DataX 是阿里开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
DataX设计理念
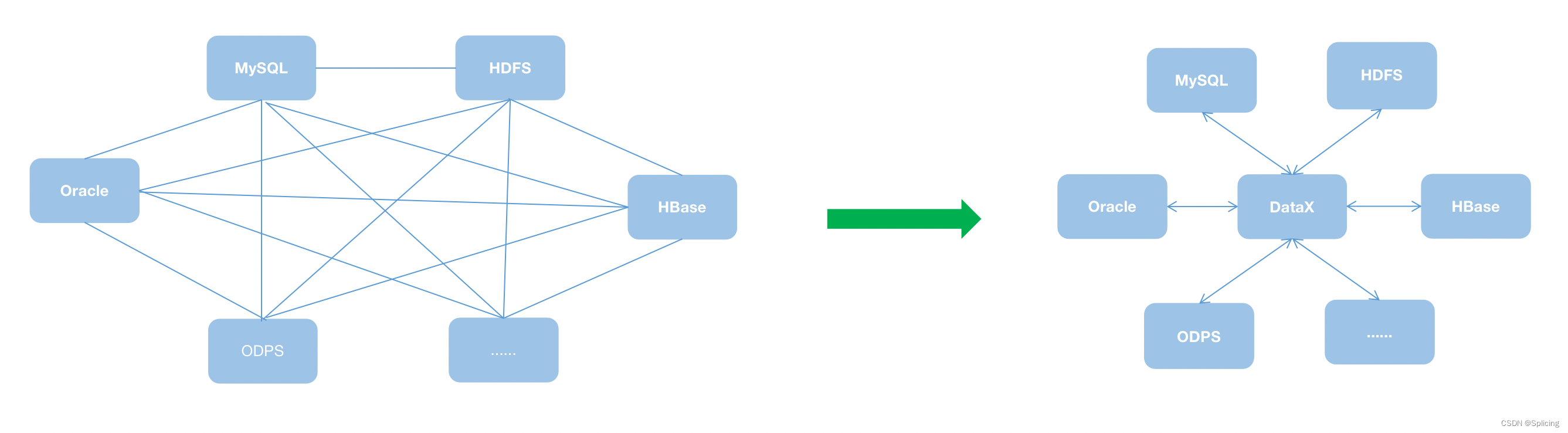
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
DataX框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
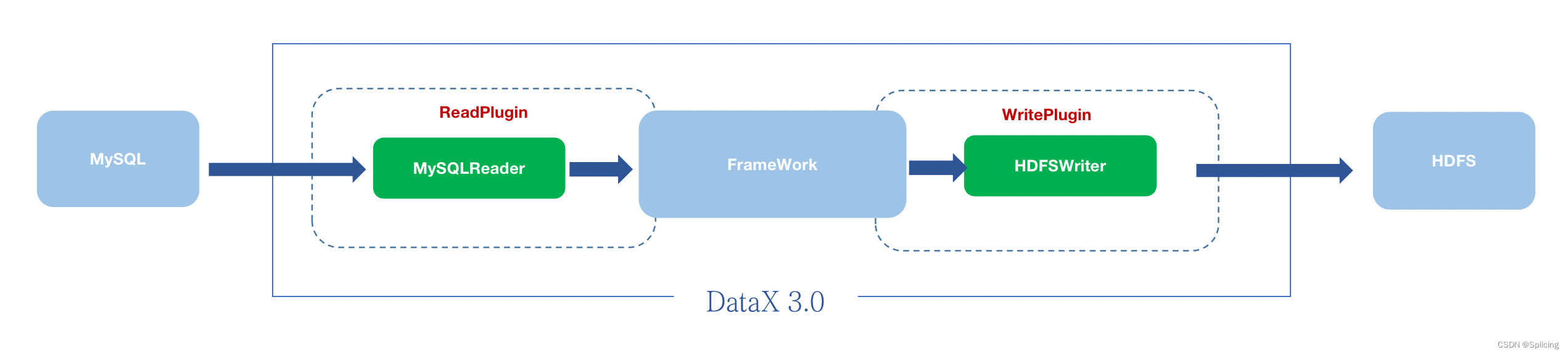
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX核心架构
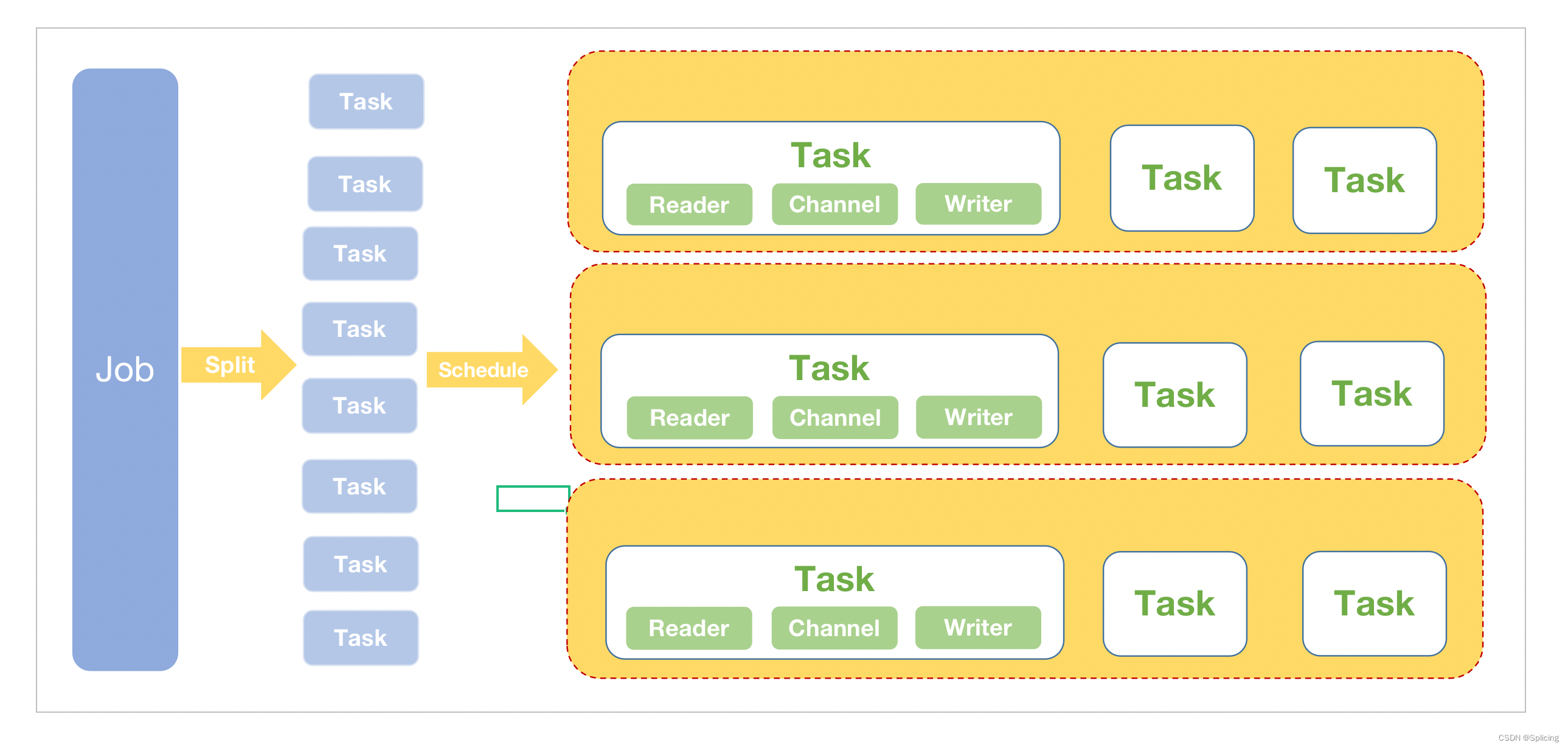
核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。* * 每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0。
DataX执行流程
1、解析配置,包括job.json、core.json、plugin.json三个配置;
2、设置jobId到configuration当中;
3、启动Engine,通过Engine.start()进入启动程序;
4、设置RUNTIME_MODE到configuration当中;
5、通过JobContainer的start()方法启动;
6、依次执行job的preHandler()、init()、prepare()、split()、schedule()、- post()、postHandle()等方法;
7、init()方法涉及到根据configuration来初始化reader和writer插件,这里涉及到jar包热加载以及调用插件init()操作方法,同时设置reader和writer的configuration信息;
8、prepare()方法涉及到初始化reader和writer插件的初始化,通过调用插件的prepare()方法实现,每个插件都有自己的jarLoader,通过集成URLClassloader实现而来;
9、split()方法通过adjustChannelNumber()方法调整channel个数,同时执行reader和writer最细粒度的切分,需要注意的是,writer的切分结果要参照reader的切分结果,达到切分后数目相等,才能满足1:1的通道模型;
10、channel的计数主要是根据byte和record的限速来实现的(如果自己没有设置了channel的个数),在split()的函数中第一步就是计算channel的大小;
11、split()方法reader插件会根据channel的值进行拆分,但是有些reader插件可能不会参考channel的值,writer插件会完全根据reader的插件1:1进行返回;
12、split()方法内部的mergeReaderAndWriterTaskConfigs()负责合并reader、writer、以及transformer三者关系,生成task的配置,并且重写job.content的配置;
13、schedule()方法根据split()拆分生成的task配置分配生成taskGroup对象,根据task的数量和单个taskGroup支持的task数量进行配置,两者相除就可以得出taskGroup的数量14、schdule()内部通过AbstractScheduler的schedule()执行,继续执行startAllTaskGroup()方法创建所有的TaskGroupContainer组织相关的task,TaskGroupContainerRunner负责运行TaskGroupContainer执行分配的task;
14、taskGroupContainerExecutorService启动固定的线程池用以执行TaskGroupContainerRunner对象,TaskGroupContainerRunner的run()方法调用taskGroupContainer.start()方法,针对每个channel创建一个TaskExecutor,通过taskExecutor.doStart()启动任务。