点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
扫码加入CVer学术星球,可以最快学习到最新顶会顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文搞科研,强烈推荐!



论文:https://arxiv.org/abs/2312.03441
数据集及代码地址:
https://github.com/Zplusdragon/UFineBench
太长不看版:
针对基于文本的行人检索任务,我们人工标注了一个全新的有着超细粒度文本描述的数据集UFine6926(平均单词数为先前数据集的三到四倍),提出了一个更能够反映真实场景中高度复杂变化的测试集UFine3C,一个更准确反映检索能力的测试指标mSD和一个有着细粒度设计的新算法CFAM。我们主要证明了的是,在超细粒度数据集上进行训练得到的模型能够更好地感知细粒度的属性信息并泛化到真实场景中!
简介:
现有的基于文本的行人检索数据集通常具有相对粗糙的文本注释,这极大限制了模型对真实场景中查询文本细粒度语义的理解。为了解决这一问题,我们提出了一个专注于超细粒度的文本行人检索的名为 UFineBench 的新基准。首先,我们构建了一个名为 UFine6926 的新数据集,其中包含大量行人图像,每张图像有着两个人工标注的详细的文本描述,平均每个描述有着80.8个单词,平均单词数是先前数据集的三到四倍。同时,除了标准的域内评估,我们还提出了一种更贴近真实场景的特殊评估范式。该范式包含一个新的跨域、跨文本粒度和跨文本风格的三跨评估集,命名为 UFine3C,以及一个用于准确衡量检索能力的新评估指标,名为mSD。此外,我们还专为超细粒度文本行人检索设计了一种更高效的算法 CFAM。它通过采用共享的跨模态粒度解码器和硬负匹配机制实现了更好的细粒度的挖掘。通过标准域内评估,CFAM在各种数据集上建立了竞争性的性能,特别是在超细粒度的 UFine6926 上。此外,通过在 UFine3C 上进行评估,我们证明了在 UFine6926 上进行训练相比其他粗粒度数据集显著提高了对真实场景的泛化能力。
UFine6926:

由上图左列可以看到,现有的数据集普遍存在一些共性问题:1)文本粒度非常粗糙导致很多细节的行人属性特征没有得到显式的描述与挖掘,这样会导致模型在实际应用中很难感知到某些关键性细节属性特征;2)文本描述模糊性太大,粗糙的文本描述极易导致一句本来应该和一个行人身份高度绑定的文本却在语义上能够很好地对应另外一个行人身份,这会在训练过程中引入很大的不确定性因素,影响模型的性能表现。
而由上图右列可以看到,我们提出的UFine6926数据集中的文本粒度非常精细,基本上一个行人身上的任何细节性特征都有着对应的描述,从而很好地解决了上述问题。
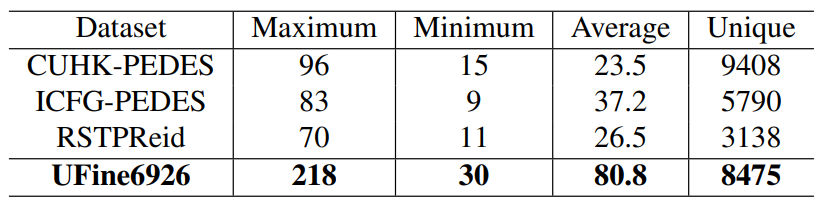
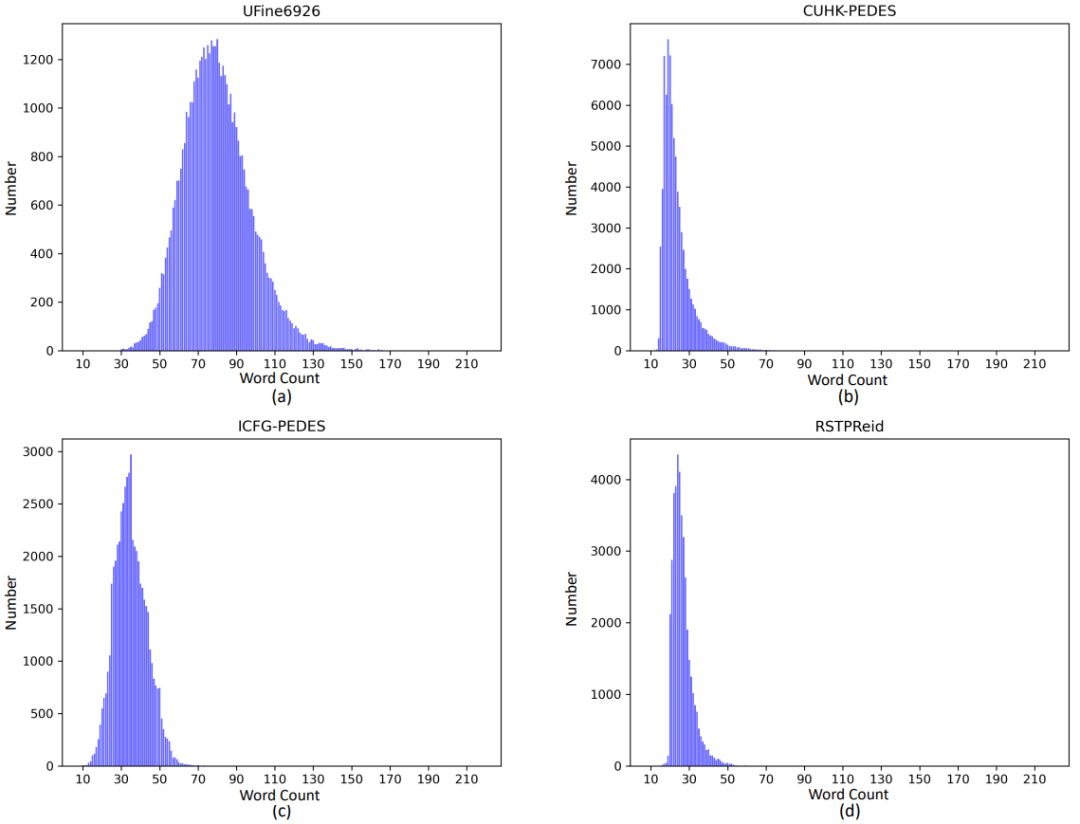
我们统计比较了UFine6926与先前其他数据集的文本描述的单词数目情况,如上表所示,UFine6926的平均单词数达到了80.8,远远高于所有的其他数据集。同时如下图我们展示了各个数据集的单词数目的分布情况,可以看到,与其他数据集相比较,我们数据集的细粒度程度有着极其显著的提高。
下方是UFine6926中一些图文数据的更多展示:

UFine3C:
同时,我们构建了一个跨域、跨文本粒度、跨文本风格的三跨测试集,名为UFine3C,该数据集可以更好地评估各模型在真实应用场景中的实际表现情况,详细构建过程可参阅原文。
如下图所示,UFine3C的图片部分的变化非常丰富,不仅有着分辨率和光照情况的差异,同时也有着非常丰富的场景变化。

如下图可以看到UFine3C的文本粒度分布情况,可以看到,UFine3C的检索文本的单词数目有着由粗到细的分布。

如下图所示可以看到UFine3C的文本风格情况,一幅待检索图片通常有着很多局句式结构不一样,语言风格不一样的文本检索。

此外,我们还提出了一个更能准确衡量模型检索性能的新指标mSD和一个专门针对细粒度设计的新算法CFAM,详细介绍可参见原文。
实验部分
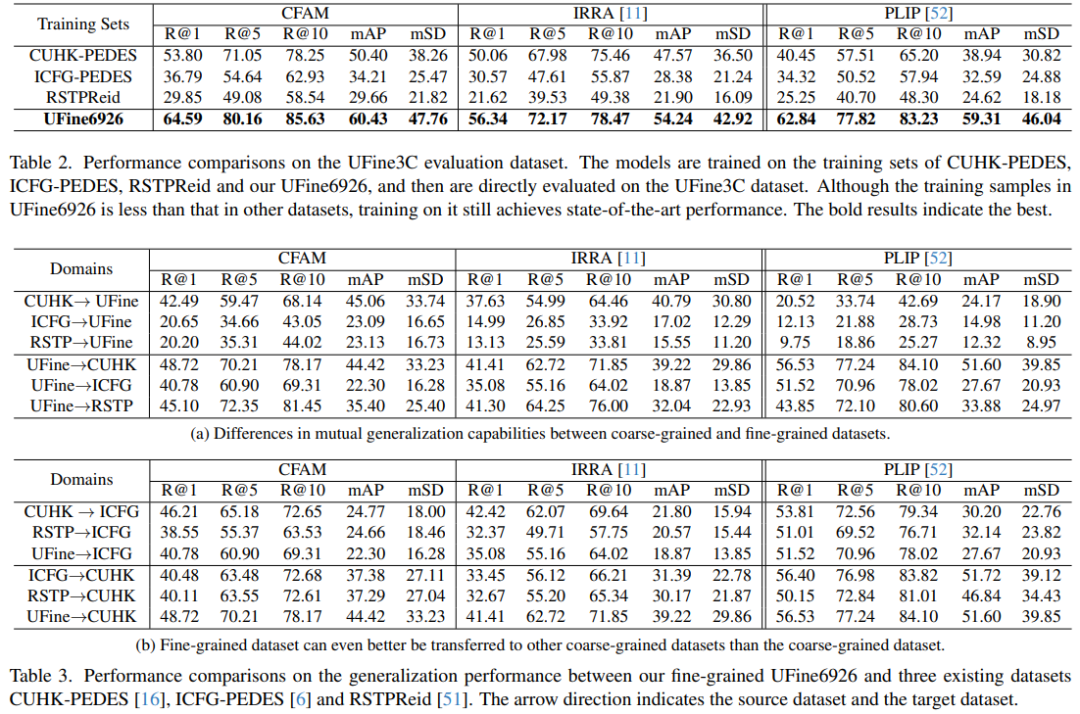
我们最主要的一个实验是证明了在我们的细粒度数据集UFine6926上训练得到的模型有着更为优秀的泛化能力,在真实应用场景中有更好的性能表现,一些实验结果如下所示。同时我们还展现了CFAM的优秀性能表现,本文不予展示,可参见原论文。
我们还做了一个可视化定性实验,如下图所示,可以看到在UFine6926上训练得到的模型对细节的感知能力有着极其明显的提高。

最后,我们非常希望我们新提出的UFineBench能够促进该领域更多地去研究细粒度和真实应用场景的泛化问题,希望该领域不要局限于一两个粗粒度数据集的性能点的提升,非常欢迎各位同行讨论与交流!
CVPR / ICCV 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集ReID和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-ReID或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如ReID或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号