第一天 :dIntroduction · HonKit https://python.swaroopch.com/ 这本书重点看看数据结构就行了 简单入门
https://python.swaroopch.com/ 这本书重点看看数据结构就行了 简单入门
第二天GitHub - huangsam/ultimate-python: Ultimate Python study guide for newcomers and professionals alike.Ultimate Python study guide for newcomers and professionals alike. :snake: :snake: :snake: - GitHub - huangsam/ultimate-python: Ultimate Python study guide for newcomers and professionals alike. https://github.com/huangsam/ultimate-python非常不错的教程,数据结构部分代码讲解很清楚,可以直接用python运行来理解
https://github.com/huangsam/ultimate-python非常不错的教程,数据结构部分代码讲解很清楚,可以直接用python运行来理解
BeginnersGuide/Programmers - Python Wiki各种python学习教程 我就从里面找了几本看 意义好像不太大
https://github.com/huangsam/ultimate-python 简单看看
Pandas Cookbook :: TutsWiki Beta pandas入门 目前没发现更好的教程
pandas.DataFrame — pandas 1.5.2 documentation
Basics of NumPy Arrays - GeeksforGeeks 如何理解ndarray in numpy nupyarray
第三天
python中数据结构的转换
跟着数据结构那几章 2倍速观看学习操作 list tuple ditc
174-元组-03-元组变量的常用操作_哔哩哔哩_bilibili
5. 5.数据分析-1.7 ndarray属性操作详解01_哔哩哔哩_bilibili 2倍速观看 看重点就好了
numpy 数据结构的学习
NumPy: the absolute basics for beginners — NumPy v1.24 Manual
以下这几个章节比较经典 推荐多看
-
How to get unique items and counts
-
Transposing and reshaping a matrix
-
How to reverse an array
-
Reshaping and flattening multidimensional arrays
NumPy Reference — NumPy v1.24 Manual
7.DataFrame的重要属性_哔哩哔哩_bilibili pandas数据的增删改查 切片等常用操作 很全!!
https://www.bilibili.com/video/BV1iK411f7PP?p=14&spm_id_from=pageDriver&vd_source=909d24b4b33e8977adc9d6ea868a6e4d https://www.bilibili.com/video/BV1iK411f7PP?p=14&spm_id_from=pageDriver&vd_source=909d24b4b33e8977adc9d6ea868a6e4d
https://www.bilibili.com/video/BV1iK411f7PP?p=14&spm_id_from=pageDriver&vd_source=909d24b4b33e8977adc9d6ea868a6e4d
讲解非常好,很详细!
Essential basic functionality — pandas 1.5.2 documentationhttps://pandas.pydata.org/pandas-docs/stable/user_guide/basics.html pandas操作总结
ndarry
一维数组:增删改查 切片
二维数组:增删改查 切片
多维数组的组合与拆分
(466条消息) 强烈推荐python中学习单细胞分析必看anndata官网教程初探 先理解python中基础的数据结构列表 元组 字典 增删改查 以及numpy和pandas数据结构,再看此教程_YoungLeelight的博客-CSDN博客 https://blog.csdn.net/qq_52813185/article/details/128500883?
第四天
anndata单细胞分析的基本数据结构 重点在线学习
https://anndata.readthedocs.io/en/latest/tutorials/index.html
https://anndata.readthedocs.io/en/latest/tutorials/notebooks/getting-started.html
 编辑
编辑
python中的类与对象
【Python】Python中的类与对象_哔哩哔哩_bilibili
大概看了一下
Intro to data structures — pandas 1.5.2 documentation
NumPy Documentation
GitHub - pandas-dev/pandas: Flexible and powerful data analysis / manipulation library for Python, providing labeled data structures similar to R data.frame objects, statistical functions, and much more
for each in adata.obs.columns:
...: print(adata.obs[each].describe())
...: print("=============================\n")
第五天 scanpy学习
(469条消息) scanpy学习 教程 就像seurat教程一样_YoungLeelight的博客-CSDN博客https://blog.csdn.net/qq_52813185/article/details/128443014
经典pbmc3k教程
Preprocessing and clustering 3k PBMCs — Scanpy documentation (scanpy-tutorials.readthedocs.io)
我的学习过程详细代码
step1——在r中运行python环境设置 有点像conda的环境设置
```{r}
library(rmarkdown)#不运行就保存rmarkdown
rmarkdown::render("tracy.Rmd",
run_pandoc = FALSE,
output_format = "pdf_document")
```
getwd() #教程地址 https://theislab$github$io/scanpy-in-R/#alternative-approaches
1#创建python环境
renv::init()
renv::install("reticulate")
2#使用第二个python环境 #2: C:/Users/yll/AppData/Local/Programs/Python/Python39/python$exe
renv::use_python("C:/Users/yll/AppData/Local/Programs/Python/Python39/python.exe")
3#安装python环境中的python模块
py_pkgs <- c(
"scanpy",
"python-igraph",
"louvain"
)
reticulate::py_install(py_pkgs)
reticulate::py_install("certifi")#ModuleNotFoundError: No module named 'certifi'
reticulate::py_install("leidenalg")#不可以用vpn 否则会报错
reticulate::py_install("ipython")#安装包
library(reticulate)
sc <- reticulate::import("scanpy")
#adata <- sc$datasets$pbmc3k_processed()
adata=sc$datasets$paul15()
adata
adata$var
rownames(adata$var)
head(adata$X)[1:3,1:10]
head(adata$obs)[1:3,1:10]
dim(adata$X)
str(adata$X)
#####读取下载好的pbmc
np=reticulate::import('numpy')
pd=import('pandas')
sc=import("scanpy")
sc$settings$verbosity <- 3 # verbosity: errors (0), warnings (1), info (2), hints (3)
sc$logging$print_header()
sc$settings$set_figure_params(dpi=80, facecolor='white')
results_file = 'write/pbmc3k$h5ad' # the file that will store the analysis results
adata = sc$read_10x_mtx(
"G:/silicosis/sicosis/gitto/python_study/scanpy_study/data/filtered_gene_bc_matrices/hg19/", # the directory with the `$mtx` file
var_names='gene_symbols' # use gene symbols for the variable names (variables-axis index)
) # write a cache file for faster subsequent reading
adata
adata$var_names_make_unique() # this is unnecessary if using `var_names='gene_ids'` in `sc.read_10x_mtx`
sc$plotting$highest_expr_genes(adata =adata,n_top = 20,)
sc$pl$highest_expr_genes(adata, n_top=20 )
sc$pp$filter_cells(adata, min_genes=200)
sc$pp$filter_genes(adata, min_cells=3)
adata$var['mt'] = adata$var_names$str$startswith('MT-') # annotate the group of mitochondrial genes as 'mt'
sc$pp$calculate_qc_metrics(adata, qc_vars=adata$var['mt'])
sc$pl$violin(adata, adata$uns['n_genes_by_counts', 'total_counts', 'pct_counts_mt'],
jitter=0.4, multi_panel=True)
sc$pl$scatter(adata, x='total_counts', y='pct_counts_mt')
sc$pl$scatter(adata, x='total_counts', y='n_genes_by_counts')
adata$X
adata$obs
#此处不需要adata=
adata=adata[adata$obs$n_genes_by_counts < 2500, :]
adata[adata$obs$pct_counts_mt < 5, :]
sc$pp$normalize_total(adata, target_sum=1e4)
sc$pp$log1p(adata)
sc$pp$highly_variable_genes(adata, min_mean=0$0125, max_mean=3, min_disp=0$5)
sc$pl$highly_variable_genes(adata)
adata$raw = adata
adata
adata=adata[:, adata$var$highly_variable]
adata
step2 使用 rmarkdown 初步学习 认识了一下scanpy 环境的安装 还有如何导出rmarkdown文件
---
title: "Untitled"
author: "yll"
date: "2022-12-27"
output:
word_document: default
html_document:
df_print: paged
pdf_document: default
---
```{r}
#install.packages("bookdown")
#install.packages("pdflatex")
reticulate::py_install("lxml")
reticulate::py_config()
reticulate::conda_version()
reticulate::conda_python()
```
```{r}
#设置r包安装路径
.libPaths()
.libPaths(c("G:/silicosis/sicosis/gitto/python_study/renv/library/R-4.1/x86_64-w64-mingw32","C:/Users/yll/AppData/Local/Temp/RtmpErvVSx/renv-system-library" ,"G:/R_big_packages/","D:/Win10 System/Documents/R/win-library/4.1","C:/Program Files/R/R-4.1.0/library"))
```
```{r}
#tinytex::install_tinytex()
```
```{r}
#install.packages("rticles")
library(reticulate)
py_install("openpyxl")
```
\#`{r setup, include=FALSE} #knitr::opts_chunk$set(echo = TRUE) #`
##python清除所有变量_如何清空python的变量
```{python}
for key in list(globals().keys()):
if not key.startswith("__"):
globals().pop(key)
```
```{python}
import numpy as np
import pandas as pd
import scanpy as sc
```
```{python}
sc.settings.verbosity = 3 # verbosity: errors #(0),warnings (1), info (2), hints (3)
sc.logging.print_header()
sc.settings.set_figure_params(dpi=80, facecolor='white')
results_file = 'write/pbmc3k.h5ad' # the file that will store the #analysis results
```
#Preprocessing
```{python,echo=T}
adata = sc.read_10x_mtx(
"G:/silicosis/sicosis/gitto/python_study/scanpy_study/data/filtered_gene_bc_matrices/hg19/", # the directory with the `.mtx` file
var_names='gene_symbols', # use gene symbols for the variable names (variables-axis index)
cache=True) # write a cache file for faster subsequent reading
adata
adata.var_names_make_unique() # this is unnecessary if using `var_names='gene_ids'` in `sc.read_10x_mtx`
```
```{python,echo=T}
adata
sc.pl.highest_expr_genes(adata, n_top=20, )
```
```{python,echo=T}
```
## Basic filtering:
```{python echo=TRUE}
sc.pp.filter_cells(adata, min_genes=200)
sc.pp.filter_genes(adata, min_cells=3)
```
With pp.calculate_qc_metrics, we can compute many metrics very efficiently.
```{python echo=TRUE}
adata.var['mt'] = adata.var_names.str.startswith('MT-') # annotate the group of mitochondrial genes as 'mt'
sc.pp.calculate_qc_metrics(adata, qc_vars=['mt'], percent_top=None, log1p=False, inplace=True)
```
```{python echo=TRUE}
sc.pl.violin(adata, ['n_genes_by_counts', 'total_counts', 'pct_counts_mt'],
jitter=0.4, multi_panel=True)
```
```{python}
sc.pl.scatter(adata, x='total_counts', y='pct_counts_mt')
sc.pl.scatter(adata, x='total_counts', y='n_genes_by_counts')
adata = adata[adata.obs.n_genes_by_counts < 2500, :].copy()
adata = adata[adata.obs.pct_counts_mt < 5, :].copy()
```
```{python}
adata = adata[adata.obs.n_genes_by_counts < 2500, :].copy()
adata = adata[adata.obs.pct_counts_mt < 5, :].copy()
```
```{python echo=TRUE}
sc.pp.normalize_total(adata, target_sum=1e4)
sc.pp.log1p(adata)
sc.pp.highly_variable_genes(adata, min_mean=0.0125, max_mean=3, min_disp=0.5)
sc.pl.highly_variable_genes(adata)
```
```{python}
adata.raw = adata
```
##do the filtering
```{python echo=FALSE}
adata = adata[:, adata.var.highly_variable].copy()
```
```{python}
adata = adata[:, adata.var.highly_variable].copy()
```
```{python echo=FALSE}
sc.pp.regress_out(adata, ['total_counts', 'pct_counts_mt'])
sc.pp.scale(adata, max_value=10)
```
```{python}
adata
mydata=adata.obs
```
```{r}
rdata=seq(1,9,1)
```
#
```{r}
#library(knitr)
#library(reticulate)
```
```{python}
r.rdata
print("=================")
mydata
```
```{r }
py$mydata$n_genes
rdata=subset(py$mydata,'n_genes'>1000)
py$results_file
py$mydata
```
```{r}
py$mydata
```
```{r}
#install.packages("knitr")
package_version("knitr")
```
```{python echo=TRUE}
import seaborn as sns
#fmri=sns.load_dataset("fmri")#和网路有关可能需要翻墙 ,否则报错
```
```{python}
#fmri=sns.load_dataset()#和网路有关可能需要翻墙 ,否则报错
```
```{r}
py$sns
```
```{r}
py$mydata
```
```{r}
#py_save_object(py$adata, "adata.pickle", pickle = "pickle")
```
step4 和哔哩哔哩视频学习了python中基础的数据结构 如列表 元组 字典 及其常见操作:增加 删除 改 变 切片语法
---
title: "Untitled"
author: "yll"
date: "2022-12-28"
output: html_document
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
```
```{python}
name="xiaoming"
type(name)
acb=True
type(acb)
2**32
type(2**32)
type(2**64)
```
#根据内容获取索引
#根据索引获取内容
```{python}
name=["zhansan","lisi","wangwu","afda","fa"]
name
name.index("lisi")
#根据内容获取索引
name.index("zhansan" or "lisi")
name.index("zhansan" and "lisi")
type(name)
name[1]
name[1:5:1]
#修改索引内容
```{python}
name
name[1]
```
#获取多个元素的索引
```{python}
lst=['zhansan', 'lisi', 'wangwu', 'afda', 'fa']
lst
for index, element in enumerate(lst):
print(index, element)
a=index, element
print(a)
############333
elements = [3, 5, 7]
indices = [index for index, element in enumerate(lst) if element in elements]
indices
###################
numbers = [1, 2, 3, 4, 5, 6]
# 获取多个元素的索引
for i, number in enumerate(numbers):
if number in (4, 5):
print(i) # 输出 3 4
```
```{python}
name.append("wangxiaoer")
name
#在列表的指定位置插入数据
name.insert(1,"小美眉")
name
temp_list=["Afda","Afd",("Afaf"),{"AFa":"faafafa"}]
temp_list
name.extend(temp_list)
name
#name.index("afaf")
len(name)
name[1]
name[len(name)-1]
```
#删除列表中元素
```{python}
name
name.remove("fa")
name
#pop默认删除最后一个
name.pop()
name
name.pop(4)#删除指定索引位置的元素 并打印该元素
name.clear()
name
```
#del关键字来删除列表中的元素
#del本质上是从内存中删除变量,后续就不能再使用该变量
```{python}
name.reverse()
name
name=["zhansan","lisi","wangwu","afda","fa"]
name
name.index("lisi")
name
del name[1]
name
del name
#name就不复存在了
```
```{python}
len(name)
name
#某个元素在列表中出现的次数
name.count("afd")
#name.remove()会删除第一个出现的值
```
```{python}
#sort 默认升序
name
name.sort()
name
#降序排序
name.sort(reverse=True)
name
#逆序 反转
name
name.reverse()
name
name[::-1]
```
#取值 取索引 统计记数
```{python}
#python中的关键字有哪些 key
#使用这些关键字时候 不需要括号
import keyword
print(keyword.kwlist)
len(keyword.kwlist)
info_tuple
info_tuple[1]
print(info_tuple)
print(info_tuple[:])
print(info_tuple[::])
info_tuple.index(18)
name
name.index("fa")
```
#循环遍历
```{python}
#迭代遍历iteration 使用for关键字
#顺序从列表中依次获取数据
name
for my_name in name:
print("我的名字叫 %s" %my_name)
```
```{python}
list=["AFaf",1,2,1]
list
```
#元组数据 tuple 元素不可以修改,
#只可以从中获取数据,不可以修改
#数据之间 逗号 , 分隔
```{python}
#可以保存不同类型数据
info_tuple=("afa","zhansan",18,1.75)
info_tuple
type(info_tuple)
info_tuple[1]
info_tuple[::-1]
info_tuple
empty_tuple=()
empty_tuple
#只包含一个数据的元组 加上逗号即可
single_tuple=(5)
type(single_tuple)
single=(5,)
type((5,))
type(single)
info_tuple
print(info_tuple)
len(info_tuple)
```
#遍历元组
```{python}
for my_info in info_tuple:
#元组中通常保存的数据类型是不同的
print(my_info)
```
#格式化字符串 $s占位符 后面的()本质上就是个元组
```{python}
print("%s 年龄是 %d, 身高是 %.2f" %("xiaoming",16,180) )
info_tuple=("xiaoming",16,180)
print("%s 年龄是 %d, 身高是 %.2f" %info_tuple )
```
#数据结构相互转换
#元组与列表之间的相互转换
```{python}
num_list=[1,34,563,1,1]
num_list
num_tuple=tuple(num_list)
num_tuple
type(list)
del list
list(num_tuple)
```
#字典是无序的对象集合 列表是有顺序的
#字典的key必须是唯一的
```{python}
xiaoming={"name":"小明",}
print(xiaoming)
xiaoming_dict={"name":"小明",
"age":19,
"gender": "nan",
"height": 190}
print(xiaoming)
print (xiaoming_dict)
#取值
xiaoming_dict["name"]
#在取值时候,如果指定的key不存在,则会报错
#增加 删除
xiaoming_dict["age"]=00
xiaoming_dict
xiaoming_dict["name"]="xiaoxiaoming"
xiaoming_dict
#删除 指定删除的key即可 如果指定的key不存在 则报错
xiaoming_dict.pop("name")
xiaoming_dict
```
```{python}
#统计键值对的数量
len(xiaoming_dict)
xiaoming_dict
#合并字典 如果被合并的字典包含与原字典相同的key,则覆盖
name.extend(xiaoming)
name
temp_dict={"height":19010,
"agse":10,
"name":"xiaoming"}
temp_dict
xiaoming_dict
xiaoming_dict.update(temp_dict)
xiaoming_dict
xiaoming_dict.items()
#删除字典
xiaoming_dict
xiaoming_dict.clear()
xiaoming_dict
```
#循环遍历字典
```{python}
for i in xiaoming_dict:
print(i)
print("---")
print(xiaoming_dict[i])
xiaoming_dict.update(temp_dict)
xiaoming_dict
xiaoming_dict["age"]
for k in xiaoming_dict:
print("%s---%s" % (k,xiaoming_dict[k]))
for k in xiaoming_dict.items():
print(k)
print(" %s,====,%s" % k) #格式化输出 不用加逗号,
print("%s,---,%s",k)
xiaoming_dict.values()
type(xiaoming_dict.values())
type(xiaoming)
xiaoming_dict.values()
globals().keys()
for i in xiaoming_dict.values():
print(i)
```
#列表和字典嵌套操作
#多个字典放在一个列表中
```{python}
card_list=[
{"name":"zhangsan",
"phenumb":235215325},
{"name":"lisi",
"phenumb":87342}
]
card_list
for card_info in card_list:
print(card_info,"=======+")
print(card_info["name"])
card_info
```
#字符串
```{python}
str1="hello python hello world"
str1
str1[4]
str1[::-1]
for char in str1:
print(char)
len(str1)
str1.count("o")
str1.count("lo")
str1.capitalize()
str1.index("lo")
str1.upper()
str1.isspace()
str1.istitle()
str1
str1.upper()
str1
str1.split()
str1
str_list=str1.split()
print(str_list)
" ".join(str_list)
```
#字符串的切片
```{python}
```
#公共方法 也就是内置函数
```{python}
len()
del() #加了括号就与关键字不一样了 但是作用是完全相同的
char
char = str1.split()
char
del(char[1])
char
del char[2]
char
max(char)
max(str1)
str1
1>6
[111,1]>[3,1,1]
max(str('"1,"fs",342"'))
```
```{python}
name
name[0]="agaf"
name
```
name[::-1]
name['afda']
name.count("a")
print(name[2])
name.index()
```
```{python}
name_list=[]
name_list.
```
step5 跟着bilibili视频学习 numpy中的ndarray数据结构 数组结构 数据 没有看完 因为后面感觉有点南?而且太深入了,我好像用不到。主要学习了增删改查 切片语法 ,shape属性。进入学习疲劳期之后 就换了个pandas继续学习
心得:学习这些数据结构的过程就大概分为:
1.是什么 ,定义是啥?数据结构 长啥样子,
2.该对象属性的学习
3.该对象方法的学习
4.通用函数的学习
字符串 操作:正则表达式
数字的操作
列表操作
元组操作 以及和列表的区别
字典的常见操作
数组操作
#https://www.bilibili.com/video/BV1dd4y1Q7vt/?p=9&spm_id_from=pageDriver&vd_source=909d24b4b33e8977adc9d6ea868a6e4d
import numpy as np
ary=np.array([1,3,4,2,6,7])
ary
type(ary)
ary.data
ary.shape
ary.shape=(2,3)
ary
type(ary)
ary.shape=(6,)
ary
ary*3
len(ary)
ary<3
#创建数组的方法
ary=np.arange(0,9,1)
ary
ary=np.array([1,42,55,2542,253,414,1])
ary
ary=np.zeros(20)
ary
ary.shape=(4,5)
ary
ary=np.ones((2,4),dtype='float32')
ary
ary=np.ones((2,4))
ary
np.ones(10)
np.ones(10,10)
ary=np.ones((10,10))*5
#100个1/5
np.ones(5)/5
np.zeros_like(ary)#维度长得像ary
np.ones_like(ary)
#常见的属性
shape
dtype
size
len
a=np.arange(0,9)
a
a.shape
a.shape=(3,3)
a
#错误的而修改数据类型方式
a.dtype
a.dtype="float32" #说明这种强制转换是不对的!!
a
a.dtype
#
b=a.astype('float32')
a
b
#size属性
a
a.size
len(a)
a.shape=(3,3)
a.size
a
len(a)
a.size
a.shape
a
#index 索引
c=np.arange(1,28)
c
c.shape=(3,9)
c
c.shape=(3,3,3)
c
#取4 怎么取
c[0]
c[0][1][0]
c[0,1,0]
c[0][1,0]
c
c[0,1][0]
c.shape
a=np.arange(0,8)
a
a.shape=(2,4)
a
a[1,3]
a[1][3]
##复合数据类型
data=[
("zhangsan",[1,23,4],19),
("lisi",[2,5,6],18),
("ww",[23,635,1],19)
]
data
a=np.array(data,dtype=object)
a
a.__index__
a[0,0]
a[2][2]
a[2,2]
a=np.array(data,dtype="U8,3int32,int32")
a
#第二种设置dtype的方式
data
type(data)
b=np.array(data,dtype=[("name","str_",8),
("scores","int64",3),
("ages","int32",1)#数字代表元素的个数
])
b
b["name"]
b['ages']
b["ages"][1]
b[0]
b
b["name"]
#取出ww的年龄
b
b[2]
b[2]["ages"]
b[2][2]
b[2,2]
class(b)
type(b)
b.shape
a.shape
type(b[2])
type(b[2][2])
#第三种设置dtype的方式
a=np.array(data,dtype={
"names":["name","scores",'age'],
"formats":["U8","int64","int32"] })
a
type(a)
a[1]
a[1][""age""]
a[1]['age']
a[1][1]
type(a[1]['age'])
type(a[1][1])
type(a)
a
a[1,1]
a[1:]
a[1:,]
a
import numpy as np
data=["2022-01-10","2012","2022-09",
"2022-10-01 10:10:00"]
data
a=np.array(data)
a
b=a.astype("M8[D]")
b.dtype
b[1] - a[1]
####ndarray 的维度
##视图变维(数据共享)view reshape() ravel()
#只是对原始数据的映射/投影。并没有单独的空间来存储原始数据
# a和b会互相影响
a=np.arange(1,10)
a
a.shape
b=a.reshape(3,3)
a
b
#很多方法会得到一个新的返回值,而不会改变原有数据
a.reshape(3,3)
print(a,"---->a")
a[0]
a[0]=999
a
print(b,"--------->b")
b.ravel()#抻平数组
c=b.ravel()
c
print(c,"------>c")
a
c[1]=53434
c
##复制变维(数据独立)fatten() 把数据撑平了
b
b.flatten()
d=b.flatten()
d
d[4]=10000
d
print(d,"------>d")
b
#就地变维 涂改直接改变当前数组的维度
c
c.shape=(3,3)
c.resize((9,))
c
c.data
#########ndarry 数组切片操作 二维数组的切片
a=np.arange(0,9)
a
a[1:5]
a[:3]
a[6:]
a[::-1]
a[:-4]
a
a[:-4:-2]
a
a[:-4:-1]
a[-4:-1]
a[::]
a[1:4]
a
##二维数组的切片
a.resize(3,3)
a
a[:2,:2]
a[::,::2]
a[:,:]
a[::2,::2]
a[[2]]
a[[1]]
a
a[0] #取第0行
a[[0,]]
a[[0,1]]#取第0行和第1行
a[[0,1,2]]
a[:]
a[:,]
a[:,:]
a[,::1]
a[::1,]
type(a[[2]])
a
a[[2]]
a
a[[1,2]]
a[[2,1]]
a=np.arange(0,201)
a.resize(100,2,refcheck=False)
a
a[::,0]
##ndarry数组的掩码操作
a=np.arange(0,10)
a
mask=[True,False]
import numpy as np
a=np.arange(1,100)
a
mask=a % 3==0
mask
a
a[mask]
#100以内 3和7的公倍数
a
mask=(a % 3==0) & (a % 7==0)
a[mask]
a
a.all()
#基于索引的掩码
names=np.array(["apple",
"mate30","ioeoij","FAs"])
names
rank=[0,1,3,2]
names[rank]
#多维数组的组合与拆分
scanpy annadata
step6 跟随视频学习pandas 干货有很多 但是我好像只学习了三分之二 因为感觉后面的东西不是自己需要的。主要学习了:pandas中的Series和dataframe结构。增删改查 切片操作 。index shape axis columns iloc loc属性 以及describe head 方法 我现在更需要实操 。在实战中锻炼这几天的学习内容。
第七天就开始学习python中anndata单细胞包
25.数据的排序_哔哩哔哩_bilibili25.数据的排序是【宝藏级】这是我看过的最好的Python基础Pandas教程!全程干货细讲,带你迅速掌握Pandas数据处理库的第25集视频,该合集共计42集,视频收藏或关注UP主,及时了解更多相关视频内容。 https://www.bilibili.com/video/BV1iK411f7PP?p=25&spm_id_from=pageDriver&vd_source=909d24b4b33e8977adc9d6ea868a6e4d
https://www.bilibili.com/video/BV1iK411f7PP?p=25&spm_id_from=pageDriver&vd_source=909d24b4b33e8977adc9d6ea868a6e4d
#https://www.bilibili.com/video/BV1iK411f7PP?p=20&spm_id_from=pageDriver&vd_source=909d24b4b33e8977adc9d6ea868a6e4d
#serise对象 属于pandas中的数据结构
import pandas as pd
data=["Afas","afdsa","wangwu"]
s=pd.Series(data=data,index=[1,2,3])
s
data=[12,324,12]
index=["zhangsan","lisi","wangwu"]
s=pd.Series(data,index)
s
#位置索引 取值 增删改
s[0]
s[1]
#根据index获取相对应的zhi
s["lisi"]
#获取多个标签所对应的值 【】里面使用列表来提取
s
s[ ["zhangsan","lisi"] ]
#切片索引
s[ 0:2:1 ]
#标签索引 切片
s["zhangsan":"lisi"]
s.index
type(s.index)
s.values
#dataframe
#既有行索引 又有列索引
DataFrame(data=None,
index: 'Axes | None' = None,
columns: 'Axes | None' = None,
dtype: 'Dtype | None' = None, copy: 'bool | None' = None) -> 'None'
#列表方式创建dataframe对象
data=[["xiaotaiyang",23,12],["afaf",31,12],["fa",12,12],]
columes=["mingcheng","danjia","shuliang"]
df=pd.DataFrame(data=data,columns=columes)
df
#字典方式创建dataframe对象
data={ "名称":["xiaotaiy","shubiao","xiaodao"],
"danjain":[320,321,132],
"数量":[34,24,24]}
pd.DataFrame(data)
data={"名称":["xiaotaiy","shubiao","xiaodao"],
"danjain":[320,321,132],
"数量":[34,24,24],
"公司名称":"chaoshi"}
pd.DataFrame(data)
#dataframe的属性
'''
values
dtypes
index
columns
T
head
tail
shape
info
'''
df.info
df
df.values
df.dtypes
df.index
list(df.index)
#修改行索引
df.index=[1,2,3]
df
#数据规整
pd.set_option('display.unicode.east_asian_width',True)
df.T
df
#
df.head
print (df.head)
df.head()
df.head(2)
df.tail()
#
df.shape
df.shape[0] #多少行
df.shape[1]
(3, 4,3)[2]
#查看索引 内存xinx
df.info
#dataframe中的重要函数
'''
describe 每列的汇总信息 dataframe类型
count 返回每一列的非空值个数
sum 返回每一列的和
max 返回每一列的最大值
min 返回每一列的最小值'''
data={"名称":["xiaotaiy","shubiao","xiaodao"],
"danjain":[320,321,132],
"数量":[34,24,24],
"公司名称":"chaoshi"}
pd.DataFrame(data)
df=pd.DataFrame(data)
df
#数据规整 数据格式整理数据清理
pd.set_option('display.unicode.east_asian_width',True)
df
df.describe()
df.count()
df.sum()
df
df.min()
##导入外部数据
#.xls .xlsx
import pandas as pd
?pd.read_excel(io,sheet_name,header)
pd.describe_option()
df=pd.read_excel(io="D:/Win10 System/Desktop/yll_version1/briefings in bioinformatics/Supplementary Table.xlsx",
header=None) #header=None
'''
.libPaths()
.libPaths(c("G:/silicosis/sicosis/gitto/python_study/renv/library/R-4.1/x86_64-w64-mingw32","C:/Users/yll/AppData/Local/Temp/RtmpErvVSx/renv-system-library" ,"G:/R_big_packages/","D:/Win10 System/Documents/R/win-library/4.1","C:/Program Files/R/R-4.1.0/library"))
'''
df.head()
type(df)
df.shape
df.keys()
df.keys
df.values
#导入指定的数据
#导入一列数据
df=pd.read_excel(io="D:/Win10 System/Desktop/yll_version1/briefings in bioinformatics/Supplementary Table.xlsx",
header=None,usecols=[1]) #header=None
df
df[1]
#导入多列
df=pd.read_excel(io="D:/Win10 System/Desktop/yll_version1/briefings in bioinformatics/Supplementary Table.xlsx",
header=None,usecols=[1,2]) #header=None
df
##读取csv文件
import pandas as pd
# 读取pandas内置的CSV数据
import pandas as pd
import io
# 读取pandas内置的CSV数据
##读取html文件
import pandas as pd
url="http://www.espn.com/nba/salaries"
df=pd.DataFrame()
df
#dataframe添加数据
df=df.append(pd.read_html(url, header=0 ))
'''
进入类似于conda的环境
1#创建python环境
renv::init()
'''
df
df.head()
#保存成csv文件
df.to_csv("nbasalrary.csv",index=False)
##数据提取 增删改删 切片抽取
df.head()
data=[[45,52,234],[234,43,2],[43,243,924] ]
index=["张三",'lisi',"wangwu"]
columns=["yuwen","shuxue","yingyu"]
df=pd.DataFrame(data=data,index=index,columns=columns)
df
pd.set_option('display.unicode.east_asian_width',True)
df
type(df)
#提取行数据
df.loc["lisi"]
df.iloc[0]
df.iloc[1]
df.iloc[:]
df.iloc[::]
df.iloc[::2]
#提取多行数据 谁和谁
df.loc[["lisi","wangwu"]]
df.iloc[1:3]
df
df.iloc[[1,2]]
df.iloc[1,2]
##提取联系多行数据 谁到谁 切片
df
df.loc["lisi":"wangwu"] #此时只有一对方括号 包含首尾
df.iloc[1:2] #使用索引时候 含头不含尾
df.iloc[1::]
df.iloc[1:]
df
df.iloc[::2]
df.iloc[::-1]
df.iloc[:1]
df.iloc[:2]
#抽取想要的列
data=[[45,52,234],[234,43,2],[43,243,924] ]
index=["张三",'lisi',"wangwu"]
columns=["yuwen","shuxue","yingyu"]
df=pd.DataFrame(data=data,index=index,columns=columns)
df
pd.set_option('display.unicode.east_asian_width',True)
df
type(df)
df.columns
df["yuwen"]
df
df.iloc[0:2]
#提取列数据时候 可以直接使用列名提取 而行不可以
#行必须使用loc参数才可以
#提取多列数据 直接使用列名提取
df
df[["shuxue","yuwen"]]
df
#提取所有行的数学和语文
df.loc[::,["shuxue","yuwen"]]
df.loc[:,["shuxue","yuwen"]]
df.iloc[:,[0,2]]
#提取连续的列
df.iloc[:,1:2]
##提取区域数据
#张三的数学
df
df.loc["张三","shuxue"]
type(df.loc["张三","shuxue"])
#张三wangwu的yuwen和shuxue成绩
df.loc[["张三","wangwu"],["yuwen","shuxue"]]
df
df.loc["张三":"wangwu","yuwen":]
df.iloc[0:2,:]
df.iloc[0:2,::]
df.iloc[0:2,::2]
#提取非连续的数据
df.iloc[[0,2],:]
df
df[:,[0,2]]
df.loc[:,["shuxue","yingyu"]]
df[["shuxue","yingyu"]]
#提取满足条件的数据
df
#提取语文大于60的数据
df.describe()
df
df["yuwen"]
df["yuwen"]>60
#df.loc[::,df["yuwen"]>60]
df
#提取语文成绩》60的所有学生信息
df.loc[df["yuwen"]>60]
#语文和数学都大于60de
df
df.loc[:]
df.iloc[0:2]
df
df.loc[df["yuwen"]>60]
#多个判断需要括号括起来
df.loc[(df["yuwen"]>60) & (df["shuxue"]<60)]
###############3数据的增 修 删 改
columns=["yuwen","shuxue","yingyu"]
index=["张三",'lisi',"wangwu"]
data=[[45,52,234],[234,43,2],[43,243,924] ]
df=pd.DataFrame(data=data,index=index,columns=columns)
df
##增加列数据
df
#直接赋值的方式 增加一列政治chengji
df["zhengzhi"]=[34,242,1321]
df
df.tail()
#使用loc属性,在dataframe的最后一行增加
df.shape
df.loc[:,"maogai"]=[34,423,22]
df
#在指定位置插入数据 insert
lst=[123,312,3312]
df.insert(1,"历史",lst) #在索引为1的列上添加 历史 列内容为:lst
df
##########按行增加数据
import numpy as np
df.loc["lisi"]
df
df.loc["陈六"]=list(np.arange(0,6))
df
#增加多行数据
#新建一个dataframe
df
new_dataframe=pd.DataFrame(
index=["zhaoqian","sunli"],
columns=list(df.columns),
data=[list(np.arange(0,6)),
list(np.arange(6,12))]
)
new_dataframe
df
df.append(new_dataframe) #append 追加行
df
lst=[123, 312, 3312]
lst
lst.append(342)
lst
lst.shape
ary=np.array(lst)
ary
ary.shape
ary.shape=(2,2)
ary
ary[:,]
ary[:,::]
columns=["yuwen","shuxue","yingyu"]
index=["张三",'lisi',"wangwu"]
data=[[45,52,234],[234,43,2],[43,243,924] ]
df=pd.DataFrame(data=data,index=index,columns=columns)
df
############修改数据
#修改列标题
df
#修改语文
df["yuwen"]="语文" #这样是修改yuwen这一列的内容,而不是改列标题
#改yingyu列标题
df.columns
df
lst="yuwen 历史 shuxue yingyu zhengzhi maogai".split()[::-1]
lst
lst[::-1]
df.columns="yuwen 历史 shuxue yingyu zhengzhi maogai".split()[::-1]
df
df.index
#rename
df
df.rename(columns={"maogai":"maogai(上)"})
df
#加上inplace参数,直接修改dataframe
df.rename(columns={"maogai":"maogai(上)"},inplace=True)
df
#修改行标题 也就是修改行名
#直接赋值
list('1234')
df
df.index=list('1234')
df
#有点像设置索引的方法
#rename方法 可以修改任意行名和列名 需要通过字典来指定新的名字
df.rename({"1":"11",
"2":["fadsa,afd"]},inplace=True,axis=0)
df
###修改数据内容
#修改一整行数据
columns=["yuwen","shuxue","yingyu"]
index=["张三",'lisi',"wangwu"]
data=[[45,52,234],[234,43,2],[43,243,924] ]
df=pd.DataFrame(data=data,index=index,columns=columns)
df
df.loc["lisi"]=100
df
df.loc["lisi"]=[19,2,423]
df
df.loc["lisi",:]
df
df.loc["lisi",:]=100
df
df.loc["lisi",:]=list("432")
df
df.iloc[1]=100
df
df.iloc[1,:]
df
df.iloc[1,:]=list("123")
df
##修改列数据
df
df["yuwen"]=100
df
df.loc[:,"yuwen"]
df
df.loc[:,"yuwen"]=list("!23")
df
#修改某一处 比如 修改lisi的yuwen成绩
df
df.loc["lisi","yuwen"]
df.loc["lisi","yuwen"]=100
df
df.iloc[1,0]=1000
df
###删除数据 axis 0表示行 1 表示列
#drop参数说明
#有点像设置索引的方法
labels 行或者列标签
axis
index
columns
inplace
columns=["yuwen","shuxue","yingyu"]
index=["张三",'lisi',"wangwu"]
data=[[45,52,234],[234,43,2],[43,243,924] ]
df=pd.DataFrame(data=data,index=index,columns=columns)
df
#删除数学列 删除 去除 去掉
df.drop(["shuxue"],axis=1)
df
df.drop(labels=["shuxue"],axis=1)
#
df.drop(columns=["shuxue"])
df
#
df.drop(labels="shuxue",axis=1)
df
df.drop(["shuxue"],axis=1,inplace=True)
df.drop()
##删除行
df
df.drop(["lisi"],axis=0) #顺序反了也不行
df.drop(axis=0,["lisi"])
df
df.drop(axis=0,labels=["lisi"],inplace=True)
df
df.drop(index="lisi")
df.drop(index="lisi",axis=0)
df.drop(index="lisi",axis=0,inplace=True)
df
df.drop()
##带条件的删除
columns=["yuwen","shuxue","yingyu"]
index=["张三",'lisi',"wangwu"]
data=[[45,52,234],[234,43,2],[43,243,924] ]
df=pd.DataFrame(data=data,index=index,columns=columns)
df
df
df["shuxue"]
df.loc[:,"shuxue"]
df
df.loc["lisi"]
df.loc["lisi",]
df.loc["yuwen"]
df
df.loc[:,'yuwen']
df.loc[,"yuwen"] #行中的冒号不可以省略,列中的切片可以省略
#删除数学<60分的数据
df["shuxue"]<60
df
df["shuxue"]>60
#也就是取出数学>60的行
df.loc[df["shuxue"]>60,:]
#<60
df.index
df[df["shuxue"]<60]
df.loc[df["shuxue"]<60,]
df[df["shuxue"]<60].index
df[df["shuxue"]<60].index[0]
df
df.drop(df[df["shuxue"]<60].index[0],axis=0)
#删除数学<60分的数据
df["shuxue"]<60
(df["shuxue"]<60).index
df[df["shuxue"]<60]
df[df["shuxue"]<60].index
df.drop(index=df[df["shuxue"]<60].index,axis=0)
df
###数据清洗qingchu
##python清除所有变量_如何清空python的变量
for key in list(globals().keys()):
if not key.startswith("__"):
globals().pop(key)
import pandas as pd
df=pd.read_csv("nbasalrary.csv",header=None)
df
df.head()
pd.set_option("display.unicode.east_asian.width",True)
df.loc[1:5,1:5]
df.index
df.columns
df
df.loc[1,:]
df.columns=df.loc[1,:]
df.head()
df.columns
df.index
type(df)
df.shape
df[[0,1]]
#查看是否有缺失值
df.info
df.info()
###判断是否有缺失值 true就表示是缺失值naa
df.isnull()
df.notnull() #不为缺失值就为true
#缺失值的处理方式
#删除缺失值
df.dropna()
df.dropna(inplace=True)
df
df.shape
#
df=pd.read_csv("nbasalrary.csv",header=None)
df
df=df.loc[:,:3]
df.head()
df.isnull()
df.isnull().info()
df.isnull().describe()
df.describe()
df
df.shape
df.columns=df.loc[1,]
df
df.dropna(inplace=True)
df
df.shape
df.columns
df.loc[3,:]=['None',None,bool('null'),"fdsa"]
df.loc[4,:]=[None,'afda',None,'fda']
df.head()
df.dropna()
df.notnull()
df["NAME"].notnull()
df.head()
#提取NAME中不为nan的数据
df["NAME"].notnull
df["NAME"].notnull()
df["NAME"].isna
df["NAME"].isna()
df.head()
df.loc[df["NAME"].notna(),:]
#填充na fillna
df
df=pd.read_csv("nbasalrary.csv",header=None)
df.columns=df.loc[1,]
df
##把所有的缺失值填充为o0
df
df.loc[:,:].fillna(0)
df
##重复值的处理
#判断是否有重复值
df.duplicated()
#去除全部的重复值
df.shape
df
df.drop_duplicates()
#去除指定列的重复数据
df=df.drop_duplicates(["NAME"])
df.shape
#去除指定列的重复数据 保留重复行中的最后一行
df.columns
df.drop_duplicates(['TEAM'])
df
df=df.drop_duplicates("TEAM",keep='last')
df
#直接删除 保留一个副本
df
df.drop_duplicates(["RK"],inplace=True)
df
df1=df.drop_duplicates(['TEAM'],inplace=False)
df1
df
############异常值的检测和处理
###pandas索引设置
#如果索引是唯一的,pandas会使用哈希表优化
#如果索引不是唯一的,但是有序, 使用二分查找算法
#如果索引是完全随机的,那么每次查询都需要扫描数据表
import pandas as pd
s1=pd.Series([19,12,132],
index=["a","b","c"])
s1
s2=pd.Series([19,12,132],
index=["a","b","c"])
s2
print(s1+s2)
##重新设置索引
reindex(labels=None, index=None, columns=None,
axis=None, method=None, copy=None,
level=None, fill_value=nan, limit=None, tolerance=None)
s=pd.Series([11,2,3,333],index=list("abcd"))
s
s.reindex(list("fsas"))
s=pd.Series([11,2,3,333],index=list("1234"))
s
s.reindex(list("23541"))
s=pd.Series([11,12,3234],index=[1,22,3])
s
type(s)
#重新设置索引
s
print(range(1,8))
s.reindex(range(1,6)) #多出来的为nan
print(s.reindex(range(1,7)))
#使用o进行填充
print(s.reindex(range(1,7),fill_value=0))
s=s.reindex(range(1,8),fill_value=5)
s
#向前填充和向后填充
s
s.shape
s.reindex(range(1,10))
s.reindex(range(1,9),method="ffill") #向前填充
s.reindex(range(1,11),method="bfill")#向后填充
#dataframe对象重新设置索引
data=[[12,132,13],[23,23,432],[34,24,63]]
data
index=["heng1",'heng2',"heng3"]
index
columns=["c1","c2","c3"]
columns
df=pd.DataFrame(columns=columns,
index=index,
data=data)
df
pd.set_option("display.unicode.east_asian_width",True)
df
#重新设置索引
#设置行索引
import numpy as np
df
df.index
df.reindex(np.array((1, 2, 3,'heng1', 'heng2', 'heng3')))
df.reindex(['heng1', 'heng2', 'heng3',333,113])
df.index
df.index[1]
df.loc[0]
df
df.iloc[0]
df.iloc[1]
df
df.iloc[0,:]
#重新设置列索引
data=[[12,132,13],[23,23,432],[34,24,63]]
data
index=["heng1",'heng2',"heng3"]
index
columns=["c1","c2","c3"]
columns
df=pd.DataFrame(columns=columns,
index=index,
data=data)
df
df
df.columns
df.reindex(columns=['c1', "fas",'c2', 'c3'])
#有点像df.drop() 删除某行或者哪些列
##同时设置 行索引和列索引
df.index
df.columns
df.reindex(index=['heng1',"fasa", 'heng2', 'heng3'],
columns=['c1',"fas", 'c2', 'c3'])
df.reindex(index=['heng1',"fasa", 'heng2', 'heng3'],
columns=['c1',"fas", 'c2', 'c3'],
fill_value=0)
#设置某行或某列为索引
set_index(keys, *, drop: 'bool' = True,
append: 'bool' = False, inplace:
'bool' = False,
verify_integrity: 'bool' = False) -> 'DataFrame | None'
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale': [55, 40, 84, 31]})
df
#设置某列为行索引
df
df.shape
df.set_index("month") #,inplace=True
df.set_index("month").index
df
df.shape
df.index
#创建多个行索引
df
df.set_index(['year', 'sale'])
df.set_index(['year', 'sale']).index
##设置某行为列索引
set_axis(labels, *, axis: 'Axis' = 0,
inplace: 'bool | lib.NoDefault' = <no_default>,
copy: 'bool | lib.NoDefault' = <no_default>)
df
df.index
df
df.set_axis(labels=df.loc[3,:],axis=1)
df.set_axis(labels=df.loc[3,:],axis="columns")
#Create a MultiIndex using an Index and a column:
df
df.index
df.set_index(df.index)
df.index
pd.Index([1, 2, 3, 4])
df.set_index([pd.Index([1, 2, 3, 4]), 'year'])
df.set_axis()
#数据清洗之后设置索引
df
df.reindex(np.arange(0,8),fill_value=9)
df=df.reindex(np.arange(0,6),method="ffill")
df.columns
df=df.reindex(columns=['month', "fsa",'year', 'sale'])
df
df = pd.DataFrame([('bird', 389.0),
('bird', 24.0),
('mammal', 80.5),
('mammal', np.nan)],
index=['falcon', 'parrot', 'lion', 'monkey'],
columns=('class', 'max_speed'))
df
#重新设置索引之后 旧索引默认变成索引列
df.reset_index()
df
#drop参数可以避免旧索引变成新的列
df.reset_index(drop=True)
df
df.dropna()
df.dropna().reset_index()
df.dropna().reset_index(drop=True)
index = pd.MultiIndex.from_tuples([('bird', 'falcon'),
('bird', 'parrot'),
('mammal', 'lion'),
('mammal', 'monkey')],
names=['class', 'name'])
columns = pd.MultiIndex.from_tuples([('speed', 'max'),
('species', 'type')])
df = pd.DataFrame([(389.0, 'fly'),
( 24.0, 'fly'),
( 80.5, 'run'),
(np.nan, 'jump')],
index=index,
columns=columns)
df
df.index
df.columns
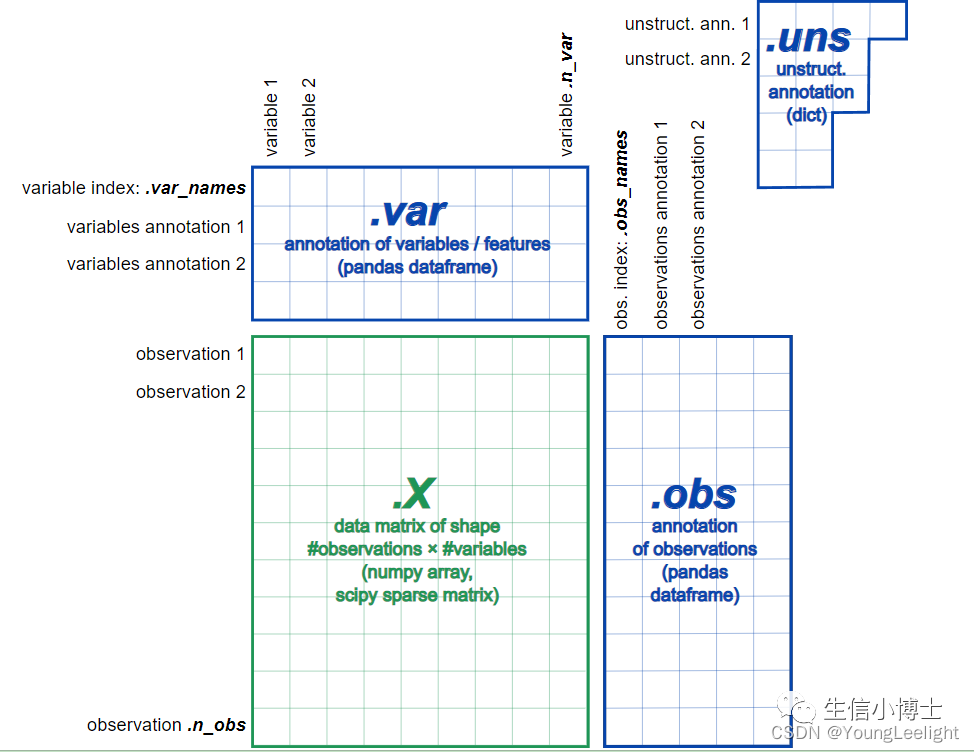
step7第七天 anndata学习 这个官网教程太给力了,我用的是Linux服务器 安装了conda环境 使用 ipython进行学习。主要是实操,anndata其实是numpy和pandas的升级版,其操作很多都是基于numpy和pandas以及基本的python数据结构的。主要属性:X, obs, var , obs_names, var_names.
Getting started with anndata — anndata 0.9.0.dev37+g312e6ff documentation必看入门anndata
anndata for R • anndata anndata与R
covid19已经出圈了anndata - Annotated data — anndata 0.9.0.dev37+g312e6ff documentation
COVID-19 Cell Atlas