23年10月20日的论文“OpenAnnotate3D: Open-Vocabulary Auto-Labeling System for Multi-modal 3D Data“,来自复旦和多伦多大学。

在大数据和大模型时代,多模态数据的自动标注功能对现实世界的人工智能驱动应用(如自动驾驶和嵌入式人工智能)具有重要意义。与传统的闭集注释不同,开放词汇注释对于实现人类级的认知能力至关重要。然而,很少有用于多模态三维数据的开放词汇自动标注系统。本文介绍OpenAnnotate3D,一个开源的开放词汇自动标注系统,可以自动生成视觉和点云数据的二维掩码、三维掩码和三维边框标注。系统集成了大语言模型(LLM)的思维链能力和视觉语言模型(VLM)的跨模态能力。对公共和内部真实世界数据集进行了全面评估,结果表明,与手动标注相比,该系统显著提高了标注效率,同时提供了准确的开放词汇自动标注结果。
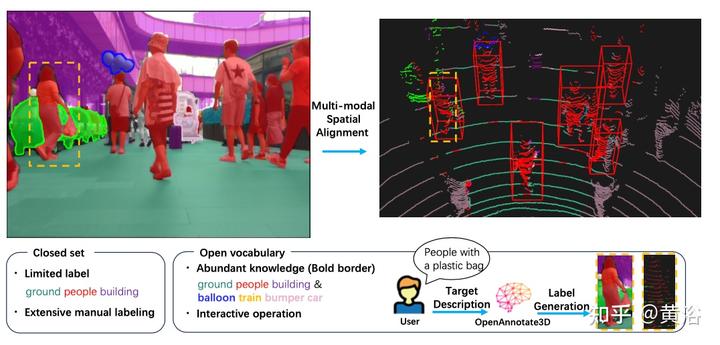
如图为例:与可以为“地面”、“人”和“建筑”等已知类别提供标签的闭集标注系统相比,OpenAnnotate3D可以为“气球”和“碰碰车”等稀有目标提供开放词汇的三维标注。此外,OpenAnnotate3D甚至可以理解高级标签命令,例如“给带塑料袋的人贴标签”。
如图所示是OpenAnnotate3D的工作流程。在接收到用户的标记请求后,系统首先通过LLM解释器和适当的提示工程来解释该请求。请注意,解释器与可提示视觉模块做几轮交互,以便让解释的文本符合可提示视觉模型的推理能力。然后生成密集的2D掩码,并通过多模态空间对齐进一步计算3D掩码。为了克服二维掩码的不完全性,采取时空融合和校正来细化三维标签。

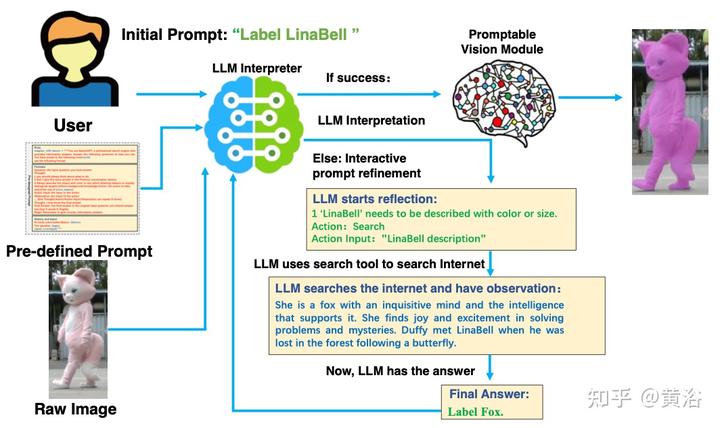
如图说明基于预定义提示的解释过程。使用预定义的提示模板,可以为LLM分配一个角色,指定可用的工具。此外,与可提示视觉模块的交互历史,会被存储并包含在下一个提示。
如图是用于迭代的文本解释流水线。LLM首先解释用户的目标(goal)提示,提取核心内容,然后对可提示视觉模块进行初始查询,获得场景特征。基于来自可提示视觉模块的场景理解结果,LLM解释器不断细化视觉模块的提示。这显著提高了推理能力和分割精度。

文中设计了一种迭代的文本解释策略,如下算法所述,将开放词汇用户提示更好地连接到下游可提示视觉模块。最初,将原始用户提供的文本输入到可提示视觉模块。如果视觉模块无法在文本描述和图像之间建立匹配,它会向LLM解释器提供反馈。提示历史记录将被存储并进一步合并到下一个提示中。然后LLM解释器用LLM中嵌入的语言理解和推理能力调整其输出,直到可提示视觉模块能够很好地理解其指令。

假设视觉模块在L次迭代后仍然无法生成有效的输出,标注系统会中断并向用户提供反馈,要求完善文本输入以描述所需目标。此外,当生成掩码标注时,系统还允许用户评估这些标注。如果他们对结果不满意,这个反馈也会传达给解释器,使系统能够继续迭代以获得更好的标注。
有了基于LLM的解释器,构建了一个可以自动标注三维多模态数据的过程。当前现成的跨模态视觉语言模型基于2D图像,如CLIP[29]和SAM[21]。
1) 多模空间对齐。
OpenAnnotate3D旨在对RGB和3D点云数据执行目标级标记。很少有直接在多模态三维数据上操作的开放词汇模型。为此,作者进行多模态空间对齐,以便更好地利用二维VLM的推理能力。
当RGB和3D点云在空间上对齐时,可以将精确的2D掩码直接投影到3D空间以用作3D分割标注。既然2D掩码标注是从视觉模块生成的,为了获得3D标注,需要将RGB相机图像与3D激光雷达点云在空间上对齐(给定摄像头-激光雷达的标定参数)。
给定对齐良好的RGB图像和3D点云,可以建立精确的点到像素对应关系。通过可提示的视觉模块获得2D掩码,该模块使用SAM(segment-anything)等VLM实现。基于在2D图像坐标中标注的语义目标,可以将同一区域内的对应点标记为同一语义目标。当这些点云被投影回三维世界坐标时,可以直接获得不同目标的三维掩码标注。此外,系统还支持将三维边框拟合到分割和聚集的三维点云,这样标记三维边框。
2) 时空融合和校正。
在处理多帧视频数据时,提供了两种可选的解决方案,可以实现连续帧标注。在第一种方法中,用户可以明确指定视频片段内的开始帧和结束帧。一旦系统自动标记了两个帧,就使用插值算法来标注该视频中的剩余帧。这种方法是高效的,但可能不能保证中间帧注释的准确性。
因此,系统还支持逐帧自动标注视频。然而,问题是VLM可能偶尔会对特定帧的某些目标进行错误标注或遗漏掉,这可能导致较差的3D标注质量,尤其是在诸如遮挡之类的困难情况下。
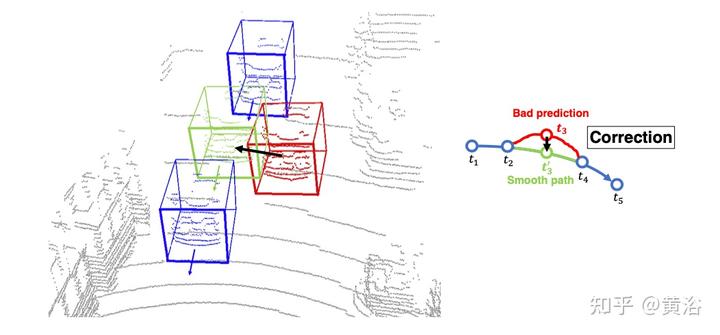
为此,作者提出了一种融合和校正方法,该方法基于一种观察,即重要的是跨帧利用空间和时间信息。如果将时间视为一个附加轴,随着时间的推移,移动的目标将生成一个三维体。该体的横截面表示目标在时间上的瞬时姿态。考虑到物理世界中的大多数目标都遵循运动学定律,保持几何和空间一致性,可以评估和校正目标的轨迹。如图展示了时空融合和校正如何修复错误标注的结果。