文章版本为6.0及以上
论文:https://arxiv.org/pdf/2208.03641v1.pdf
github:SPD-Conv/YOLOv5-SPD at main · LabSAINT/SPD-Conv · GitHub
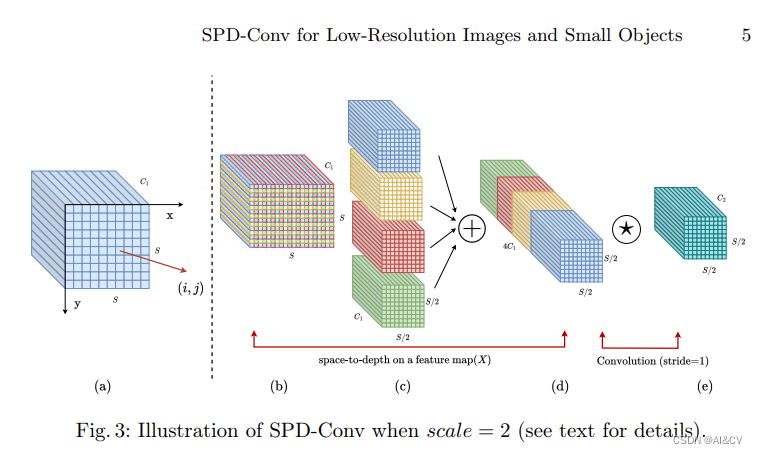
摘要:卷积神经网络(CNNs)在计算即使觉任务中如图像分类和目标检测等取得了显著的成功。然而,当图像分辨率较低或物体较小时,它们的性能会灾难性下降。这是由于现有CNN常见的设计体系结构中有缺陷,即使用卷积步长和/或池化层,这导致了细粒度信息的丢失和较低效的特征表示的学习。为此,我们提出了一个名为SPD-Conv的新的CNN构建块来代替每个卷积步长和每个池化层(因此完全消除了它们)。SPD-Conv由一个空间到深度(SPD)层和一个无卷积步长(Conv)层组成,可以应用于大多数CNN体系结构。我们从两个最具代表性的计算即使觉任务:目标检测和图像分类来解释这个新设计。然后,我们将SPD-Conv应用于YOLOv5和ResNet,创建了新的CNN架构,并通过经验证明,我们的方法明显优于最先进的深度学习模型,特别是在处理低分辨率图像和小物体等更困难的任务时。
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 1]], # 1
[-1,1,space_to_depth,[1]], # 2 -P2/4
[-1, 3, C3, [128]], # 3
[-1, 1, Conv, [256, 3, 1]], # 4
[-1,1,space_to_depth,[1]], # 5 -P3/8
[-1, 6, C3, [256]], # 6
[-1, 1, Conv, [512, 3, 1]], # 7-P4/16
[-1,1,space_to_depth,[1]], # 8 -P4/16
[-1, 9, C3, [512]], # 9
[-1, 1, Conv, [1024, 3, 1]], # 10-P5/32
[-1,1,space_to_depth,[1]], # 11 -P5/32
[-1, 3, C3, [1024]], # 12
[-1, 1, SPPF, [1024, 5]], # 13
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 14
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 15
[[-1, 9], 1, Concat, [1]], # 16 cat backbone P4
[-1, 3, C3, [512, False]], # 17
[-1, 1, Conv, [256, 1, 1]], # 18
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 19
[[-1, 6], 1, Concat, [1]], # 20 cat backbone P3
[-1, 3, C3, [256, False]], # 21 (P3/8-small)
[-1, 1, Conv, [256, 3, 1]], # 22
[-1,1,space_to_depth,[1]], # 23 -P2/4
[[-1, 18], 1, Concat, [1]], # 24 cat head P4
[-1, 3, C3, [512, False]], # 25 (P4/16-medium)
[-1, 1, Conv, [512, 3, 1]], # 26
[-1,1,space_to_depth,[1]], # 27 -P2/4
[[-1, 14], 1, Concat, [1]], # 28 cat head P5
[-1, 3, C3, [1024, False]], # 29 (P5/32-large)
[[21, 25, 29], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]common里加入
class space_to_depth(nn.Module):
# Changing the dimension of the Tensor
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)替换yolo.py 中以下代码
def parse_model(d, ch): # model_dict, input_channels(3)
# Parse a YOLOv5 model.yaml dictionary
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
LOGGER.info(f"{colorstr('activation:')} {act}") # print
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
with contextlib.suppress(NameError):
args[j] = eval(a) if isinstance(a, str) else a # eval strings
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
PatchMerging, PatchEmbed,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d,
C3x, SwinStage, CBAM}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
# TODO: channel, gw, gd
elif m in {Detect, Segment}:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is space_to_depth:
c2 = 4 * ch[f]
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]SPD适用于小目标检测涨点