API 的调用稳定性被视为数据服务的最重要的指标。该指标的影响因素是多种多样的,「袋鼠云数据服务平台 DataAPI」不仅多次对于调用性能和稳定性进行压测和调优,而且还提供了多种配置项优化手段供客户进行自行调优。但是当遇到不可预期的大流量或其他突然情况时还是会遇到 API 调用失败的情况。
当随着流量的不断增长,达到或超过服务本身的可承载范围,系统服务的自我保护机制的建立就显得很重要了。「袋鼠云数据服务平台 DataAPI」将 API 调用和微服务流量控制概念相结合,推出了熔断降级功能,最大程度保证 API 调用的稳定性和系统可用性。
本文希望可以用最通俗的解释和贴切的实例带大家了解什么是熔断降级。
熔断降级概述
一般提到微服务系统流量保护,都会提起限流、熔断、降级三种手段,其实他们都是系统容错的重要设计模式。
限流、熔断、降级
● 限流
限流是一种对系统被请求频率以及内部部分功能的执行频率进行限制的措施,防止因突发的流量激增,导致整个系统不可用。限流主要是防御保护手段,从流量源头开始控制流量、规避问题。
● 熔断
熔断机制是一种自动化的应对措施,当流量过大或下游服务出现问题时,可以自动断开与下游服务的交互,以防止故障的进一步扩散。同时,熔断机制还可以自我诊断下游系统的错误是否已经修正,或者上游流量是否减少至正常水平,以实现自我恢复。
熔断更像是自动化补救手段,可能发生在服务无法支撑大量请求或服务发生其他故障时,对请求进行限制处理,同时还可尝试性的进行恢复。
● 服务降级
主要是针对非核心业务功能,而核心业务如果流程超过预估的峰值,就需要进行限流。降级一般考虑的是分布式系统的整体性,从源头上切断流量的来源。降级更像是一种预估手段,在预计流量峰值前提下,提前通过配置功能降低服务体验,或暂停次要功能,保证系统主要流程功能平稳响应。
熔断降级
限流和熔断也可以看作是一种服务降级的手段。微服务架构下,服务和服务之间的调用通常关注的是流量,开发者需要从流量路由、流量控制、流量整形、熔断降级、系统自适应过载保护、热点流量防护等多个维度来保障微服务的稳定性。其中熔断降级更趋向于在微服务调用链路中保障重点链路或者重点服务的稳定性。
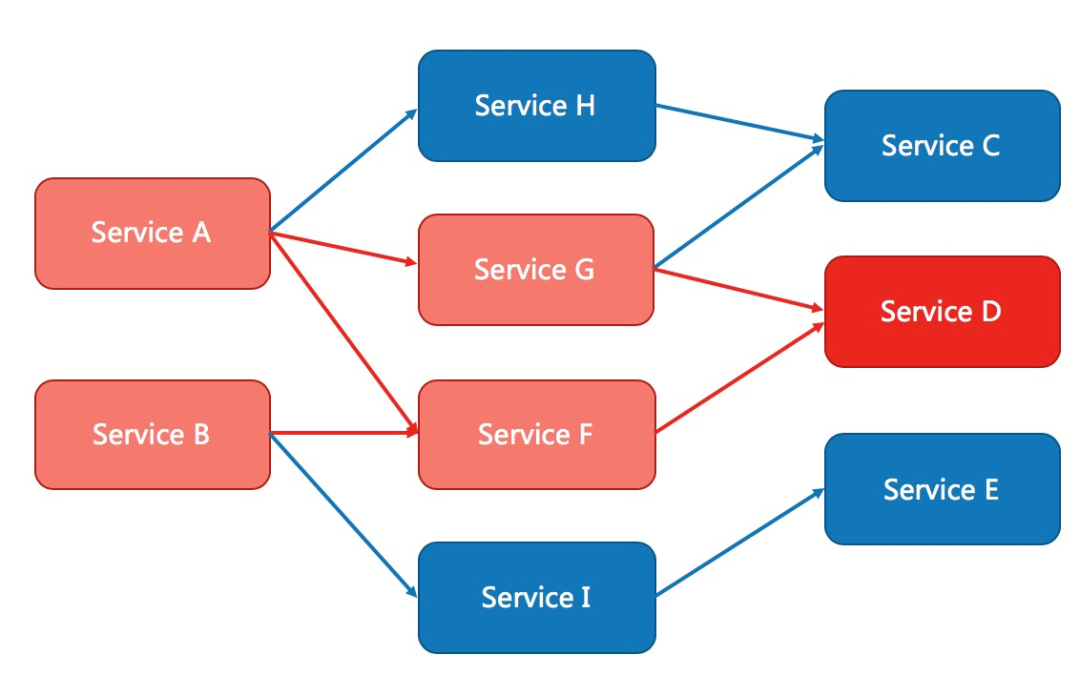
如下图,当 serviceD 发生异常不可用时会影响到 serviceA、B、G、F,如不加以管控,最终可能会导致整个微服务全部瘫痪。熔断要做的事情就是达到某个错误阈值后停止再调用 serviceD 服务;降级则会返回开发者自定义的降级内容,至少保证链路的整体可用。
熔断规则介绍
「袋鼠云数据服务平台 DataAPI」目前提供三种熔断策略,每个 API 可以且仅可关联一个熔断策略,策略类型分别为:
● 慢调用比例(SLOW_REQUEST_RATIO)
选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。
经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。
● 异常比例(ERROR_RATIO)
当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。
经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
● 异常数(ERROR_COUNT)
当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
DataAPI 对于熔断降级的应用
接下来通过实例为大家介绍熔断降级在「袋鼠云数据服务平台 DataAPI」内的应用。
熔断
数据服务的熔断降级是基于 Sentinel 框架实现的。Sentinel 对于资源的定义更偏向于服务级别,不过也提供了对于指定代码或内容进行资源定义。所以 DataAPI 是通过定义 APIID 作为唯一资源来进行熔断阈值的判断和具体熔断动作的实施。同时,通过控制资源名称的生成规则,测试 API 和正式 API 实现了环境隔离。

在开发实现的过程中,最大的难点在于 Sentinel 原生支持限流策略的集群控制,但是不支持熔断策略的集群控制。DataAPI 采用的方法是采用主节点的方式去实现集群的控制,主要有以下两点内容。
● 熔断规则如何只加载到主节点上
首先,熔断策略基于内存是通过 DegradeRuleManager 加载的,既然是基于内存那么必然要做持久化动作,否则程序重启规则就会清空。这里采用了 MySQL 建立熔断规则表的方式进行规则详情的修改操作。
其次启动时通过 nacos 获取 gateway 实例列表并选取主节点,调用 nacos 的 namingService.getAllInstance 方法可以获取到所有的 gateway 实例。选取第一个健康的 gateway 实例为主节点,将主节点 ip 信息以 key value 的形式存储到 redis 中,主节点重新选举时会更新此 redis key,gateway 集群所有实例每次启动先判断当前节点是否为主节点,只有主节点才会进行熔断策略的初始化加载动作。
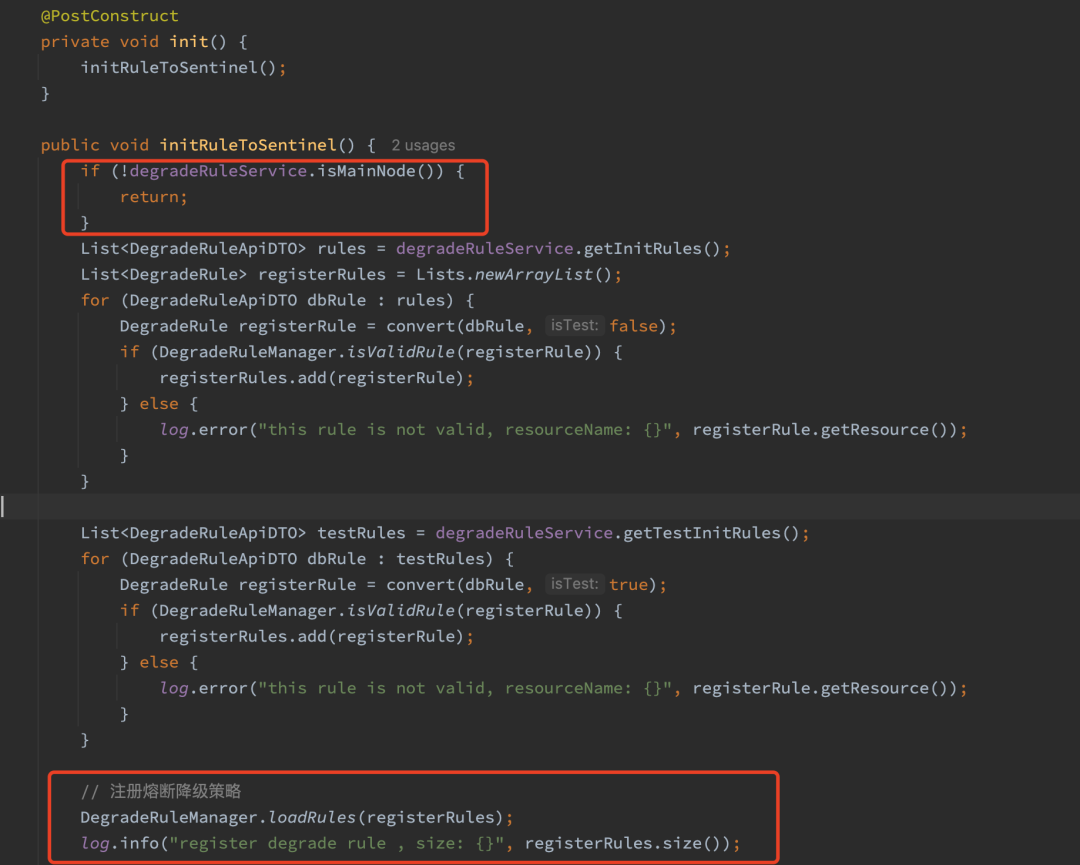
这里针对主节点的选举 DataAPI 是做了自动选举的,即使当前主节点宕机,也可以通过每分钟一次的定时器获取到存活的节点实例并重新选取主节点,保证高可用。当主节点发生变更后也会发送 redis 通知给到所有节点,新的主节点收到通知后会从 MySQL 获取当前最新的熔断策略加载进内存,不过此动作会清空之前的流量统计,时间窗口会重置。
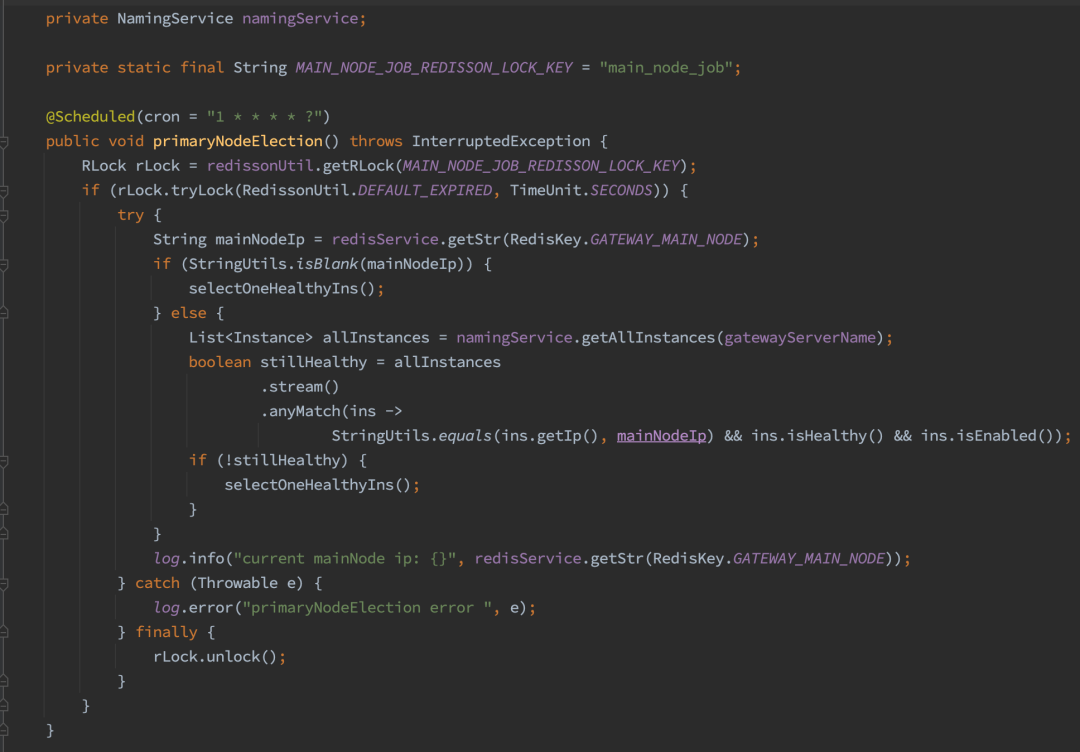
最后,策略的修改如何同步到主节点。数据服务采用的是 redis channel 通知的方式,每台 gateway 都监听 channel 消息,只有判断当前节点为主节点的 gateway 才进行内存规则的 load 操作。
● 集群阈值判定
通过主节点进行规则加载和阈值判断,集群所有示例都正常执行 API 请求,只有阈值判断会发起 http 请求到主节点进行判断,并返回是否通过结果,整体工作流程图如下:
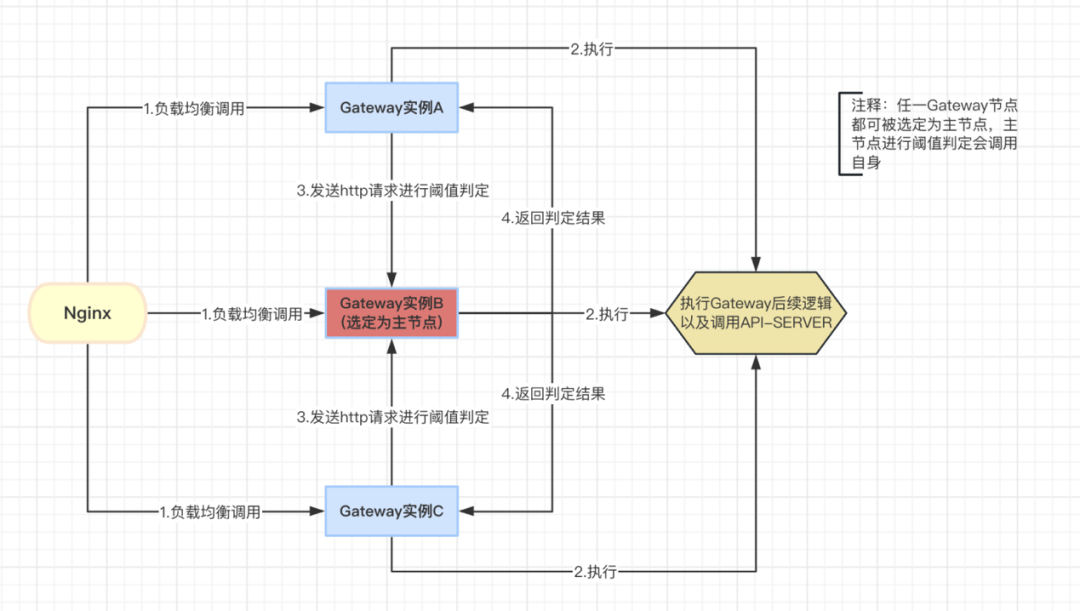
阈值判定一共分为两种模式:
· 错误模式,也可细分为错误数或者错误率
· 慢调用模式,指慢调用请求占比
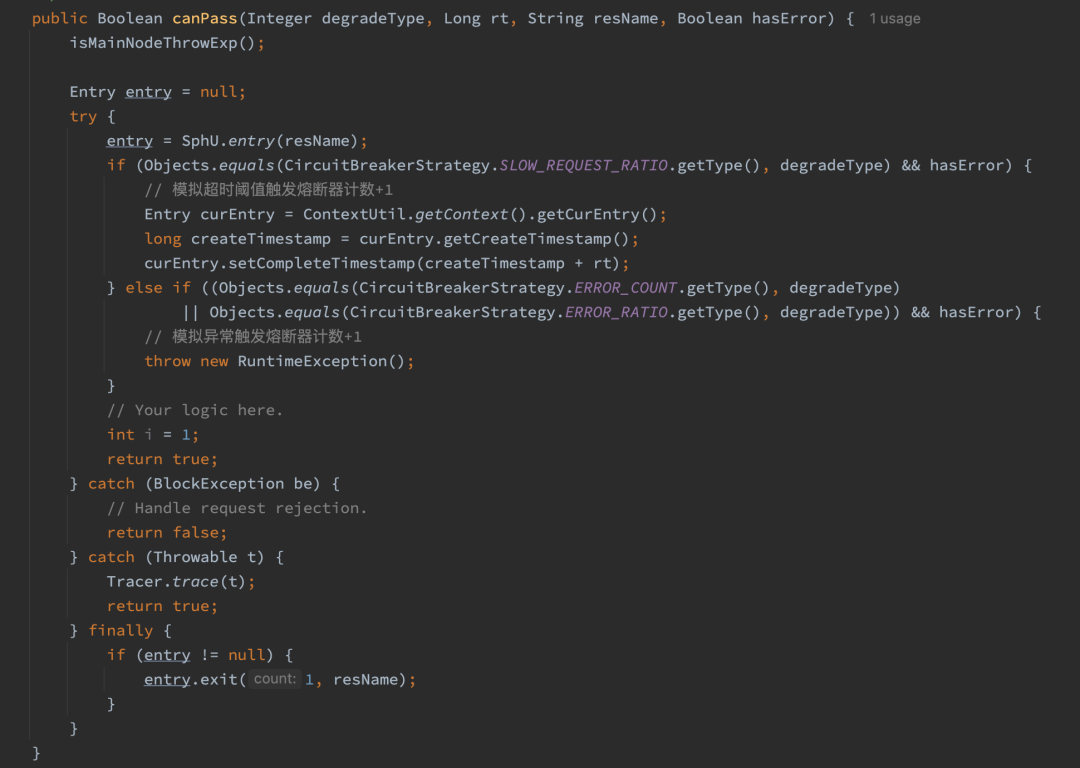
由于判断主节点为实例B,但是错误发生在实例A/C,所以在实例B是需要手动去产生异常或者慢调用的。当节点请求发生异常后主节点收到异常标志位,则手动抛出异常,这时候 Sentinel 是可以感知的并且异常数会加一。慢调用则是通过修改请求的 complateTime 让计数器能够判断到慢调用来实现。
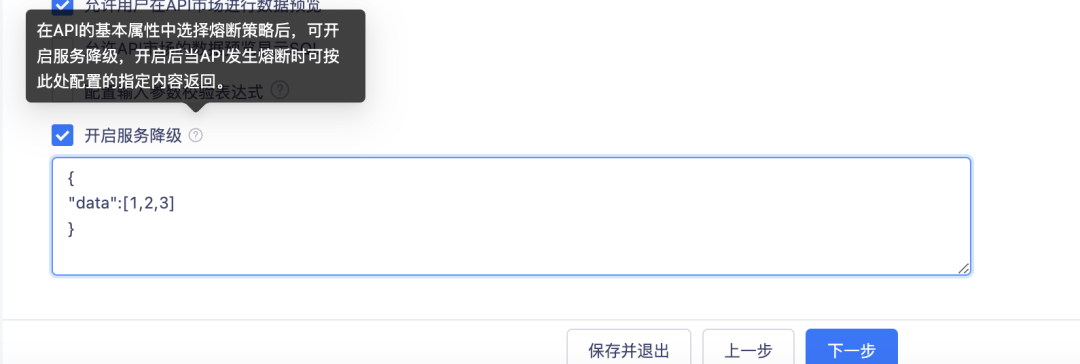
降级
用于可在 API 编辑页面进行降级内容的配置,配置条件为需先配置熔断策略,当熔断器处于开启状态时 gateway 会返回完全由用户自定义的降级内容,该内容必须为 json 格式。
降级最主要解决的是资源不足和访问量增加的矛盾,在有限的资源情况下,可以应对高并发大量请求。尤其当 API 配置被访问的数据源无法承载大流量时,在有限的资源情况下,想要达到以上效果就需要对一些服务功能进行一些限制但是又不是完全的不可用状态,系统将返回预设的值,保证整个系统能够平稳运行。
降级的代码实现相对简单,判断条件生效后,通过重写 ServerWebExchange 对象的 Response 即可。
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
IntelliJ IDEA 2023.3 & JetBrains 全家桶年度大版本更新 新概念“防御性编程”:让自己稳拿铁饭碗 GitHub.com 跑了 1200 多台 MySQL 主机,如何无缝升级到 8.0? 周星驰 Web3 团队下个月上线独立 App Firefox 会被淘汰吗? Visual Studio Code 1.85 发布,浮动窗口 余承东:华为明年将推出颠覆性产品,改写行业历史 美国 CISA 建议放弃 C/C++,消除内存安全漏洞 TIOBE 12 月:C# 有望成为年度编程语言 雷军 30 年前写的论文:《计算机病毒判定专家系统原理与设计》