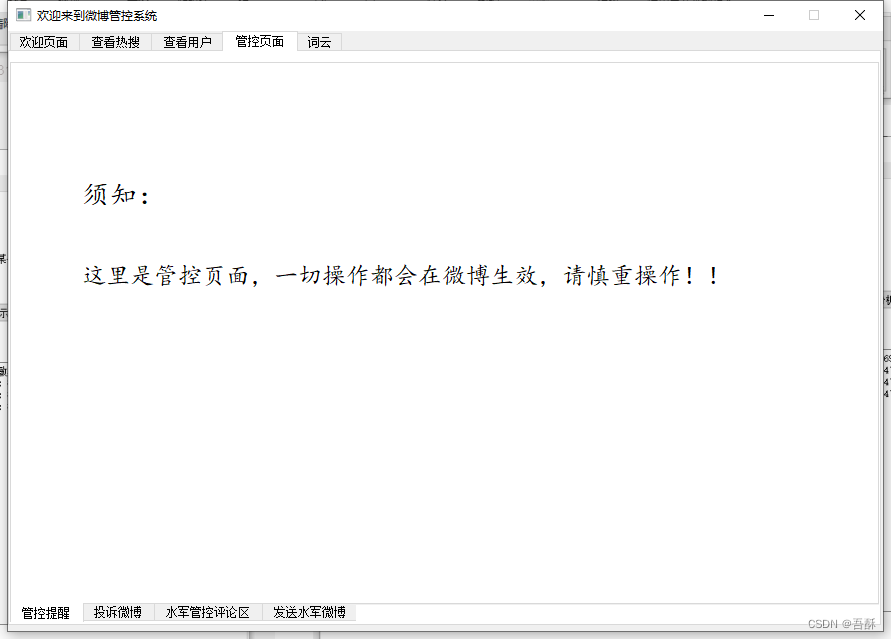
管控页面:

词云生成页面:

第三章 实现方案
3.1系统方案
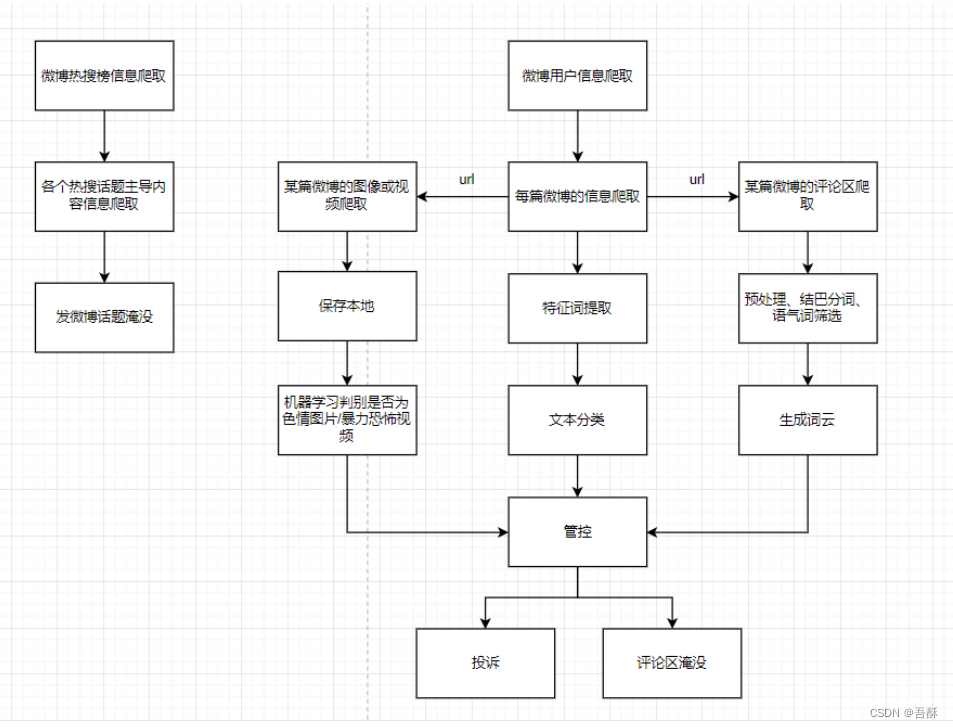
3.2实现原理
3.2.1 微博热搜榜及热搜话题爬取子系统
环境及语言:python selenium库 Chrome浏览器
1.首先根据https://s.weibo.com/top/summary?sudaref=www.sogou.com微博热搜榜的url逐条爬取到每一条热搜对应一个其单独的话题广场url,通过预处理过滤掉热搜榜上的广告热搜。下面是预处理的关键代码
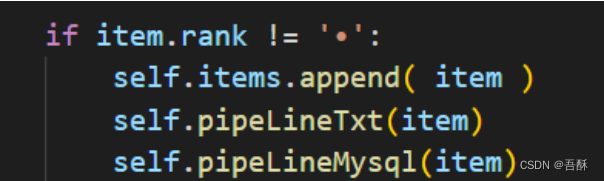
2.我们进行深度优先遍历,分别根据url可以逐次进入到每条热搜的热搜广场,热搜广场的第一条热搜通常即为热度最高的文章,因此我们可以从其内容中提取到热搜的主要内容。

3.将每条热搜的内容、排名、名称、热度存入数据库。
3.2.2 微博图像、视频爬取子系统
环境及语言:python selenium库 Chrome浏览器
1.首先根据输入的微博url打开一条微博的页面,然后利用Xpath通过元素特征值匹配到图像或视频的url存放处,从html中取出该url。
2.根据图片或视频的url跳转到该图片或视频的网页然后再下载到本地。

3.2.3 微博评论爬取及词云生成子系统
环境及语言:python selenium库 wordcloud库 jieba库 Chrome浏览器
1.首先根据用户输入的微博url进入到该微博的界面,然后利用selenium自动点击评论,先爬取当前界面可见的评论,再滑动滚轮,继续爬取评论,当遇到“登录后查看更多”时点击,提醒用户扫码登陆,登陆后继续滚动、爬取评论。
2.将爬取到评论保存到本地文件。
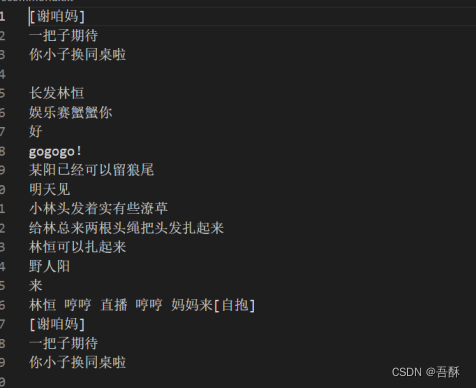
3.将该文件中的内容读出,首先过滤掉句末语气词“了”、“啊”、“啦”等,然后进行jieba分词。
4.将Jieba分词后的结果词典作为输入进行wordcloud生成词云图。

3.2.4 管控子系统
环境及语言:python selenium库 微博官方api Chrome浏览器
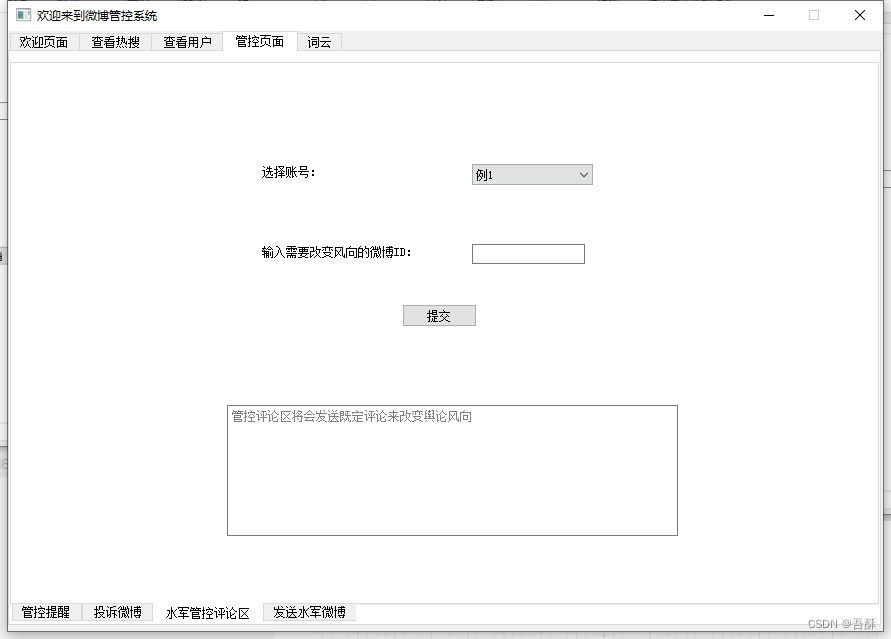
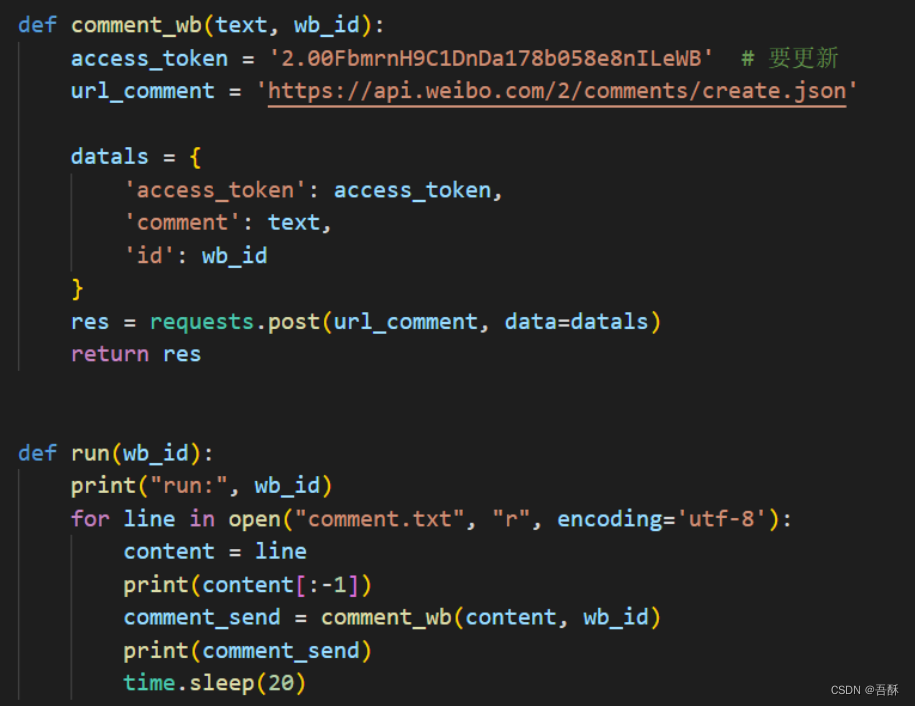
1.评论区淹没:由于利用selenium发布一条评论后难以再确定回复文本框的位置,难以进行Xpath定位,因此评论区淹没功能是基于微博官方api应用接口实现的,输入一条微博的id,程序将自动从评论文本txt文件(用户可以提前写入自己想评论的话,若不写入则默认为正能量语录)中逐条读取并构建http网络包(内容,access_token,id,url)回复在评论区,其中access_token是从微博api注册认证后颁发的。
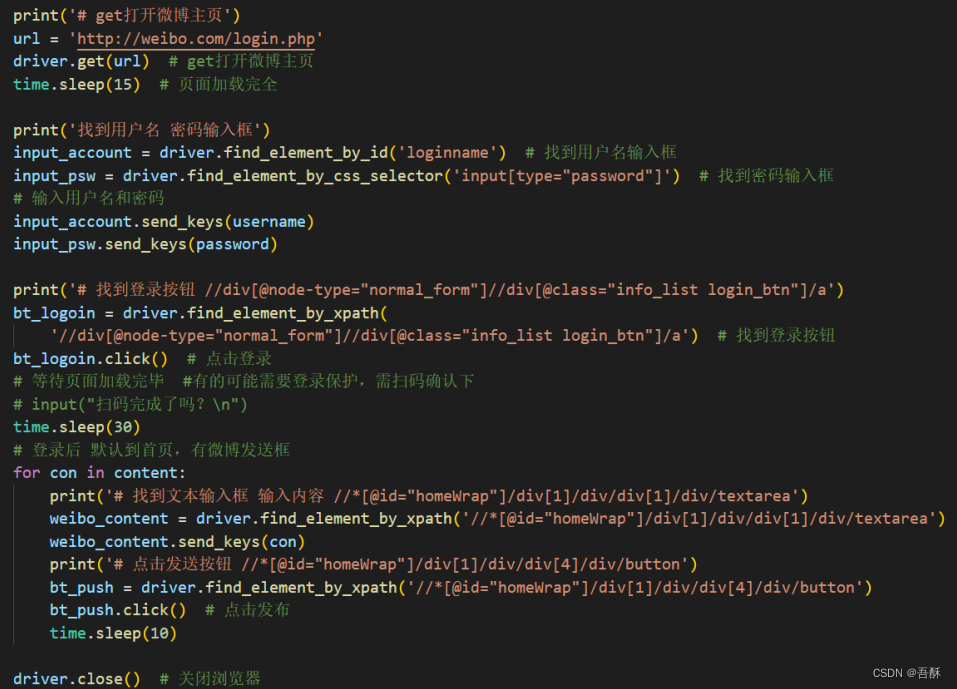
2.话题的淹没:话题的淹没即在某个话题中大量发帖以淹没原热点帖,让更多人看到正能量的真相,首先进入微博网页首界面,根据用户选择的账号进行自动输入账号密码自动登陆,登录后等待用户扫码通过安全认证,认证后自动从文本库txt文件中取出内容加上用户输入的话题进行持续发帖。
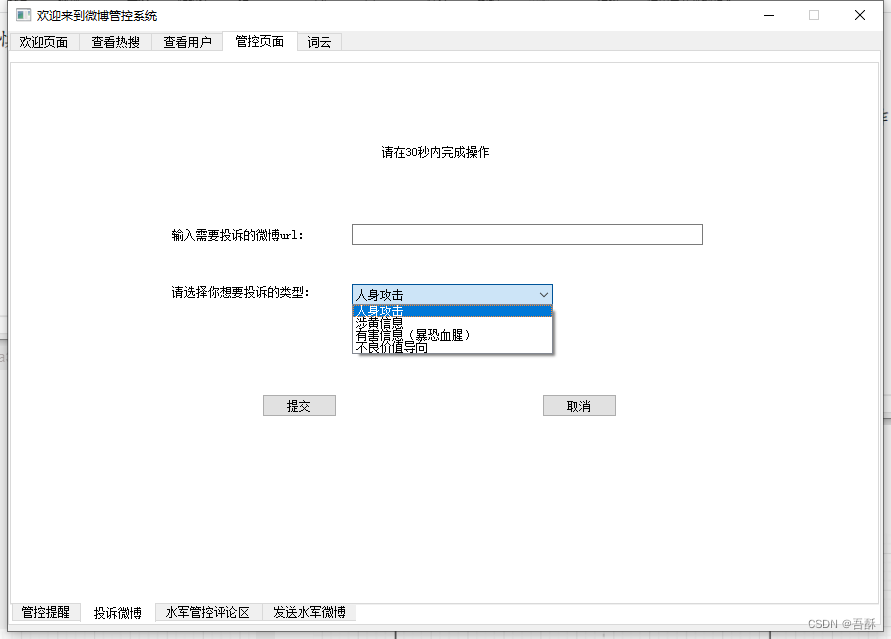
3.微博投诉:输入一篇微博的url选择以下投诉类型包括人身攻击、涉黄信息、有害信息(暴恐血腥)、不良价值导向。
程序自动索引到此篇微博并点击投诉选择类型、登陆、认证以及勾选协议并提交等。
3.2.5 文本特征提取及分类子系统
1.将提取到微博文本列表(文本可不唯一,数量不限)作为输入,首先利用优化后的WM多模式匹配算法进行特征词提取(特征词即分类的敏感词)。
2.将WM多模式匹配算法的结果作为输入,利用朴素贝叶斯机器学习算法,根据已有样本进行贝叶斯估计学习先验概率P(Y)和条件概率P(X|Y),进而求出联合分布概率P(XY),最后利用贝叶斯定理求解P(Y|X),也就是说,它尝试去找到底这个数据是怎么生成的(产生的),然后再进行分类。哪个类别最有可能产生这个信号,就属于那个类别,判断文本是否属于四类中的某一类,并输出条件概率。
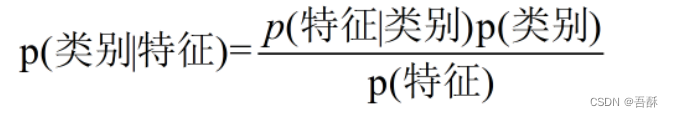
3.2.6 基于PIL的色情图片检测子系统
参考链接:https://www.cnblogs.com/wjw1014/p/10319652.html
本程序根据颜色(肤色)找出图片中皮肤的区域,然后通过一些条件判断是否为色情图片。
程序的关键步骤如下:
- 遍历每个像素,检测像素颜色是否为肤色。
- 将相邻的肤色像素归为一个皮肤区域,得到若干个皮肤区域。
- 剔除像素数量极少的皮肤区域。
我们定义非色情图片的判定规则是(满足任意一个判定为真):
- 皮肤区域的个数小于 3 个。
- 皮肤区域的像素与图像所有像素的比值小于15%。
- 最大皮肤区域小于总皮肤面积的 45%。
- 皮肤区域数量超过 60 个。
颜色模式
第一种:
r > 95 and g > 40 and g < 100 and b > 20 and max([r, g, b]) - min([r, g, b]) > 15 and abs(r - g) > 15 and r > g and r > b
第二种:
nr = r / (r + g + b), ng = g / (r + g + b), nb = b / (r +g + b), nr / ng > 1.185 and r * b / (r + g + b) ** 2 > 0.107 and r * g / (r + g + b) ** 2 > 0.112
HSV 颜色模式
h > 0 and h < 35 and s > 0.23 and s < 0.68
YCbCr 颜色模式
97.5 <= cb <= 142.5 and 134 <= cr <= 176
一幅画像有零个到多个皮肤区域,程序按发现顺序给它们编号,第一个发现的区域编号为 0 ,第 n 个发现的区域编号为 n-1 。我们用一种类型来表示像素,我们给这个类型取名为 Skin ,包含了像素的一些信息:唯一的编号(id)、是否为肤色(skin)、皮肤区域的编号(region)、横坐标(x)、纵坐标(y)。遍历所有像素时,我们为每个像素创建一个与之对应的 Skin 对象,并设置对象的所有属性。其中 region 属性即为像素所在的皮肤区域编号,创建对象时初始化为无意义的 None。关于每个像素的 id 值,左上角为原点,像素的 id 值按照像素坐标布局,那么看起来如下图所示:
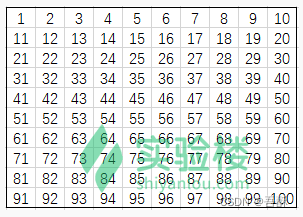
其实 id 的顺序也即遍历的顺序。遍历所有像素的时候,创建 Skin 对象后,如果当前像素为肤色,且相邻的像素有肤色的,那么我们把这些肤色归到一个皮肤区域。
相邻像素的定义:通常都能想到的是当前像素周围的8个像素,然而实际上只需要定义4个就可以了,位置分别再当前像素的左方、左上方、正上方、右上方;因为另外四个像素都在当前像素后面,我们还未给这四个像素创建对应的 Skin 对象。

我们会先设计一个Nude类,里面包含图片的所有信息,考虑到效率问题——越大的图片所需要消耗的资源与时间越大,因此有时候可能需要对图片进行缩小。接着遍历每个像素,为每个像素创建对应的Skin对象,若当前像素并不是肤色,那么跳过本次循环,继续遍历,若当前像素是肤色像素,那么就需要处理了,先遍历相邻像素。然后相邻像素的若是肤色像素,如果两个像素的皮肤区域号都为有效值且不同,因为两个区域中的像素相邻,那么其实这两个区域是连通的,说明需要合并这两个区域。记录下此相邻肤色像素的区域号,之后便可以将当前像素归到这个皮肤区域里了。
遍历完所有相邻像素后,分两种情况处理
- 所有相邻像素都不是肤色像素:发现了新的皮肤区域
- 存在区域号为有效值的相邻肤色像素:region 的中存储的值有用了,把当前像素归到这个相邻像素所在的区域
遍历完所有像素之后,图片的皮肤区域划分初步完成了,只是在变量self.merge_regions中还有一些连通的皮肤区域号,它们需要合并,合并之后就可以进行色情图片判定了。
3.2.7 基于卷积神经网络的检测子系统
参考链接:https://blog.csdn.net/v_JULY_v/article/details/51812459
由于上一个子系统的设计对色情图片实际检测的结果误差较大,我们考虑用深度学习的方法来提高准确率。我们之前还未正式接触过卷积神经网络,所以首先要弄清楚什么是卷积神经网络。
当我们给定一个"X"的图案,计算机怎么识别这个图案就是“X”呢?一个可能的办法就是计算机存储一张标准的“X”图案,然后把需要识别的未知图案跟标准"X"图案进行比对,如果二者一致,则判定未知图案即是一个"X"图案。
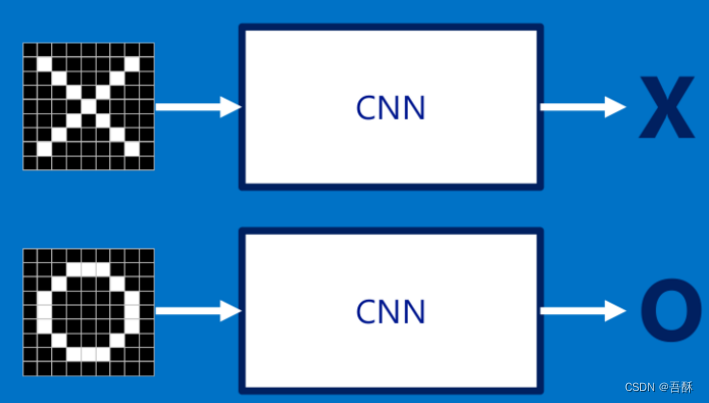
但对于计算机来说,只要图像稍稍有一点变化,不是标准的,那么要怎么解决这个问题?

计算机要解决上面这个问题,一个比较天真的做法就是先保存一张"X"和"O"的标准图像(就像前面给出的例子),然后将其他的新给出的图像来和这两张标准图像进行对比,看看到底和哪一张图更匹配,就判断为哪个字母。
但是这么做的话,其实是非常不可靠的,因为计算机还是比较死板的。在计算机的“视觉”中,一幅图看起来就像是一个二维的像素数组(可以想象成一个棋盘),每一个位置对应一个数字。在我们这个例子当中,像素值"1"代表白色,像素值"-1"代表黑色。

当比较两幅图的时候,如果有任何一个像素值不匹配,那么这两幅图就不匹配,至少对于计算机来说是这样的。因此,从表面上看,计算机判别右边那幅图不是"X",两幅图不同。但是这么做,显得太不合理了。理想的情况下,我们希望,对于那些仅仅只是做了一些像平移,缩放,旋转,微变形等简单变换的图像,计算机仍然能够识别出图中的"X"和"O"。就像下面这些情况,我们希望计算机依然能够很快并且很准的识别出来。这也就是CNN出现所要解决的问题。
第一步,特征提取
对于CNN来说,它是一块一块地来进行比对。它拿来比对的这个“小块”我们称之为Features(特征)。在两幅图中大致相同的位置找到一些粗糙的特征进行匹配,CNN能够更好的看到两幅图的相似性,相比起传统的整幅图逐一比对的方法,每一个feature就像是一个小图(就是一个比较小的有值的二维数组)。不同的Feature匹配图像中不同的特征。在字母"X"的例子中,那些由对角线和交叉线组成的features基本上能够识别出大多数"X"所具有的重要特征。
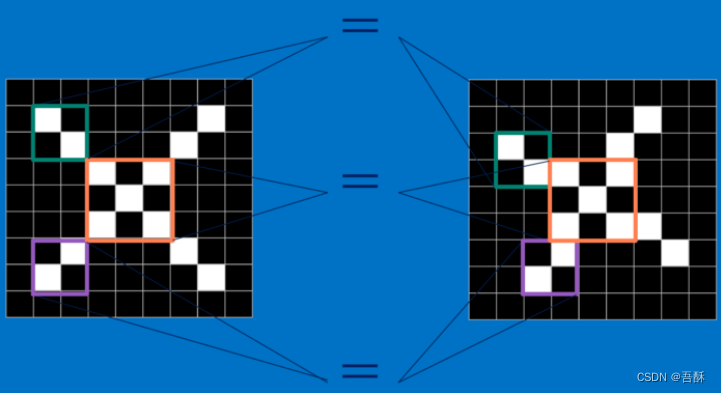
那怎么表示特征的提取呢?那就要用到卷积运算,其实就是计算相似度。举个具体的例子。比如下图中,图中左边部分是原始输入数据,图中中间部分是滤波器filter,图中右边是输出的新的二维数据。
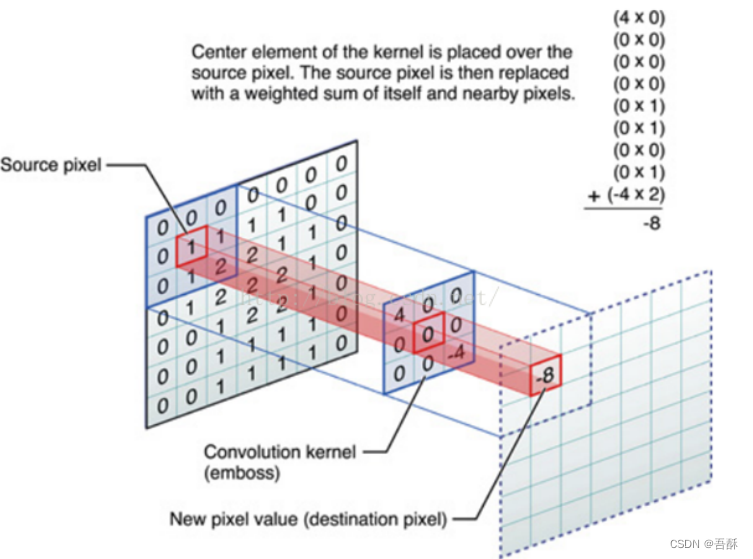
用不同的滤波器可以提取不同的特征。
第二步,池化pool池
为了提高运算效率,缩小图像大小,需要进行池化,有两种池化方式:最大池化和平均池化。
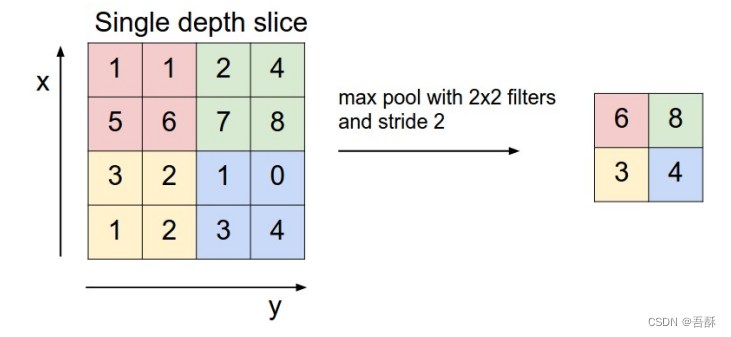
上图所展示的是取区域最大,即上图左边部分中 左上角2x2的矩阵中6最大,右上角2x2的矩阵中8最大,左下角2x2的矩阵中3最大,右下角2x2的矩阵中4最大,所以得到上图右边部分的结果:6 8 3 4。平均池化就是取平均值填入。
第三步,激活函数
为了简化计算,需要把方框区域的负数权重改为0.ReLU的优点是收敛快,求梯度简单。
然后就是三步重复出现,卷积运算,池化,激活函数,卷积运算,池化,激活函数……我们希望最后的结果是使得损失函数最小,即准确率最大。
3.2.8 基于异常检测的视频检测子系统
有两种实现代码:
参考链接:https://paperswithcode.com/paper/real-world-anomaly-detection-in-surveillance
第一种:监控视频能够捕捉到各种现实的异常现象。我们建议通过利用正常和异常视频来学习异常。为了避免注释训练视频中的异常片段或剪辑(这是非常耗时的),建议利用弱标记的排名框架通过深度多实例训练视频来训练异常,即训练标签(异常或正常),是在视频级而不是剪辑级。在此方法中,将正常视频和异常视频作为包和视频片段作为多实例学习(MIL)的实例,并自动学习一个深度异常排名模型,该模型预测异常视频片段的高异常分数。此外,在排序损失函数中引入了稀疏性和时间平滑性约束,以更好地在训练过程中定位异常。
具体而言,就是在一段视频中,只关心是否有异常事件的存在,而不关心具体的异常类型以及异常发生在哪些帧内。
基于此,方法主要实现过程为:首先,使用C3D提取视频特征,文章以32帧为一个bag进行处理。C3D提取视频时空特征是由Facebook团队提出来的。此文章使用公开的C3D预训练模型提取视频特征,然后将提取好的特征拿出来,送到三层全连接层中,计算异常得分,根据异常得分,预测是否发生异常事件。
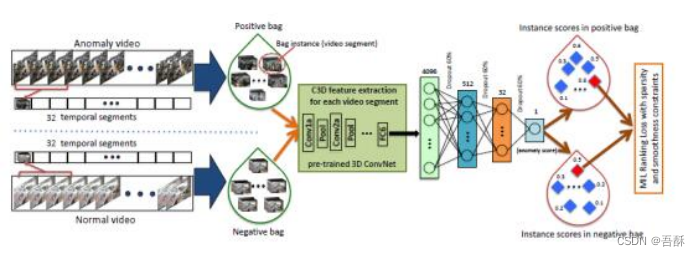
多实例学习(MIL)。平常的深度学习训练都是一个样本对应一个label,而在MIL中,出现bag这个概念,一个bag对应一个label,一个正bag中至少需要有一个正样本,一个负bag中只能全部是负样本,而一个bag中,包含有多个样本,所以叫多实例学习,此文中,一个bag中包含有32个样本。
但是此代码的输出做的并不算太好,常常有卡壳无法正常输出正常结果的情况发生,故我们还准备了第二种方案。
第二种:
参考链接:https://joshua-p-r-pan.blogspot.com/2018/05/violence-detection-by-cnn-lstm.html
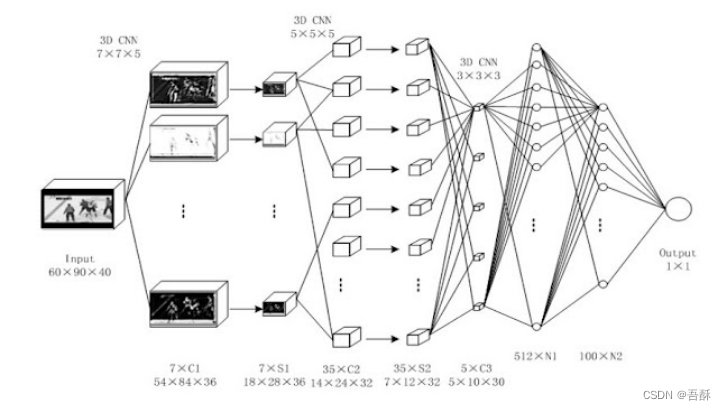
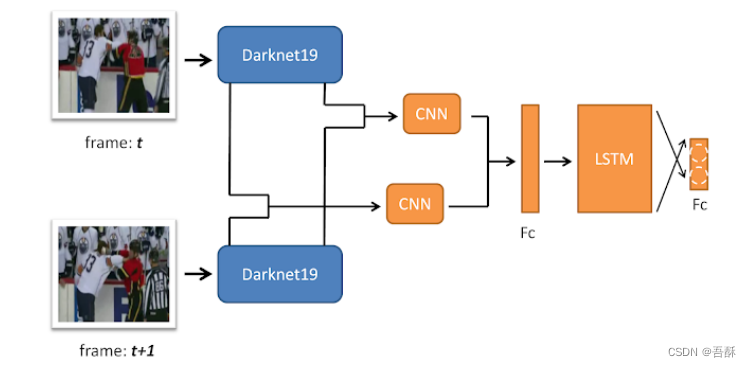
拟议的网络架构如图所示。研究表明,除了在CNN之后添加LSTM(该模型应该能够提取全局时间特征)外,可以从光流中获得的局部时间特征也很重要。此外,光流的优点在于其外观不变性以及在边界和小位移下的精确性。因此,在这项工作中,假设通过将两个视频帧作为输入来模拟光流的影响。这两个输入帧由预先训练好的CNN处理。从预训练模型的底层输出的两个帧在最后一个通道中串联,然后馈送到附加的CNN。由于底层的输出被视为低层特征,因此附加的CNN应该通过比较两帧特征图来学习局部运动特征以及外观不变特征。来自预训练网络顶层的两个帧输出也被串联并馈送到另一个附加的CNN中,以比较两个帧的高级特征。然后将来自两个附加CNN的输出串联起来,并传递到完全连接的层和LSTM单元,以学习全局时间特征。最后,LSTM细胞的输出通过一个完全连接的层进行分类,该层包含两个神经元,分别代表两个类别(战斗和非战斗)。
由于其在ImageNet上的准确性和上述实时性能,预训练模型由Darknet19实现。由于Darknet19已经包含19个卷积层,为了避免退化问题,额外的CNN由残差层实现。
精度评估
在这项工作中提出的模型可以输出每帧的分类结果。然而,先前的研究评估了视频级别的准确性。为了能够与之前的工作进行比较,帧级结果通过以下策略进行收集和处理:当且仅当该类别的连续信号的数量大于某个类别时,该视频才被分类到某个类别临界点。这样的阈值可以通过从 0 扫描到视频长度的阈值来得出,并查看哪个阈值在验证集中产生最佳精度,如果有多个阈值可以产生相同的精度,则会选择小的。
我们训练了三轮,第一轮的准确率就已经达到了91%,第三轮结束后,准确率在94%左右,但比第一轮多花了两倍的时间(完全不划算)。
3.3硬件框图
本系统无硬件
3.4系统软件流程
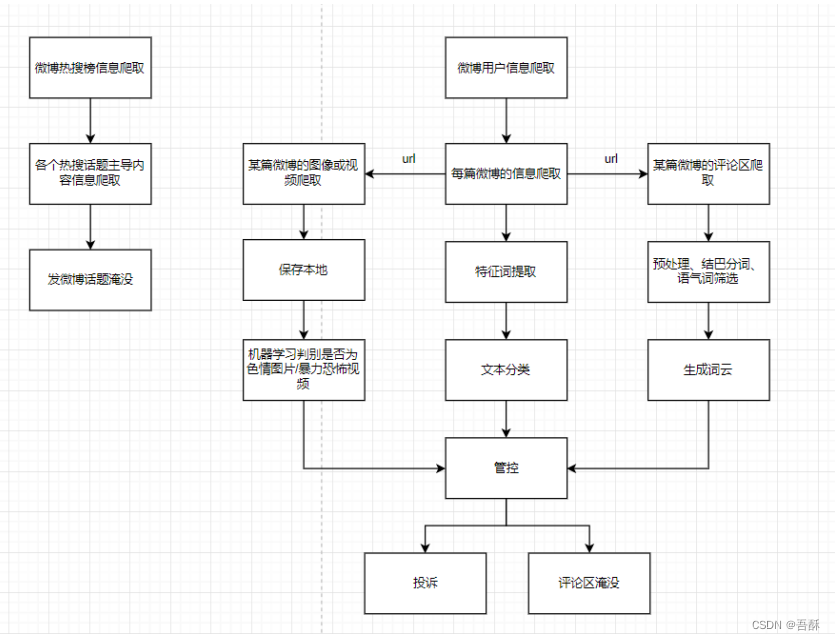
第四章 系统功能设计
4.1微博热搜榜及热搜话题爬取子系统
1.系统架构: 主要分为微博热搜榜的爬取及话题广场热门微博的内容爬取两个模块,其中前者为后者的实行准备了条件,前者的部分结果是后者的输入,即在热搜广场扫描到一条热搜并预处理后,将其Url提取出来并以此作为下一目标进入其话题广场寻找内容。
2.设计思路:基于微博热搜榜,对于每条热搜,获取其热搜话题的url,再发散式根据其url进入话题广场,爬取广场中热门微博的内容,以了解热搜详细信息,将信息保存至数据库以便展示。
4.2 微博图像、视频爬取子系统
1.系统架构:图像与视频得下载步骤相同,url在html中的Xpath也相同因此可共用一个程序。
2.设计思路:主要分为两个步骤,一个是根据用户输入找到该微博的界面,然后通过selenium爬虫从后台Html代码中找到图片/视频的url如下,然后通过此url进入该图片或视频的网址并保存下载。
4.3 微博评论爬取及词云生成子系统
1.系统架构:本子系统分为两个模块:评论区内容爬取并保存、预处理和结巴分词及生成词云。前者的输出作为后者的输入。
2.设计思路:首先根据用户输入的指定微博的url,利用selenium爬虫不断爬取其评论区的内容并保存在txt文件中,然后调用处理及生成的模块对txt文件中的内容进行过滤筛除语气词等,并对预处理后的文本进行结巴分词,生成词典,然后调用wordcloud库生成词云图。
4.4 管控子系统
1.系统架构:本系统根据不同的管控方式分为三个模块:按类型投诉举报微博、评论区淹没、话题广场淹没。三个模块分别针对不同的目的及用途。
2.设计思路:分类投诉举报微博模块首先根据用户输入的微博url进入微博页,然后自动选择登陆、认证,通过selenium定位自动按顺序点击投诉、选择类型、勾选协议、点击提交。
评论区淹没首先根据用户输入的微博id及微博api提供的开发接口https://api.weibo.com/2/comments/create.json将内容、微博id、access_token进行http包封装然后发送到微博服务器。
话题广场淹没利用selenium模拟发微博流程,逐步登陆、认证、发送微博。
4.5 文本特征提取及分类子系统
1.系统架构:本子系统分为特征词提取和文本分类两个模块,其中文本分类模块利用机器学习方法提高精确度和复用性。
2.设计思路:特征词提取模块使用课程中学习到的WM多模式匹配算法,WM多模式匹配算法同时兼具好后缀和坏前缀思路,因此能大大提高匹配速度和效率。而文本分类模块使用经典的朴素贝叶斯分类算法,利用特征词提取模块的结果作为输入,基于机器学习为文本计算概率并分类。
4.6 基于PIL的色情图片检测子系统
1.系统架构:本子系统分为分割、缩小、处理模块,其中缩小模块用来缩小存储空间,提高运算效率,处理模块遍历每个像素,检测像素颜色是否为肤色,且将相邻的肤色像素归为一个皮肤区域
2.设计思路:色情图片通常情况下会暴露大量的肉体,导致图片中肉色占很大的比例,通过检测图片的肉色比例是否符合我们设置的要求,以此判断是否为色情图片。但此方法不可靠,若有一个人穿了肉色衣服,也可能被检测为色情图片,或者是色情图片,但是转换为灰度图,则识别不出来。
4.7 基于卷积神经网络的检测子系统
1.设计思路:通过卷积神经网络,三层全连接,大量学习图片,最后可以对测试集有90%的正确率。
2.使用指令:
python nsfw_predict.py 3.jpeg,其中3.jpeg是需检测的图片地址
4.8 基于异常检测的视频检测子系统
1.设计思路:附加的CNN应该通过比较两帧特征图来学习局部运动特征以及外观不变特征。来自预训练网络顶层的两个帧输出也被串联并馈送到另一个附加的CNN中,以比较两个帧的高级特征。然后将来自两个附加CNN的输出串联起来,并传递到完全连接的层和LSTM单元,以学习全局时间特征。最后,LSTM细胞的输出通过一个完全连接的层进行分类,该层包含两个神经元,分别代表两个类别(打架和非打架)。
2.使用指令:
python.exe Deploy.py .\SS\no4_xvid.avi .\output\r_no4_xvid.avi 其中.\SS\no4_xvid.avi是需要视频检测的路径,.\output\r_no4_xvid.avi 是结果存放路径
另外需要说明的是,因为该实验每一帧的平均处理时间为0.109s,一秒的视频被分为了30帧,若进行跳帧检测,则可以实现实时的视频检测。为实时直播视频检测提供了新思路。
第四章 系统功能设计
5.1 WM多模式匹配
WM多模式匹配算法是课程中提到的常用、高效的多模式匹配算法,在本系统中我们利用WM多模式匹配算法进行对爬取到的微博文本内容的特征词提取,根据测试WM算法能够在中文字符、英文字符、及其他符号字符中精确的提取到想要的特征词,同时保证了高效率,时间复杂度较低,且在本系统中我们使用了课堂讨论课中学习和介绍的WM优化后的DWMSH算法,进一步提高了效率。
5.2朴素贝叶斯分类
本系统的文本分类功能是基于朴素贝叶斯分类器算法实现的,朴素贝叶斯分类属于机器学习算法的一种,我们只需准备好四种类型特征词及分类结果的样本集,程序即可自学习的计算概率并对新输入的特征词序列进行分类判别。
5.3 深度学习
卷积神经网络,需要大量的训练样本集合,训练出合适的模型后用测试样本进行准确性计算,经过合适的轮数确定参数模型,最后用来预测图片或视频的分类,相比较于其他分类方法,此方法需要大量的样本,训练也需要一定的时间(我们训练用了12个小时),但是准确率高,效果好。
第六章 总结
本系统基于微博网页爬虫及信息分析和管控,结合机器学习,深度学习方法,同时针对图像和音视频信息进行了分析和管控,使用了数据库,制作了精美的界面,是一套完善的微博信息爬取、分析及管控系统,同时精度高、效率高,具有良好的实用性,同时创新性的提出了针对黄色类型信息、暴力公布信息(打架斗殴、枪击等)、异常信息(爆炸、车祸等)的识别和管控,一定程度上补充了微博服务器的信息识别和管控,有利于微博移动社交平台更加正能量、更加和谐美好。
本系统充分将《信息内容安全》课程所学知识用于实践,并加以自己的理解、优化和创新性功能,在过程中也学习更多课程外的相关知识、算法理论等。
最后感谢张老师、史老师和何老师以及各位助教学长的悉心指导。
参考文献
[1]Real-world Anomaly Detection in Surveillance Videos
[2]Real-Time Violence Detection Using CNN-LSTM
参考链接:
https://paperswithcode.com/paper/real-world-anomaly-detection-in-surveillance
https://blog.csdn.net/v_JULY_v/article/details/51812459
https://www.cnblogs.com/wjw1014/p/10319652.html
https://joshua-p-r-pan.blogspot.com/2018/05/violence-detection-by-cnn-lstm.html
写在最后:感谢我的队友,我们一起完成此次实验,在获取她的同意后我才得以将此次实验报告分享给大家,她说我这样做是有意义的,她的话深深的激励到了我,我也希望这样能帮助到大家。
下面我会将每一板块的代码分开上传请大家在我的主页里查看相关内容