
引用
C++中的引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
语法和使用场景
基本语法
语法:类型& 引用变量名(对象名) = 引用实体;
具体使用如下面的代码:
using namespace std;
#include<stdio.h>
void Test()
{
int a = 10;
int& ra = a;// <====定义引用类型
printf("%p\n", &a);
printf("%p\n", &ra);
}
int main()
{
Test();
return 0;
}
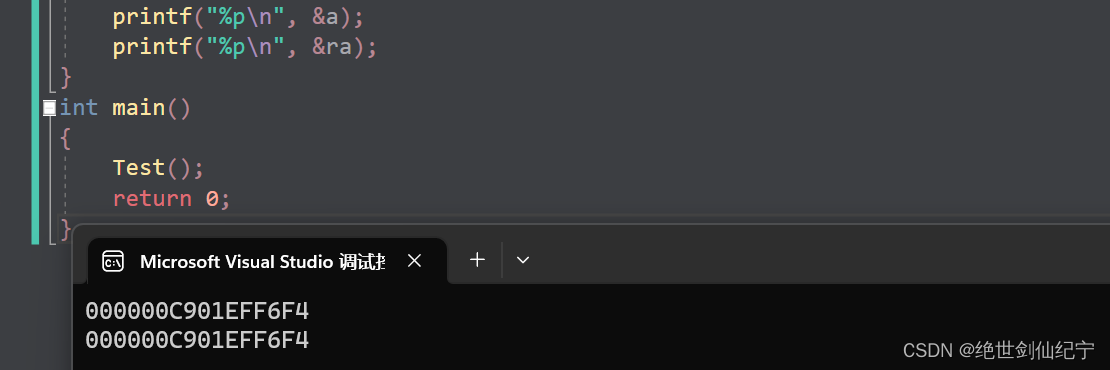
从运行结果我们也可以看到,a和a的引用的地址是相同的。
使用场景
C++中的引用使用范围是非常广泛的。例如,作函数参数,做函数的返回值等
引用作函数参数
在C语言中,我们经常是用传址的方式将变量的地址传给函数,函数使用指针变量来接受这个地址,并在函数内部使用解引用的方式来找到这个变量,从而达到在外部函数中修改变量的方式。
而在C++中,引入了引用这个概念。既然引用是给已存在的变量起一个别名,那么在定义形参的时候,也可以使用引用来定义,这样,直接在函数内部改变引用即可起到修改变量的作用。
例如,不带哨兵位头结点的链表的头插要改变头指针的指向,通过使用二级指针和引用都可以起到在函数内改变指针指向的作用。
C语言使用二级指针的操作如下:
void insertNode(struct ListNode** head, int val) {
struct ListNode* new_node = (struct ListNode*)malloc(sizeof(struct ListNode));
new_node->val = val;
new_node->next = *head;
*head = new_node;
}
加入C++的引用后:
void insert(Node*& head, int data) {
struct ListNode* new_node = (struct ListNode*)malloc(sizeof(struct ListNode));
new_node->val = val;
new_node->next = head;
head = new_node;
}
引用作为函数参数确实比二级指针稍微好理解一点。
引用作返回值
引用作返回值,就是将别名作为返回值直接进行赋值,详细代码如下:
int& Count()
{
static int n = 0;
n++;
// ...
return n;
}
在深究引用作为返回值之前,我们首先要明确返回值究竟是什么?当返回值是 int 的时候,编译器是直接将n 返回吗?显然不是,因为函数栈帧在调用函数结束后就会销毁掉,编译器是无法找到 n 的,所以,如果返回值是 int 的话,编译器会先将 n 的值拷贝一份,等到函数栈帧销毁后,再将这个值赋值给接收体。
那么,如果是 int& 引用作为函数返回值呢?这就有意思了,众所周知,引用定义的是变量的别名,返回引用类型的 n 就是将 n 这个数直接返回给了接受体,但是这时候函数栈帧是已经销毁了的,如果再访问 n 的话,相当于是非法访问了(类似于指针中的野指针问题)。这时,如果输出赋值后的接收体,会得到两种答案:如果编译器将函数栈帧清理掉了的话,可能会得到一个随机值;如果编译器未将函数栈帧清理掉的话,依然会得到原来的 n 值,但从语法上来讲,这种做法显然是错的。
那么,如何来规避这种非法访问的问题呢?答案是将要进行引用返回的变量使用 static 来定义为静态变量。因为静态变量是定义在静态区的,所以引用返回赋值就不会在出现非法访问了,且局部的静态变量只会被初始化一次。
如何理解局部的静态变量只会被初始一次?
int& Count(int a,int b)
{
static int n;
n = a + b;
n++;
return n;
}
int main()
{
int ret1=Count(3, 4);
cout << ret1 << endl;
int ret2=Count(7, 8);
cout << ret2 << endl;
return 0;
}
n 存储在静态区,每次对 n 进行操作都是有用的,那么这段代码输出的应该是 8 和 16。事实也确实如此。

但如果在定义静态变量的时候就给予它一个值,那么看起来差不多的代码结果就会大相庭径。
如果定义静态变量的时候赋了初值:
int& Count(int a,int b)
{
static int n= a + b;
n++;
return n;
}
int main()
{
int ret1=Count(3, 4);
cout << ret1 << endl;
int ret2=Count(7, 8);
cout << ret2 << endl;
return 0;
}
运行结果:
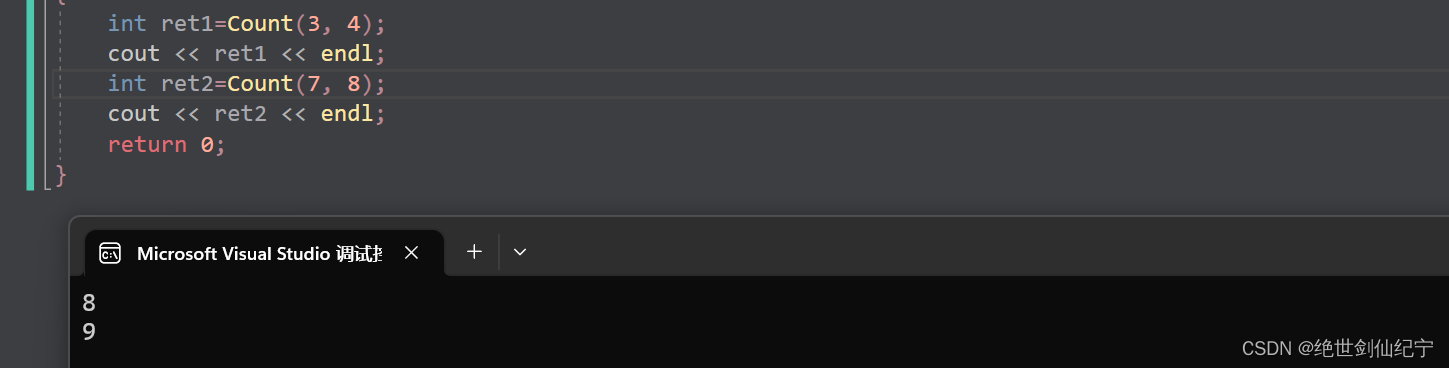
因为局部的静态变量只会被初始化一次,所以第二次传的 7 8 就相当于没有用,直接使用了上次 n 的结果8来参与运算。所以第二次调用时只执行了 n++ 这一条语句。
常引用
即常量也可以被引用定义,如下
const int & e=10
但下面这几种情况都是不对的
不加const
int& e=10;
类型不同
int j=1;
double &rj=i;
要弄懂上面的这些问题,就需要深入了解C++引用的权限问题。
权限问题
权限的放大、平移、缩小
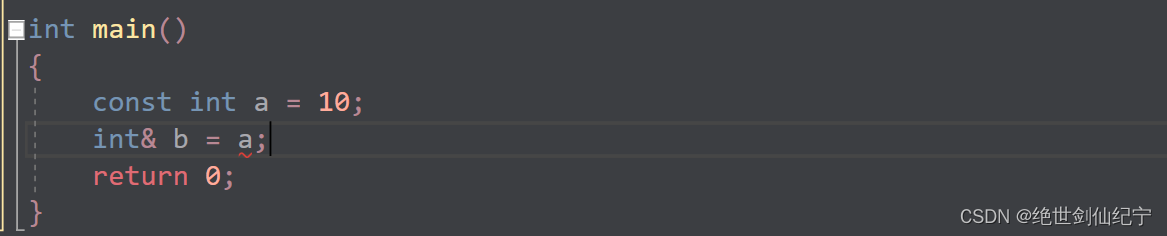
上图就是个一个典型的权限问题,变量 a 已经被限制了,引用(取别名)后会导致变量 a 权限放大,这是不允许的。所以改成下面的方式即可解决这个问题。
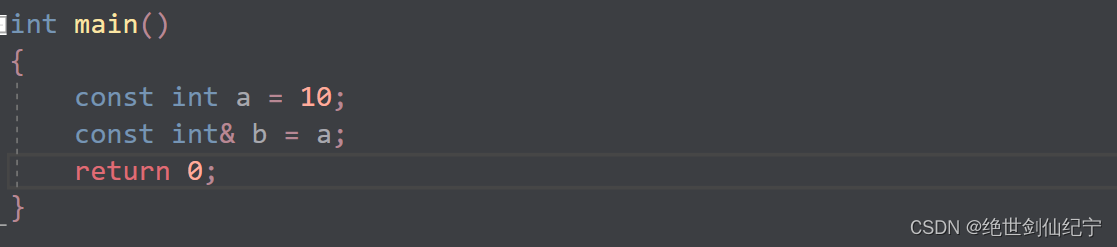
引用也使用 const 来修饰,两个的权限是同等级的,这种引用被成为权限平移
C++语法规定,引用后变量的权限可以缩小或平移,但不能放大!
所以C++在某些特定场景下会使用 const 来修饰定义引用,那么这个引用既可接收 const 修饰的变量,又可接收非 const 修饰的变量。
类型转化时使用的 const
当进行隐式类型转化的时候,编译器会创建一个临时变量,而这个临时变量具有常属性,所以要使用const 来修饰。
例如下面的变量在进行操作的时候都需要进行类型提升:
int x = 0;
size_t y = 1;
if (x > y)
{
}
//
int* ptr = (int*)i;
如 x和 y 比较,需要将 x 类型提升为 无符号的整形,但这个操作不会改变 x 本身,只是对 x 这个变量的拷贝进行提升,因为这个拷贝的变量具有常属性,所以引用时需要使用 const 来修饰。第二个强制类型转化当然不是将 i 直接转化为指针类型了,也是相同的道理。
引用的底层逻辑
引用的用法和指针如此之像,那么引用到底有没有开额外的空间呢?
在语法层面上,我们可以这样验证:打印引用和原本变量的地址。
int main()
{
int a = 10;
int& ra = a;
cout << "&a = " << &a << endl;
cout << "&ra = " << &ra << endl;
return 0;
}
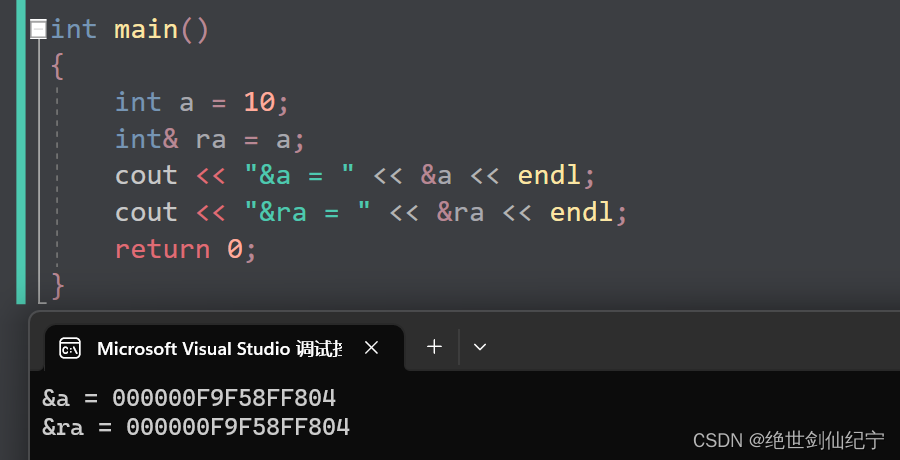
发现引用和变量的地址是相同的,说明至少在语法层面上,引用只是 ‘起别名’ ,不额外占用空间。
但实际上,我们将指针和引用放在一起比较
int main()
{
int a = 10;
int& ra = a;
ra = 20;
int* pa = &a;
*pa = 20;
return 0;
}
查看他们的汇编代码:

发现两者的汇编代码实际上是相同的,所以在底层看来,引用确实是开了空间的!
但我们在日常使用中,依然是以语法为主:引用不开空间
内联函数
在学习C语言的时候,我们学过一种替换,叫宏,但是宏又比较多的缺点,所以我们一般不适用它,但宏(特别是宏函数)在处理一些小型的优化上效率还是非常可观的,那么C++上有什么东西能解决宏这个问题呢?
C++中提出了内联函数这个概念,它在作用上可以平替宏函数,并且克服了宏函数和普通函数的缺点。
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率,但这是一种以空间换时间的方式。
内联函数不用开辟函数栈帧,相对于宏函数增加了可以调试的优点,提高了效率。
内联函数缺点
内联函数只适用于小型函数(以10行为边界),函数太大就会导致展开后占用的空间太大,导致生成的可执行程序太大。因为内联函数有可能会导致程序太大,所以一般使用 inline 只是对编译器的一个建议,不同的编译器对内联函数的机制不同,其中,展不展开内联函数主要看编译器。
一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略 inline 特性。

inline 不建议声明和定义分离,分离会导致最后链接的时候出现错误。因为inline被展开,在多个文件的情况下就没有函数地址了,链接就会找不到。