机器学习 第一课 初探 定义与应用场景
机器学习 第一课 初探 定义与应用场景
机器学习 (Machine Learning) 是人工智能的一个重要分支. 机器学习已经有几十年的发展历史. 从最初的感知模拟器, 决策树到如今的深度学习 (Deep Learning) 和神经网络 (CNN, Convolutional Neural Network), 机器学习的历史充满了创新和挑战.

机器学习的历史
20 世纪 50 年代, 人工智能 (Artificial Intelligence) 领域崭露头角. 研究者们开始探索图如何让计算机模拟人类的学习能力. 当时, 机器学习主要集中在模式识别和信息领域. 随着时间的推移, 随着技术的进步和和计算性能的提高. 机器学习领域也开始逐渐扩大, 涵盖了如今的神经网络 (Neural Network), 支持向量机 (SVM, Support Vector Machine), 随机森林 (Random Forest) 等多种算法.
机器学习为什么重要?
在信息爆炸的时代, 数据变得越来越多, 越来越复杂. 这些数据包含了大量的信息和知识. 但传统的数据处理方法往往难以有效的挖掘这些信息. 这就使得机器学习 (Machine Learning) 尤为重要. 机器学习可以帮助我们从数据中学习和提取知识, 进而对数据进行预测, 分类等操作.
随着云计算 (Cloud Computing), 大数据 (Big Data), 物联网 (IoT, Internet of Things), 等技术的日新月异, 机器学习也为许多新兴行业提供了强大的支持. 无论是智能制造, 金融分析, 医疗诊断, 自动驾驶, 智能家居等, 都离不开机器学习的应用.
机器学习的定义
传统的编程是基于规则的: 我们给计算机一个明确的指令集, 在特定的情况下执行特定的事情. 然而, 随着数据量的增加和任务的复杂性提高, 这种方法变得效率低下. 举个例子, 如果我们要编写一个宠物猫的识别程序, 在基于规则的编程下, 我们要为每一种可能的猫的形态, 颜色, 大小编写规则, 是一个不可能完成的任务.
机器学习 (Machine Learning) 为我们提供了另一种方法, 它允许计算机从数据中学习规则, 而不是直接告诉它规则. 这样, 喂给模型足够多的宠物猫的图片, 机器学习模型就可以学会识别猫.
机器学习领域有几种经典的定义。其中,Arthur Samuel在1959年提出的定义是:“机器学习是一种让计算机能够在不直接编程的情况下学习的能力。”
而 Tom Mitchell 在1997年给出了一个更为形式化的定义:“如果一个程序在执行某类任务T时,通过利用经验E提高了其性能P,那么我们说这个程序从经验E中学习。”
这两种定义都强调了机器学习与传统编程的主要区别:机器学习是基于数据和经验的,而不是基于预设规则的。
机器学习在日常生活中的应用
机器学习在我们生活的方方面面都有体现, 以下是一些常见例子:
推荐系统
购物网站的商品推荐, 音乐, 短视频平台的内容推荐, 背后都有着机器学习 (Machine Learning) 的支持. 基于用户的历史行为和其他用户行为模式, 推荐系统 (Recommender System) 推荐算法可以预测用户可能感兴趣的商品或内容, 从而提供个性的用户体验.

语音识别
智能助手, 例如 “Siri”, “Google Assistant”, “Alexa” 发出语音命令时, 机器学习算法首先需要识别并转录我们发送的语音, 然后对其进行处理. 这其中设计声学模型和语言模型, 很大程度上是基于机器学习的.
图像识别
社交媒体上的自动标签, 医学图像的疾病检测, 人脸识别很背后都离不开机器学习. 其中, 卷积神经网络 (CNN, Convolutional Neural Network) 是现在非常流行的技术, 可以帮助我们从图片中学习特征.
商业领域的机器学习
金融风险评估
机器学习模型被广泛应用于信用评分和欺诈检测. 通过分析客户的交易记录, 信用历史等信息, 机器学习可以预测用户未来可能的违约风险, 从而帮助金融机构做出更明智的决策.
股票市场预测
虽然股票市场的波动有强的随机性, 但机器学习仍然可以通过分析历史数据来找到某些模式. 一些先进的机器学习模型, 如长短期记忆模型 (LSTM, Long Short-Term Memory), 可以被用于股票价格预测. 在近些年来, 量化交易 (Qualitative Trading) 是一个非常热门的方向.
客户关系管理
客户关系管理 (CRM) 通过分析客户的行为和反馈, 机器学习可以帮助企业更好的理解客户的需求和偏好, 从而提供更个性化的产品或服务.
机器学习在医疗领域的应用
疾病预测
机器学习模型可以通过分析患者的医疗记录, 基因信息等数据, 预测患者是否存在患有某种疾病的风险. 机器学习为早期干预和治疗提供了先机.
药物发现
机器学习也在新药发现领域发挥作用, 通过模拟药物与生物分子的相互作用, 机器学习可以帮助研究人员找到可能的新药物候选.
医疗影像分析
通过对 MRI, CT 扫描等医疗影像进行分析, 机器学习可以帮助医生检测疾病, 如肿瘤, 脑出血等, 并估计其严重程度.
机器学习的主要类型
机器学习的方法可以根据学习方式和任务类型进行分类, 以下是几种主要的机器学习类型:
监督学习
监督学习 (Supervised Learning), 我们提供了带标签的训练数据. 机器学习的任务是通过这些数据学习一个模型, 然后使用这个模型对新数据进行预测. 常见的监督学习任务包括回归 (如房价预测) 和分类 (如电影分类).
无监督学习
无监督学习 (Unsupervised Learning), 我们无需提供带标签的训练数据. 机器学习的任务是找到数据的内在结构或模式. 常见的无监督学习任务包括聚类 (市场细分) 和降维 (PCA).
强化学习
强化学习 (Reinforcement Learning), 在强化学习中, 机器学习不是通过标签学习, 而是通过与环境的交互来学习. 强化学习会在环境中执行行动, 并根据环境的反馈 (奖励或惩罚) 来调整其策略. 强化学习广泛应用于游戏, 机器人和其他需要做出连续决策的领域.
常用的机器学习算法
随着机器学习领域不断发展, 算法也越来越丰富. 一下是一些常用的算法:
线性回归
线性回归 (Linear Regression) 是一种简单的回归算法, 用于预测连续的值. 线性回归的目标变量和输入变量之间存在线性关系.
逻辑回归
逻辑回归 (Logistic Regression) 常用于分类问题, 如二元分类和多元分类.
决策树
决策树 (Decision Tree) 决策树是一种可用于回归和分类任务. 决策树通过递归将数据集分割为子集来工作, 直到子集中的数据都属于同一类或满足某种终止条件.
支持向量机
支持向量机 (Support Vector Machine) 支持向量机是一种分类算法, 通过找到一个屏幕来正确分类数据. 支持向量机可以处理线性和非线性数据, 并可以使用核方法 (Kernel Method) 来处理高维数据.
随机森林
随机森林 (Random Forest) 随机森林是一种集成算法, 由多个决策树 (Decision Tree) 组成, 并将结果汇总, 以提高模型的稳定性和准确性.
评估和验证
训练集 & 测试集
为了评估模型的性能, 我们通常将数据分为训练集合测试集. 模型在训练集 (Train) 上进行训练, 在测试集 (Valid) 上进行测试.
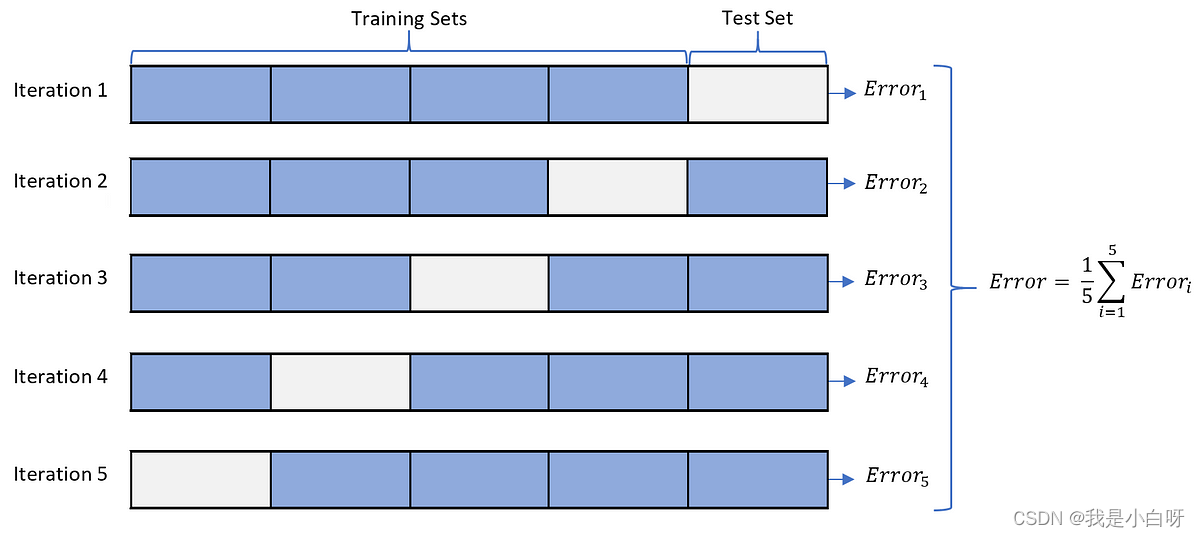
交叉验证
交叉验证 (Cross Validation) 是一种评估模型性能的方法. 交叉验证将数据分为 k-1 个子集进行训练, 剩下的子集进行测试.
机器学习面临的挑战
尽管机器学习在众多领域都取得了显著的成功, 但仍然存在一些技术和实践中的挑战.
数据质量和数量
机学习算法的性能在很大程度上取决于训练数据的质量和数量. 如果数据存在噪声, 错误, 那么模型的预测可能也会不准确或存在偏见. 此外, 对于深度学习需要大数据的方法, 获取足够数据的标记数据可能需要很长的时间, 而且非常昂贵.
模型的可解释性
许多机器学习模型 (如深度学习) 被认为是 “黑箱”. 因为机器学习的工作原理难以解释, 这对于一些需要模型透明性和可解释性的领域 (如医疗和金融) 来说是一个挑战.
过度拟合和泛化
过度拟合 (Overfitting) 是指机器学习模型在训练数上表现的非常好, 然而在验证集上表现不佳. 我们需要选择适当的模型复杂度, 正则化策略和更多的训练数据都是控制 & 避免过拟合的办法.
机器学习的未来前景
更多的跨学科应用
随着技术的进步, 机器学习将与其他领域 (如量子计算, 生物学和材料科学) 更紧密地结合, 为这些领域带来革命性的变革.
向低资源环境拓展
随着轻量级模型和算法的发展, 机器学习将更广泛地应用于资源受限的设备, 如物联网设备和移动设备.