ElasticSearch
倒排索引
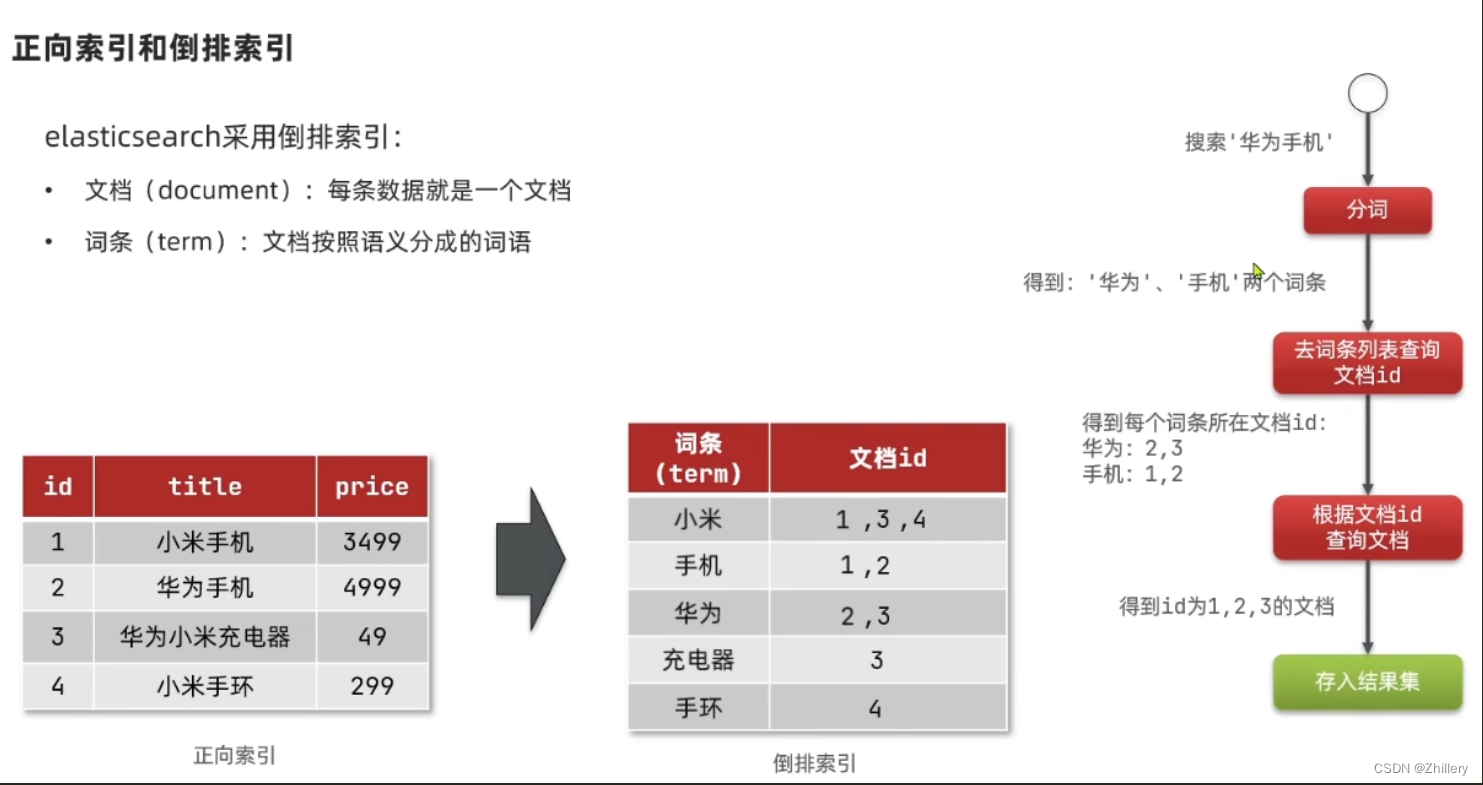
倒排索引建立:对文章标题进行分词,将每个词存入 term,这些词也对应一个 id 也就是文档
倒排索引检索:假设我们搜索华为手机
- 分词:“华为”“手机”
- 从数据库中找到对应的两个 key,及其文档 id
- 由于文档 id 分别是 2,3 以及 1,2;可见文档 id=2 重合度最高,最符合搜索条件,则搜索结果他会排在最前面
- 搜索结果存入结果集
环境配置
首先你需要下载下面三个东西(这边选择 7.8 版本是为了兼容低版本 JAVA,高版本的 ES 必须要高版本 JDK,十分不方便)
注意!由于我们是在 windows 下搭建的环境,所以下载 ik 分词器时务必下载 elasticsearch-analysis-ik-7.8.0.zip 这个编译好的包,别下载源码包了!!!
三件套全部版本都必须一致!不存在什么向下或者向上兼容!
windows 下安装非常简单,把三个压缩包全部解压到一个非中文路径的目录下
先把 ik 分词器 压缩包的所有内容丢到 es7.8 根目录下的 plugins 文件夹
打开 es7.8 的 JVM 配置文件:es7.8/config/jvm.options
调节一下运行内存,否则一运行必定爆内存然后闪退
-Xms1g
-Xmx1g
大功告成,双击运行下面这两个 bat 文件即可(注意先后顺序)
es根目录/bin/elasticsearch.batkibana根目录/bin/kibana.bat
es 默认运行 9200 端口,kibana 默认运行 5601 端口
测试 ik 分词器
打开 kibana 控制台localhost:5601
点击左上角菜单,拉到最下面选择 dev tools
在这里可以随意测试我们的 es 代码,比如说插入索引和查询啥的
按照下图格式,我们使用 ik 智能分词器对一行包含汉语和英语的文字执行了分词操作
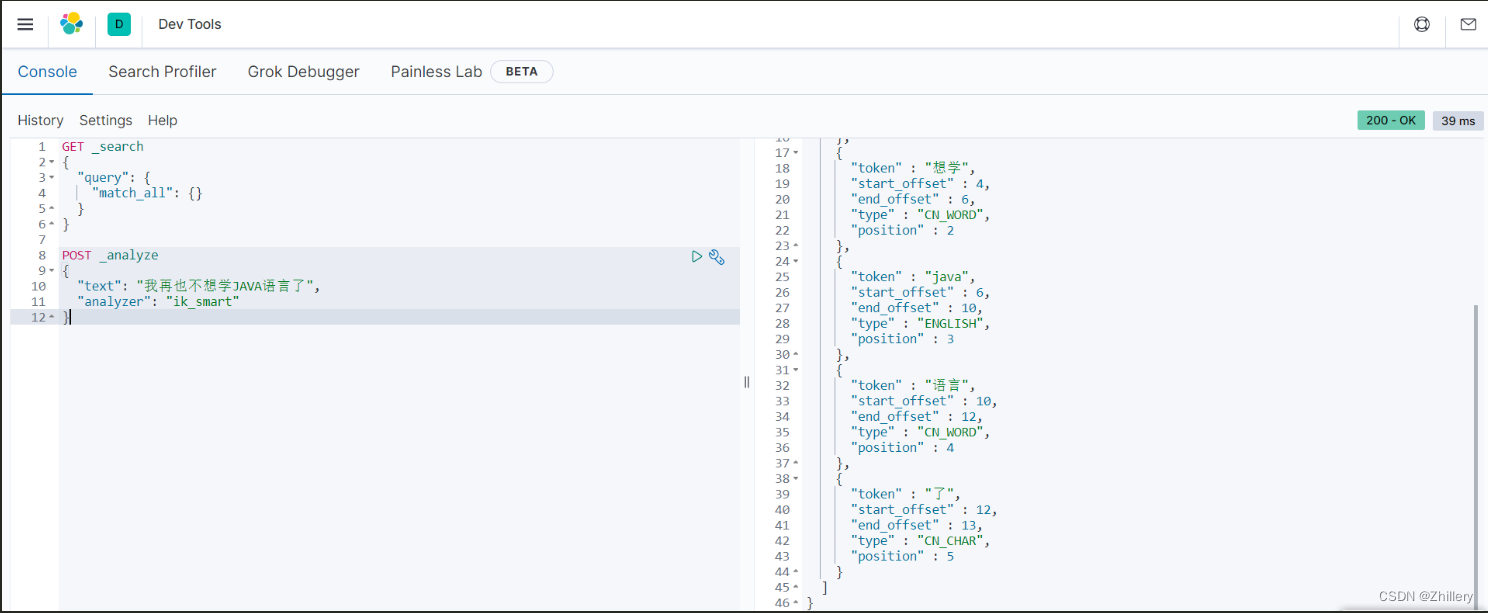
POST _analyze
{
"text": "我再也不想学JAVA语言了",
"analyzer": "ik_smart"
}
添加扩展词典
网络热词不可能总是被 ik 分词器所收录,更何况是中文,所以特殊情况下我们需要添加扩展字典来帮助 ik 分词器正确识别网络新词
首先打开 ik 分词器扩展设置文件:es根目录/plugins/analysis-ik/config/IKAnalyzer.cfg.xml
把他改成下面的样子
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
同目录下新建文件 ext.dic 用于存放扩展词,扩展词每写一个换一次行
我们可以添加以下两个扩展词
小黑子
煤油树枝
香精煎鱼
香菜凤仁鸡
梅素汁
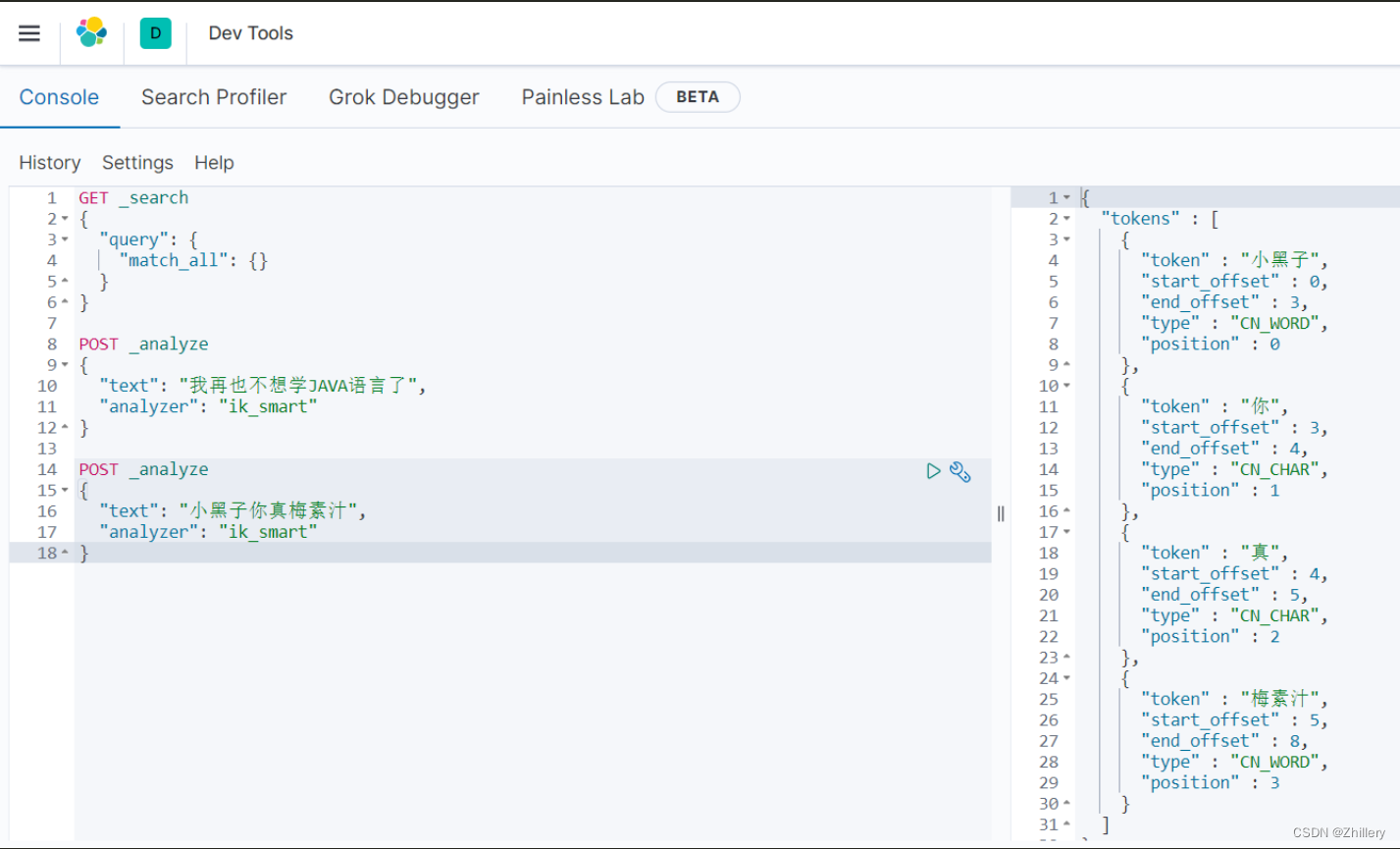
重启 es7.8,然后再次回到我们的 kibana 界面
可见,ik 分词器成功的识别出了网络热词并执行分词操作!
操作索引
创建一个简单的索引只需要按照以下的代码进行简要修改即可
PUT /heima
{
"mappings": {
"properties": {
"info":{
// 设置字段名为"info"的映射
"type": "text", // 设置字段类型为"text"
"analyzer": "ik_smart" // 使用中文分词器"ik_smart"进行分词
},
"email":{
// 设置字段名为"email"的映射
"type": "keyword", // 设置字段类型为"keyword",表示不会进行分词
"index": false // 设置不对该字段进行索引,即无法通过该字段进行搜索
},
"name":{
// 设置字段名为"name"的映射
"type": "object", // 设置字段类型为"object",表示是一个嵌套对象
"properties": {
// 定义嵌套对象的属性
"firstname":{
// 设置嵌套对象的属性名为"firstname"的映射
"type":"keyword" // 设置属性类型为"keyword",表示不会进行分词
},
"lastname":{
// 设置嵌套对象的属性名为"lastname"的映射
"type":"keyword" // 设置属性类型为"keyword",表示不会进行分词
}
}
}
}
}
}
在 dev tools 中执行完毕后的结果是
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "heima"
}
索引与文档操作
es 中索引库和 mapping 一旦创建后就无法修改,但是可以向其中添加新的字段
如下指令,向索引 heima 添加了一个新的字段叫做 age
PUT /heima/_mapping
{
"properties":{
"age":{
"type":"keyword"
}
}
}
获取索引库:GET /索引库名称
删除索引库:DELETE /索引库名称