AntDB-M在架构上分为两层,服务层和存储引擎层。元数据的并发管理集中在服务层,数据的存储访问在存储引擎层。为了保证DDL操作与DML操作之间的一致性,引入了元数据锁(MDL)。
AntDB-M提供了丰富的元数据锁功能,然而高并发锁操作很容易出现锁竞争、等待、死锁的问题,AntDB-M具体提供了什么样的元数据锁,又是如何解决这些问题的呢?本文来一探究竟。
相关概念
●MDL_lock
MDL_lock即元数据锁对象,对一个由MDL_key唯一指定的元数据加锁,即获取到该对象。
●MDL_key
MDL_key即每个元数据的唯一代表。由命名空间、表、列三部分构成。
●MDL_ticket
一个元数据对应每种锁类型都只有一个锁对象,每个客户端连接线程(后文以线程指代)在持有或者等待某个锁对象时,为其分配一个唯一的对象(MDL_ticket),代表该线程持有或等待该锁对象。
●MDL_context
每个线程都会分配一个元数据锁上下文(MDL_context),保存了其持有的所有MDL_ticket、正在等待的ticket、等待条件变量(用于等待唤醒)。
多层次、多粒度
元数据锁分为多个层次,每层分为多种粒度。不同层次间存在依赖关系,在申请元数据锁时,要先申请到其所依赖的上层锁。比如在申请表(TABLE)锁时,要先申请到其上层的GLOBAL、以及SCHEMA锁。多层次多粒度的划分可以满足元数据一致性在不同范围内的需求,又能提供更高的并发度。

图1-元数据锁层次关系
多类型
根据对元数据、表数据的访问需求,如对元数据还是表数据进行访问,读请求还是写请求,共享还是互斥,高优先级还是低优先级,是否可升级等多种维度进行设立不同类型的锁类型。在最大限度提升并发度的同时,能灵活满足多种锁需求。
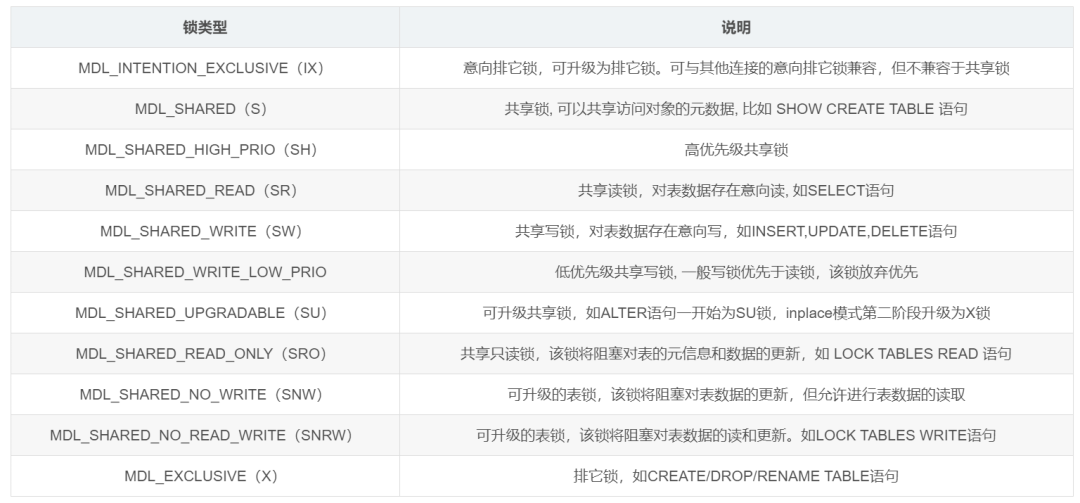
图2-锁类型说明
锁生命周期
元数据锁的生命周期分为三种:语句、事务、显式。通过不同的生命周期,来尽可能小的缩短锁时间。

图3-锁生命周期
锁的获取
5.1 锁的强弱
当线程已经持有的锁比新申请的锁更强时,认为已经持有了锁,无需再对申请锁类型加锁。锁的强弱指持有的锁与其他锁的不兼容集合大小,集合相同锁相同,集合更大锁更强,否则无强弱关系。通过锁的兼容位图进行简单的位运算即可快速判断锁的强弱。
5.2 两种锁范围
按照锁的适用范围将锁划分为两类,当然划分不是非此即彼的,会有重叠,这两类锁有各自的兼容性和锁对象管理方式。
●范围锁(scoped locks)
只有三种锁(IX,S,X),主要用于GLOBAL、COMMIT、TABLESPACE、BACKUP_LOCK命名空间的对象。这几种命名空间的锁主要从整体上去限制并发操作,比如在DML访问一张表时,会先申请一个该表所属SCHEMA的IX锁,避免访问过程中该SCHEMA被修改、删除。范围锁全局每种命名空间都仅有一个锁对象,从而实现全局性的并发控制。
●对象锁 (per-object locks)
除了IX锁,其他类型都可以用于其他命名空间,这部分是最常用的锁类型。主要用于对数据库的某个具体元数据的并发控制。这类锁对象会比较多,对其有独特的管理,本文不再展开说明。
5.3 两种锁类型
根据锁的兼容性、以及通用性将锁分为两类。
5.3.1互不干扰型(unobtrusive)
unobtrusive锁相互间兼容,并且适用于所有DML操作。这类锁获取后不用记录下具体哪个线程申请的,只需要记录下有多少个请求已经获得,通过锁对象下64位原子变量来计数,因此对其他连接的锁申请影响很小,表现比较低调。在64位中每种类型锁都有由固定的位范围存放加锁个数。对于scoped与per-object是不同锁对象,因此位分别设置。
scoped locks: IX(0~59位)
per-object locks: S,SH(0~19位),SR(20~39位), SW(40~59位)
注意分配20位的不会产生溢出,因为当前设计不会同时有超过2^20 - 1个连接。
另外,还存在三个状态指示位,用于加速锁的处理。
IS_DESTROYED: 标识锁对象将被释放。
HAS_OBTRUSIVE:标识锁对象下有obtrusive锁,新的锁申请必须进入慢速申请路径,释放锁时,也要先加锁以保护已授予锁链表。
HAS_SLOW_PATH: 标识锁对象下是否有unobtrusive锁。
5.3.2 干扰型(obtrusive)
相互间不兼容,对于DML操作不通用。此类锁的申请过程需要对锁对象的读写锁加写锁,对不同线程的锁申请影响较大,因此显的比较张扬。
scoped locks:X,S。
per-object locks:SU, SRO, SNW, SNRW, X。
5.4 加锁路径
锁的申请过程分为两种路径,1)快路径, 即只需要增加锁个数计数来授予锁; 2)慢路径,需要对锁对象读写锁加写锁来授予锁。
5.4.1 快路径(fast path)
对于unobtrusive锁,可以通过快速路径来快速授予锁。但是授予锁有个前提,就是该锁对象下没有obtrusive锁,因为unobtrusive与obtrusive之间有些锁是互斥的,只有在没有obtrusive锁存在时,unobtrusive锁才彼此兼容。通过检测锁状态的HAS_OBTRUSIVE位即可快速判断。通过CAS操作即可更新锁个数,同时也会检测是否已有其他线程以张扬方式申请了锁。CAS操作成功,即申请锁成功。
5.4.2 慢路径(slow path)
对于obtrusive锁,以及当前申请unobtrusive锁,而锁对象下已经持有obtrusive锁时,需要进入慢路径申请锁,即先对锁对象下的读写锁加写锁。在当前锁对象首次进入慢路径时,设置锁状态的HAS_SLOW_PATH位。如果是首次申请obtrusive锁,则设置HAS_OBTRUSIVE位。
5.4.3 锁位图
锁对象的快速路径锁申请锁、已经授予的锁队列、正在等待锁队列都有标识其含有锁类型的锁位图,通过位图可以加快锁兼容判断速度,避免每次遍历锁队列。
5.4.4 快速路径锁物化
在申请obtrusive锁进入慢路径之前,要将当前线程通过快路径获取的锁物化,即从锁对象的锁状态计数器中减除,并放入到锁对象的已经授予锁列表中。因为锁状态计数器中只有锁个数,不区分线程。而当前线程自己申请的unobtrusive锁与obtrusive锁不冲突。物化可以确保锁状态计数器中都是其他线程申请的,这样就可以通过快速路径锁位图快速判断是否与当前申请锁兼容。
5.4.5 慢路径锁的授予条件
当且仅当满足如下两个条件时,才可以授予锁。
1. 其他线程没有持有不兼容类型锁。
2. 当前申请的锁的优先级高于请求等待列表中的。
首先通过锁位图判断等待队列,不兼容则不能授予锁。再判断快速路径,不兼容则不能授予锁。最后判断授予锁队列,都兼容则授予锁,不兼容,需要遍历持有锁队列,检查是否其他线程持有不兼容锁,是则不能授予,否则可以授予锁。
5.5 防止低优先级锁饥饿
AntDB-M按照优先级将锁又分了两类,用于解决低优先级锁饥饿问题。
●独占型(hog): X, SNRW, SNW; 具有较强的不兼容性,优先级高,容易霸占锁,造成其他低优先级锁一直处于等待状态。
●暗弱型(piglet): SW; 优先级仅高于SRO。
这两种类型锁会分别进行加锁计数。当授予hog类型锁时,如果等待队列中有非hog类型,则计数加1。当授予piglet类型锁时,如果等待队列中有SRO,则计数加1。针对计数是否超过阀值(max_write_lock_count)制定了四种优先级矩阵。在加锁授权检测时,如果两种类型中有任一达到统计阀值,则切换到对应的优先级矩阵,重新检测是否可以授权,此时优先级进行了反转,会提升低优先级锁优先获取锁。当前等待队列里低优先级锁处理完毕后,会重置对应的hog,piglet计数器,并反转优先级。
5.6 死锁检测
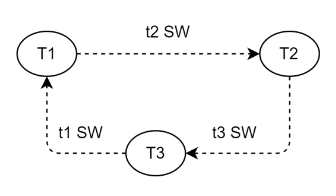
图4-死锁等待
每个线程在进入锁等待前,都会先进行死锁检测,避免陷入死锁等待。在检测前,会先将自己获取到的unobtrusive锁进行物化,即将锁放入锁的授予列表中,以便死锁检测能区分锁的归属线程。然后设置自己上下文等待ticket,每个进入等待的线程都有自己的等待ticket,用于死锁检测。
AntDB-M使用等待图算法进行死锁检测,每个锁对象下的waiting队列中的每个ticket都存在自己的不兼容锁,即正在等待的锁,所有锁对象下的waiting队列中的ticket根据等待关系,构成了一个等待图。先对当前线程的等待的锁对象下的所有ticket进行广度优先检测,即对当前ticket节点的所有边进行检测,在没有发现死锁时,再进入每个ticket上下文的等待ticket对应的锁对象进行深度检测。
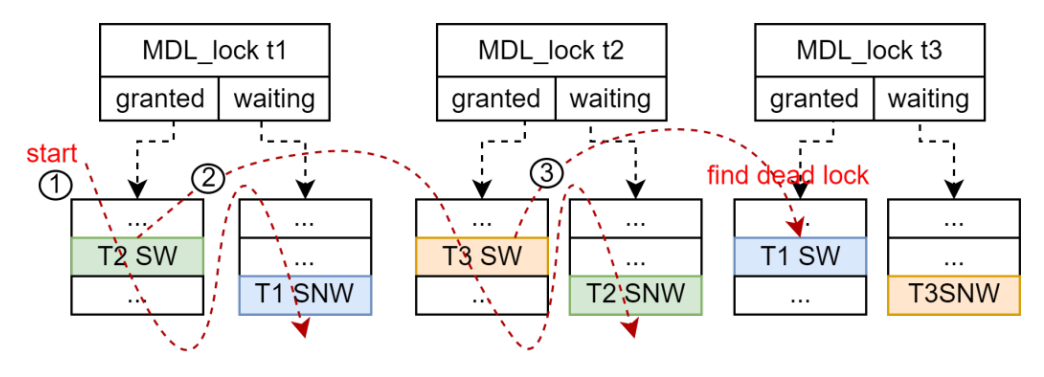
图5-死锁检测
检测开始时记住此次检测的起始上下文,即当前线程的上下文。当在广度、深度遍历过程中,发现等待路径上再次出现起始上下文,说明出现了循环等待,即死锁。如果检测深度(即检测上下文个数)超过阀值(32),也认为出现了死锁。
5.7 死锁驱逐
当发现死锁时,在整个检测路径上包括自己会有2到多个ticket,对于这些ticket,会选其中死锁权重最低的设置状态为驱逐,即唤醒该线程结束等待,将自己从锁对象的等待队列中移除。权重分为3级:DDL锁 > 用户级锁 > DML锁。在出现死锁时,更倾向于让DML事务回滚,让DDL语句继续执行。权重相同时,更倾向于后进入等待队列的事务回滚。在设置了驱逐状态后,并不能保证剩余的锁间没有死锁,会重新进行一次死锁检测,直到没有发现死锁,或者将自己设为驱逐状态为止。对每个上下文进行检测时,对其加读锁,避免上下文的等待对象被重置。
对每个锁对象进行检测时,对其加读锁,避免已授权、等待队列被更新。通过读锁保障数据安全的同时,又保障了多线程间的并发操作。
5.8 锁等待及通知
每个线程的锁上下文都有一个条件变量来进行锁等待。线程在没有获取锁的授权时,会将自己的ticket添加到锁对象的等待队列,并进入等待状态。等待队列的锁授予检测有3个时机:
1)加锁申请阶段,hog,piglet类型锁申请个数超过阀值。
2)当有线程释放元数据锁。
3)元数据锁降级。
时机触发时,会遍历该锁对象的等待列表,检测到可以授予时,设置线程等待状态为授予锁,通知该线程,并将ticket从等待队列移到授予队列。
总结
AntDB-M通过多层次、多粒度、多优先级提供了灵活丰富的元数据锁功能,适用于各种业务场景。将加锁路径区分快速、慢速路径,提高绝大部分业务场景的加锁效率。通过优先级反转,避免低优先级饥饿。高效的广度优先死锁检测技术,避免了死锁的发生。如果检测到了死锁,会优先驱逐DML操作,保障成本更高的DDL操作,相同操作会优先驱逐等待时间更短的操作,保持公平性。
关于AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,为全国24个省份的10亿多用户提供在线服务,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行近15年,并在通信、金融、交通、能源、物联网等行业成功商用落地。