一、Pandas实现复杂Excel的转置合并
-
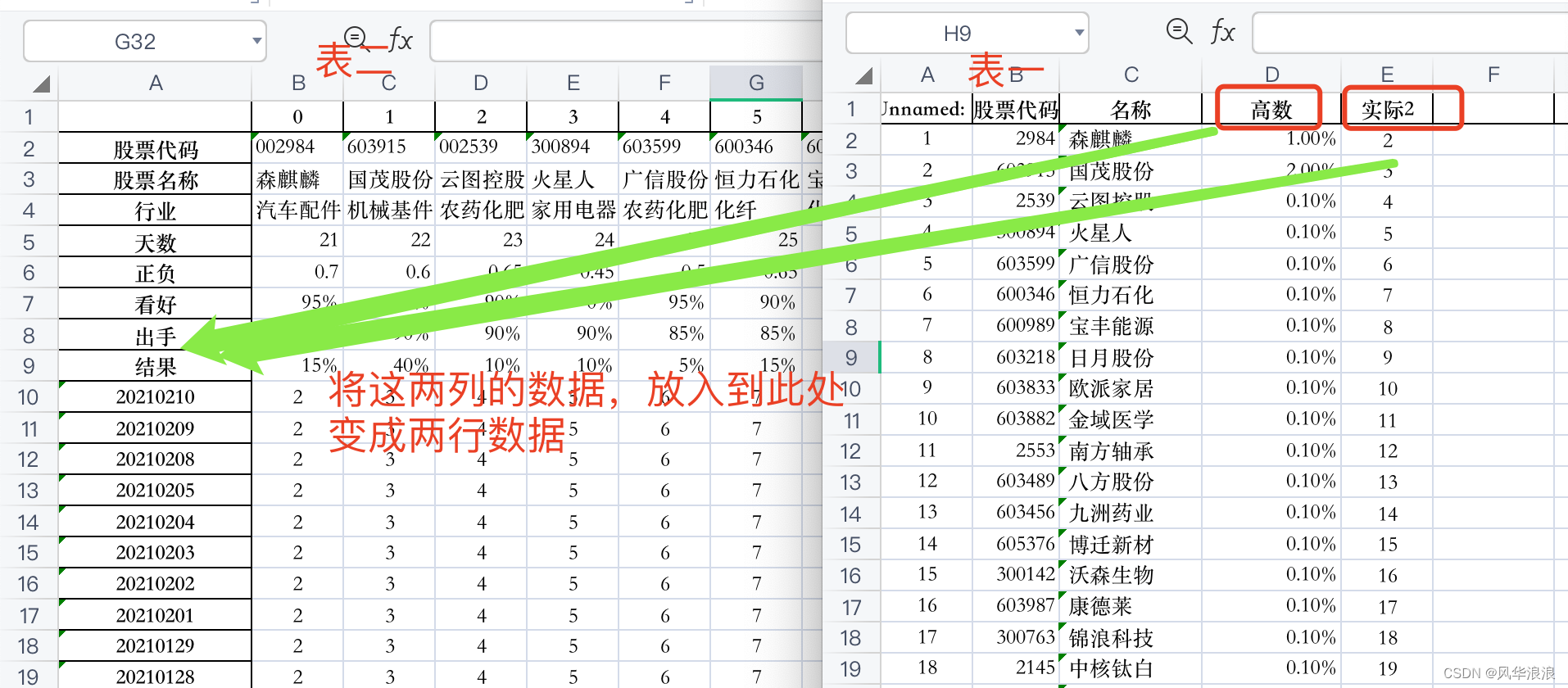
读取并筛选第一张表
df1 = pd.read_excel("第一个表.xlsx") df1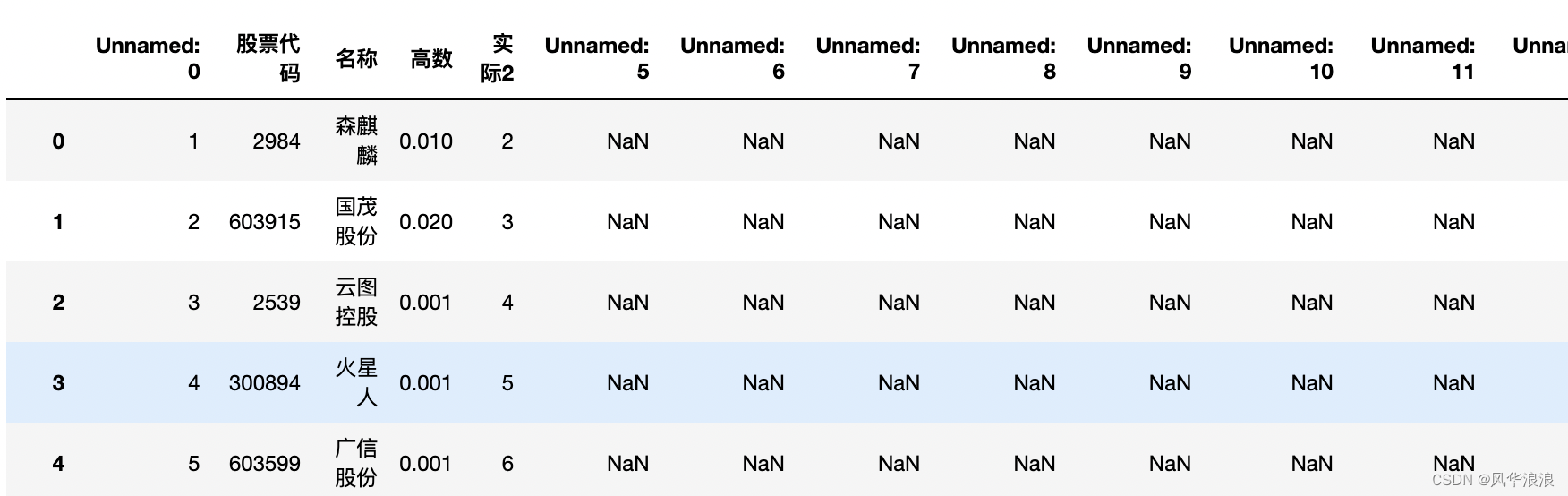
# 删除无用列 df1 = df1[['股票代码', '高数', '实际2']].copy() df1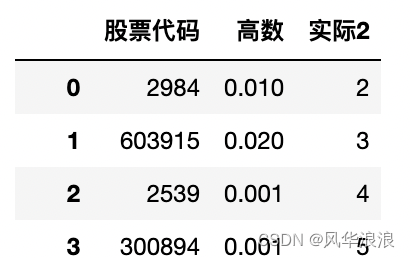
df1.dtypes 股票代码 int64 高数 float64 实际2 int64 dtype: object -
读取并处理第二张表
df2 = pd.read_excel("第二个表.xlsx") df2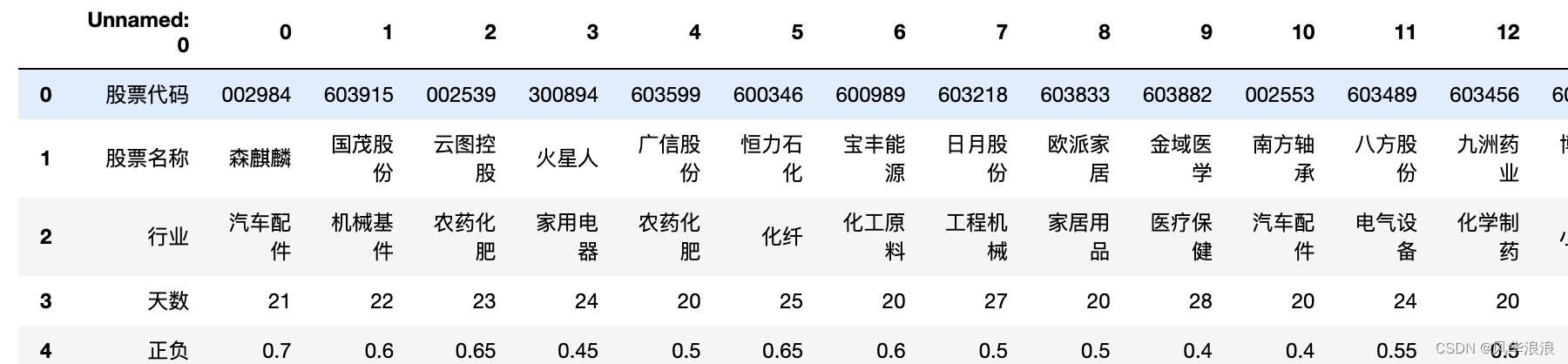
# 将 Unnamed: 0 指定为索引列 df2.set_index('Unnamed: 0', inplace=True) df2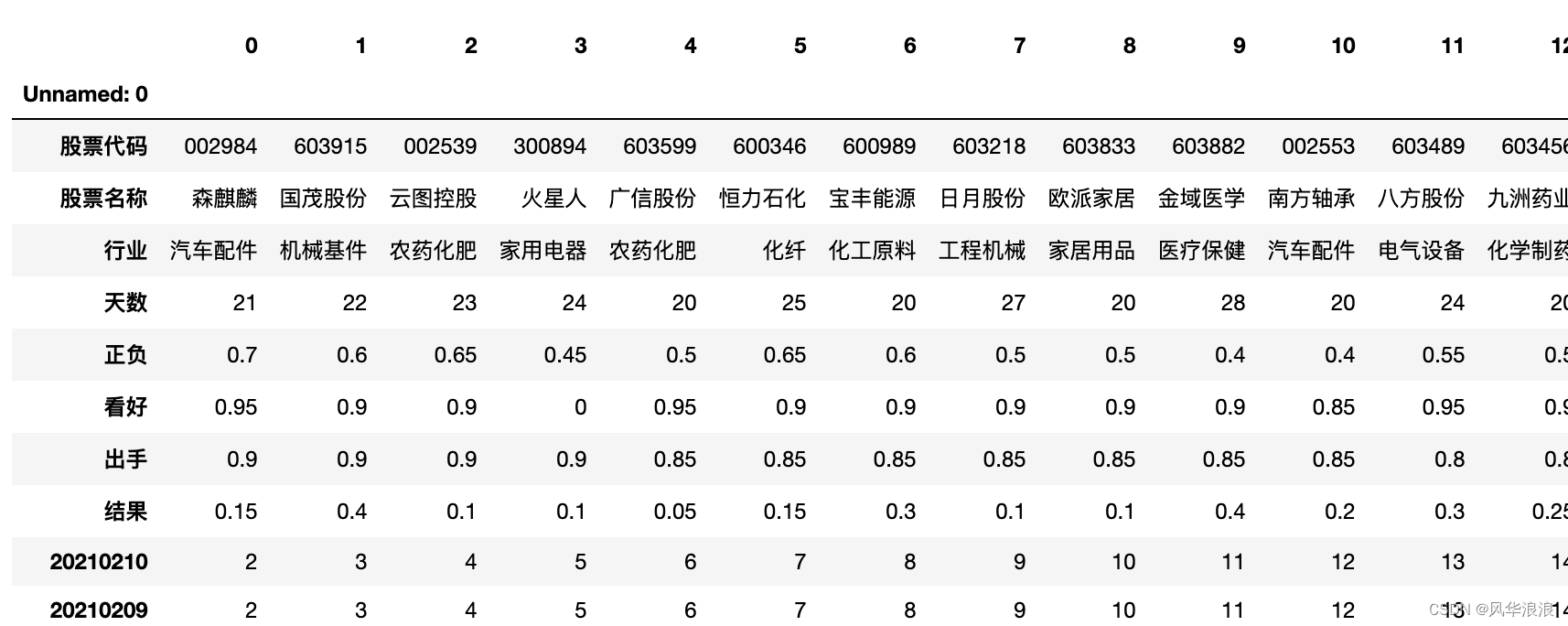
# 主要用到transpose做横竖转换,方便处理 df2 = df2.transpose() df2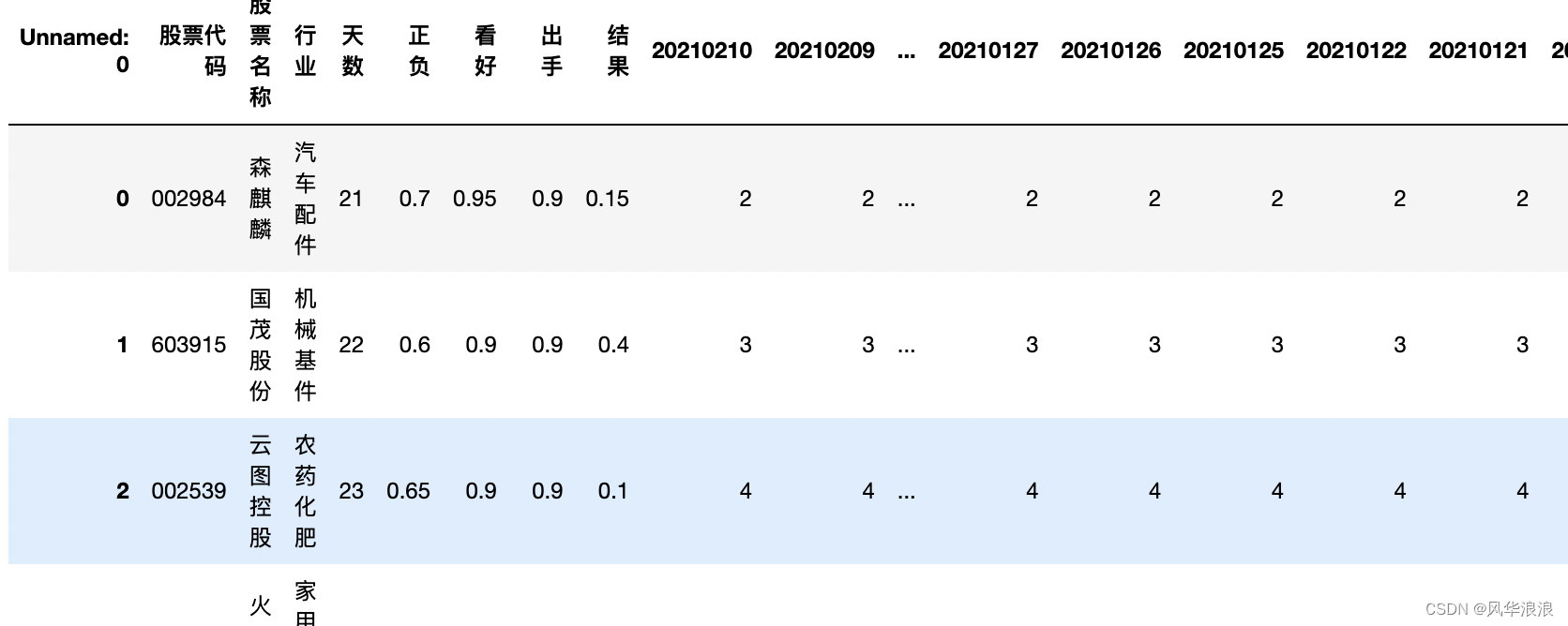
df2.dtypes Unnamed: 0 股票代码 object 股票名称 object 行业 object 天数 object 正负 object 看好 object 出手 object 结果 object 20210210 object 20210209 object 20210208 object 20210205 object# 由于第一张表股票代码是数字,第二张表object 需要转换为number类型 df2['股票代码'] = df2['股票代码'].astype(int) df2 -
合并数据
df_merge = pd.merge(left=df2, right=df1, left_on='股票代码', right_on='股票代码') df_merge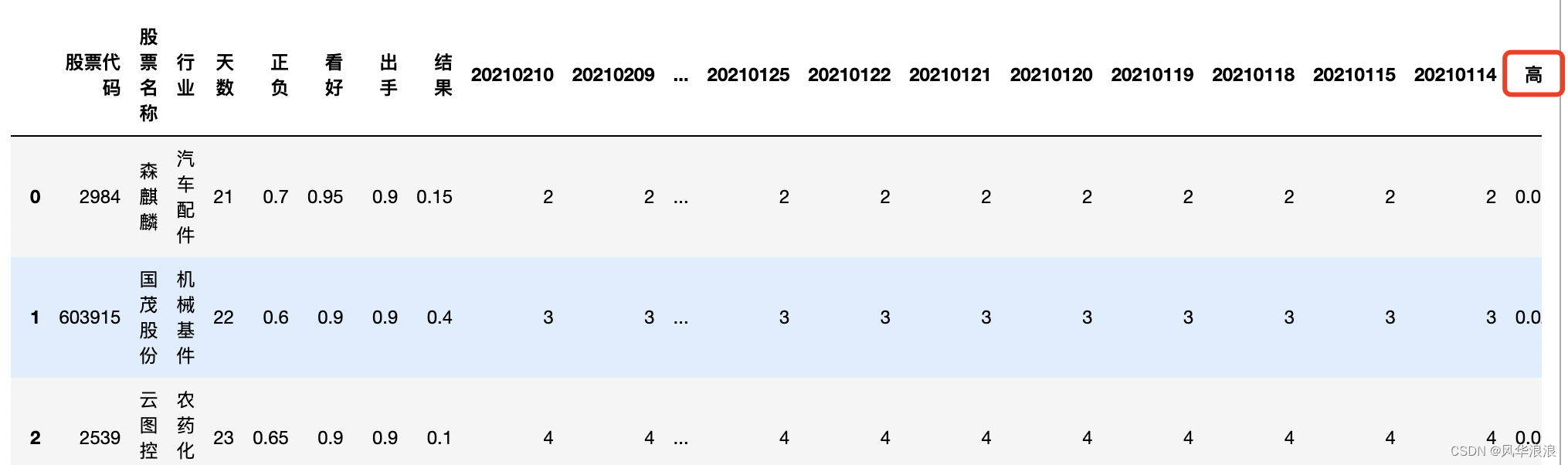
-
重新队列排序
# 重新队列排序(把list重新变成最终模样) columns = list(df_merge.columns) columns.remove('高数') columns.remove('实际2') columns.insert(columns.index("结果"), "高数") columns.insert(columns.index("结果"), "实际2") columns ['股票代码', '股票名称', '行业', '天数', '正负', '看好', '出手', '高数', '实际2', '结果', '20210210', '20210209', '20210208', '20210205', ... ] -
筛选列,专置数据、输出结果
df_result = df_merge[columns].transpose() df_result.to_excel("表一表二合并结果.xlsx", header=False)
三、其它
import pandas as pd
import random
# 学生数量
num_students = 100
# 列表包含所有的科目
subjects = ['语文', '英语', '数序', '自然', '社会', '几何', '代数', '物理', '化学']
# 使用列表推导为每个科目生成随机分数
data = {
subject: [random.randint(50, 100) for _ in range(num_students)] for subject in subjects}
# 为学生生成唯一的用户名
data['用户名'] = ['student'+str(i) for i in range(1, num_students+1)]
df = pd.DataFrame(data)
print(df)
# 获取当前的列顺序
cols = df.columns.tolist()
# 移除'化学'并将其插入到'英语'后面
cols.remove('化学')
physical_index = cols.index('英语')
cols.insert(physical_index + 1, '化学')
# 使用新的列顺序重新排序DataFrame
df = df[cols]
print(df)