原文:https://blog.csdn.net/laoyang360/article/details/77623013
Elasticsearch中当我们设置Mapping(分词器、字段类型)完毕后,就可以按照设定的方式导入数据。有了数据后,我们可以对数据进行检索。
检索概览
检索子句的行为取决于查询应用filter还是query, filter对应于结构化检索,query对应于全文检索。
GET /_search
{ "query": { "bool": { "must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
], "filter": [
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}
}
}
以检索,title中包含“Search”并且content中包含“Elasticsearch”,status中精确定匹配published,并且publish_date大于2015-01-01的全部信息。
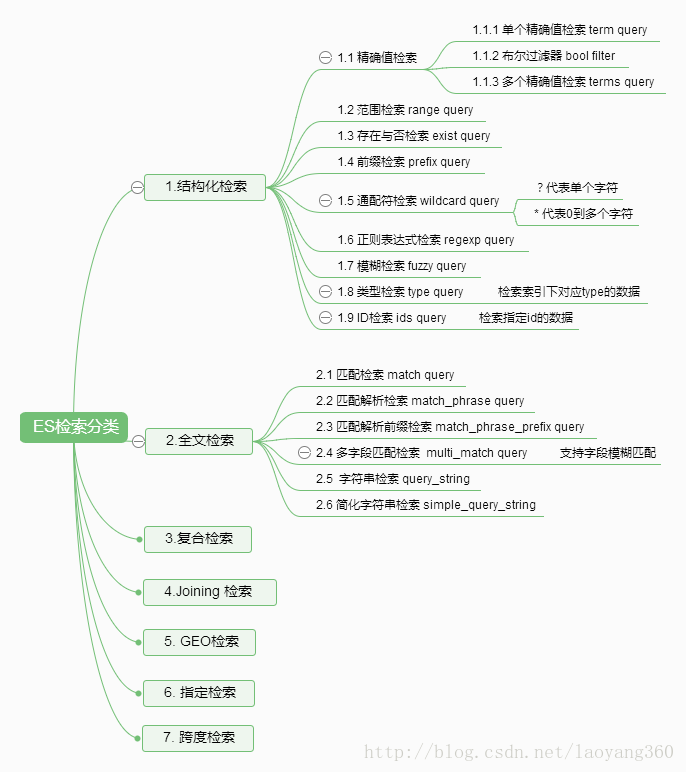
1.结构化检索
针对字段类型:日期、时间、数字类型,以及精确的文本匹配。结构化查询得到的结果要么存在于集合中,要么存在集合外,不关心文件的相关度或评分,它简单的对文档包括或排除处理。
(1)精确值查找
- term query
term查询会查找我们指定的精确值,它接受一个字段名以及我们希望查找的数值 。
想要类似mysql中如下sql语句的查询操作:
SELECT document FROM products WHERE price = 20;
DSL写法:
GET /my_store/products/_search
{
"query" : {
"term" : {
"price" : 20
}
}
}
- 布尔过滤器
一个bool过滤器由三部分组成:
{
"bool" : {
"must" : [],
"should" : [],
"must_not" : [],
"filter": []
}
}
must:所有语句都必股友匹配,与AND等价
must_not:所有的语句都不能匹配,与NOT等价
should:至少有一个语句要匹配,与OR等价
filter:必须匹配
GET /my_store/products/_search
{
"query" : {
"filtered" : {
"filter" : {
"bool" : {
"should" : [
{ "term" : {"price" : 20}},
{ "term" : {"productID" : "XHDK-A-1293-#fJ3"}}
],
"must_not" : {
"term" : {"price" : 30}
}
}
}
}
}
}
- 多个值精确查找
{
"terms" : {
"price" : [20, 30]
}
}
包含20或者含30.
(2)范围检索
gt: > 大于(greater than) lt: < 小于(less than) gte: >= 大于或等于(greater than or equal to) lte: <= 小于或等于(less than or equal to)
类似于Mysql中的范围查询
SELECT document FROM products WHERE price BETWEEN 20 AND 40
ES中对应的DSL如下:
GET /my_store/products/_search
{
"query" : {
"constant_score" : {
"filter" : {
"range" : {
"price" : {
"gte" : 20,
"lt" : 40
}
}
}
}
}
}
(3)存在与否检索
mysql中,有如下sql
SELECT tags FROM posts WHERE tags IS NOT NULL;
ES中,exist查询某个字段是否存在:
GET /my_index/posts/_search
{
"query" : {
"constant_score" : {
"filter" : {
"exists" : { "field" : "tags" }
}
}
}
}
若想要exists查询以匹配null类型,需要设置mapping
"user": {
"type": "keyword",
"null_value": "_null_"
(4)前缀检索
GET /_search
{ "query": {
"prefix" : { "user" : "ki" }
}
}
(5)通配符检索
为了防止查询慢,通配符不能以任何一个通配符*或?开头。
GET /_search
{
"query": {
"wildcard" : { "user" : "ki*y" }
}
}
(6)正则表达式检索
GET /_search
{
"query": {
"regexp":{
"name.first": "s.*y"
}
}
}
(7)模糊检索
在指定的最大编辑距离内的所有可能的匹配项,然后检查术语字典,以找出在索引中实际存在待检索的关键字。
GET /_search
{
"query": {
"fuzzy" : { "user" : "ki" }
}
}
(8)类型检索
GET /my_index/_search
{
"query": {
"type" : {
"value" : "xext"
}
}
}
检索索引my_index中,type为xext的全部信息。
(9)Ids检索
GET /my_index/_search
{
"query": {
"ids" : {
"type" : "xext",
"values" : ["2", "4", "100"]
}
}
}
2全文检索
(1)匹配检索
匹配查询接受文本、数字、日期类型,分析它们,并构造查询。
- 匹配查询的类型为boolean,这意味着分析所提供的文本,并且分析过程从提供的文本构造一个布尔查询。
- 文本分析取决于mapping中设定的analyzer(默认是ik分词器)
GET /_search
{
"query": {
"match" : {
"message" : {
"query" : "this is a test",
"operator" : "and"
}
}
}
}
(2)匹配解析检索
类似match查询,match_phrase查询首先将查询字符串解析成一个词项列表,然后对这些词项进行搜索,但只保留那么包含全部搜索词项。
GET /my_index/my_type/_search
{
"query": {
"match_phrase": {
"title": "quick brown fox"
}
}
}
(3)匹配解析前缀检索
match_phrase_prefix与match_phrase相同,除了它允许文本中最后一个术语的前缀匹配。
GET / _search
{
“query”:{
“match_phrase_prefix”:{
“message”:“quick brown f”
}
}
}
(4)多字段匹配检索(暂时不理解)
multi_match查询为能在多个字段上反复执行相同查询提供了一种便捷方式。
(5)字符串检索(暂时不理解)
(6)简化字符串检索(暂时不理解)