目录
① from test_excel where user_cardid = 'xxx'
② from test_excel where user_cardid = 'xxx' and user_age = 'xxx' and user_name = 'xxx'
③ from test_excel where user_cardid = 'xxx' and user_age = 'xxx' or user_name = 'xxx'
2、in,not in,is null,is not null
① from test_excel where user_name like '张三129%'
以MySQL数据库为例:
一、什么是数据库索引
1、索引的作用
数据库表存在大量数据的情况下,索引能极大的加快表数据的查询速度,减少IO操作次数,降低资源的消耗,是一种典型的以空间换时间的处理方法;
2、索引的分类
其实索引类型是没有指定的标准的(因为引擎不一样,这里以MySQL的InnoDB引擎为例),但是大体可以分为三类:
1、聚集索引:也叫主键索引,所有数据都按照主键索引进行排序;
2、非聚集索引:一系列的普通索引都可以归纳到非聚集索引,如:普通索引、唯一索引、全文索引;
3、复合索引:很多也叫组合索引,听名字就知道,很多字段组合的索引;
二、索引的原理
在不建立索引的情况下,数据库查询数据是从上往下依次匹配的,如果有100万条数据,你运气不好,要的数据刚好在最后一条,那就呵呵呵,而索引就是为了解决这一问题的;
① 索引的结构:B-tree索引、平衡树(很多人也叫B树,其实这种直译的方式是不好的)
btree索引有几个很重要的概念:阶、根节点、内部节点、叶子节点,当然你还必须得有磁盘块这个概念,因为索引和数据都是存在磁盘里的,而每次读数据其实是读某个“磁块”,也可以简单的理解为“分页”,一个“磁块”内包含有很多数据,读取一次磁盘就是一次IO操作,会一次把附近所有的数据都读取到缓冲区,然后再在缓冲区查找到你想要的数据,而一次读取数据量的多少是和你的操作系统有关的;
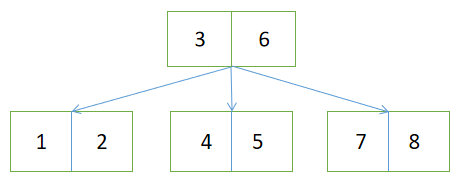
那问题来了,什么是btree,看图(没有在网上找到合适的图片,就自己画了个,传说中的灵魂画家)

如图:
1、根节点:磁块1部分;
2、内部节点:磁块2、磁块3部分;
3、叶子节点:磁块4、5、6、7、8、9、10部分;
4、阶:一个节点下包含最多的叶子节点个数叫阶数,如上图最多的叶子节点数为4个,所以叫4阶btree;
而他们之间又有固定的比例,平衡树嘛,肯定是要遵循一定比例的(考验数学理解的时候来了):
1、假设我们定义每个节点下最多的叶子节点数为m(其实就是阶数为m),那么每个内部节点下至少包含m/2个子节点;
2、根如果不是叶子节点的情况下,根必须包含2个节点,节点可以为内部节点或者叶子节点;
3、(这点很重要)所有的叶子节点都是在同一层的(就是高度一样),并且是不带有任何参数的;
② btree的新增
以上图为例,我们做一个4阶btree的新增:
1、插入4个元素:1、2、3、4
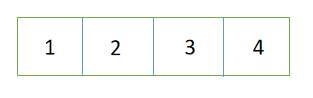
2、再插入1个元素:5,因为这是一个4阶的btree所以当达到5时,则必须进行拆分,那么为什么会是3拆分出来了呢,这里就又增加了一个概念:取中间值

3、再插入2个元素:6、7

4、再插入1个元素:8,这里又进行了拆分,4、5、6、7、8已经有5个了,所以中间值6被拆分了出来。
5、后面再增加也是一样的操作了,这里不就一一写了,删除也是一样的,反着来就可以了 。
③ btree的读取流程

如图所示,假设需要读取“7”的数据,流程:先读取根节点(磁块1),匹配后得知“7”在(磁块2)里,然后获取到(磁块2)的下标再读取(磁块2),又匹配后得知“7”在(磁块6)里,再获取(磁块6)的下标读取(磁块6),最后加载到缓冲里获取到“7”的数据。
整个流程只进行了3此IO操作,数据量多时可以极大的减少IO操作次数。同样由上图可知,加索引后的IO操作次数只与btree的高度有关(重点)。
④ B-tree和B+tree对比
btree的介绍就差不多了,再对比一下B-tree和B+tree吧,注意这3条来自于百度查找,还没有研究b+tree。
1、所占空间的对比,b+tree的内部结点是没有指向具体信息的指针的(b-tree是有的),所以b+tree占用空间更小。
2、读取流程上的对比:b+tree读取时总是从根节点开始然后到叶子节点的(b-tree不一定),所以你会发现每条sql的查询速度都是差不多的,并没有明显的差别。
3、范围查找(最主要的一点):b-tree对范围查找并没有提高效率,b+tree提高了范围查询的效率。
三、怎么创建索引
1、创建一个测试表
CREATE TABLE test_excel (
user_id varchar(255) NOT NULL COMMENT '表主键id',
user_name varchar(255) NOT NULL COMMENT '用户姓名,不能为空',
user_age int(11) DEFAULT NULL COMMENT '用户年龄,允许为空',
user_cardid varchar(255) NOT NULL COMMENT '身份证号,不能为空,不允许重复',
PRIMARY KEY (user_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;在写上一篇博客EasyExcel导入的时候正好有创建一个测试表,数据也导进去了,测试数据为200万条,后面所有的都使用该测试表了。
2、聚集索引(主键索引)
① 聚集索引(主键索引)
创建:alter table test_excel add primary key (user_id);
删除:alter table test_excel drop primary key
3、非聚集索引
① 普通索引
创建:alter table test_excel add index index_name(user_cardid)
删除:alter table test_excel drop index index_name
② 唯一索引
创建:alter table test_excel add unique index_age(user_age)
删除:alter table test_excel drop index index_age
③ 全文索引
创建:alter table test_excel add fulltext index_name(user_name,user_cardid)
删除:alter table test_excel drop index index_name
④ 复合索引
创建:alter table test_excel add index index_name(user_name,user_age,user_cardid)
删除:alter table test_excel drop index index_name
四、根据sql创建索引(索引实战)
1、=,>=,<=,<>,and,or
① from test_excel where user_cardid = 'xxx'
使用普通索引:alter table test_excel add index index_cardid(user_cardid)
② from test_excel where user_cardid = 'xxx' and user_age = 'xxx' and user_name = 'xxx'
包含了(=,and),这种情况既可以使用普通索引也可以使用复合索引,这里建议使用普通索引,因为普通索引只需要建立一个字段即可生效。建议:使用索引的字段放在条件查询里的最前面,如:user_cardid字段放在最前面
使用普通索引:alter table test_excel add index index_cardid(user_cardid)
在值重复并有很多个and时建议使用复合索引:alter table test_excel add index index_name(user_cardid,user_age,user_name)
③ from test_excel where user_cardid = 'xxx' and user_age = 'xxx' or user_name = 'xxx'
包含了(=,and,or),and的处理,可以参考②的方法,or时则必须再创建个单独的索引,不然会没有效果
使用普通索引:alter table test_excel add index index_name(user_name)
④ from test_excel where user_cardid = 'xx' and user_age >= 80 and user_age <= 100 and user_name <> 'xx'
包含了(=,and,>=,<=,<>),普通索引和复合索引都可以使用,这里使用复合索引
使用复合索引:alter table test_excel add index index_name(user_cardid,user_age,user_name)
注意:包含范围查询的,都有查询“数据量”的限制,数据量太多时会不走索引,并且范围查询索引等级只能在“range”级
2、in,not in,is null,is not null
建立普通索引就可以了,其实和上面的第④点是一样的,不在重复写了,但是也有注意查询的数据量,数据量多了后也不会走索引
3、like,order by
① from test_excel where user_name like '张三129%'
这种同样使用普通索引:alter table test_excel add index index_name(user_name)
注意:like '%xxx',%在最左边的这种是不能使用索引的,其它位置才能使用索引,如果%一定要在最左边,就只能使用覆盖索引了如还有一个user_age字段:alter table test_excel add index index_name(user_name,user_age)
② from test_excel where user_age < 5000 order by user_age desc
使用普通索引:alter table test_excel add index index_age(user_age)
4、连表查询(左连接查询left join)
from test_excel e
left join test_pay p
on e.user_id = p.user_id
where e.user_id = '1499561693366382961' and e.user_name = '张三1299000'
and p.pay_id = 1 and p.pay_number = 'xxx' 使用复合索引:alter table test_excel add index index_sum(user_id,user_name)
alter table test_pay add index index_sum(pay_id,pay_number)
在连表查询时一般的字段都是非常多的(这里只是做了个例子),所以一般也都是建议建立复合索引,当然建立普通索引也是有效果的,但对MySQL来说,一次是只能使用一条索引的,字段超级多的时候普通索引肯定是没复合索引效率高的;
总结
使用索引,一定要记得最左原则,建了索引的列要在条件查询里的最前面,索引的使用是需要非常注意顺序的,不然是很难走索引的;
复合索引查询条件顺序:如创建索引(alter table test_excel add index index_name(A,B,C)),那么你查询的条件顺序只能是(A),(AB),(ABC),这种排序效率才是最高的:(where a='xxx' and b='xxx' and c='xxx');
查询一个表所有的索引:show index from test_excel
查询一条语句是否走了索引:explain select * from test_excel,加上explain关键字即可;
索引的type等级:all,index,range,ref,eq_ref,system,const;“all,index”相当于没走索引,索引至少要优化到range级
注意:有的时候创建索引后查询速度反而会更慢,先检查一下创建的索引是不是存在冲突,如果语句没问题,可以把索引删了重新创建。