1 归一化概述
训练深度神经网络是一项具有挑战性的任务。 多年来,研究人员提出了不同的方法来加速和稳定学习过程。 归一化是一种被证明在这方面非常有效的技术。

1.1 为什么要归一化
数据的归一化操作是数据处理的一项基础性工作,在一些实际问题中,我们得到的样本数据都是多个维度的,即一个样本是用多个特征来表示的,数据样本的不同特征可能会有不同的尺度,这样的情况会影响到数据分析的结果。为了解决这个问题,需要进行数据归一化处理。原始数据经过数据归一化后,各特征处于同一数量级,适合进行综合对比评价。
例如,我们现在用两个特征构建一个简单的神经网络模型。 这两个特征一个是年龄:范围在 0 到 65 之间,另一个是工资:范围从 0 到 10 000。我们将这些特征提供给模型并计算梯度。

不同规模的输入导致不同的权重更新和优化器的步骤向最小值的方向不均衡。这也使损失函数的形状不成比例。在这种情况下,就需要使用较低的学习速率来避免过冲,这就意味着较慢的学习过程。
所以我们的解决方案是输入进行归一化,通过减去平均值(定心)并除以标准偏差来缩小特征。
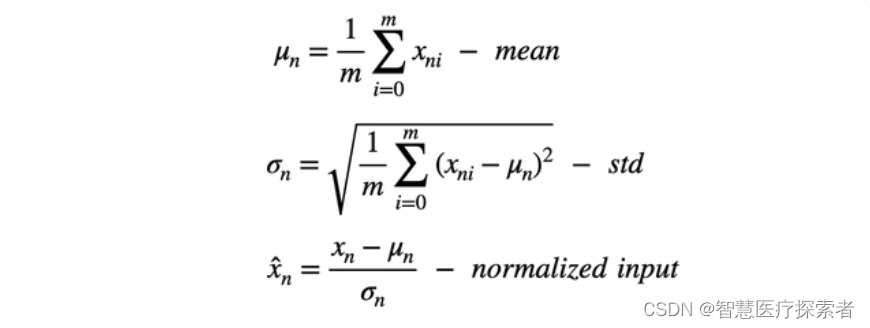
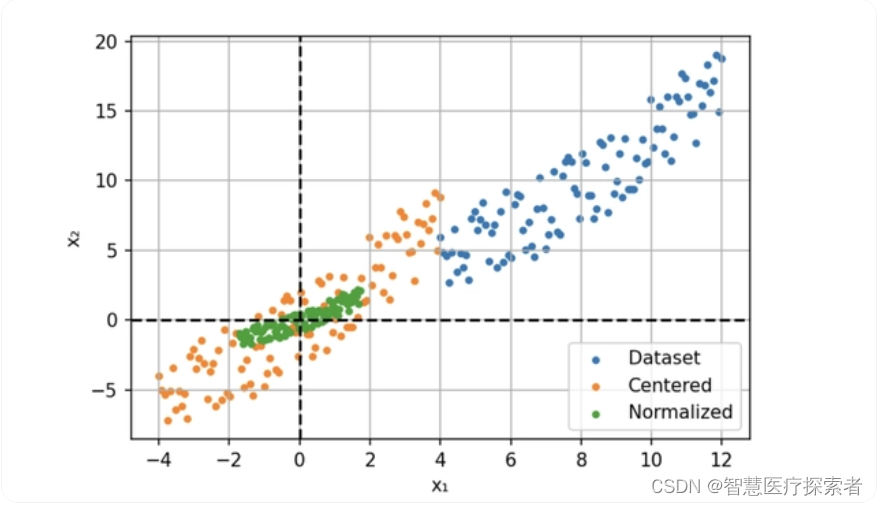
此过程也称为“漂白”,处理后所有的值具有 0 均值和单位方差,这样可以提供更快的收敛和更稳定的训练。
1.2 归一化的作用
在深度学习中,数据归一化是一项关键的预处理步骤,用于优化神经网络模型的训练过程和性能。归一化技术有助于解决梯度消失和梯度爆炸问题,加快模型的收敛速度,并提高模型的鲁棒性和泛化能力。详细介绍如下:
-
梯度消失和梯度爆炸问题:在深度神经网络中,梯度消失和梯度爆炸是常见的问题。数据归一化可以缓解这些问题,使得梯度在合理的范围内进行传播,有助于提高模型的训练效果。
-
特征尺度不一致:深度学习模型对特征的尺度非常敏感。如果不同特征具有不同的尺度范围,某些特征可能会主导模型的训练过程,而其他特征的影响可能被忽略。通过数据归一化,可以将不同特征的尺度统一到相同的范围,使得模型能够平衡地对待所有特征,避免尺度不一致带来的偏差。
-
模型收敛速度:数据归一化可以加快模型的收敛速度。当数据被归一化到一个较小的范围时,模型可以更快地找到合适的参数值,并减少训练过程中的震荡和不稳定性。这样可以节省训练时间,提高模型的效率。
-
鲁棒性和泛化能力:通过数据归一化,模型可以更好地适应不同的数据分布和噪声情况。归一化可以增加模型的鲁棒性,使得模型对输入数据的变化和扰动具有更好的容忍度。同时,归一化还有助于提高模型的泛化能力,使得模型在未见过的数据上表现更好。
1.3 归一化的步骤
归一化通过对数据的特定维度上进行归一化操作来调整输入数据的分布,使其具有零均值和单位方差。一般通过以下步骤对输入进行归一化:
-
对于给定的输入数据,在给定的维度上计算其均值和方差。
-
使用计算得到的均值和方差对输入数据进行标准化,将其零均值化并使其具有单位方差。
-
对标准化后的数据进行缩放和平移操作,通过可学习的参数进行调整,以恢复模型对数据的表达能力。
进一步地,在归一化中,通过缩放和平移操作,引入了可学习的参数,即缩放参数(scale)和平移参数(shift)。这些参数用于在标准化后的数据上进行线性变换,以恢复模型的表达能力。
具体而言,在每个特征维度上,假设归一化后的数据为,则通过以下公式计算最终的输出:
。其中,
是最终的输出,
是缩放参数(scale),
是平移参数(shift)。这两个参数是可学习的,它们可以通过反向传播和优化算法(如随机梯度下降)来进行更新。在训练过程中,模型会通过梯度下降的方式来调整这些参数,使得模型能够自适应地对不同的数据分布进行缩放和平移。这样,模型可以根据实际情况自由地调整每个特征的重要性和偏置,从而更好地适应不同的数据分布。
2 pytorch中的归一化
BatchNorm、LayerNorm 和 GroupNorm 都是深度学习中常用的归一化方式。它们通过将输入归一化到均值为 0 和方差为 1 的分布中,来防止梯度消失和爆炸,并提高模型的泛化能力。
2.1 BatchNorm
一般 CNN 中,卷积层后面会跟一个 BatchNorm 层,减少梯度消失和爆炸,提高模型的稳定性。
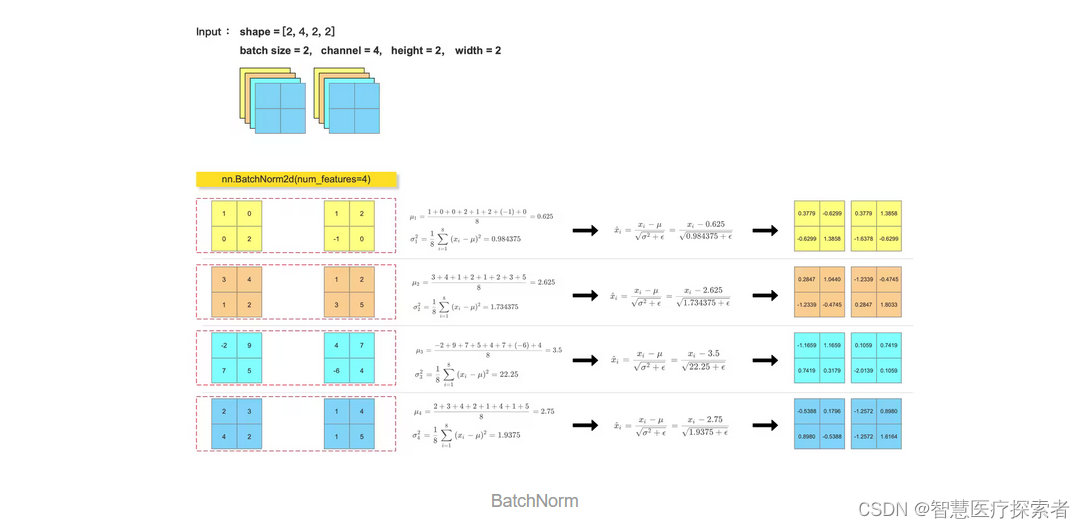
在PyTorch中,可以使用torch.nn.BatchNorm1d、torch.nn.BatchNorm2d或torch.nn.BatchNorm3d等批归一化层来实现批归一化。
实例代码:
import torch
import torch.nn as nn
import numpy as np
feature_array = np.array([[[[1, 0], [0, 2]],
[[3, 4], [1, 2]],
[[-2, 9], [7, 5]],
[[2, 3], [4, 2]]],
[[[1, 2], [-1, 0]],
[[1, 2], [3, 5]],
[[4, 7], [-6, 4]],
[[1, 4], [1, 5]]]], dtype=np.float32)
feature_tensor = torch.tensor(feature_array.copy(), dtype=torch.float32)
bn_out = nn.BatchNorm2d(num_features=4, eps=1e-5)(feature_tensor)
print(bn_out)
for i in range(feature_array.shape[1]):
channel = feature_array[:, i, :, :]
mean = feature_array[:, i, :, :].mean()
var = feature_array[:, i, :, :].var()
print(mean)
print(var)
feature_array[:, i, :, :] = (feature_array[:, i, :, :] - mean) / np.sqrt(var + 1e-5)
print(feature_array)运行结果显示:
tensor([[[[ 0.3780, -0.6299],
[-0.6299, 1.3859]],
[[ 0.2847, 1.0441],
[-1.2339, -0.4746]],
[[-1.1660, 1.1660],
[ 0.7420, 0.3180]],
[[-0.5388, 0.1796],
[ 0.8980, -0.5388]]],
[[[ 0.3780, 1.3859],
[-1.6378, -0.6299]],
[[-1.2339, -0.4746],
[ 0.2847, 1.8034]],
[[ 0.1060, 0.7420],
[-2.0140, 0.1060]],
[[-1.2572, 0.8980],
[-1.2572, 1.6164]]]], grad_fn=<NativeBatchNormBackward0>)
0.625
0.984375
2.625
1.734375
3.5
22.25
2.75
1.9375
[[[[ 0.37796253 -0.6299376 ]
[-0.6299376 1.3858627 ]]
[[ 0.28474656 1.0440707 ]
[-1.2339017 -0.4745776 ]]
[[-1.1659975 1.1659975 ]
[ 0.7419984 0.3179993 ]]
[[-0.53881454 0.17960484]
[ 0.8980242 -0.53881454]]]
[[[ 0.37796253 1.3858627 ]
[-1.6378376 -0.6299376 ]]
[[-1.2339017 -0.4745776 ]
[ 0.28474656 1.8033949 ]]
[[ 0.10599977 0.7419984 ]
[-2.0139956 0.10599977]]
[[-1.2572339 0.8980242 ]
[-1.2572339 1.6164436 ]]]]2.2 LayerNorm
Transformer block 中会使用到 LayerNorm , 一般输入尺寸形为 :(batch_size, token_num, dim),会在最后一个维度做 归一化: nn.LayerNorm(dim)
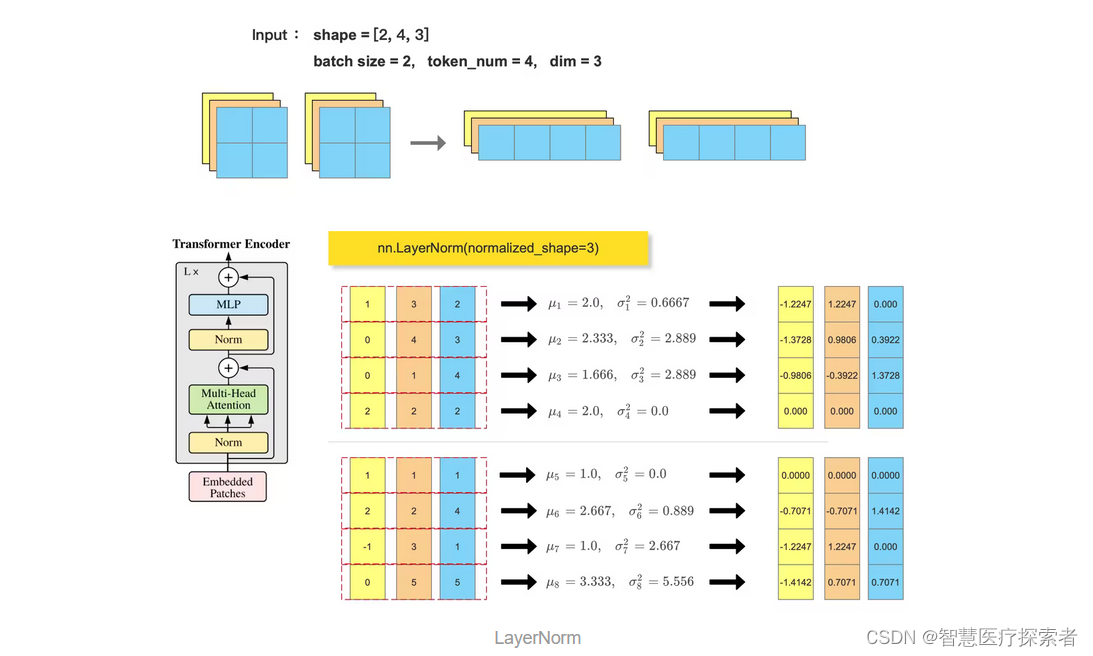
与批归一化不同,层归一化的计算是针对单个样本的特征维度进行的,其目的是将每个样本在单个层内的特征维度进行归一化,以增强特征之间的独立性,并提供更稳定的特征表示。具有以下优点:
-
适用于处理单个样本:相比于批归一化,层归一化的计算是基于单个样本在单个层内的特征维度进行的,而不依赖于小批量样本的统计信息。这使得层归一化适用于处理单个样本的情况,例如在循环神经网络(RNN)中,每个时间步的输入可以被看作是一个单独的样本。
-
适用于动态计算图和序列数据:由于层归一化的计算不依赖于小批量样本的统计信息,它更适合在动态计算图和序列数据上进行计算。在处理变长序列数据或使用动态计算图的场景下,层归一化可以提供更好的性能和效果。
另外,在Transformer模型中使用层归一化(Layer Normalization)主要是因为其独立的特征维度归一化的性质:Transformer模型的核心是自注意力机制,它在每个位置对输入序列中的所有位置进行关注。由于每个位置的特征维度可以看作是独立的,对每个位置进行层归一化可以提供更稳定的特征表示,减少特征之间的耦合,这有助于模型更好地学习位置之间的依赖关系,提高模型的表示能力。并且,减少了特征之间的内部协变量转移,这有助于缓解深度神经网络中常见的梯度消失和梯度爆炸问题,提高模型的训练效果和收敛速度。
层归一化(Layer Normalization)一般来说在激活函数之前应用:在层归一化之后应用激活函数可以使得激活函数的输入保持在归一化后的范围内,避免激活函数的输入过大或过小。这种方式与批标准化的应用顺序相似。
例如:在传统的RNN中,通常是将输入序列经过线性变换后再应用激活函数(如tanh或ReLU)进行非线性变换。然而,这样的操作可能会导致梯度消失或梯度爆炸问题,并且不同时间步的输入之间可能存在较大的变化。通过在激活函数之前应用层归一化,可以解决上述问题。
示例代码:
import torch
import torch.nn as nn
import numpy as np
feature_array = np.array([[[[1, 0], [0, 2]],
[[3, 4], [1, 2]],
[[2, 3], [4, 2]]],
[[[1, 2], [-1, 0]],
[[1, 2], [3, 5]],
[[1, 4], [1, 5]]]], dtype=np.float32)
feature_array = feature_array.reshape((2, 3, -1)).transpose(0, 2, 1)
feature_tensor = torch.tensor(feature_array.copy(), dtype=torch.float32)
ln_out = nn.LayerNorm(normalized_shape=3)(feature_tensor)
print(ln_out)
b, token_num, dim = feature_array.shape
feature_array = feature_array.reshape((-1, dim))
for i in range(b*token_num):
mean = feature_array[i, :].mean()
var = feature_array[i, :].var()
print(mean)
print(var)
feature_array[i, :] = (feature_array[i, :] - mean) / np.sqrt(var + 1e-5)
print(feature_array.reshape(b, token_num, dim))代码运行显示:
tensor([[[-1.2247, 1.2247, 0.0000],
[-1.3728, 0.9806, 0.3922],
[-0.9806, -0.3922, 1.3728],
[ 0.0000, 0.0000, 0.0000]],
[[ 0.0000, 0.0000, 0.0000],
[-0.7071, -0.7071, 1.4142],
[-1.2247, 1.2247, 0.0000],
[-1.4142, 0.7071, 0.7071]]], grad_fn=<NativeLayerNormBackward0>)
2.0
0.6666667
2.3333333
2.888889
1.6666666
2.888889
2.0
0.0
1.0
0.0
2.6666667
0.88888884
1.0
2.6666667
3.3333333
5.555556
[[[-1.2247357 1.2247357 0. ]
[-1.3728105 0.980579 0.3922316 ]
[-0.98057896 -0.39223155 1.3728106 ]
[ 0. 0. 0. ]]
[[ 0. 0. 0. ]
[-0.70710295 -0.70710295 1.4142056 ]
[-1.2247427 1.2247427 0. ]
[-1.4142123 0.7071062 0.7071062 ]]]2.3 GroupNorm
batch size 过大或过小都不适合使用 BN,而是使用 GN。
(1)当 batch size 过大时,BN 会将所有数据归一化到相同的均值和方差。这可能会导致模型在训练时变得非常不稳定,并且很难收敛。
(2)当 batch size 过小时,BN 可能无法有效地学习数据的统计信息。
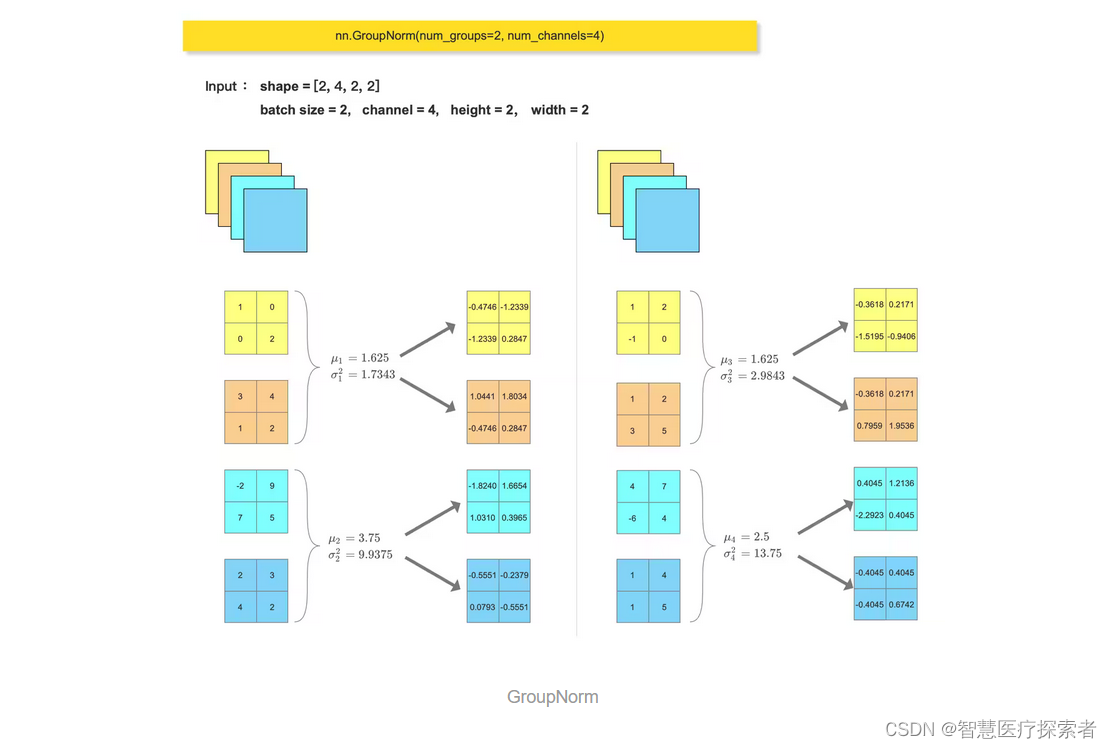
比如,Deformable DETR 中,就用到了 GroupNorm

示例代码:
import torch
import torch.nn as nn
import numpy as np
feature_array = np.array([[[[1, 0], [0, 2]],
[[3, 4], [1, 2]],
[[-2, 9], [7, 5]],
[[2, 3], [4, 2]]],
[[[1, 2], [-1, 0]],
[[1, 2], [3, 5]],
[[4, 7], [-6, 4]],
[[1, 4], [1, 5]]]], dtype=np.float32)
feature_tensor = torch.tensor(feature_array.copy(), dtype=torch.float32)
gn_out = nn.GroupNorm(num_groups=2, num_channels=4)(feature_tensor)
print(gn_out)
feature_array = feature_array.reshape((2, 2, 2, 2, 2)).reshape((4, 2, 2, 2))
for i in range(feature_array.shape[0]):
channel = feature_array[i, :, :, :]
mean = feature_array[i, :, :, :].mean()
var = feature_array[i, :, :, :].var()
print(mean)
print(var)
feature_array[i, :, :, :] = (feature_array[i, :, :, :] - mean) / np.sqrt(var + 1e-5)
feature_array = feature_array.reshape((2, 2, 2, 2, 2)).reshape((2, 4, 2, 2))
print(feature_array)运行结果显示:
tensor([[[[-0.4746, -1.2339],
[-1.2339, 0.2847]],
[[ 1.0441, 1.8034],
[-0.4746, 0.2847]],
[[-1.8240, 1.6654],
[ 1.0310, 0.3965]],
[[-0.5551, -0.2379],
[ 0.0793, -0.5551]]],
[[[-0.3618, 0.2171],
[-1.5195, -0.9406]],
[[-0.3618, 0.2171],
[ 0.7959, 1.9536]],
[[ 0.4045, 1.2136],
[-2.2923, 0.4045]],
[[-0.4045, 0.4045],
[-0.4045, 0.6742]]]], grad_fn=<NativeGroupNormBackward0>)
1.625
1.734375
3.75
9.9375
1.625
2.984375
2.5
13.75
[[[[-0.4745776 -1.2339017 ]
[-1.2339017 0.28474656]]
[[ 1.0440707 1.8033949 ]
[-0.4745776 0.28474656]]
[[-1.8240178 1.6654075 ]
[ 1.0309665 0.3965256 ]]
[[-0.55513585 -0.23791535]
[ 0.07930512 -0.55513585]]]
[[[-0.3617867 0.21707201]
[-1.5195041 -0.9406454 ]]
[[-0.3617867 0.21707201]
[ 0.79593074 1.9536481 ]]
[[ 0.40451977 1.2135593 ]
[-2.2922788 0.40451977]]
[[-0.40451977 0.40451977]
[-0.40451977 0.67419964]]]]