1.研究背景与意义
随着科技的不断发展,人工智能技术在各个领域得到了广泛的应用。其中,图像识别技术在实际生活中的应用越来越广泛,其中之一就是火车票实时识别系统。火车票实时识别系统可以通过识别火车票上的信息,实现自动化的售票、验票等功能,提高了火车站的工作效率,方便了乘客的出行。
然而,火车票实时识别系统面临着一些挑战。首先,火车票的样式和格式多种多样,包括不同的颜色、字体、布局等。这使得传统的基于规则的方法很难适应各种不同的火车票样式。其次,火车票上的信息需要高精度的识别,以确保售票和验票的准确性。然而,由于火车票上的信息通常是印刷体,存在一定的模糊和变形,这增加了识别的难度。因此,开发一种高效准确的火车票实时识别系统对于提高火车站的工作效率和服务质量具有重要意义。
近年来,深度学习技术在图像识别领域取得了巨大的突破。其中,卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)是两种常用的深度学习模型。CNN可以有效地提取图像的特征,而RNN可以处理序列数据,适用于文本识别任务。因此,将CNN和RNN相结合的CRNN模型成为了文本识别领域的研究热点。
然而,传统的CRNN模型在火车票实时识别任务中存在一些问题。首先,传统的CRNN模型对于小尺寸的文本识别效果较差,而火车票上的信息通常较小。其次,传统的CRNN模型对于文本的上下文信息利用不充分,导致识别准确率不高。因此,有必要对CRNN模型进行改进,以提高火车票实时识别系统的性能。
基于以上背景和问题,本研究旨在基于ATT-ABCNet改进CRNN模型,实现高效准确的火车票实时识别系统。具体来说,本研究将引入注意力机制(Attention Mechanism)和自适应二维卷积(Adaptive 2D Convolution)来改进CRNN模型。注意力机制可以帮助模型更好地关注文本的重要部分,提高识别准确率。自适应二维卷积可以适应不同尺寸的文本,提高模型对小尺寸文本的识别效果。
本研究的意义主要体现在以下几个方面。首先,通过改进CRNN模型,可以提高火车票实时识别系统的准确性和鲁棒性,提高火车站的工作效率和服务质量。其次,本研究引入的注意力机制和自适应二维卷积可以为其他文本识别任务提供借鉴和参考,拓展了深度学习在文本识别领域的应用。最后,本研究对于推动火车站数字化转型,提高火车站信息化水平具有重要意义。
综上所述,基于ATT-ABCNet改进CRNN的火车票实时识别系统的研究具有重要的背景和意义,对于提高火车站的工作效率和服务质量具有积极的影响。
2.图片演示



3.视频演示
4.ABCNet 模型文本识别模型
ABCNet 模型框架
ABCNet模型的网络架构如图3.1所示,模型主要由检测模块、贝塞尔网络以及识别模块组成。检测模块利用ResNet-50作为主干网络,使用FPN融合特征图,并在此基础上预测文本框的位置信息。在回归坐标点时,输入进基于贝塞尔曲线检测算法的 anchor-free 网络,使用坐标点的参数信息对图像中的文本形成文本框。ABCNet模型的识别模块包括六个卷积层、BLSTM网络和CTC层,属于轻量级的识别分支,这样可以保证模型的识别速度。
ABCNet模型采用的贝塞尔曲线检测网络,使其代替传统长方形文本框,对任意形状的文本进行拟合,实现自适应的对图像中的文本进行检测。贝塞尔曲线的计算公式如下,主要由一系列支点b,和关于t的参数方程表示,详见公式4.1和 4.2所示。
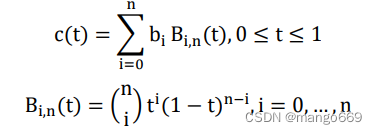
其中n为贝塞尔曲线的阶数,因为b的指数是从О开始,所以这里的支点个数为n+1。参数t由0至1进行演化,形成了一条完整的曲线。曲线上的任意一点T(t)的坐标,就是由曲线上全部支点坐标的加权平均值计算得到,T(t)的权重是上述公式中的B。B的方程在数学中叫做伯恩斯坦多项式(Bernstein polynomials)[51l,它也是t的函数,也由支点决定。
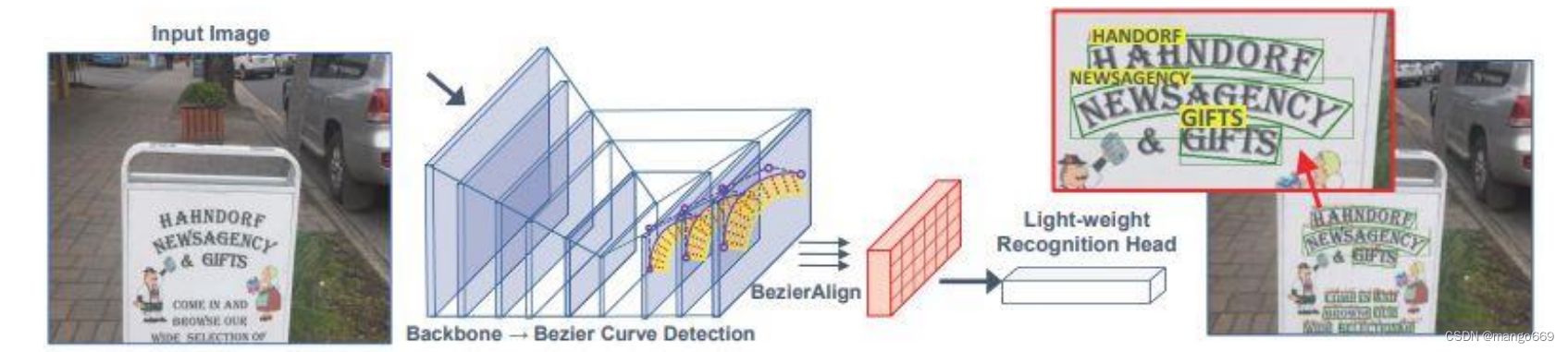
基于深度学习的自然场景文本识别算法改进框利用贝塞尔曲线回归,短边是直线段。ABCNet模型使用三阶贝塞尔曲线,每边有四个支点,上下两条曲线需要的总共八个支点坐标,就是检测网络预测的目标。由于采用贝塞尔曲线网络并不会增加太多的参数,因此后续在模型改进时保留了这一部分,在其检测模块和识别模块进行改进。
5.核心代码讲解
5.1 collect_env.py
根据代码,我将其封装为一个名为EnvironmentInfo的类,其中包含一个静态方法collect_env_info用于收集环境信息。
class EnvironmentInfo:
@staticmethod
def collect_env_info():
def collect_torch_env():
try:
import torch.__config__
return torch.__config__.show()
except ImportError:
# compatible with older versions of pytorch
from torch.utils.collect_env import get_pretty_env_info
return get_pretty_env_info()
def get_env_module():
var_name = "DETECTRON2_ENV_MODULE"
return var_name, os.environ.get(var_name, "<not set>")
def detect_compute_compatibility(CUDA_HOME, so_file):
try:
cuobjdump = os.path.join(CUDA_HOME, "bin", "cuobjdump")
if os.path.isfile(cuobjdump):
output = subprocess.check_output(
"'{}' --list-elf '{}'".format(cuobjdump, so_file), shell=True
)
output = output.decode("utf-8").strip().split("\n")
sm = []
for line in output:
line = re.findall(r"\.sm_[0-9]*\.", line)[0]
sm.append(line.strip("."))
sm = sorted(set(sm))
return ", ".join(sm)
else:
return so_file + "; cannot find cuobjdump"
except Exception:
# unhandled failure
return so_file
has_gpu = torch.cuda.is_available() # true for both CUDA & ROCM
torch_version = torch.__version__
# NOTE: the use of CUDA_HOME and ROCM_HOME requires the CUDA/ROCM build deps, though in
# theory detectron2 should be made runnable with only the corresponding runtimes
from torch.utils.cpp_extension import CUDA_HOME
has_rocm = False
if tuple(map(int, torch_version.split(".")[:2])) >= (1, 5):
from torch.utils.cpp_extension import ROCM_HOME
if (getattr(torch.version, "hip", None) is not None) and (ROCM_HOME is not None):
has_rocm = True
has_cuda = has_gpu and (not has_rocm)
data = []
data.append(("sys.platform", sys.platform))
data.append(("Python", sys.version.replace("\n", "")))
data.append(("numpy", np.__version__))
try:
import detectron2 # noqa
data.append(
("detectron2", detectron2.__version__ + " @" + os.path.dirname(detectron2.__file__))
)
except ImportError:
data.append(("detectron2", "failed to import"))
try:
from detectron2 import _C
except ImportError:
data.append(("detectron2._C", "failed to import"))
# print system compilers when extension fails to build
if sys.platform != "win32": # don't know what to do for windows
try:
# this is how torch/utils/cpp_extensions.py choose compiler
cxx = os.environ.get("CXX", "c++")
cxx = subprocess.check_output("'{}' --version".format(cxx), shell=True)
cxx = cxx.decode("utf-8").strip().split("\n")[0]
except subprocess.SubprocessError:
cxx = "Not found"
data.append(("Compiler", cxx))
if has_cuda and CUDA_HOME is not None:
try:
nvcc = os.path.join(CUDA_HOME, "bin", "nvcc")
nvcc = subprocess.check_output("'{}' -V".format(nvcc), shell=True)
nvcc = nvcc.decode("utf-8").strip().split("\n")[-1]
except subprocess.SubprocessError:
nvcc = "Not found"
data.append(("CUDA compiler", nvcc))
else:
# print compilers that are used to build extension
data.append(("Compiler", _C.get_compiler_version()))
data.append(("CUDA compiler", _C.get_cuda_version())) # cuda or hip
if has_cuda:
data.append(
("detectron2 arch flags", detect_compute_compatibility(CUDA_HOME, _C.__file__))
)
data.append(get_env_module())
data.append(("PyTorch", torch_version + " @" + os.path.dirname(torch.__file__)))
data.append(("PyTorch debug build", torch.version.debug))
data.append(("GPU available", has_gpu))
if has_gpu:
devices = defaultdict(list)
for k in range(torch.cuda.device_count()):
devices[torch.cuda.get_device_name(k)].append(str(k))
for name, devids in devices.items():
data.append(("GPU " + ",".join(devids), name))
if has_rocm:
data.append(("ROCM_HOME", str(ROCM_HOME)))
else:
data.append(("CUDA_HOME", str(CUDA_HOME)))
cuda_arch_list = os.environ.get("TORCH_CUDA_ARCH_LIST", None)
if cuda_arch_list:
data.append(("TORCH_CUDA_ARCH_LIST", cuda_arch_list))
data.append(("Pillow", PIL.__version__))
try:
data.append(
(
"torchvision",
str(torchvision.__version__) + " @" + os.path.dirname(torchvision.__file__),
)
)
if has_cuda:
try:
torchvision_C = importlib.util.find_spec("torchvision._C").origin
msg = detect_compute_compatibility(CUDA_HOME, torchvision_C)
data.append(("torchvision arch flags", msg))
except ImportError:
data.append(("torchvision._C", "failed to find"))
except AttributeError:
data.append(("torchvision", "unknown"))
try:
import fvcore
data.append(("fvcore", fvcore.__version__))
except ImportError:
pass
try:
import cv2
data.append(("cv2", cv2.__version__))
except ImportError:
pass
env_str = tabulate(data) + "\n"
env_str += collect_torch_env()
return env_str
if __name__ == "__main__":
try:
import detectron2 # noqa
except ImportError:
print(EnvironmentInfo.collect_env_info())
else:
from detectron2.utils.collect_env import collect_env_info
print(collect_env_info())
该程序文件名为collect_env.py,主要功能是收集环境信息。程序首先导入了一些必要的库,包括importlib、numpy、os、re、subprocess、sys、collections、PIL、torch、torchvision和tabulate。然后定义了一个collect_torch_env函数,用于收集torch环境信息。接下来定义了一个get_env_module函数,用于获取环境变量DETECTRON2_ENV_MODULE的值。然后定义了一个detect_compute_compatibility函数,用于检测CUDA环境的兼容性。最后定义了一个collect_env_info函数,用于收集整个环境信息。在该函数中,首先判断是否有GPU可用,并获取torch的版本号。然后收集一些基本的环境信息,如sys.platform、Python版本和numpy版本。接着尝试导入detectron2库,并获取其版本号和路径。如果导入失败,则打印收集到的环境信息。如果导入成功,则继续导入detectron2.utils.collect_env模块,并打印收集到的环境信息。最后,在程序的主函数中,首先尝试导入detectron2库,如果导入失败,则打印收集到的环境信息。如果导入成功,则调用collect_env_info函数,并打印收集到的环境信息。
5.2 demo.py
class OCRProcessor:
def __init__(self):
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
def single_pic_proc(self, image_file):
image = np.array(Image.open(image_file).convert('RGB'))
result, image_framed = ocr(image)
return result, image_framed
def process_images(self, image_dir, result_dir):
image_files = glob(os.path.join(image_dir, '*.*'))
for image_file in sorted(image_files):
t = time.time()
print(image_file)
result, image_framed = self.single_pic_proc(image_file)
output_file = os.path.join(result_dir, image_file.split('/')[-1])
print(output_file)
txt_file = os.path.join(result_dir, image_file.split('/')[-1].split('.')[0]+'.txt')
print(txt_file)
txt_f = open(txt_file, 'w')
Image.fromarray(image_framed).save(output_file)
print("Mission complete, it took {:.3f}s".format(time.time() - t))
print("\nRecognition Result:\n")
for key in result:
print(result[key][1])
txt_f.write(result[key][1]+'\n')
txt_f.close()
这个程序文件名为demo.py,它的功能是对指定文件夹中的图片进行OCR识别,并将识别结果保存到指定文件夹中。
程序首先导入了所需的库,包括os、ocr、time、shutil、numpy和PIL。然后设置了环境变量。
接下来定义了一个函数single_pic_proc,用于处理单张图片。该函数首先将图片转换为RGB格式的数组,然后调用OCR函数进行识别,返回识别结果和带有识别框的图片。
在主程序中,首先使用glob函数获取指定文件夹中的所有图片文件路径,并指定了结果保存的文件夹路径。然后遍历每个图片文件,对每个文件调用single_pic_proc函数进行处理。
处理过程中,程序会打印当前处理的图片文件路径,并计算处理时间。然后将带有识别框的图片保存到结果文件夹中,并根据图片文件名生成对应的txt文件路径。
接下来,程序会打印识别结果,并将结果写入到对应的txt文件中。
最后,程序会关闭txt文件,打印处理完成的信息,并继续处理下一张图片。
6.系统整体结构
以下是每个文件的功能概述:
| 文件路径 | 功能概述 |
|---|---|
| collect_env.py | 收集环境信息 |
| demo.py | 对指定文件夹中的图片进行OCR识别 |
| ocr.py | 进行OCR(光学字符识别) |
| pytorch_on_gpu.py | 在GPU上运行PyTorch代码 |
| setup.py | 安装AdelaiDet软件包 |
| test_one.py | 处理单张图片进行OCR识别 |
| test_pth.py | 对模型进行测试 |
| ui.py | 用户界面相关功能 |
| adet_init_.py | AdelaiDet软件包的初始化文件 |
| adet\checkpoint\adet_checkpoint.py | 检查点相关功能 |
| adet\checkpoint_init_.py | 检查点相关功能 |
| adet\config\config.py | 配置文件相关功能 |
| adet\config\defaults.py | 默认配置文件 |
| adet\config_init_.py | 配置文件相关功能 |
| adet\data\augmentation.py | 数据增强相关功能 |
| adet\data\builtin.py | 内置数据集相关功能 |
| adet\data\dataset_mapper.py | 数据集映射器 |
| adet\data\detection_utils.py | 检测工具函数 |
| adet\data_init_.py | 数据相关功能 |
| adet\data\datasets\text.py | 文本数据集相关功能 |
| adet\evaluation\rrc_evaluation_funcs.py | RRC评估函数 |
| adet\evaluation\text_evaluation.py | 文本评估功能 |
| adet\evaluation\text_eval_script.py | 文本评估脚本 |
| adet\evaluation\text_eval_script2.py | 文本评估脚本 |
| adet\evaluation_init_.py | 评估相关功能 |
| adet\layers\bezier_align.py | Bezier对齐层 |
| adet\layers\conv_with_kaiming_uniform.py | 带有Kaiming均匀初始化的卷积层 |
7.ABCNet 模型改进思路
ABCNet模型在Total-Text数据集上识别效果部分可视化结果如图所示,图中包含部分错检、漏检的示例。根据ABCNet模型论文的局限分析以及本文复现ABCNet模型测试其在数据集上的检测和识别效果时发现,ABCNet模型存在仍然有两点局限:
(1)对于复杂背景下的文本,在检测时会出现漏检、错检,影响检测准确率,同时导致文本识别准确率下降;
(2)对于弯曲变形的文本等识别难度大的文本区域,难以准确识别出来。

本文认为原因主要有以下几点:
(1)ABCNet模型特征提取网络生成训练标签时受到图像背景影响,使得特征图的聚焦能力不强,同时模型原本的BLSTM 网络对于长序列的识别,会产生性能问题,因此对于复杂背景下的文本易出现漏检、错检。
(2)模型在特征融合过程中采用了传统特征金字塔的策略,但是效果不佳,容易导致特征丢失文本语义特征和边界信息。
(3)对于部分弯曲变形的文本,模型前段的检测算法形成的文本检测框没有紧密包围文本,将会影响后续识别网络效果。
针对上述原因,对ABCNet模型提出如下改进思路:
(1) 针对复杂背景下文本,在模型的检测和识别模块中分别引入注意力机制,减轻了自然场景文本复杂背景干扰,缓解原模型在识别含有长文本的自然场景图片时性能较差的问题。
(2) 在特征金字塔结构基础上增加特征增强模块,保留底层特征信息和上下文语义信息,提升网络检测效果。
(3) 在文本识别网络之前增加空间矫正模块,能够矫正变形的文本,有利于提升后续识别性能。
8.ATT-ABCNet 模型
谷歌大脑提出的ATT-ABCNet模型整体架构如图所示。其主要由文本检测模块和文本识别模块两部分组成。检测模块利用ResNet-50作为主干网络,并在此基础上引入注意力机制,使用FPN融合特征图,并在此基础上预测文本框的位置信息。在回归坐标点时,将特征图输入基于贝塞尔曲线检测算法的anchor-free网络,使用坐标点的参数信息对图像中的文本构建文本框。文本识别模块分为Encoder和 Decoder。Encoder主要功能是对输入提取特征,ATT-ABCNet模型的该部分使用卷积层作为特征提取层,再送入BLSTM网络编码特征序列,得到包含文字特征的编码序列。Decoder使用结合注意力机制的LSTM网络结构,生成预测标签。
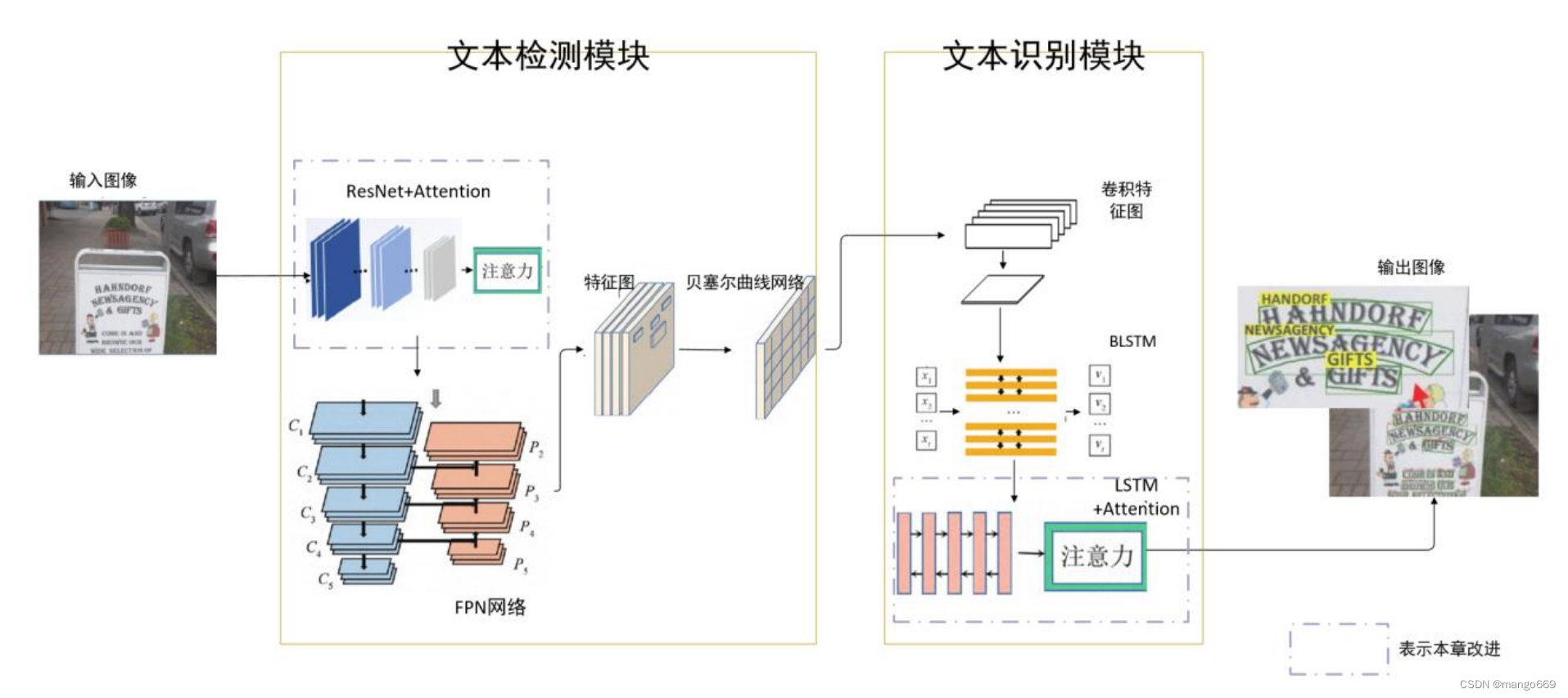
ATT-ABCNet模型在检测模块引入注意力机制,使得网络能提高对小尺度文本的关注度,关注重要特征并抑制不重要的特征,并有效定位密集型文本,更多的文本语义特征和边界信息得到保留,减少检测复杂背景下的文本时出现漏检的情况;在识别模块采用结合注意力机制的网络,注意力机制能够算出特征的对齐评分来权衡其贡献
基于深度学习的自然场景文本识别算法改进度,并根据不同特征的权重生成概率分布,递归单元根据权重值组合和配置网络中的序列。对序列重构,使输出预测的序列与实际标签更大程度上接近,从而纠正了在检测复杂背景中的文本时容易出现的文本错检,并缓解了BLSTM网络在长序列文本识别任务中的性能下降。
文本检测模块
ATT-ABCNet模型在文本检测模块的主干网络,采用ResNet 与注意力机制结合的结构,分别引入通道注意力SENet以及混合注意力CBAM两种注意力模块,融入ResNet网络形成新的网络结构,通过分配不同的特征以权重,可以区分不同特征的重要性。在该模块对比SENet和 CBAM注意力对残差网络的增益效果。再通过特征金字塔网络进行自顶向下融合特征,将得到的特征图送入贝塞尔曲线检测网络模块,通
过anchor-free网络回归坐标点,使用坐标点的参数信息对图像中的文本形成文本框,得到输出结果。
ATT-ABCNet模型的文本检测模块去除了区域选择、非文本区域过滤、文本后处理等中间环节,从而实现文本位置的自动定位。从而缩短了计算时间,并能处理词级和行级别的文本。引入注意力机制模块,使得改进后的网络关注重要特征,并抑制不重要的特征,能有效地从不同规模的文本中抽取特征,从而降低背景信息的干扰。改善了检测背景复杂图像文本时常常在生成训练标签时受到图像背景影响,使得特征图的聚焦能力不强,导致学习的文本区域特征不完整,造成文本漏检的问题。
文本识别模块
ATT-ABCNet模型的文本识别模块将原模型循环层的BLSTM 网络替换为LSTM与注意力机制结合的网络结构,卷积层保留原本的CNN 以及 BLSTM 网络。文本识别模块由卷积层,BLSTM层和结合注意力机制的LSTM层组成。卷积层主要用于提取特征,并通过BLSTM层将特征向量编码为特征序列,注意力机制利用BLSTM 网络的输出计算权重和文本向量,再由LSTM和注意力层对输入的特征序列进行解码,注意力机制的作用是计算特征的贡献度,并根据不同特征的权重生成概率分布,递归单元根据权重值组合和配置网络中的序列。对序列重构,使输出预测的序列与实际标签更大程度上接近,从而生成较为精准的预测标签。
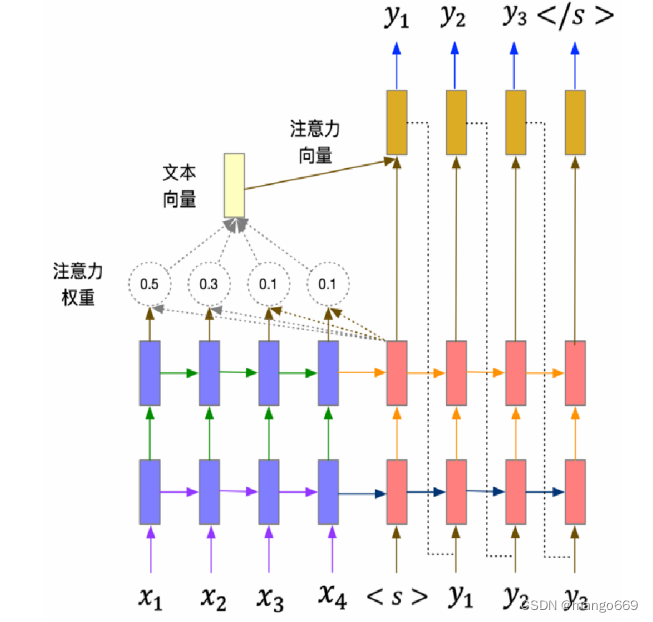
为了提升ATT-ABCNet模型文本识别模块的性能,AAAI选择了引入常与神经网络相结合使用的 Luong注意力和 Bahdanau注意力机制。在此基础上,对比了两种注意力对LSTM网络的增益效果,选择更适用于文本序列识别的注意力机制用于构建ATT-ABCNet模型。注意力机制与文本识别模块LSTM网络的结合,改善了复杂背景下的文本容易在检测时产生的错检问题,同时对循环神经网络在识别长序列文本会出现性能下降的问题也有所缓解,提升了场景文本识别的准确率。
9.训练结果分析
算法性能指标解释
精确率(Precision):此指标衡量的是算法检测到的正确文本数量占算法认为是文本的总数量的比例。高精确率意味着较少的误报。
召回率(Recall):召回率衡量的是算法正确检测到的文本数量占实际文本总数的比例。高召回率表明算法能够捕捉到更多的真实文本。
F测量(F-measure):F分数是精确率和召回率的调和平均,是评估算法整体性能的重要指标,平衡了精确率和召回率的权衡。
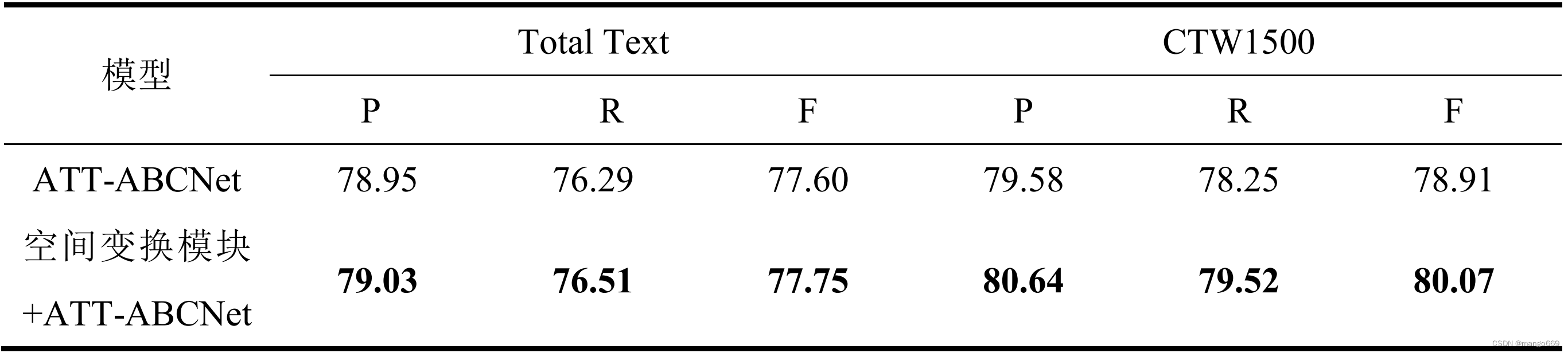
ATT-ABCNet算法与增强版对比
基础版ATT-ABCNet性能
在Total Text数据集上,该算法展示出较为平衡的精确率和召回率,但仍有提升空间。
在CTW1500数据集上,尽管精确率略高,但召回率有所下降,这可能意味着算法对于长文本行的检测能力不如对于多样形态文本的检测。
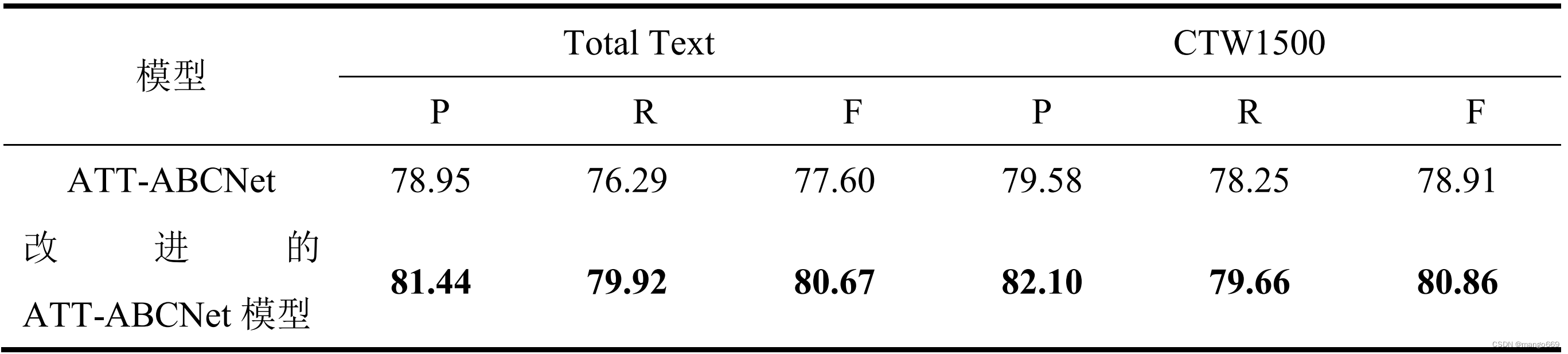
增强版ATT-ABCNet性能
增强版在Total Text数据集上的精确率和召回率都有明显提升,说明算法对于多样形态文本的检测能力增强。
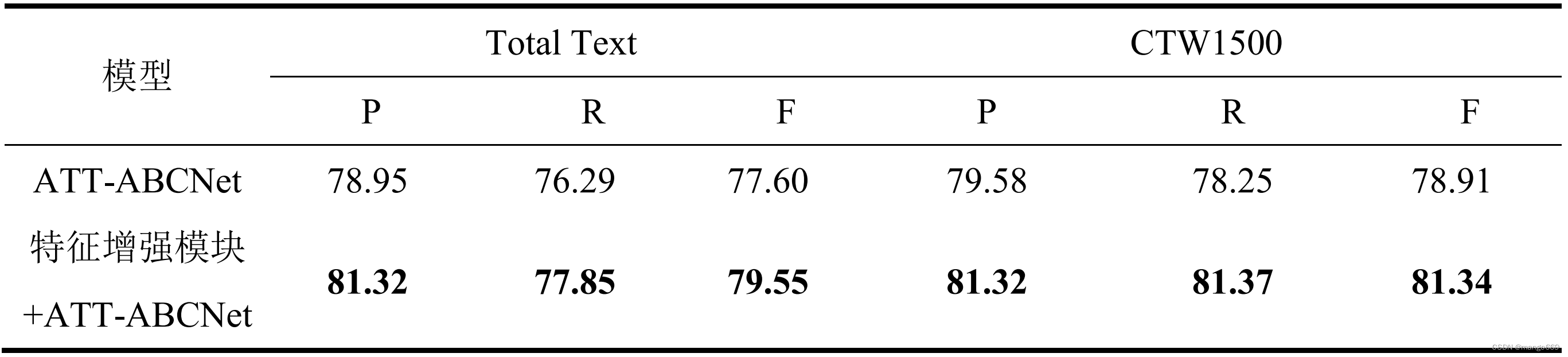
在CTW1500数据集上,增强版同样表现出更好的精确率和召回率,尤其是在精确率上的提升更为突出,这表明算法在减少误报方面取得了进步。
性能提升的分析
增强版算法可能引入了新的特征提取机制,如改进的卷积神经网络架构,更有效的特征融合技术或是更先进的后处理步骤。
算法可能通过更复杂的数据预处理和增强,能更好地处理文本的变形和遮挡问题。
增强版算法也可能使用了更深的网络结构或更复杂的优化策略,例如注意力机制的改进,来更好地聚焦于文本特征。
性能提升表明了持续算法创新的重要性。通过持续的迭代和改进,算法能够更好地适应复杂多变的现实世界文本检测任务。
同时,精确率和召回率之间的平衡仍然是场景文本检测算法设计中的一个关键挑战,未来的工作可以考虑如何在保持高精确率的同时进一步提高召回率。
增强版ATT-ABCNet在Total Text和CTW1500数据集上展示了较原版算法更为出色的性能,特别是在精确率上的提升更为显著。这一结果不仅展示了算法改进的潜力,也为文本检测领域的研究提供了宝贵的参考。尽管如此,算法开发者需要持续探索新的方法,以应对更多样化的文本场景和挑战。
10.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面
