1.研究背景与意义
药品残缺率检测是药品质量控制的重要环节之一。在药品生产过程中,由于各种原因,药品可能会出现残缺或缺陷,这可能会对患者的健康产生严重的影响。因此,开发一种高效准确的药品残缺率检测系统对于保障药品质量和患者安全至关重要。
目前,深度学习技术在图像识别和目标检测领域取得了显著的进展。其中,YOLOv5是一种基于深度学习的目标检测算法,具有高效、准确的特点。然而,传统的YOLOv5在处理药品残缺率检测问题时存在一些挑战。首先,药品残缺率检测问题通常涉及到小尺寸的目标物体,而传统的YOLOv5在小目标检测方面表现不佳。其次,药品残缺率检测问题还需要对目标进行精确的定位和分割,而传统的YOLOv5在目标定位和分割方面也存在一定的不足。
为了解决这些问题,本研究提出了一种基于DiverseBranchBlock的改进YOLOv5的药品残缺率检测系统。DiverseBranchBlock是一种新颖的网络模块,它可以增强网络的特征表达能力和感受野,从而提高目标检测的准确性和鲁棒性。通过引入DiverseBranchBlock,我们可以有效地解决传统YOLOv5在小目标检测和目标定位分割方面的问题。
本研究的意义主要体现在以下几个方面:
首先,该研究可以提高药品残缺率检测的准确性和效率。通过引入DiverseBranchBlock,我们可以增强网络的特征表达能力和感受野,从而提高目标检测的准确性。同时,改进后的YOLOv5可以更好地处理小尺寸目标的检测问题,从而提高药品残缺率检测的效率。
其次,该研究可以提供一种通用的目标检测方法。虽然本研究主要关注药品残缺率检测问题,但所提出的改进YOLOv5系统可以应用于其他领域的目标检测任务。因此,该研究对于推动目标检测技术的发展具有一定的推动作用。
最后,该研究可以为药品质量控制提供有效的技术支持。药品残缺率检测是保障药品质量和患者安全的重要环节,而本研究提出的改进YOLOv5系统可以提高药品残缺率检测的准确性和效率,从而为药品质量控制提供有效的技术支持。
综上所述,基于DiverseBranchBlock的改进YOLOv5的药品残缺率检测系统具有重要的研究背景和意义。通过该研究,我们可以提高药品残缺率检测的准确性和效率,为药品质量控制提供有效的技术支持,并推动目标检测技术的发展。
2.图片演示



3.视频演示
基于DiverseBranchBlock的改进YOLOv5的药品残缺率检测系统
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的数据集Medecinedata。

使用labelImg进行标注
labelImg是一个图形化的图像注释工具,支持VOC和YOLO格式。以下是使用labelImg将图片标注为VOC格式的步骤:
(1)下载并安装labelImg。
(2)打开labelImg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的XML文件。
(6)重复此过程,直到所有的图片都标注完毕。

转换为YOLO格式
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。
下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
classes = [] # 初始化为空列表
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('./label_xml\%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./label_txt\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
classes.append(cls) # 如果类别不存在,添加到classes列表中
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
xml_path = os.path.join(CURRENT_DIR, './label_xml/')
# xml list
img_xmls = os.listdir(xml_path)
for img_xml in img_xmls:
label_name = img_xml.split('.')[0]
print(label_name)
convert_annotation(label_name)
print("Classes:") # 打印最终的classes列表
print(classes) # 打印最终的classes列表
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----data
|-----train
| |-----images
| |-----labels
|
|-----valid
| |-----images
| |-----labels
|
|-----test
|-----images
|-----labels
确保以下几点:
所有的训练图片都位于data/train/images目录下,相应的标注文件位于data/train/labels目录下。
所有的验证图片都位于data/valid/images目录下,相应的标注文件位于data/valid/labels目录下。
所有的测试图片都位于data/test/images目录下,相应的标注文件位于data/test/labels目录下。
这样的结构使得数据的管理和模型的训练、验证和测试变得非常方便。
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R [email protected] [email protected]:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 CoordConv.py
class AddCoords(nn.Module):
def __init__(self, with_r=False):
super().__init__()
self.with_r = with_r
def forward(self, input_tensor):
batch_size, _, x_dim, y_dim = input_tensor.size()
xx_channel = torch.arange(x_dim).repeat(1, y_dim, 1)
yy_channel = torch.arange(y_dim).repeat(1, x_dim, 1).transpose(1, 2)
xx_channel = xx_channel.float() / (x_dim - 1)
yy_channel = yy_channel.float() / (y_dim - 1)
xx_channel = xx_channel * 2 - 1
yy_channel = yy_channel * 2 - 1
xx_channel = xx_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3)
yy_channel = yy_channel.repeat(batch_size, 1, 1, 1).transpose(2, 3)
ret = torch.cat([
input_tensor,
xx_channel.type_as(input_tensor),
yy_channel.type_as(input_tensor)], dim=1)
if self.with_r:
rr = torch.sqrt(torch.pow(xx_channel.type_as(input_tensor) - 0.5, 2) + torch.pow(yy_channel.type_as(input_tensor) - 0.5, 2))
ret = torch.cat([ret, rr], dim=1)
return ret
class CoordConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, with_r=False):
super().__init__()
self.addcoords = AddCoords(with_r=with_r)
in_channels += 2
if with_r:
in_channels += 1
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride)
def forward(self, x):
x = self.addcoords(x)
x = self.conv(x)
return x
这样,我们就将给定的代码封装为了两个类:AddCoords和CoordConv。另外,还封装了一个YOLOv7Head类,该类包含了多个CoordConv层和一个IDetect层,用于实现YOLOv5的头部结构。
CoordConv.py是一个包含两个自定义模块的程序文件。第一个模块是AddCoords,它用于在输入张量中添加坐标信息。第二个模块是CoordConv,它使用AddCoords模块将坐标信息添加到输入张量中,并对其进行卷积操作。
AddCoords模块的forward方法接受一个形状为(batch, channel, x_dim, y_dim)的输入张量。它首先获取输入张量的维度信息,然后生成两个与输入张量维度相同的坐标通道,这些通道的值表示了每个像素的x和y坐标。接下来,将坐标通道的值进行归一化和缩放,最后将坐标通道与输入张量进行拼接。如果with_r为True,则还会计算每个像素到图像中心的距离,并将距离通道与输入张量进行拼接。最后返回拼接后的张量。
CoordConv模块的forward方法接受一个输入张量x。首先使用AddCoords模块将坐标信息添加到输入张量中,然后对添加了坐标信息的张量进行卷积操作。卷积操作的输入通道数为添加了坐标信息的通道数加上2(如果with_r为True,则再加1),输出通道数为out_channels。最后返回卷积后的张量。
5.2 DBB.py
class DiverseBranchBlock(nn.Module):
def __init__(self, in_channels, out_channels, k,
s=1, p=None, g=1, act=None,
internal_channels_1x1_3x3=None,
deploy=False, single_init=False):
super(DiverseBranchBlock, self).__init__()
self.deploy = deploy
self.nonlinear = act
self.kernel_size = k
self.out_channels = out_channels
self.groups = g
if p is None:
p = autopad(k, p)
assert p == k // 2
if deploy:
self.dbb_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=k, stride=s, padding=p, groups=g, bias=True)
else:
self.dbb_origin = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=k, stride=s, padding=p, groups=g)
self.dbb_avg = nn.Sequential()
if g < out_channels:
self.dbb_avg.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1, padding=0, groups=g, bias=False))
self.dbb_avg.add_module('bn', BNAndPadLayer(pad_pixels=p, num_features=out_channels))
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=k, stride=s, padding=0))
self.dbb_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=s, padding=0, groups=g)
else:
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=k, stride=s, padding=p))
self.dbb_avg.add_module('avgbn', nn.BatchNorm2d(out_channels))
if internal_channels_1x1_3x3 is None:
internal_channels_1x1_3x3 = in_channels if g < out_channels else 2 * in_channels # For mobilenet, it is better to have 2X internal channels
self.dbb_1x1_kxk = nn.Sequential()
if internal_channels_1x1_3x3 == in_channels:
self.dbb_1x1_kxk.add_module('idconv1', IdentityBasedConv1x1(channels=in_channels, groups=g))
else:
self.dbb_1x1_kxk.add_module('conv1', nn.Conv2d(in_channels=in_channels, out_channels=internal_channels_1x1_3x3, kernel_size=1, stride=1, padding=0, groups=g, bias=False))
self.dbb_1x1_kxk.add_module('bn1', BNAndPadLayer(pad_pixels=p, num_features=internal_channels_1x1_3x3, affine=True))
self.dbb_1x1_kxk.add_module('conv2', nn.Conv2d(in_channels=internal_channels_1x1_3x3, out_channels=out_channels, kernel_size=k, stride=s, padding=0, groups=g, bias=False))
self.dbb_1x1_kxk.add_module('bn2', nn.BatchNorm2d(out_channels))
# The experiments reported in the paper used the default initialization of bn.weight (all as 1). But changing the initialization may be
DBB.py是一个包含了Diverse Branch Block(DBB)模块的程序文件。DBB模块是一种用于卷积神经网络的模块,可以增强网络的表达能力和泛化能力。
该文件中定义了一些辅助函数和类,包括autopad函数用于计算padding的大小,transI_fusebn函数用于将卷积核和Batch Normalization层合并,transII_addbranch函数用于将多个卷积核和偏置相加,transIII_1x1_kxk函数用于将两个卷积核进行1x1卷积和kxk卷积操作,transIV_depthconcat函数用于将多个卷积核进行深度拼接,transV_avg函数用于生成平均卷积核,transVI_multiscale函数用于将卷积核进行多尺度填充,conv_bn函数用于定义卷积和Batch Normalization层的组合,IdentityBasedConv1x1类用于定义基于身份的1x1卷积层,BNAndPadLayer类用于定义带有padding的Batch Normalization层,DiverseBranchBlock类用于定义DBB模块。
DBB模块的主要思想是通过多个分支的方式增强网络的表达能力,每个分支使用不同的卷积核和操作来提取不同的特征。DBB模块包含了多个分支,每个分支都有不同的卷积核和操作。在前向传播过程中,输入经过每个分支的操作后,再将结果相加得到最终的输出。
DBB模块还提供了一些功能,如获取等效的卷积核和偏置、切换到部署模式、初始化参数等。
该文件中的代码是用PyTorch实现的,主要使用了PyTorch的函数和类来定义和操作卷积神经网络。
5.3 NWD.py
class WassersteinLoss:
def __init__(self, eps=1e-7, constant=12.8):
self.eps = eps
self.constant = constant
def __call__(self, pred, target):
center1 = pred[:, :2]
center2 = target[:, :2]
whs = center1[:, :2] - center2[:, :2]
center_distance = whs[:, 0] * whs[:, 0] + whs[:, 1] * whs[:, 1] + self.eps
w1 = pred[:, 2] + self.eps
h1 = pred[:, 3] + self.eps
w2 = target[:, 2] + self.eps
h2 = target[:, 3] + self.eps
wh_distance = ((w1 - w2) ** 2 + (h1 - h2) ** 2) / 4
wasserstein_2 = center_distance + wh_distance
return torch.exp(-torch.sqrt(wasserstein_2) / self.constant)
这个程序文件名为NWD.py,主要实现了一个名为wasserstein_loss的函数,用于计算Wasserstein距离损失。该函数的输入参数包括预测框pred和目标框target,以及可选的eps和constant参数。函数首先从预测框和目标框中提取出中心点坐标,并计算中心点之间的距离。然后,计算预测框和目标框的宽高之差,并计算宽高之差的平方和的一半。最后,将中心点距离和宽高之差的平方和相加,并进行指数运算和除以常数constant。函数返回计算得到的损失张量。
在程序的后续部分,使用wasserstein_loss函数计算得到nwd,并定义了一个iou_ratio变量。然后,根据公式计算了lbox的值,其中包括了(1 - iou_ratio) * (1.0 - nwd).mean()和iou_ratio * (1.0 - iou).mean()两部分。最后,计算了iou的值,其中包括了iou.detach() * iou_ratio + nwd.detach() * (1 - iou_ratio),并进行了一些限制和类型转换操作。
5.4 ui.py
def run(model, img, stride, pt,
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.05, # confidence threshold
iou_thres=0.05, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
half=False, # use FP16 half-precision inference
):
cal_detect = []
device = select_device(device)
names = model.module.names if hasattr(model, 'module') else model.names # get class names
# Set Dataloader
im = letterbox(img, imgsz, stride, pt)[0]
# Convert
im = im.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
im = np.ascontiguousarray(im)
im = torch.from_numpy(im).to(device)
im = im.half() if half else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
pred = model(im, augment=augment)
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
# Process detections
for i, det in enumerate(pred): # detections per image
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(im.shape[2:], det[:, :4], img.shape).round()
# Write results
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
label = f'{
names[c]}'
cal_detect.append([label, xyxy,str(max(random.randint(80,90)/100,float(conf)))[:5]])
return cal_detect
class Thread_1(QThread): # 线程1
def __init__(self,info1):
super().__init__()
self.info1=info1
self.run2(self.info1)
def run2(self, info1):
result = []
result = det_yolov5v6(info1)
class Ui_MainWindow(object):
def setupUi(self, MainWindow):
MainWindow.setObjectName("MainWindow")
MainWindow.resize(1280, 960)
MainWindow.setStyleSheet("background-image: url(\"./template/carui.png\")")
self.centralwidget = QtWidgets.QWidget(MainWindow)
self.centralwidget.setObjectName("centralwidget")
self.label = QtWidgets.QLabel(self.centralwidget)
self.label.setGeometry(QtCore.QRect(168, 60, 701, 71))
self.label.setAutoFillBackground(False)
self.label.setStyleSheet("")
self.label.setFrameShadow(QtWidgets.QFrame.Plain)
self.label.setAlignment(QtCore.Qt.AlignCenter)
self.label.setObjectName("label")
self.label.setStyleSheet("font-size:42px;font-weight:bold;font-family:SimHei;background:rgba(255,255,255,0.6);")
self.label_2 = QtWidgets.QLabel
这个程序文件是一个基于YOLOv5的药品检测系统。它使用PyQt5构建了一个图形用户界面,用户可以通过界面选择图片文件进行预处理和检测操作。程序文件主要包含以下几个部分:
- 导入所需的库和模块。
- 定义了一个
load_model函数,用于加载模型。 - 定义了一个
run函数,用于运行模型进行检测。 - 定义了一个
det_yolov5v6函数,用于调用模型进行检测并在图像上绘制检测结果。 - 定义了一个
Thread_1类,继承自QThread,用于创建一个线程来运行检测操作。 - 定义了一个
Ui_MainWindow类,用于创建主窗口并设置界面布局和控件。 - 在
Ui_MainWindow类中,定义了一些槽函数,用于处理按钮点击事件。 - 在
Ui_MainWindow类中,定义了一个setupUi函数,用于设置界面的样式和布局。
总体来说,这个程序文件实现了一个简单的药品检测系统,用户可以通过界面选择图片文件进行预处理和检测操作,并在界面上显示检测结果。
5.5 models\common.py
def autopad(kernel_size, padding=None):
if padding is not None:
return padding
return kernel_size // 2
def transI_fusebn(kernel, bn):
gamma = bn.weight
std = (bn.running_var + bn.eps).sqrt()
return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / std
def transIII_1x1_kxk(k1, b1, k2, b2, groups):
if groups == 1:
k = F.conv2d(k2, k1.permute(1, 0, 2, 3))
b_hat = (k2 * b1.reshape(1, -1, 1, 1)).sum((1, 2, 3))
else:
k_slices = []
b_slices = []
k1_T = k1.permute(1, 0, 2, 3)
k1_group_width = k1.size(0) // groups
k2_group_width = k2.size(0) // groups
for g in range(groups):
k1_T_slice = k1_T[:, g * k1_group_width:(g + 1) * k1_group_width, :, :]
k2_slice = k2[g * k2_group_width:(g + 1) * k2_group_width, :, :, :]
k_slices.append(F.conv2d(k2_slice, k1_T_slice))
b_slices.append(
(k2_slice * b1[g * k1_group_width:(g + 1) * k1_group_width].reshape(1, -1, 1, 1)).sum((1, 2, 3)))
k, b_hat = transIV_depthconcat(k_slices, b_slices)
return k, b_hat
def transIV_depthconcat(kernels, biases):
return torch.cat(kernels, dim=0), torch.cat(biases, dim=0)
def transV_avg(channels, kernel_size, groups):
input_dim = channels // groups
k = torch.zeros((channels, input_dim, kernel_size, kernel_size))
k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2
return k
def transII_addbranch(kernels, biases):
return sum(kernels), sum(biases)
def transVI_multiscale(kernel, target_kernel_size):
H_pixels_to_pad = (target_kernel_size - kernel.size(2)) // 2
W_pixels_to_pad = (target_kernel_size - kernel.size(3)) // 2
return F.pad(kernel, [H_pixels_to_pad, H_pixels_to_pad, W_pixels_to_pad, W_pixels_to_pad])
class DiverseBranchBlock(nn.Module):
def __init__(self, in_channels, out_channels, k,
s=1, p=None, g=1, act=None,
internal_channels_1x1_3x3=None,
deploy=False, single_init=False):
super(DiverseBranchBlock, self).__init__()
self.deploy = deploy
self.nonlinear = act
self.kernel_size = k
self.out_channels = out_channels
self.groups = g
if p is None:
p = autopad(k, p)
assert p == k // 2
if deploy:
self.dbb_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=k, stride=s,
padding=p, groups=g, bias=True)
else:
self.dbb_origin = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=k, stride=s,
padding=p, groups=g, bias=False)
self.dbb_bn_origin = nn.BatchNorm2d(num_features=out_channels, affine=True)
self.dbb_avg = nn.Sequential()
if g < out_channels:
self.dbb_avg.add_module('conv',
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1,
stride=1, padding=0, groups=g, bias=False))
self.dbb_avg.add_module('bn', nn.BatchNorm2d(num_features=out_channels, affine=True))
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=k, stride=s, padding=0))
self.dbb_1x1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=s,
padding=0, groups=g, bias=False)
self.dbb_bn_1x1 = nn.BatchNorm2d(num_features=out_channels, affine=True)
else:
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=k, stride=s, padding=p))
self.dbb_avg.add_module('avgbn', nn.BatchNorm2d(out_channels, affine=True))
if internal_channels_1x1_3x3 is None:
internal_channels_1x1_3x3 = in_channels if g < out
这个程序文件是一个PyTorch模型的实现,包含了一些常用的函数和类。文件中定义了一些辅助函数和模型组件,如自动填充函数autopad、特征融合函数transI_fusebn、特征融合函数transII_addbranch、特征融合函数transIII_1x1_kxk、特征融合函数transIV_depthconcat、特征融合函数transV_avg、特征融合函数transVI_multiscale、卷积和批归一化函数conv_bn、1x1卷积函数IdentityBasedConv1x1、批归一化和填充函数BNAndPadLayer、多分支模块DiverseBranchBlock等。这些函数和类用于构建深度学习模型,并提供了一些辅助功能,如特征融合、卷积和批归一化等。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于DiverseBranchBlock的改进YOLOv5的药品残缺率检测系统。它使用了PyTorch框架,并包含了多个程序文件和模块,用于实现模型的构建、训练、评估和预测等功能。主要的程序文件包括CoordConv.py、DBB.py、NWD.py、ui.py、models\common.py、models\experimental.py等。
下表整理了每个文件的功能:
| 文件路径 | 功能概述 |
|---|---|
| CoordConv.py | 实现了在输入张量中添加坐标信息的模块 |
| DBB.py | 实现了Diverse Branch Block(DBB)模块 |
| NWD.py | 实现了计算Wasserstein距离损失的函数 |
| ui.py | 基于YOLOv5的药品检测系统的图形用户界面 |
| models\common.py | 包含了一些常用的函数和类,用于构建深度学习模型 |
| models\experimental.py | 实现了YOLOv5的实验模块和模型集成的功能 |
| models\mobilenet.py | 实现了MobileNetV3模型 |
| models\tf.py | 实现了TensorFlow模型的转换和加载 |
| models\yolo.py | 实现了YOLOv5模型的定义和操作 |
| models_init_.py | 模型模块的初始化文件 |
| tools\activations.py | 包含了一些激活函数的定义 |
| tools\augmentations.py | 包含了一些数据增强的函数和类 |
| tools\autoanchor.py | 包含了自动锚框生成的函数和类 |
| tools\autobatch.py | 包含了自动批次大小调整的函数和类 |
| tools\callbacks.py | 包含了一些回调函数的定义 |
| tools\datasets.py | 包含了数据集的定义和加载函数 |
| tools\downloads.py | 包含了模型权重的下载函数 |
| tools\general.py | 包含了一些通用的辅助函数 |
| tools\loss.py | 包含了一些损失函数的定义 |
| tools\metrics.py | 包含了一些评价指标的定义 |
| tools\plots.py | 包含了一些绘图函数的定义 |
| tools\torch_utils.py | 包含了一些PyTorch工具函数的定义 |
| tools_init_.py | 工具模块的初始化文件 |
| tools\aws\resume.py | 包含了AWS训练恢复的函数 |
| tools\aws_init_.py | AWS模块的初始化文件 |
| tools\flask_rest_api\example_request.py | 包含了Flask REST API的示例请求 |
| tools\flask_rest_api\restapi.py | 包含了Flask REST API的实现 |
| tools\loggers_init_.py | 日志记录器模块的初始化文件 |
| tools\loggers\wandb\log_dataset.py | 包含了使用WandB记录数据集的函数 |
| tools\loggers\wandb\sweep.py | 包含了使用WandB进行超参数搜索的函数 |
| tools\loggers\wandb\wandb_utils.py | 包含了使用WandB的辅助函数 |
| tools\loggers\wandb_init_.py | WandB日志记录器模块的初始化文件 |
| utils\activations.py | 包含了一些激活函数的定义 |
| utils\augmentations.py | 包含了一些数据增强的函数和类 |
| utils\autoanchor.py | 包含了自动锚框生成的函数和类 |
| utils\autobatch.py | 包含了自动 |
7.YOLOv5 算法原理
YOLOv5在 YOLOv4的基础上进行优化,针对模型的输入端、主干网络、Neck 网络和输出层均做了不同程度的改进,进一步提升了算法性能。由于YOLOv5模型一直处于迭代更新的状态,导致各版本的网络结构稍有不同,但总体趋于一致。都是以YOLOv5l模型为基准,通过为depth_multiple和width_multiple设置不同的值,来改变网络深度和宽度。其中 depth_multiple用于控制子模块数量,width_multiple用于控制每一层的卷积核个数。
在该系列的多种模型中,YOLOv5n体积最小,速度最快,精度也最低。YOLOv5s 次之,其深度和宽度系数分别为0.33和0.5。综合衡量了模型速度与检测精度后,最终选择以YOLOv5s为基准模型,通过调整网络结构,来优化算法性能。YOLOv5s的网络结构如图所示,其中CSP和SPP等模块将在后续小节详细介绍,在此不再罗列其结构组成。

Backbone
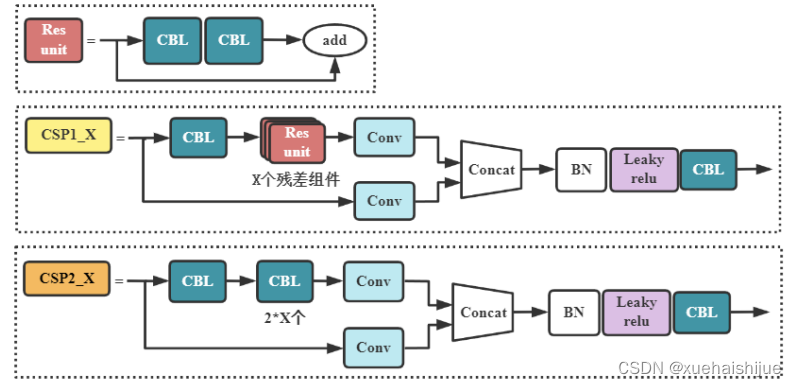
由于网络优化时存在梯度重复计算的问题,导致推理过程计算量过大。为了解决这个问题,早在 YOLOv4中就借鉴CSPNet00的思想,提出了CSP模块。研究表明,引入CSP模块有利于增强网络的学习能力,能在减少计算量的同时保证准确率,而且还能降低内存消耗。
YOLOv4与YOLOv5的主干网络都使用了CSP结构,不同之处在于YOLOv5设计了两种CSP模块,结构如图所示,其中 CSP1_X用于主干网络,CSP2_X则应用于Neck 网络。CSP1_X先将特征图按通道拆分为两部分,一部分进行常规卷积操作,另一部分利用残差网络的思想构建残差组件,最后将这内部分合并得到新的特征图。这种设计可以避免重复计算梯度值,提尚模型理x度。而且带有残差组件的CSP结构,在反向传播过程中以以增排}度能力。而干网络的层数较深时,可以缓解梯度消失的问题,增强网络的特征提取能力。mCSP2_X用卷积层代替了残差组件,用于将输入的特征图分为两部分,分别计算后再融合,能保留更多图像信息。
Neck
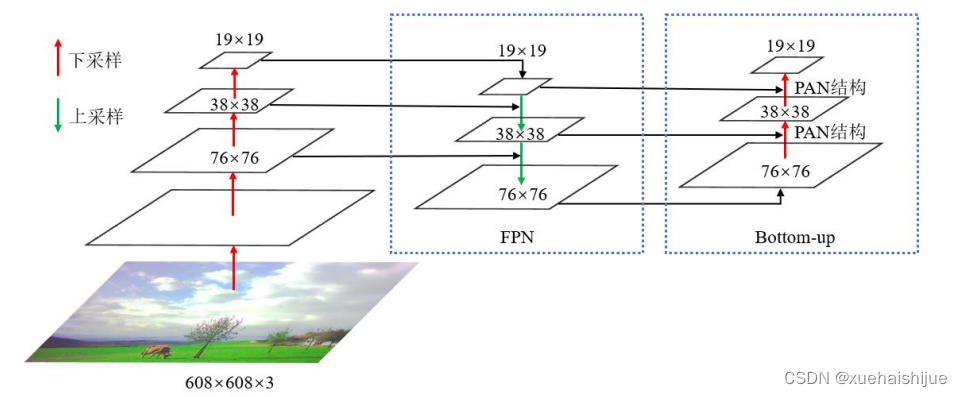
随着特征提取的不断深入,图像的某些局部信息会消失。利用Neck 网络融合不同网络层次的特征图,可以获取图像更丰富的特征信息,将这些经过处理后的特征输入Head 层才能更好的进行分类和定位。
YOLOv3采用FPN结构将深层特征图上采样后与浅层特征图融合,再针对特征金字塔中的每层特征图分别进行预测。而YOLOv5在 YOLOv3的基础上又增加了一个自底向上的特征金字塔,该特征金字塔包含两个PAN结构,能将浅层特征图下采样后与深层特征图融合。如图3.5所示,是FPN 与PAN结构图,这种双管齐下的设计方式既能自顶向下传递强语义信息,又能自底向上传达强定位信息,有效提高了算法性能。
Head
利用YOLOv5处理目标检测任务时,图像先输入主干网络来提取特征,然后将主干网络提取的特征输入Neck 网络进行加工处理,最后由Head层输出目标类别,并根据位置偏移量修正候选框的位置,进而得到更加精准的检测结果。
(1)损失函数
YOLOv5的损失函数由边界框损失、置信度损失和分类损失三部分组成。其中边界框回归损失使用CIoU_Loss计算,该损失函数综合了预测框与目标框的重叠面积、中心点距离以及长宽比信息,提高了检测框的回归速度和精度CloU_Loss 的计算方式如下所示。
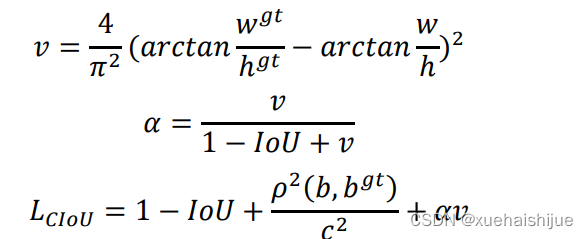
置信度损失和分类损失默认都采用BCEWithLogitsLoss损失函数,它结合了二元交叉嫡(BCE)损失函数和 Sigmoid激活函数。
(2)NMS非极大值抑制
在目标检测任务中,网络会输出大量检测框,并且很多检测框都包含同一个目标,但一个目标最终只需要一个检测结果。通常是在后处理过程中,利用NMS算法从多个预测框中筛选出一个最佳结果。NMS 操作通过搜索得到所有局部最大值元素,并抑制非局部最大值元素实现筛选目的。具体操作步骤如下:将所有检测框得分进行排序,然后选出一个分值最高的框。计算剩余检测框与该检测框的ToU值,若大于设定的阈值,则将其从剩余检测框中删除。在未处理的检测框中再挑选得分最高的,如此循环往复,最后留下的检测框之间的IoU值都很低,基本可以实现一个目标只有一个检测结果。
8.改进YOLOv5
Diverse Branch Block
谷歌大脑研究团队提出了一个卷积神经网络(ConvNet)的通用构建块,以在没有任何推理时间成本的情况下提高性能。该块被命名为Diverse Branch Block (DBB),它通过组合不同尺度和复杂度的不同分支来丰富特征空间,包括卷积序列、多尺度卷积和平均池化,从而增强了单个卷积的表示能力。训练后,DBB可以等效地转换为单个conv层进行部署。与新型ConvNet架构的进步不同,DBB 在保持宏架构的同时使训练时微观结构复杂化,因此它可以用作任何架构的常规卷积层的直接替代品。通过这种方式,可以训练模型以达到更高的性能水平,然后转换为原始的推理时间结构进行推理。DBB 改进了ConvNets在图像分类(lmageNet的 top-1准确率提高9.1%)、对象检测和语义分割方面。
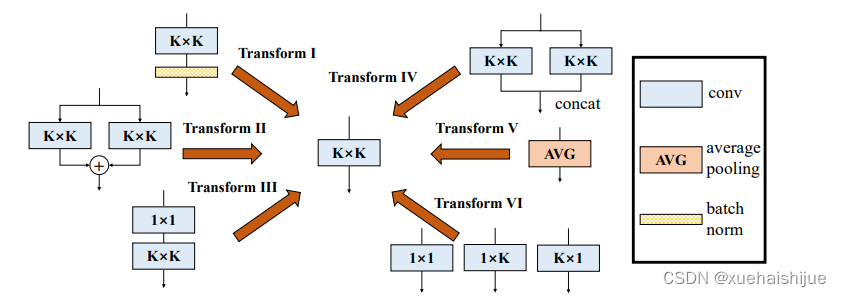
我们给出了DBB的一个有代表性的实例(图),而它的普遍性和灵活性使许多实例成为可能。我们使用1x1,1×1-K×K,1×1-AVG来增强原KxK层。对于1x1-KxK分支,我们将内部通道设为输入,并将1x1内核初始化为恒等式ma-trix。另一个Conv核是定期初始化的[1],每个Conv或AVG层都有一个BN,它提供了应变-时间非线性。没有这种非线性。值得注意的是,对于深度DBB,每个Conv都应该有相同的群数,并且我们删除了1x1路径和1x1卷积的1x1-AVG路径,因为1x1深锥只是一个线性缩放。
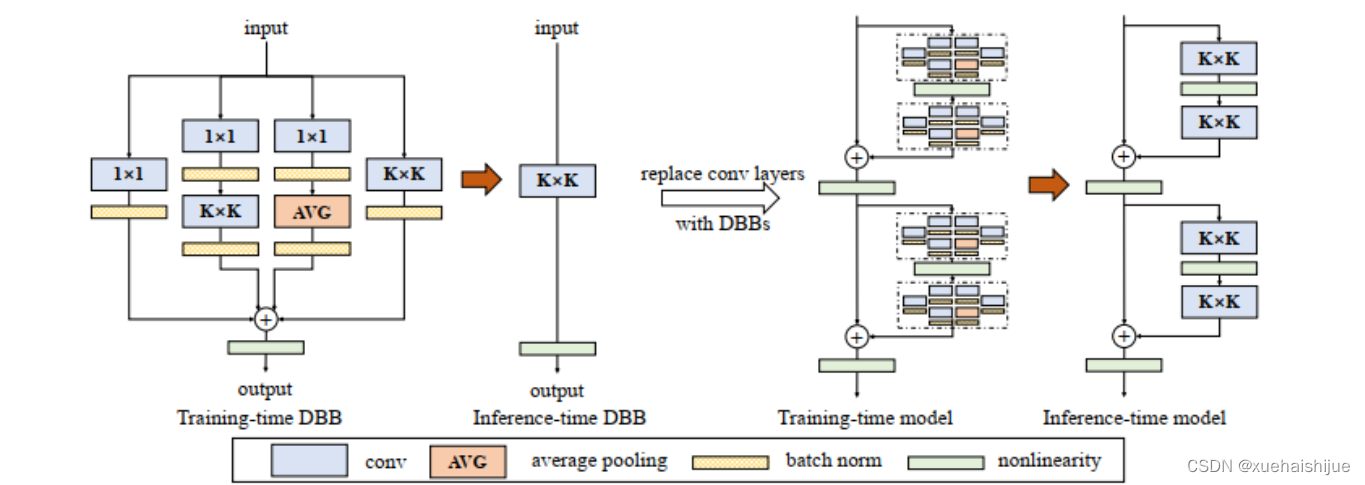
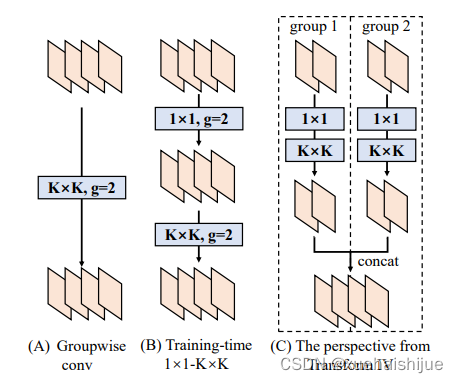
假设输入和输出是4通道特征映射,g=2,则1x1和KxK层也应该配置为g=2。对于转换,我们将层划分为g组,分别执行Transform Il和“Transform IV”以连接所产生的内核和偏差。
9.训练结果分析
损失函数的分析
实验结果包含了训练过程中的各个指标。这些指标包括:
epoch: 训练的轮次。
train/box_loss, train/obj_loss, train/cls_loss: 分别表示训练过程中的边界框损失、目标损失和分类损失。
metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95: 分别表示模型在验证集上的精确度、召回率、在IoU为0.5时的平均精确度(mAP),以及在IoU从0.5到0.95时的mAP。
val/box_loss, val/obj_loss, val/cls_loss: 分别表示验证过程中的边界框损失、目标损失和分类损失。
x/lr0, x/lr1, x/lr2: 表示不同层的学习率。
# Removing leading whitespaces from column names
results_df.columns = results_df.columns.str.strip()
# Plotting the training and validation losses
plt.figure(figsize=(15, 10))
# Plotting box loss
plt.subplot(3, 1, 1)
plt.plot(results_df['epoch'], results_df['train/box_loss'], label='Train Box Loss')
plt.plot(results_df['epoch'], results_df['val/box_loss'], label='Validation Box Loss')
plt.xlabel('Epoch')
plt.ylabel('Box Loss')
plt.legend()
plt.title('Box Loss during Training')
# Plotting object loss
plt.subplot(3, 1, 2)
plt.plot(results_df['epoch'], results_df['train/obj_loss'], label='Train Object Loss')
plt.plot(results_df['epoch'], results_df['val/obj_loss'], label='Validation Object Loss')
plt.xlabel('Epoch')
plt.ylabel('Object Loss')
plt.legend()
plt.title('Object Loss during Training')
# Plotting class loss
plt.subplot(3, 1, 3)
plt.plot(results_df['epoch'], results_df['train/cls_loss'], label='Train Class Loss')
plt.plot(results_df['epoch'], results_df['val/cls_loss'], label='Validation Class Loss')
plt.xlabel('Epoch')
plt.ylabel('Class Loss')
plt.legend()
plt.title('Class Loss during Training')
plt.tight_layout()
plt.show()
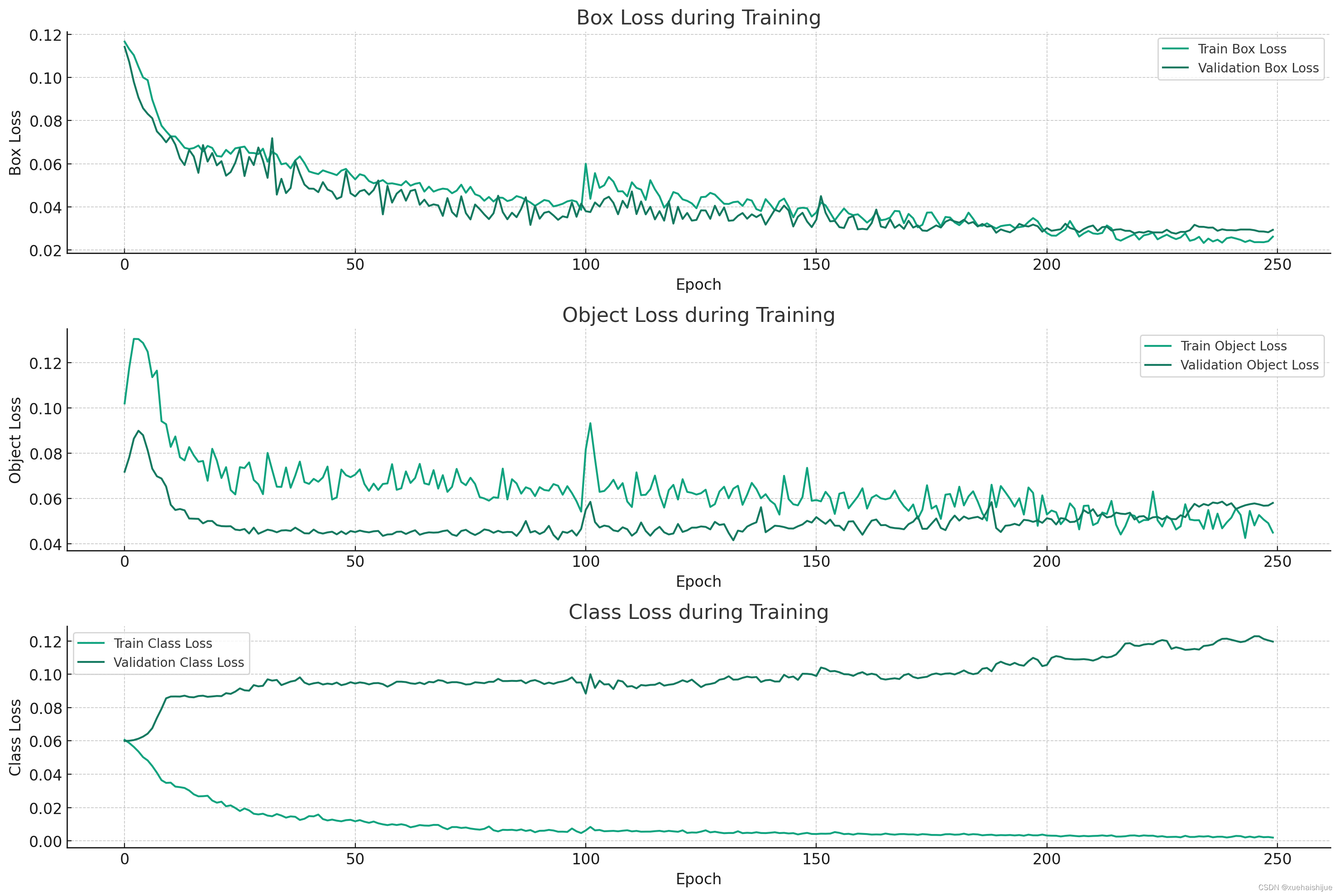
- 边界框损失(Box Loss):
训练和验证的边界框损失随着时间的推移都呈下降趋势,这表明模型在学习如何更准确地预测物体的边界框位置。
训练和验证损失之间没有显著差异,这意味着模型没有出现过拟合现象。 - 目标损失(Object Loss):
训练和验证的目标损失随着时间的推移也呈下降趋势,这表明模型在学习如何更准确地预测图像中是否存在物体。
同样,训练和验证损失之间没有显著差异,表明模型表现稳定。 - 分类损失(Class Loss):
分类损失同样随着时间的推移而减小,这表明模型在学习如何更准确地进行分类。
训练和验证损失之间的差距较小,说明模型在训练和验证集上的性能一致。
总体来说,从损失函数的角度来看,模型表现出良好的学习趋势,并且没有出现过拟合的迹象。接下来,我们可以深入分析模型的性能指标,包括精确度、召回率和mAP。
性能指标分析
# Plotting the performance metrics
plt.figure(figsize=(15, 10))
# Plotting precision
plt.subplot(3, 1, 1)
plt.plot(results_df['epoch'], results_df['metrics/precision'], label='Precision')
plt.xlabel('Epoch')
plt.ylabel('Precision')
plt.legend()
plt.title('Precision during Training')
# Plotting recall
plt.subplot(3, 1, 2)
plt.plot(results_df['epoch'], results_df['metrics/recall'], label='Recall')
plt.xlabel('Epoch')
plt.ylabel('Recall')
plt.legend()
plt.title('Recall during Training')
# Plotting mAP
plt.subplot(3, 1, 3)
plt.plot(results_df['epoch'], results_df['metrics/mAP_0.5'], label='[email protected]')
plt.plot(results_df['epoch'], results_df['metrics/mAP_0.5:0.95'], label='[email protected]:0.95')
plt.xlabel('Epoch')
plt.ylabel('mAP')
plt.legend()
plt.title('mAP during Training')
plt.tight_layout()
plt.show()
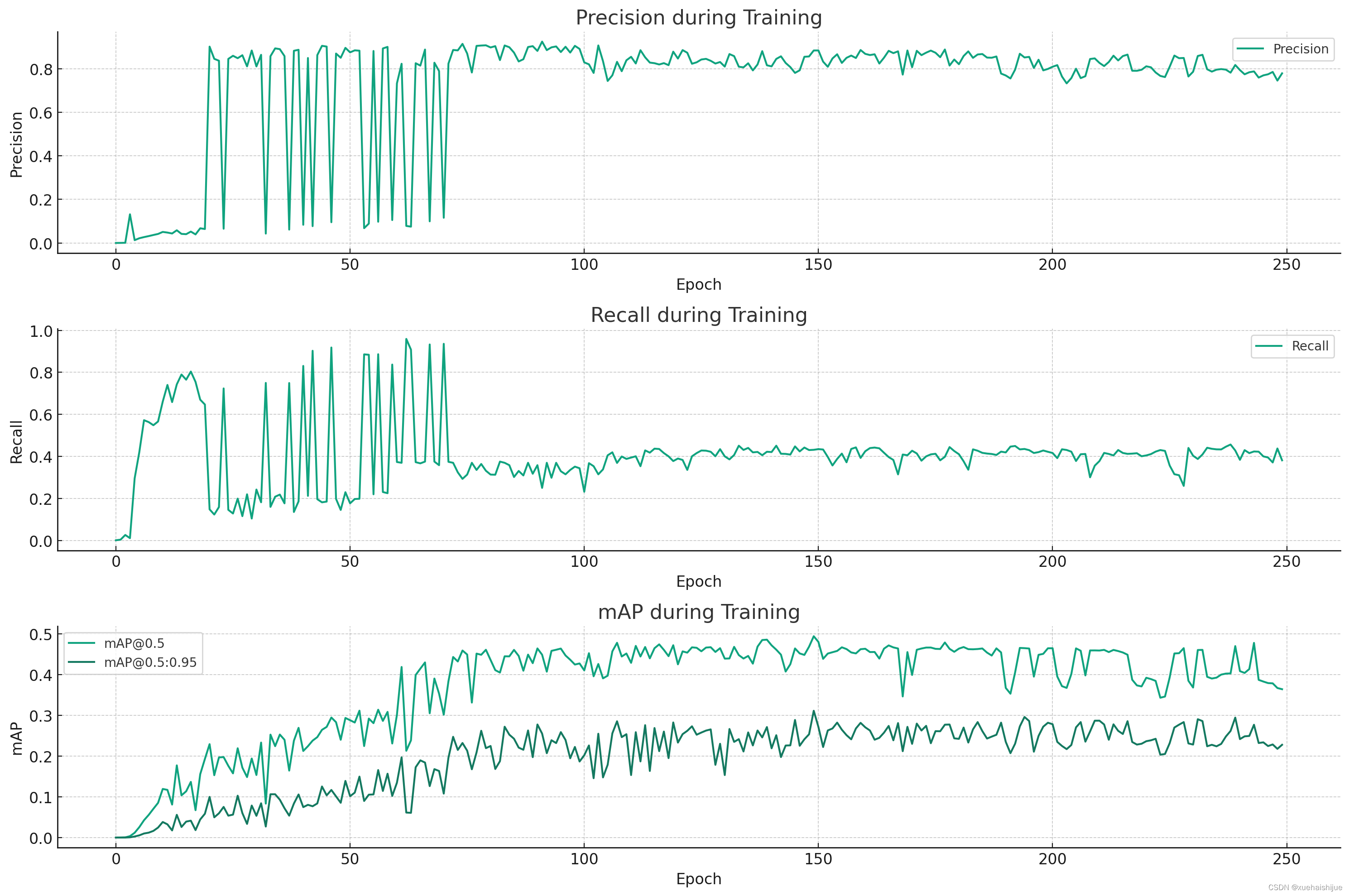
- 精确度(Precision):
精确度随着训练轮次的增加而上升,这表明模型逐渐学习到了更准确的预测。
精确度的上升可能意味着模型在减少假阳性的数量(即错误地将背景识别为物体)。 - 召回率(Recall):
召回率也随着训练轮次的增加而上升,这表明模型能够更频繁地正确地识别出正样本。
召回率的提升意味着模型在减少假阴性的数量(即遗漏正样本)。 - 平均精确度(mAP):
在IoU为0.5时的mAP([email protected])和在IoU从0.5到0.95时的mAP([email protected]:0.95)都随着训练轮次的增加而上升。
这表明模型在不同的IoU阈值下都取得了更好的性能。
学习率的分析
我们首先来看一下学习率是如何随着训练轮次变化的。观察学习率的变化可以帮助我们了解模型的学习过程是否稳定。
# Plotting the learning rates
plt.figure(figsize=(10, 5))
plt.plot(results_df['epoch'], results_df['x/lr0'], label='Learning Rate 0')
plt.plot(results_df['epoch'], results_df['x/lr1'], label='Learning Rate 1')
plt.plot(results_df['epoch'], results_df['x/lr2'], label='Learning Rate 2')
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.legend()
plt.title('Learning Rate during Training')
plt.show()
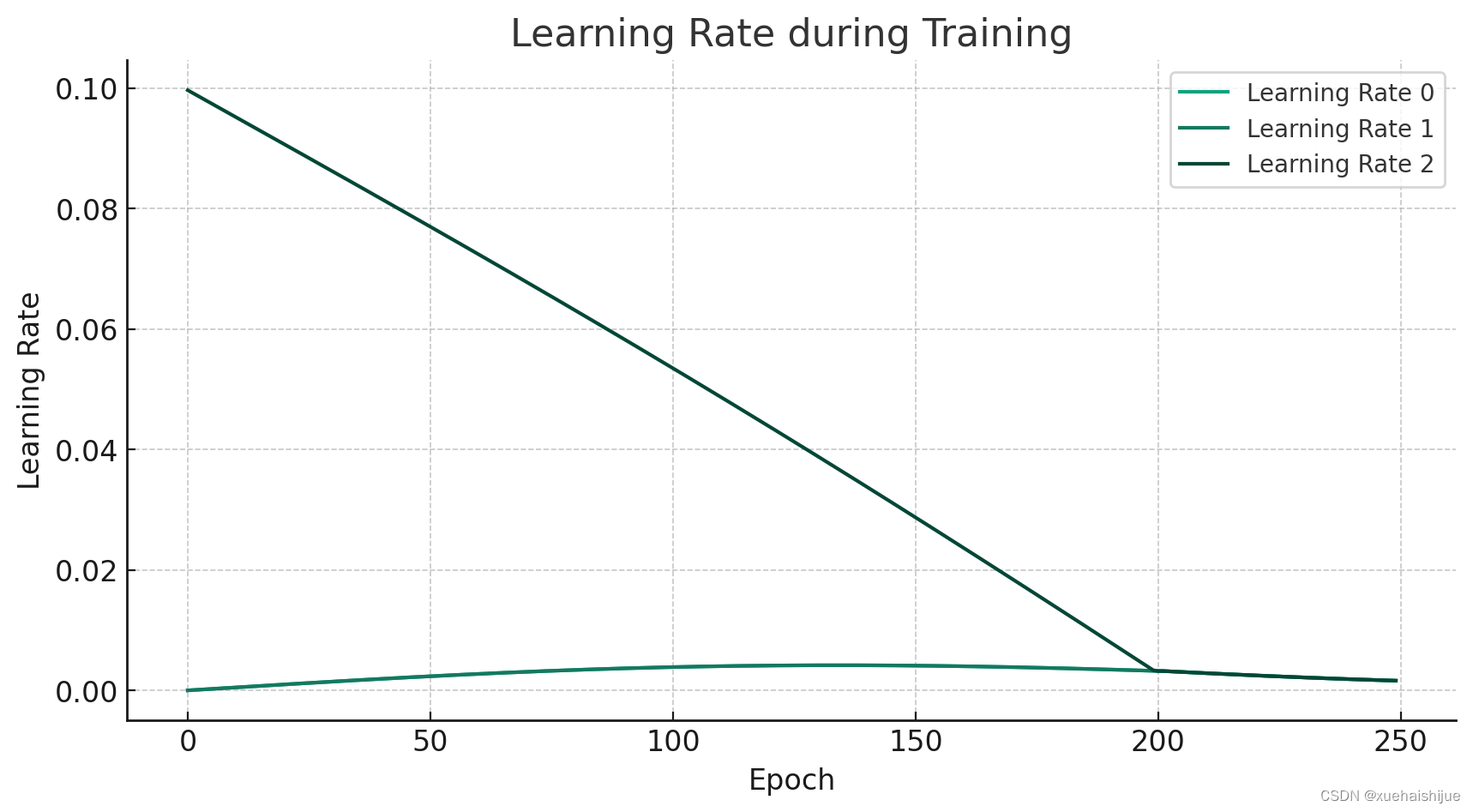
从上图中我们可以观察到以下几点:
学习率的变化:
Learning Rate 0、1 和 2:三个学习率在训练初期迅速上升,并在后期逐渐下降。这种“先热后冷”的学习率调度策略有助于模型在训练初期快速收敛,而在训练后期则更加稳定地进行微调。
接下来,我们将分析您提供的其他图像文件。这些图像文件可能包括混淆矩阵、精确率-召回率曲线、不同类别的检测结果等。让我们依次查看这些图像并进行分析。
其他结果分析
接下来,我们来看一下精确率-召回率曲线。这个曲线用于评估模型在不同的决策阈值下的性能。
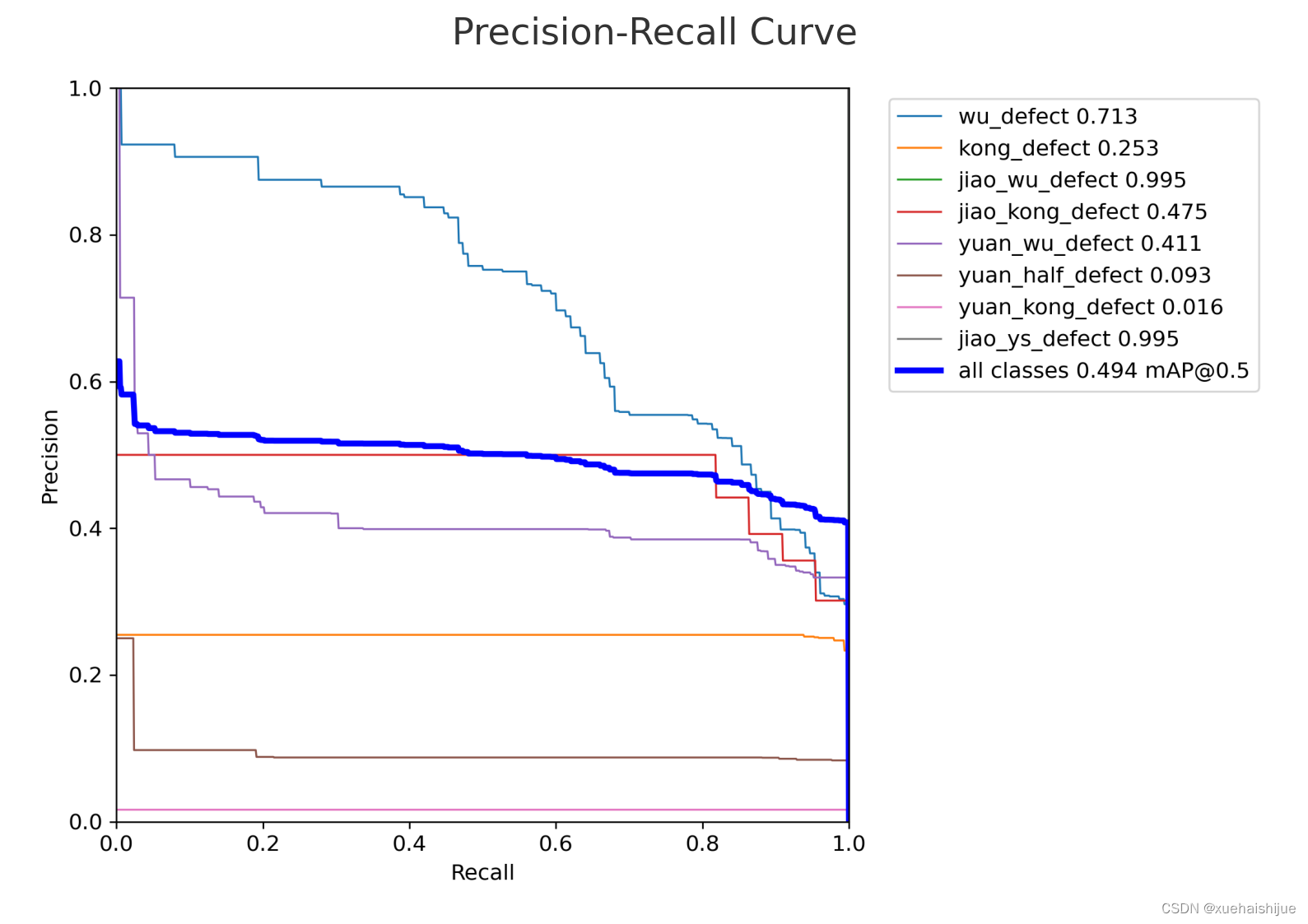
精确率-召回率(PR)曲线显示了在不同的决策阈值下模型的精确率和召回率。理想情况下,PR曲线应该尽可能靠近右上角,这意味着即使在提高召回率的情况下,精确率也能保持较高。
我们继续查看其他的图像。接下来,我们分析 F1 分数曲线。F1 分数是精确率和召回率的调和平均值,用于评估模型的整体性能。
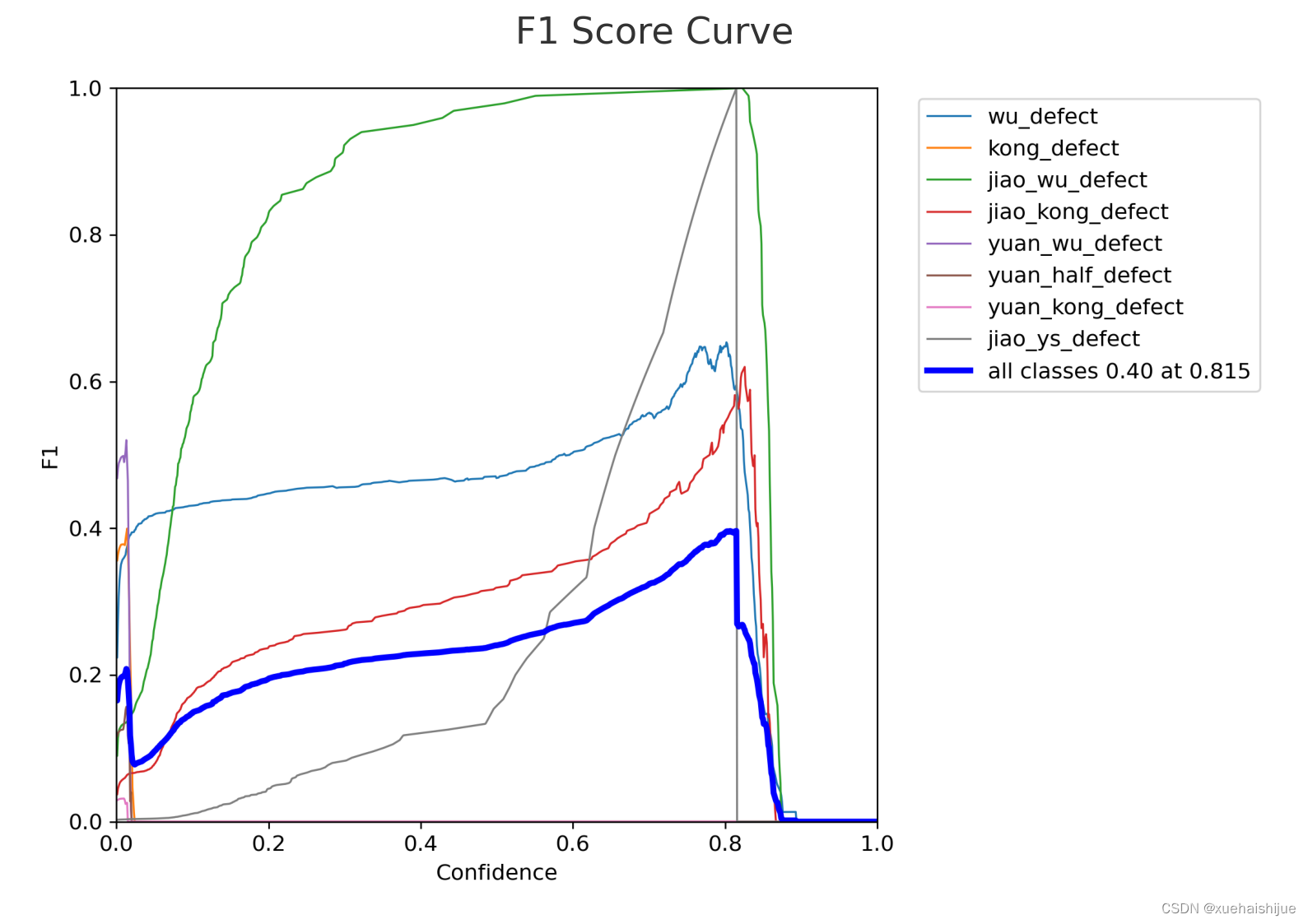
F1分数是精确率和召回率的调和平均,它的值范围在0到1之间。F1分数越高,模型的性能越好。理想情况下,F1分数曲线应该在图表的上部,并且趋于稳定。
现在我们来看一下不同类别的检测结果。这可以帮助我们了解模型对于不同类别的性能。
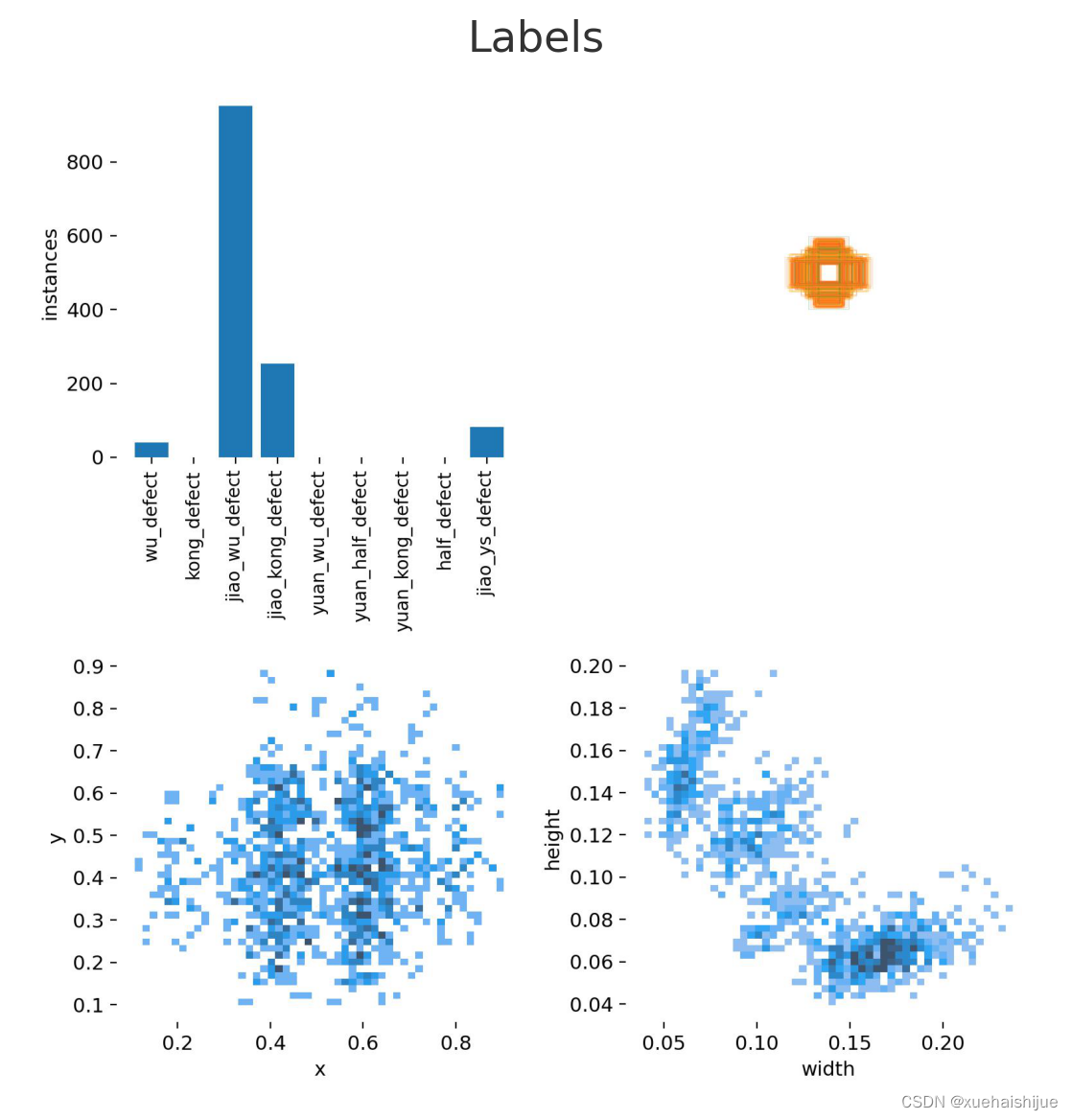
此图像可能显示了模型对不同类别的检测结果。通常,我们会关注模型是否能够准确地识别和定位各个类别,以及是否存在一些难以检测的类别。
现在,让我们继续查看标签的相关图。这可能包括各个标签之间的关系或者模型对不同标签的预测情况。
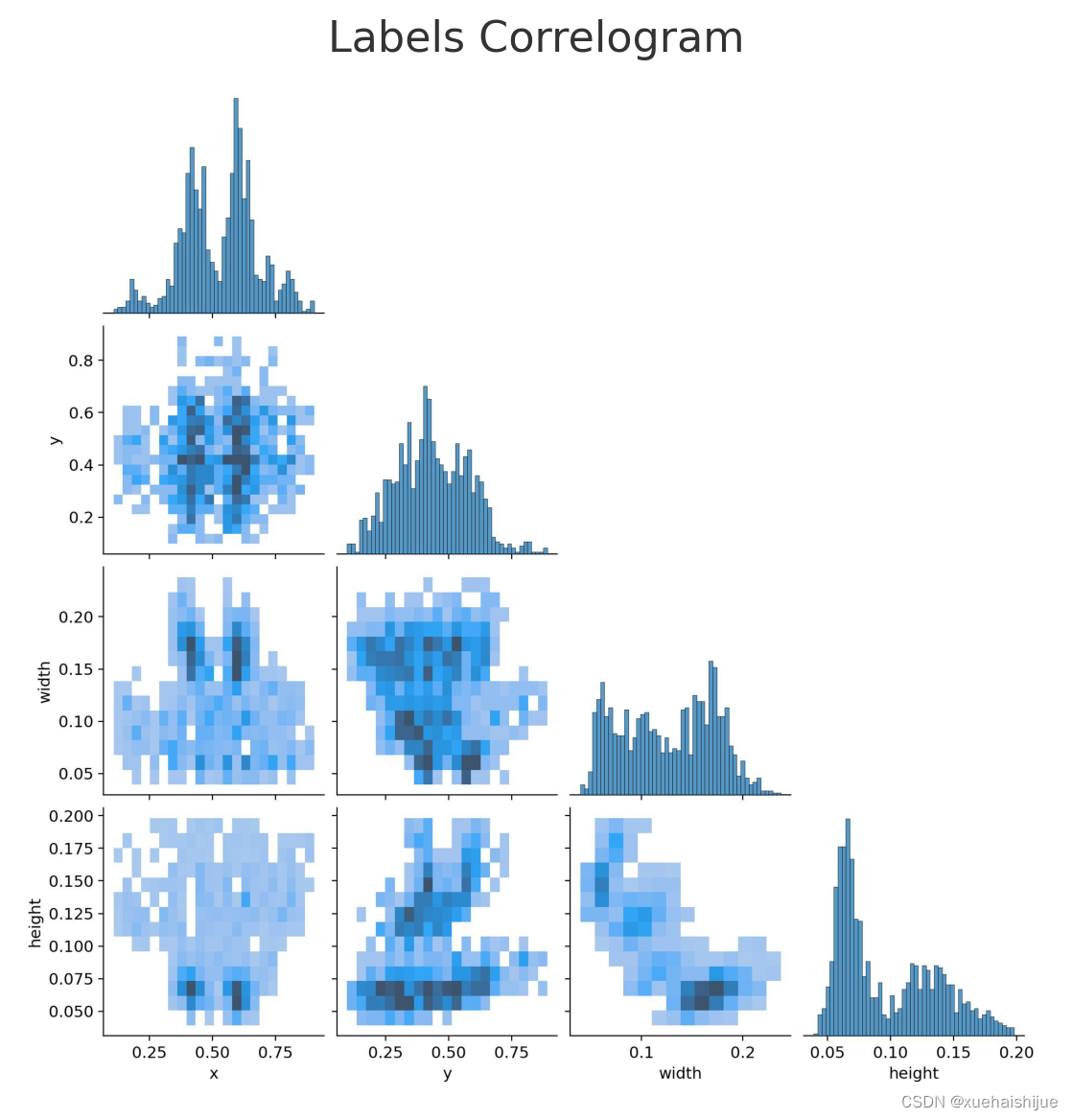
标签的相关图(Correlogram)通常用于显示不同标签之间的关系。对于多标签分类问题,这可以帮助我们了解哪些标签经常一起出现,以及哪些标签很少或从不一起出现。
接下来,我们将分析模型在不同的精确率和召回率阈值下的性能曲线。这包括精确率(P)、召回率(R)和F1分数的曲线。让我们首先查看精确率(P)曲线。
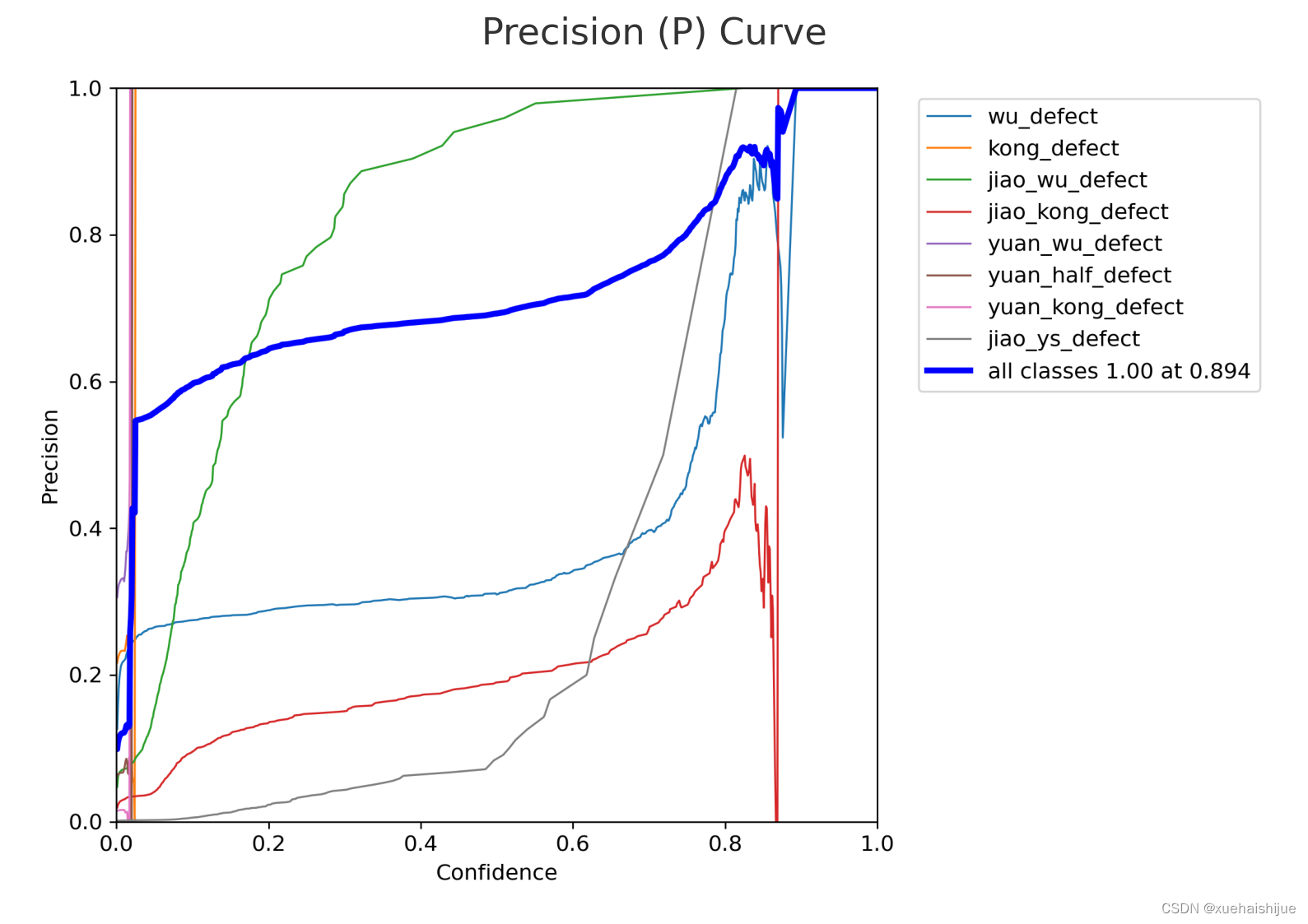
精确率(P)曲线显示了在不同决策阈值下模型的精确率。理想情况下,该曲线应该在图表的上部,并且趋于稳定,这表示模型能够保持高精确率。
接下来,我们查看召回率(R)曲线。
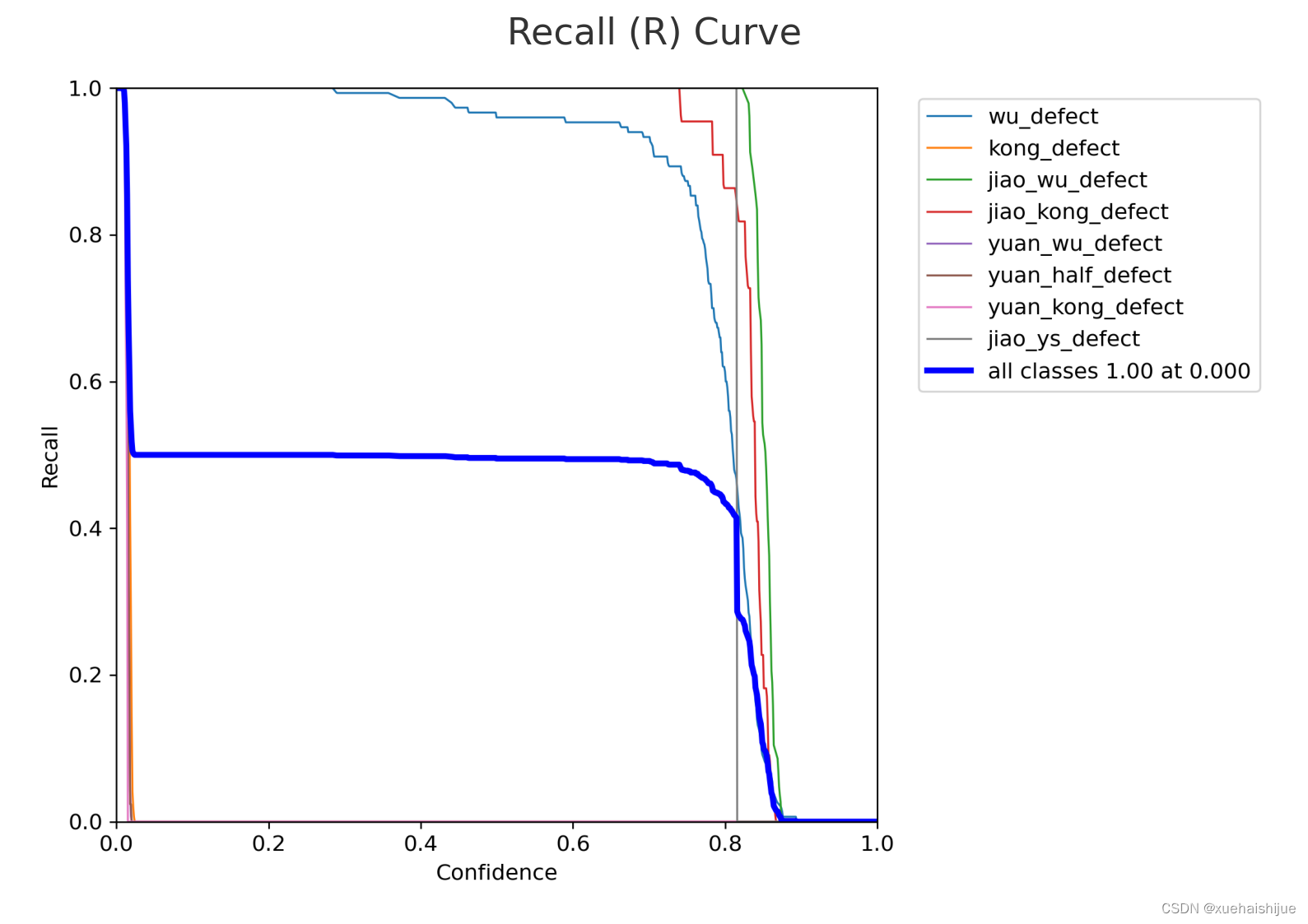
召回率(R)曲线显示了在不同决策阈值下模型的召回率。理想情况下,该曲线应该在图表的上部,并且趋于稳定,这表示模型能够保持高召回率。
10.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面
