一、泛型
1、啥叫泛型?
泛型是java5新增的语法糖。这种技术可以把编译期发生的错误提到运行期,很大程度上提升编码效率。
默认情况下向集合中添加的类型元素都是被当做Object类型处理,当程序从集合中取出对象后,就需要进行强制类型转换,这种强制类型转换不仅使代码臃肿,而且容易引起ClassCastExeception异常。然而这个异常在编译期是没有任何问题的,会编译通过。但是在运行期就抛出异常了。通过引入泛型这个语法,使编译期间限制添加元素的类型,避免了类型转换的出现。
2、泛型的通配符 < ? > 与类型形参变量Class < T >{}的区别?
-
通配符<?>是类型实参而不是类型形参
-
List<?>在逻辑上是List、List<具体类型实参>的父类,它的使用比类型形参T更加灵活。
-
传入的通配符通常进行的是许多于具体类型无关的操作,如果涉及到具体类型相关的操作,以及返回值,还是需要使用泛型方法T。
//虽然Object是所有类的基类,但是List<Object>在逻辑上与List<Integer>等并没有继承关系,
//这个方法只能传入List<Object>类型的数据
public static void showOList(List<Object> list){
System.out.println(list.size());
}
//同理,这个方法只能传入List<Number>类型的数据,并不能传入List<Integer>
public static void showList(List<Number> list){
System.out.println(list.size());
}
//使用通配符,List<?>在逻辑上是所有List<Number>,List<Integer>,List<String>……的父类,
//可以传递所有List类型的数据,但是不能在List<?>类型的数据进行于具体类型相关的操作,如add
public static void showList2(List<?> list){
System.out.println("<?>");
System.out.println(list.size());
}
//设置通配符上限,可以传入List<Number及Number的子类>
public static void showNumList(List<? extends Number> list){
System.out.println(list.size());
}
//设置通配符下限,List<? super Number>只可以传入List<Number及其父类>
public static boolean Compare(List<? super Number> list1,List<? super Integer> list2){
return list1.size()>list2.size();
}
3、了解泛型的擦除吗?为什么要类型擦除?类型擦除带来的副作用?
泛型擦除:
java的参数化类型信息只存在于编译阶段。在编译过程中,javac编译器正确检验泛型结果后,会将泛型的相关信息擦除,并且在对象进入和离开方法的边界处添加类型检查和类型转换的方法,也就是说,泛型信息不会进入到运行期。
为啥需要泛型擦除:
为了向下兼容,泛型是java5出现的语法,在此之前都是没有范型的。当时引入范型主要是为了解决遍历集合的时候总要手动强制转型的问题。把运行期容易引发的异常提升到编译期。为了让JVM保持向下兼容,就出了类型擦除这个下下策。
类型擦除的后果:
- 还是有可能出现ClassCastException的风险。因为带泛型类型的变量和原始类型的变量之间是可以相互赋值的而且不会编译报错这样就容易引起ClassCastException。
public static void main(String[] args) {
List<Integer> integerList = new ArrayList<>(); //带泛型类型的变量
integerList.add(1);
List rawList = integerList; //rawList 原始类型的变量
List<String> stringList = new ArrayList<>(); //带泛型类型的变量
stringList = rawList; //编译时只会警告,但通过
System.out.println(stringList.get(0)); //运行时java.lang.ClassCastException
}
- 方法签名可能冲突
// 编译后后T被还原为原始的Object类型。编译后的方法可以看做和下面的方法一样。
// 注意泛型擦除的疑惑点,这里编译后方法签名信息还是会保留到class文件中的,方法体中的语句与泛型相关的都被擦除。在
// 编译期间自动添加强制类型转化。
public boolean test(T t) {
return true;
}
public boolean test(Object object) {
return true;
}
- 泛型实参类型不支持基本数据类型:泛型擦除后原始类型中的T会被替换为Object,而Object不能存放基本数据类型。所以为了解决这个问题出现了包装类。
- 不可以对泛型实参使用instanceof(通配符除外)
// instanceof 存在继承实现关系即true。
List<String> list = new ArrayList<>();
System.out.println(list instanceof List<?>); //true
System.out.println(list instanceof List<String>); // 编译报错,擦除后String丢失
- 静态方法|静态类中不能使用泛型参数:泛型类中的泛型实参是在对象创建时指定,而静态的不需要创建对象,所以无法使用泛型。
- 无法创建泛型实例:存在擦除,类型不确定。
/**
* 无法为泛型创建实例(反射可以)
* */
public static <E> void test(List<E> eList, Class<E> eClass) {
// E e = new E(); // 编译报错,信息擦除。
try {
// 编译通过
E e = eClass.newInstance(); // Class<E> eClass 泛型作为了方法的参数,作为了元数据存在。可以使用这个信息。
eList.add(e);
} catch (InstantiationException | IllegalAccessException e1) {
e1.printStackTrace();
}
}
- 无泛型数组
4、既然存在擦除那为什么在运行期仍然可以使用反射获取到具体的泛型类型?
事实上,除了结构化信息外的所有东西都被擦除了 —— 这里结构化信息是指与类结构相关的信息,即与类及其字段和方法的类型参数相关的元数据都会被保留下来,可以通过反射获取到。
public static <E> void test(List<E> eList, Class<E> eClass) {
// 如方法签名相关信息都是元数据
// 如下:涉及到泛型的代码会被擦除为原始类型
List<String> list = new ArrayList<>();
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String s = it.next();
}
//如上
// 上面代码擦除后和如下代码字节码一致
List list = new ArrayList();
Iterator it = list.iterator();
while (it.hasNext()) {
String s = (String) it.next();
}
}
事实上所谓的泛型的类型擦除是指把某个具体的泛型引用在编译期完成类型检查后,还原成了Object类型,在代码中必要的地方添加了强制类型转换,而丢失了它运行时所赋予的类型信息。
在运行期只能获取当前class文件中包含泛型信息的泛型类型,而不能在运行时动态获取某个泛型引用的类型。
而在类型擦除后,如下代码中是没有任何办法在test方法内部获取到E的类型信息的,这才是擦除后的实际效果。您所说的可以通过反射获取到的泛型信息一定是某个class作为成员变量、方法返回值等位置的具体泛型类型,举例来说:
public static <E> void test(List<E> eList, Class<E> eClass) {
// E e = new E(); // 编译报错,信息擦除。无法确定E的实际类型。
try {
// 反射代码,编译通过。
E e = eClass.newInstance(); // Class<E> eClass 泛型作为了方法的参数,作为了元数据存在。可以使用这个信息。
eList.add(e);
} catch (InstantiationException | IllegalAccessException e1) {
e1.printStackTrace();
}
}
5、你工作中使用到的泛型场景
(2)网络请求接口Restful风格Base bean对象封装
(3)通用工具类的封装:任意数组reverse。
6、你了解泛型通配符与上下界吗?PECS原则是啥?
它们的目的都是为了使方法接口更为灵活,可以接受更为广泛的类型。
< ? super E> 用于灵活写入或比较,使得对象可以写入父类型的容器,使得父类型的比较方法可以应用于子类对象。
泛型能够接受指定E类,及其父类类型(按照super的功能记忆就行)
< ? extends E> 用于灵活读取,使得方法可以读取 E 或 E 的任意子类型的容器对象。
泛型能够接受E类,及其子类类型(按照extends 的功能记忆就行)
用《Effective Java》 中的一个短语来加深理解:
为了获得最大限度的灵活性,要在表示 生产者或者消费者 的输入参数上使用通配符,使用的规则就是:生产者有上限、消费者有下限。
PECS: producer-extends, costumer-super
如果参数化类型表示一个 T 的生产者,使用 < ? extends T>;
如果它表示一个 T 的消费者,就使用 < ? super T>;
如果既是生产又是消费,那使用通配符就没什么意义了,因为你需要的是精确的参数类型。
二、反射
1、啥叫反射
jdk提供的一种技术,使用反射api在程序运行期间可以动态解剖类的组分。
2、反射应用场景有哪些?
(1)运行配置文件中的类:框架中常见,一般表现为xml或者配置文件中配置类的全限定名字符串。这时就可通过反射动态生成类的对象。
(2)注解的运行期处理
(3)编译器的动态提示:开发工具利用反射动态刨析对象的类型与结构,动态提示对象的属性和方法。
(4)动态代理的实现:jdk动态代理就是利用反射来实现的。其实利用高性能的字节码操作框架ASM也能实现动态代理如 cglib。
(5)JDBC中,利用反射动态加载了数据库驱动程序
(6)Web服务器中利用反射调用了Sevlet的服务方法
3、反射的优点缺点
优点:动态执行,运行期间动态获取类的组分最大限度发挥了java的灵活性。
缺点:主要是性能开销。对性能有影响,反射操作总是慢于直接执行java代码。
- 性能开销:反射涉及类型动态解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率低下,尽量避免在高性能要求下使用反射。
- 安全限制:使用反射要求程序必须在一个没有安全限制的环境中运行。否则会拿不到期待效果。
- 内部曝光:由于反射允许代码执行一些在正常情况下不被允许的操作,所以使用反射可能会导致意料之外的副作用。
4、反射原理,JVM 是如何实现反射的?
(1)首先大致介绍下
在java的reflect包下反射相关的类主要包括两种:Class、Member。Class很好理解是一个类,封装了了某个类所有信息。
Class是有成员的,Class的成员包括三种也即构造函数、方法、字段。通过Class的api便可获取成员。
Member,是一个接口,主要定义了getName、getModifiers接口,有三个最常见的实现类Field、Method、Constructor。
这三个实现类都有一个相同的父类,AccessibleObject,在访问私有属性时需要设置 setAccessible 为true ,关闭系统的访问权限检查就是出自这个类里面的方法。



(2)具体实现
这里以Method的源码为例子讲解下:
public Object invoke(Object obj, Object... args)
throws IllegalAccessException, IllegalArgumentException,
InvocationTargetException
{
...
...
// 检查访问权限
MethodAccessor ma = methodAccessor; // read volatile
if (ma == null) {
ma = acquireMethodAccessor();
}
return ma.invoke(obj, args);
}
反射执行方法会调用Method#invoke方法,方法内部委托给MethodAccessor类来处理。MethodAccessor 是一个接口,它有两个已有的具体实现,一个是通过本地方法(NativeMethodAccessorImpl)来实现反射,简称本地实现;另一个则使用了委派模式(DelegatingMethodAccessorImpl),简称委派实现。
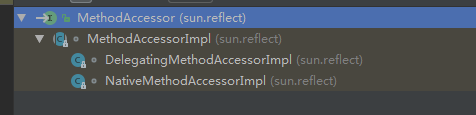
那么何时使用本地实现?何时使用委托实现呢?首先看下MethodAccessor实例的创建,MethodAccessor实例是在ReflectionFactory 被创建的,ReflectionFactory 是一个反射工厂类,负责创建Field对应的FieldAccessor ,Method对应的MethodAccessor 、Constructor对应的ConstructorAccessor 。
public class ReflectionFactory {
private static boolean initted = false;
// 反射工厂类,负责创建FieldAccessor 、MethodAccessor 、ConstructorAccessor
private static final ReflectionFactory soleInstance = new ReflectionFactory();
private static volatile LangReflectAccess langReflectAccess;
private static volatile Method hasStaticInitializerMethod;
// "Inflation" mechanism. Loading bytecodes to implement
// Method.invoke() and Constructor.newInstance() currently costs
// 3-4x more than an invocation via native code for the first
// invocation (though subsequent invocations have been benchmarked
// to be over 20x faster). Unfortunately this cost increases
// startup time for certain applications that use reflection
// intensively (but only once per class) to bootstrap themselves.
// To avoid this penalty we reuse the existing JVM entry points
// for the first few invocations of Methods and Constructors and
// then switch to the bytecode-based implementations.
//
// Package-private to be accessible to NativeMethodAccessorImpl
// and NativeConstructorAccessorImpl
private static boolean noInflation = false; // noInflation 默认关闭。关闭时会采用本地实现。
//[ˈθreʃhəʊld] 阈;
private static int inflationThreshold = 15; // 阈值,发射次数大于inflationThreshold 时则noInflation为true
//MethodAccessor 对象创建
public MethodAccessor newMethodAccessor(Method method) {
checkInitted();
if (Reflection.isCallerSensitive(method)) {
Method altMethod = findMethodForReflection(method);
if (altMethod != null) {
method = altMethod;
}
}
// use the root Method that will not cache caller class
Method root = langReflectAccess.getRoot(method);
if (root != null) {
method = root;
}
// 这里需要注意一点,VMAnonymousClass 并不是指匿名内部类
// 它可以看做是 JVM 里面的一个模板机制
if (noInflation && !ReflectUtil.isVMAnonymousClass(method.getDeclaringClass())) {
//动态生成字节码技术
return new MethodAccessorGenerator().
generateMethod(method.getDeclaringClass(),
method.getName(),
method.getParameterTypes(),
method.getReturnType(),
method.getExceptionTypes(),
method.getModifiers());
} else {
//本地实现
NativeMethodAccessorImpl acc = new NativeMethodAccessorImpl(method);
//委派实现,代理本地实现。
DelegatingMethodAccessorImpl res = new DelegatingMethodAccessorImpl(acc);
acc.setParent(res);
return res;
}
}
}
可以得出结论:在第一次调用反射的时候,noInflation 字段值显然为 默认的false,这时就会生成一个委派实现,而委派实现的的具体实现便是一个本地实现。
其实我们也可以一个栗子来验证上面的结论:
/**
* Create by SunnyDay on 2022/04/19 17:14
*/
public class TestReflectTrack {
/**
* 执行方法时直接搞个异常
* */
public static void showTrack(int i) {
new Exception("#" + i).printStackTrace();
}
public static void main(String[] args) throws Exception {
Class<?> clazz = Class.forName("TestReflectTrack");
Method method = clazz.getMethod("showTrack", int.class);
method.invoke(null, 0);
}
}

本地实现很好理解就是调用native方法进行的实现,当进入 Java 虚拟机内部之后,我们便拥有了 Method 实例所指向方法的具体地址。这时候,反射调用无非就是将传入的参数准备好,然后调用进去目标方法即可。
为什么反射调用还要采取委派实现作为中间层?直接交给本地实现不可以么?
其实,Java 的反射调用机制还设立了另一种动态生成字节码的实现(简称动态实现),直接使用 invoke 指令来调用目标方法,之所以采用委派实现,便是为了能够在本地实现以及动态实现中切换。
如ReflectionFactory 注释所述,动态实现比本地实现运行效率要快上 20 倍,这是因为动态实现无需经过 Java 到 C++ 再到 Java 的切换,但由于生成字节码十分耗时,仅调用一次的话,反而是本地实现要快上 3 到 4 倍。
考虑到许多反射调用仅会执行一次,Java 虚拟机设置了一个阈值 15,当某个反射调用的调用次数在 15 之下时,采用本地实现;当达到 15 时,便开始动态生成字节码,并将委派实现的委派对象切换至动态实现,这个过程我们称之为 Inflation。
知道了inflationThreshold = 15那么我们看下这个控制逻辑是如何处理的?
/** Used only for the first few invocations of a Method; afterward,
switches to bytecode-based implementation */
class NativeMethodAccessorImpl extends MethodAccessorImpl {
private final Method method;
private DelegatingMethodAccessorImpl parent;
private int numInvocations;
NativeMethodAccessorImpl(Method method) {
this.method = method;
}
public Object invoke(Object obj, Object[] args)
throws IllegalArgumentException, InvocationTargetException
{
// We can't inflate methods belonging to vm-anonymous classes because
// that kind of class can't be referred to by name, hence can't be
// found from the generated bytecode.
//invoke方法没次被调用时计数器+1,当计数器值大于15时执行如下逻辑
if (++numInvocations > ReflectionFactory.inflationThreshold()
&& !ReflectUtil.isVMAnonymousClass(method.getDeclaringClass())) {
// 生成java版的MethodAccessor 实现类
MethodAccessorImpl acc = (MethodAccessorImpl)
new MethodAccessorGenerator().
generateMethod(method.getDeclaringClass(),
method.getName(),
method.getParameterTypes(),
method.getReturnType(),
method.getExceptionTypes(),
method.getModifiers());
// 改变委托实现DelegatingMethodAccessorImpl 的引用为java版。之后就是java动态实现了。
parent.setDelegate(acc);
}
return invoke0(method, obj, args);
}
void setParent(DelegatingMethodAccessorImpl parent) {
this.parent = parent;
}
private static native Object invoke0(Method m, Object obj, Object[] args);
}
inflationThreshold = 15 是在NativeMethodAccessorImpl 这个类中进行判断的。每次 NativeMethodAccessorImpl.invoke 方法被调用时,都会增加一次计数器,看超过阈值没有;一旦超过,则调用 MethodAccessorGenerator.generateMethod 来生成 Java 版的 MethodAccessor 的实现类,并且改变 DelegatingMethodAccessorImpl 所引用的 MethodAccessor 为 Java 版。后续经由 DelegatingMethodAccessorImpl.invoke 调用就是 Java 版的实现了。

影响性能因素小结:
外在因素:
Class.forName 会调用本地方法,相对直接使用java对象调用方法来说饶了好多步,Class.getMethod 则会遍历该类的公有方法。如果没有匹配到,它还将遍历父类的公有方法,可想而知,这两个操作都非常耗时。
值得注意的是,以 getMethod 为代表的查找方法操作,会返回查找得到结果的一份拷贝。因此,我们应当避免在热点代码中使用返回 Method 数组的 getMethods 或者 getDeclaredMethods 方法,以减少不必要的堆空间消耗。
自身因素:
- Method.invoke 是一个变长参数方法,在字节码层面它的最后一个参数会是 Object 数组。Java 编译器会在方法调用处生成一个长度为传入参数数量的 Object 数组,并将传入参数一一存储进该数组中。
- Object 数组不能存储基本类型,Java 编译器会对传入的基本数据类型进行自动装箱。
因此反射耗时因素如下:
- 方法表查找:遍历该类所有方法,有可能还要遍历父类。
- 构建 Object 数组以及可能存在的自动装拆箱操作
- 运行时权限检查:每次反射调用都会检查目标方法的权限,而这个检查同样可以在 Java 代码里关闭。
- 方法内联
如何避免反射性能开销?
- 尽量避免反射调用虚方法:对于 invokevirtual 或者 invokeinterface,Java 虚拟机会记录调用者的具体类型,我们称之为类型 profile,虚方法多时,虚拟机无法同时记录这么多个类,因此可能造成所测试的反射调用没有被内联的情况。
- 关闭运行时权限检查。
- 可能需要增大基本数据类型对应的包装类缓存
- 关闭 Inflation 机制(可以通过参数设置)
- 提高 JVM 关于每个调用能够记录的类型数目profile(默认2可通过虚拟机参数调整)
三、注解
1、啥叫注解
注解Annotation,可以理解为java代码的一个标签,这个标签为被标记的代码提供一些数据。
2、注解存在的时期
这个对应元注解Retention 的参数值。参数值为RetentionPolicy 内的三种枚举值,SOURCE、CLASS、RUNTIME。分别代表存在源码阶段、存在class文件中、存在class文件中。CLASS与RUNTIME是有区别的,CLASS的值代表jvm读取class文件时会把注解信息丢弃,而RUNTIME的值代表jvm会读取class文件中的注解值。
3、啥叫元注解
元注解是作用于注解的注解,java中提供了四个元注解
- @Retention:注解作用的期间。默认值为CLASS
- @Target:注解作用的目标。默认为可作用任意代码。
- @Inherited:[ɪnˈherɪtɪd],是否允许子类继承父类的注解,默认是 false。
- @Documented :注解信息是否可以保存到javadoc中
4、注解的处理场景
- 编译期处理(ButterKnife框架实现原理、工作项目中LayerHelper的实现)
- 运行期处理。(Uutils框架中ViewUtils的实现原理 )
5、注解处理器使用大致流程
(1)啥叫APT
APT:AnnotationProcessorTool的缩写,注解处理器是给编译器使用的,可以让编译器按照我们的意愿来处理注解。
(2)APT的工作原理
Java 源代码的编译流程分为三个步骤,
将源文件解析成抽象语法树 -> 调用已注册的注解处理器 -> 生成字节码
如果第二步调用注解处理器过程中生成了新的源文件,那么编译器将重复第一二步骤,解析并处理新生成的源文件。因此可以理解为注解处理器是给编译器使用的,可以让编译器按照我们的意愿来处理注解。
(3)注解处理器的常见用途
-
一是定义编译规则,并检查被编译的源文件(如java自带的@Override)
-
二是修改已有的源代码(这种方式很少使用,涉及了 Java 编译器的内部 API,可能会存在兼容性问题)
-
三是生成新的源代码(比较常见,目前最常用的方式。如Butterknife、EventBus 等框架,)
(4)注解处理器的大致使用流程
可以通过继承 AbstractProcress 来自定义注解处理逻辑,但是还得需要向编译器注册注解处理器,这是一件很麻烦的事,需要在 META-INFO 目录下手动注册,一般是通过依赖 Google 的 AutoService 库来解决。
public interface Processor {
//一般做一些初始化工作可通过ProcessingEnvironment#getXXX来获取相应的对象如:
//filer:用于给注解处理器创建文件,可把文件保存到本地。生成文件时经常会使用。
//Messager:打印编译处理期间的信息。可在build->outPut 窗口查看。
void init(ProcessingEnvironment processingEnv);
// 获取注解处理器所支持的注解类型,一般固定写法,生成、返回一个set即可。
Set<String> getSupportedAnnotationTypes();
// 注解处理器支持的java版本,一般与编译器保持一致即可,固定写法。
SourceVersion getSupportedSourceVersion();
/**
注解处理器的核心处理方法。
annotations:注解处理器能够处理的注解类型。同上getSupportedAnnotationTypes。
roundEnv:封装了当前轮抽象语法树的注解信息。一般通过如下方式处理:
Set<? extends Element> elementSet = roundEnvironment.getElementsAnnotatedWith(BindView.class);//BindView 为自定义的注解
Element是一个接口,代表元素,他的实现类有很多如
TypeElement:表示一个类或接口程序元素
VariableElement:表示一个字段、enum 常量、方法或构造方法参数、局部变量或异常参数
这样通过相应的api就可以获取注解信息进行处理了。
*/
boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv);
...
}
四、异常
1、谈谈java的异常
Java语言中Throwable是所有异常的根类,Throwable 派生了两个直接子类Error 和 Exception。
Error 表示应用程序本身无法克服和恢复的一种严重问题,触发Error时会终止线程甚至是虚拟机。一般为虚拟机相关的错误如系统崩溃,内存不足,堆栈溢出等。
Exception 表示程序还能够克服和恢复的问题,Exception按照处理时机可以分为编译时异常和运行时异常。
编译时异常都是可以被修复的异常,代码编译期间Java程序必须显式处理编译时异常,否则无法编译通过。运行时异常通常是软件开发人员考虑不周所导致的问题,软件使用者无法克服和恢复这种问题,但在这种问题下软件系统可能会继续运行,严重情况下软件系统才会死掉。
2、jvm是如何处理异常的?
class 文件被编译成字节码时,每个方法都附带一张异常表。异常表中的每一个条目代表一个异常处理器。
该处理器由from指针、to指针、target指针、所捕获的异常类型组成。这些指针的值是字节码索引,用以定位字节码。
- from 、to 表示表示异常处理器监控范围,即用try代码块监控的范围。
- target表示异常处理器的起始位置,即catch起始位置。
- 异常类型即为xxxException。
当程序触发异常时,Java 虚拟机会生成一个要抛出的异常实例,然后自上至下遍历异常表中的所有条目。当触发异常的字节码的索引值在某个异常表条目的监控范围内,Java 虚拟机会判断要抛出的异常和该条目想要捕获的异常是否匹配。如果匹配,Java 虚拟机会将控制流转移至该条目 target 指针指向的字节码。
如果遍历完所有异常表条目,Java 虚拟机仍未匹配到异常处理器,那么它会弹出当前方法对应的Java 栈帧,并且在调用者中重复上述操作。在最坏情况下,Java 虚拟机需要遍历当前线程 Java栈上所有方法的异常表。最终把异常抛出。
finally 代码块的编译比较复杂,当前版本 Java 编译器的做法,是复制 finally 代码块的内容,分别放在 try-catch 代码块所有正常执行路径以及异常执行路径的出口中。以保证finally的必须执行。
3、 try-catch-finally 中哪个部分可以省略?
其实try只适合处理运行时异常,try+catch适合处理运行时异常+编译时异常。
也就是说,如果你只用try去处理编译时异常却不加以catch处理,编译是通不过的,因为编译器硬性规定,编译时异常如果选择捕获,则必须用catch显示声明以便进一步处理。而运行时异常在编译时没有如此规定,所以catch可以省略,加上catch编译器也觉得无可厚非。
理论上,编译器看任何代码都不顺眼,都觉得可能有潜在的问题,所以你即使对所有代码加上try,代码在运行期时也只不过是在正常运行的基础上加一层皮。但是你一旦对一段代码加上try,就等于显示地承诺编译器,对这段代码可能抛出的异常进行捕获而非向上抛出处理。如果是编译时异常,编译器要求必须用catch捕获以便进一步处理;如果运行时异常,捕获然后丢弃并且+finally扫尾处理,或者加上catch捕获以便进一步处理。
try{
// 运行时异常|编译时异常
}catch(XXXException e){
//1、try中为运行时异常时,这里catch 块可无。但是finally必须有。
//2、try中为编译时异常时,cacth必须有,finally可有可无。
}finally{
// finally 块可有可无,做资源处理。
}
//栗子
try{
// 运行时异常
int a = 1/0;
}finally {
// 必须有
}
4、 try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
会执行。
异常机制有这么一个原则如果在 catch 中遇到了 return 或者异常等能使该函数终止的话,那么finally就必须先执行完finally代码块里面的代码然后再返回到catch中抛出或者return处。(主动退出虚拟机除外如catch中System.exit(),finally不会被执行)
不过上述的执行机制存在异常丢失的情况。一般可以使用java7的 try - catch - resource 语法糖处理。不过try catch-resource设计的初衷是为了优化try-catch-finally资源关闭的代码臃肿。同时引入了Supressed 异常,在字节码层面自动使用 Supressed 异常,这个新特性允许开发人员将一个异常附于另一个异常之上。因此,抛出的异常可以附带多个异常的信息。
5、 NoClassDefFoundError 和 ClassNotFoundException 区别?
NoClassDefFoundError 是一个 Error 类型的异常,是由 JVM 引起的,不应该尝试捕获这个异常。引起该异常的原因是 JVM 或 ClassLoader 尝试加载某类时在内存中找不到该类的定义,该动作发生在运行期间,即编译时该类存在,但是在运行时却找不到了,可能是变异后被删除了等原因导致。
ClassNotFoundException 是一个受查异常,需要显式地使用 try-catch 对其进行捕获和处理,或在方法签名中用 throws 关键字进行声明。当使用 Class.forName, ClassLoader.loadClass 或 ClassLoader.findSystemClass 动态加载类到内存的时候,通过传入的类路径参数没有找到该类,就会抛出该异常;另一种抛出该异常的可能原因是某个类已经由一个类加载器加载至内存中,另一个加载器又尝试去加载它。
五 、接口抽象类区别
1、成员的区别
抽象类
1、构造方法:有构造方法,用于子类实例化使用。
2、成员变量:可以是变量,也可以是常量。
3、成员方法:可以是抽象的,也可以是非抽象的。
接口
1、构造方法:没有构造方法
2、成员变量:只能是常量。默认修饰符public static final
3、成员方法:jdk1.7只能是抽象的。默认修饰符public abstract 。jdk1.8可以写以default和static开头的具体方法。
2、关系区别
类与类:
1、继承关系,只能单继承。可以多层继承。
类与接口:
1、实现关系:可以单实现,也可以多实现。
2、类还可以在继承一个类的同时实现多个接口。
接口与接口:
1、继承关系:可以单继承,也可以多继承。
3、理念不同
1、抽象类里面定义的都是一个继承体系中的共性内容。
2、接口是功能的集合,是一个体系额外的功能,是暴露出来的规则。
4、接口与抽象类的选择
接口和抽象类的概念不一样。接口是对动作的抽象,表示对象能做什么,抽象类是对根源的抽象,表示对象是什么。当你关注一个事物的本质的时候,用抽象类;当你关注一个操作的时候,用接口。
栗子:
男人,女人,这两个类,他们的抽象类是人。说明,他们都是人。人可以吃东西,狗也可以吃东西,你可以把“吃东西”定义成一个接口。所以,在高级语言上,一个类只能继承一个类(正如人不可能同时是人类和非人类),但是可以实现多个接口(吃饭接口、走路接口)。
抽象类的功能要远超过接口,但是,定义抽象类的代价高。因为高级语言来说(从实际设计上来说也是)每个类只能继承一个类。在这个类中,你必须继承或编写出其所有子类的所有共性。虽然接口在功能上会弱化许多,但是它只是针对一个动作的描述。而且你可以在一个类中同时实现多个接口。在设计阶段会降低难度。