文章目录
一、什么是信号?
以日常为例,信号弹,上下课铃声,动物求偶行为,红绿灯等等。这些都是信号。
我们怎么认识信号?
从小开始,父母教的,老师教我们识别这些信号。
在信号产生后,可能我并不会马上处理该信号,但我记得有这个信号。所以必须在未来某个时间窗口内处理该信号。
比如:在宿舍点外卖的行为,外卖员打电话,我当时在打游戏,电话一挂,推高地去了,然后游戏打完后,我再下去拿外卖。
这个就是典型的信号收到之后,没有马上处理,而是再未来某个时间窗口内处理。
对于进程:
- 1.进程必须具备识别和处理信号的能力。即使没有产生信号,但是也要能够识别对应未来可能产生的信号,属于进程的内置功能。
- 2.当进程真的收到一个信号的时候,可能并不会立刻处理该信号,会在合适的时候处理。
- 3.一个进程必须具备一个信号产生,到该信号被处理这个时间窗口内将信号保存的能力。
根据上面第二点,进程处理信号的方式有三种:
- 默认动作
- 忽略
- 自定义动作
提出问题:
ctrl + c为什么能够杀掉前台进程呢?
前台进程:
在Linux中,一次登陆中,一个终端配一个bash,每一个登陆,只允许一个进程是前台进程。
也就是说,我们的bash,输命令的进程,就是前台进程,当写好代码,将一个程序运行起来后,这个正在运行的进程就是前台进程,bash就被变成后台进程了。
键盘在输入的时候,是前台进程获取的。
所以一个循环执行的时候,在键盘输入ctrl + c,会被前台进程获取并识别成2号信号,2号信号就是将进程中断。
所以ctrl + c的本质是被进程识别成2号信号。
1.signal系统调用
前面说过,进程处理信号的方式有三种。
对于2号信号来说,进程处理该信号的默认方式就是终止自己。
而其他两种处理方式,就是要signal函数解决。

第一个参数:signum,几号信号。
第二个函数:这个参数的类型是一个函数指针类型,其实就是自定义的处理signum信号的方式。
也就是说,调用signal系统调用,如果传入2号参数,在将来遇到2号信号时,处理方式就是调用handler函数的自定义处理方式。
void myheader(int sig)
{
cout << "process get a signal : %d "<< sig << endl;
}
int main()
{
signal(SIGINT,myheader);
int cnt = 50;
while(cnt--)
{
cout << "I am a process" << endl;
sleep(1);
}
return 0;
}
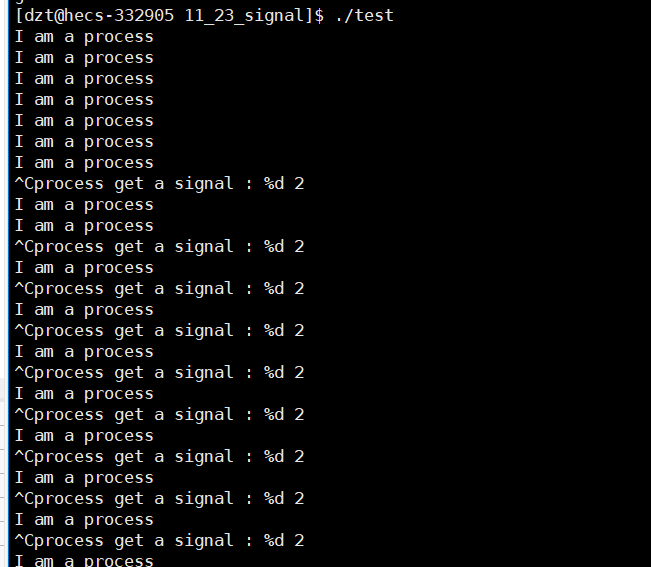
遇到2号信号时,调用的自定义处理方式就是调用自己写的handler函数。
注意:signal函数只需要设置一次,就一直有效,往后只要遇到2号信号,都会使用自定义处理信号的方式,即调用handler函数。
2.从硬件解析键盘数据如何输入给内核
首先,键盘只要被摁下了,一定是操作系统先知道!
那么,操作系统怎么知道键盘上有数据?
在计算机中有许多硬件,其中,只要我们摁下键盘的键,就会产生信号中断,
通过高低电流的形式发送给中断单元,中断单元再将该信号发送到CPU的引脚,CPU接收到信号后,告知操作系统,并将中断单元号发送给操作系统,操作系统收到信号后,执行中断向量表中对应中断编号的方法的地址。
而再执行读取键盘的方法,也就是将键盘上摁下的内容拷贝到内存中的内核缓冲区中。
至此,就完成了操作系统可以知道键盘上有数据并将数据拷贝到内核缓冲区中的动作。
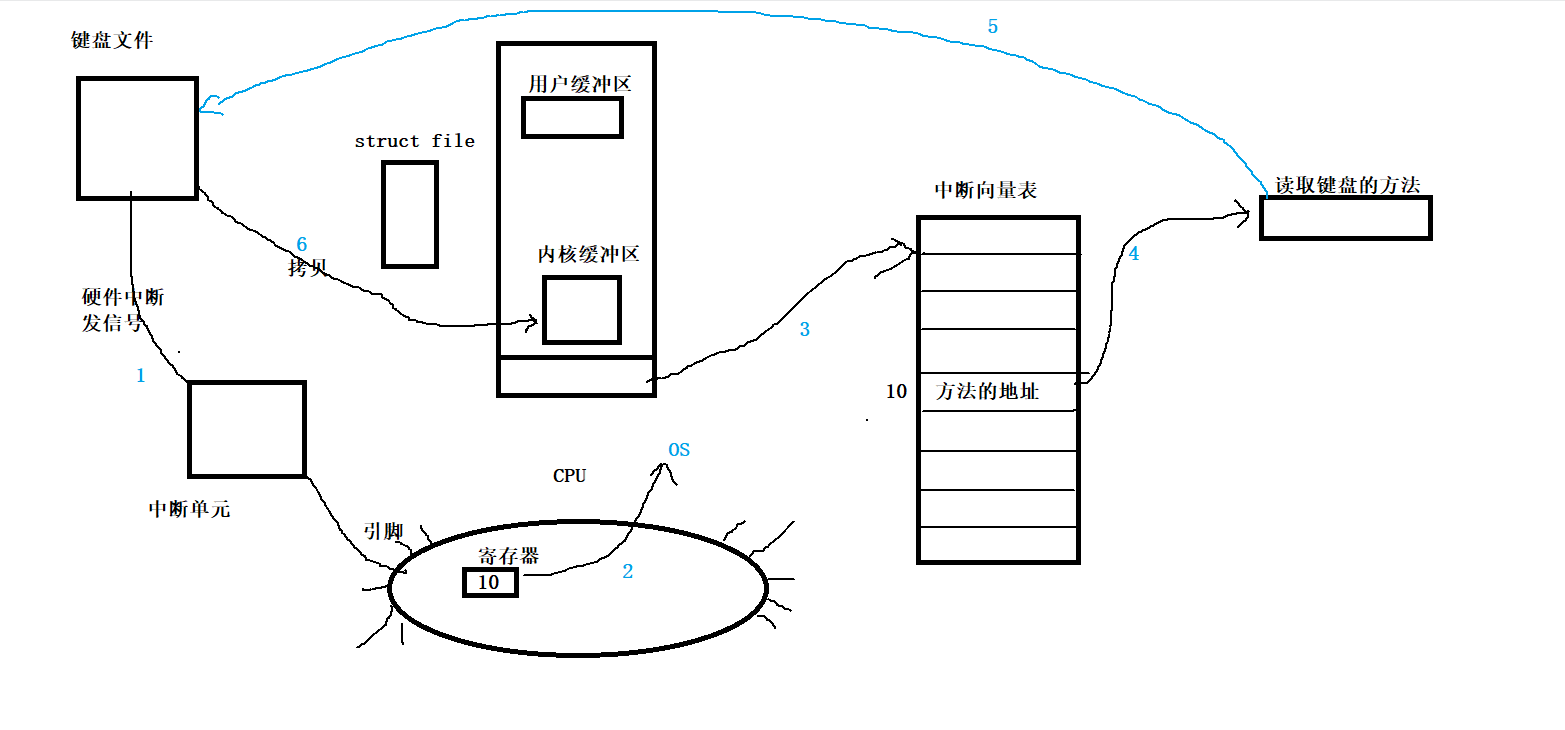
所以,操作系统不需要再对每一个硬件进行信号的检测了,只需等待CPU将对应的中断信号发送过来即可。
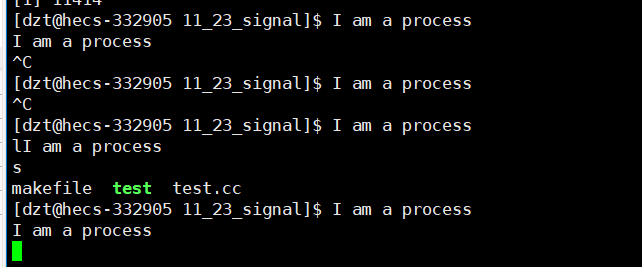
对于上面这种后台进程输入了l,再输入s,但是在屏幕上显示的是乱序的问题。
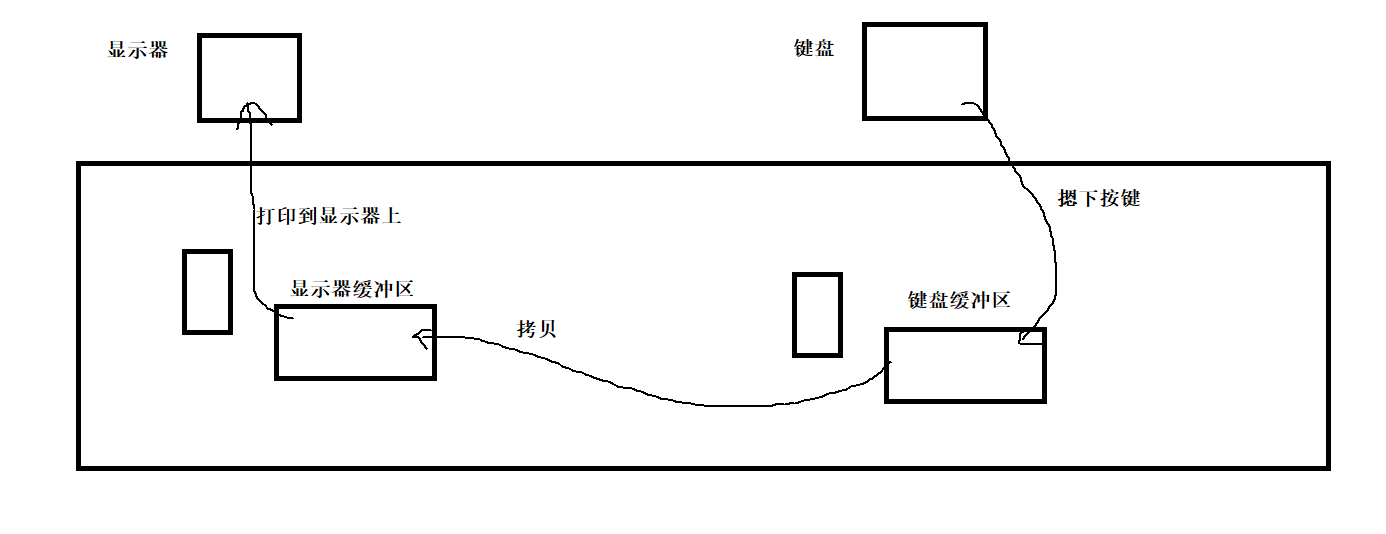
其实原理如下:
键盘在被摁下的时候,按键被加载到缓冲区中,第一次摁下l键,此时键盘缓冲区中有一个l键,然后再将该字符拷贝到显示器缓冲区中,打印到显示器上,此时后台进程一直再跑,也将对应的字符串打印到显示器上,造成打印是乱序的。
但是丝毫不影响键盘缓冲区中的l字符。
因为键盘文件和显示器文件是两个不同的文件,分别具有不同的缓冲区。
他们互不干扰,所以再输入s时,键盘缓冲区就形成了ls指令,再将该s拷贝到显示器缓冲区中打印到显示器文件上,就看到了乱序的ls指令,但是按下回车键后,键盘会向CPU发送硬件中断。就执行了ls命令。
3.同步和异步
信号的产生和我们写的代码执行是异步的。
就比如说:
我和张三去自习室学习,张三说,等我会宿舍拿本书,然后我就在楼下等张三,等到张三后我们在一起去自习。我们一起去的过程就是同步进行的。
如果我和张三去自习室自习,张三说他去拿书,我不等他,我就先走了,然后我就和张三不同时到自习室,这个过程就是异步的。
二、信号的产生
信号产生的方式有五种。
1.键盘组合键
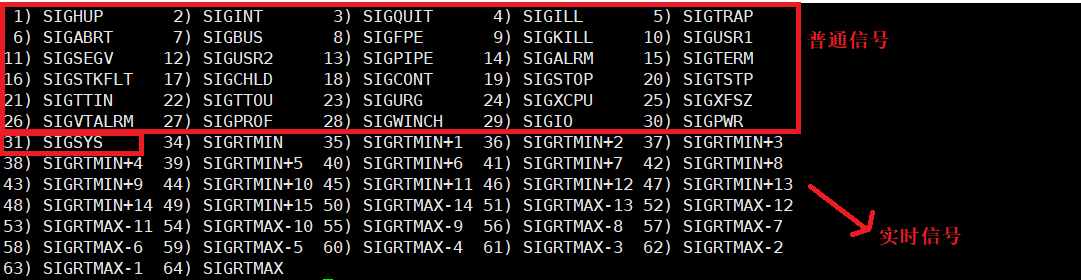
- 1.
ctrl + c产生2号信号。 - 2.
ctrl + \产生3号信号。
2. kill命令
kill -signo + 进程pid
对特定进程发送对应的信号。
3.系统调用接口
3.1kill
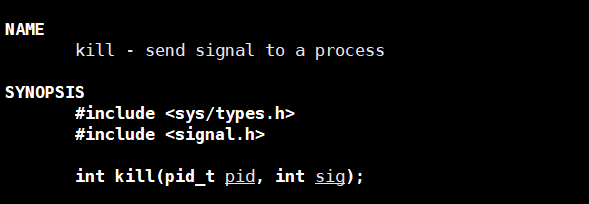
给pid进程发送sig信号。
//实现一个kill命令
void Usage(string name)
{
cout << "Usage:\n\t" << name << " signo pid" << endl;
}
int main(int argc,char* argv[])
{
if(argc != 3)
{
Usage(argv[0]);
exit(1);
}
int signo = stoi(argv[1]); //获取信号码
pid_t pid = stoi(argv[2]); //获取信号id
int n = kill(pid,signo);
if(n < 0) //kill 失败了
{
perror("kill");
exit(1);
}
return 0;
}
3.2 raise
给调用者发送指定的信号。
也就是给自己发送指定信号。
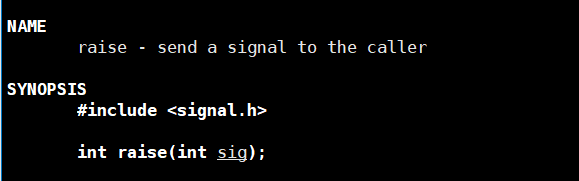
该函数的本质就是调用kill(getpid(),sig);
3.3abort
给自己发送6号信号。
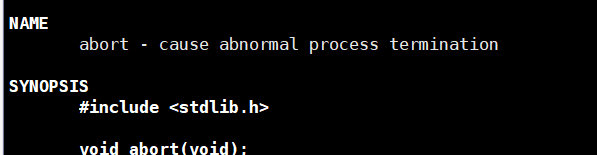
该函数的底层就是调用Kill(getpid(),6)
4.异常
当代码出现异常时,会向进程发送信号。
//模拟异常后发信号
void handler(int sig)
{
cout << "receive " << sig << " signo!"<<endl;
sleep(1);
}
int main()
{
signal(SIGFPE,handler);
int a = 10;
a/=0;
return 0;
}
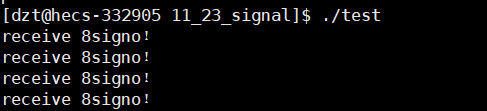
这里有个问题:信号为什么一直被触发?操作系统怎么知道进程发信号了?
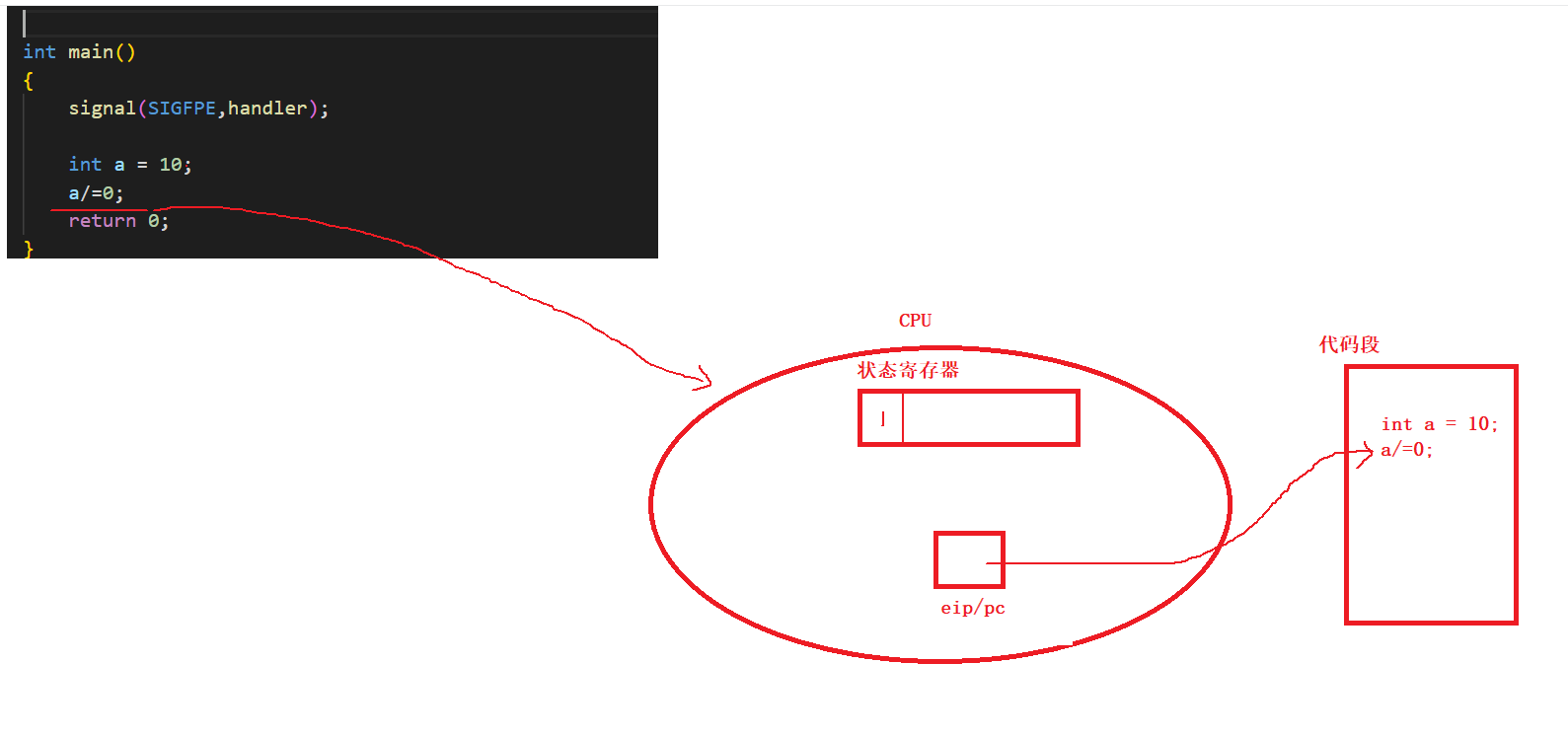
CPU内的寄存器eip/pc会记录进程中的代码走到哪一步了。
CPU中有一个寄存器叫做状态寄存器,这个状态寄存器虽然也是寄存器,但是该寄存器被设置成了具有比特位的寄存器,也就是说一个寄存器可以表示多个状态。
这些状态寄存器,eip寄存器等等保存的数据,都叫做进程上下文。
一个进程在退出时会把关于该进程本身的上下文数据全部带走,下一个进程在被CPU调度执行时,会把自己进程的上下文数据加载到CPU的寄存器中。
所以,上一个进程如果修改了状态寄存器中的内容,也丝毫不影响下一个进程!!!
所以虽然我们修改了状态寄存器的内容,但只影响我进程自己!
所以,当一个进程出现异常时,状态寄存器的某个比特位会由0置1。而操作系统要保证CPU的健康状态,一定会频繁地检查寄存器的内容是否被修改,从而获取到进程是否出异常了!!
CPU也是硬件,操作系统是硬件的管理者!!!
为什么操作系统不直接根据进程发的信号,帮助进程处理这些信号呢?
因为信号存在的意义,就是为了让进程死的明白!!
进程会被操作系统指派去执行各种各样的任务,而这些任务又是用户给的。一旦某个任务在执行过程中出现异常,产生信号了,进程要知道自己到底因为什么而产生的信号,这样就算自己死了也能给上面一个交代!
异常的出现只是为了可以统一在一个地方处理后续的工作,而不是用来解决的。
异常无法解决,只能让用户知道到底是什么原因而改变相应的策略。
5.软件条件
软件条件实现闹钟
alarm函数实现闹钟。
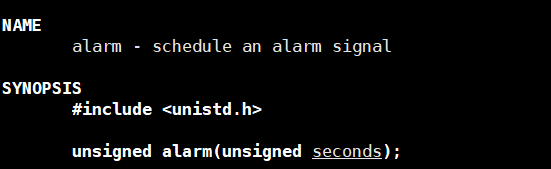
设置一个函数实现闹钟,seconds秒之后会响,然后向进程发送14号信号终止进程。
返回值是:上一次设置的闹钟的剩余时间。
如果第一次设置闹钟是10秒,过了5秒后,再设置一个闹钟,此时设置的第二个闹钟时,返回值就是第一个闹钟的剩余时间,也就是5。
void handler(int sig)
{
cout << "receive a " << sig << " signal" << endl;
}
int main()
{
signal(SIGALRM,handler);
int n = alarm(5);
while(true)
{
cout << "i am a process ,pid : " << getpid() << endl;
sleep(1);
}
return 0;
}
该代码验证了闹钟响,并向进程发送14号信号的结论。
重谈core dump标志位
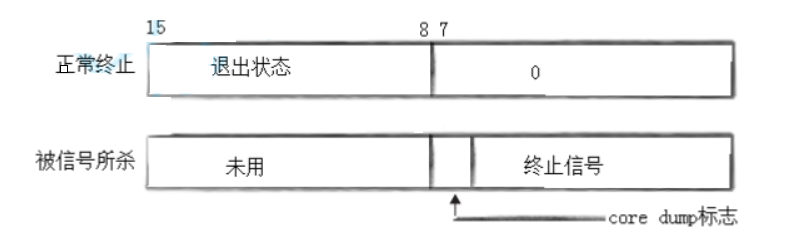
在进程等待环节中,进程等待的中的status参数的其中一个比特位叫做core dump标志位
这个比特位的意义是:
一旦进程出现异常,OS会将进程在内存中的运行信息,给我转储(转而存储,dump)到进程的当前目录(磁盘)形成core.pid文件,这个过程叫做核心转储。
并将core dump对应的比特位设置为1,告诉用户。
为什么要有core dump这个功能呢,这是为了方便进行事后调试,也就是代码出错后再调试。
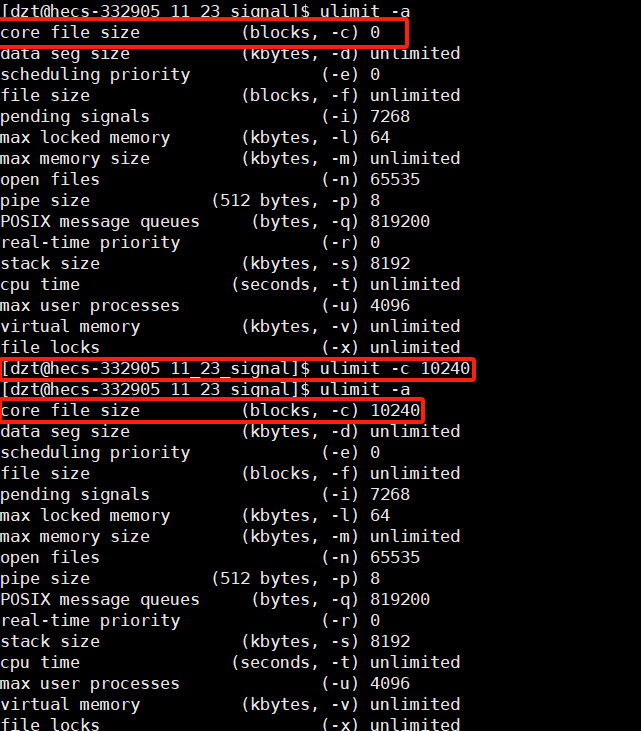
使用
ulimit -a查看系统的一些配置,其中第一个就是core file size,core文件的大小为0,说明core功能未打开
使用
ulimit -c 10240,将core文件大小设置最大为10240字节,此时就相当于打开了core功能了。
在.cc文件中写代码写一个除零错误后,会发现结果如下
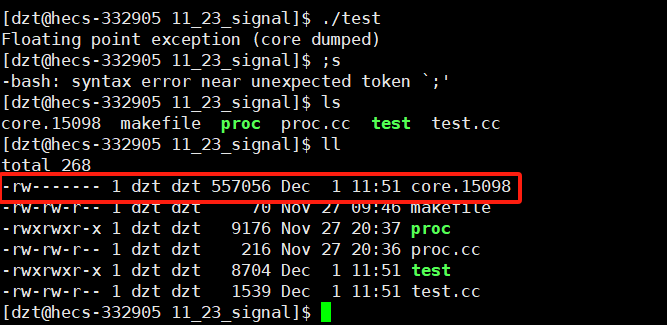
那就意味着进程出现异常后,生成了一个core.pid文件,就是把进程在内存的运行信息转储到当前进程的目录下。
打开调试器调试当前可执行程序后,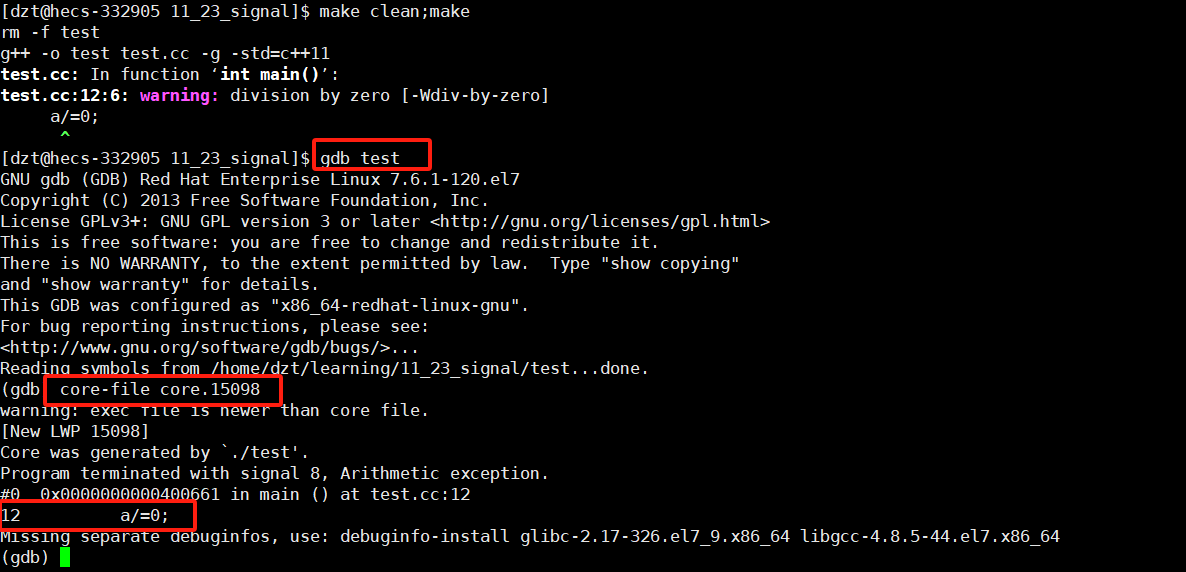
结果如下,将core.pid文件导入后,就能看到具体错误出现在什么地方,这样的调试就是事后调试。
其中,默认的云服务器没有打开core dump功能。
因为在公司的服务器中,如果某个服务挂掉了,不管三七二十一,先不管为什么挂掉,立刻进行重启,立刻重新启动服务,事后再根据日志其他的排查问题即可。可是,如果打开了core dump功能,每次有服务挂掉,都会形成一个core.pid文件,这个文件还挺大的,如果在某个时间段,有许许多多的服务挂掉,或者一个服务挂了之后重启,重启后又挂掉,这样重重复复会产生大量的core.pid文件,久而久之会将磁盘空间占满,这时候就不再是服务挂掉那么简单的问题了,可能就转变成了操作系统挂掉的严重问题!