1、今天争取把这个工具的所有操作都罗列出来
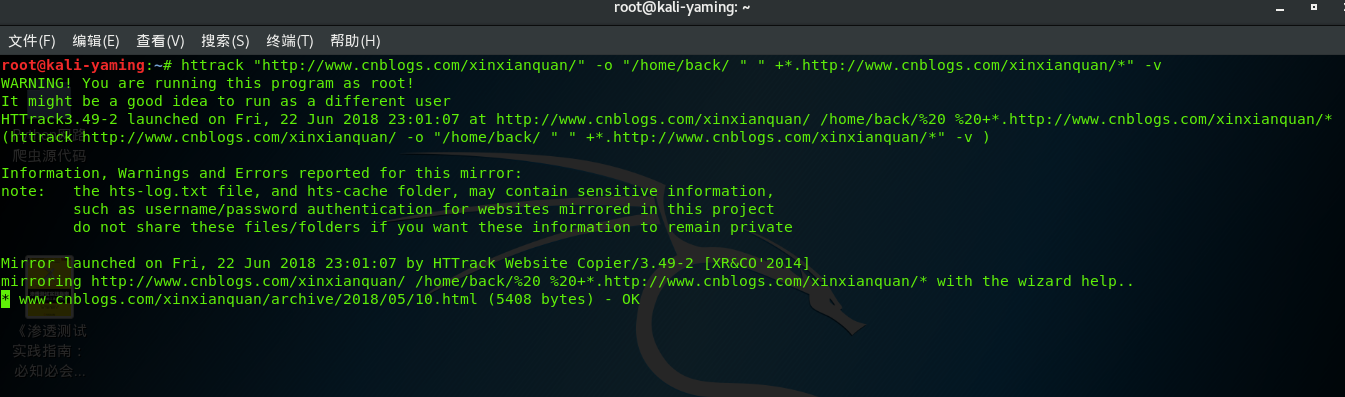
首先打开kali 中的这个工具 Web信息收集工具HTTrack ,会直接出现出现使用语法。
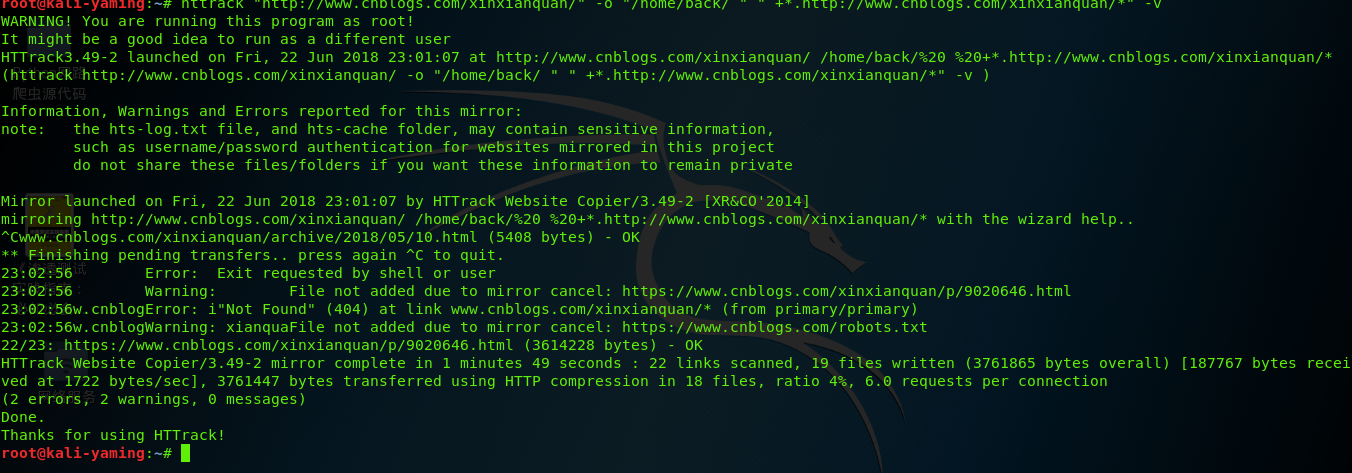
对于传统的像存在Robots.txt的网站,如果程序运行的时候不做限制,在默认的环境下程序不会把网站镜像,简单来说HTTPrack跟随基本的JavaScript或者APPLet、flash中的链接,对于复杂的链接(使用函数和表达式创建的链接)或者服务器端的ImageMap则不能镜像。
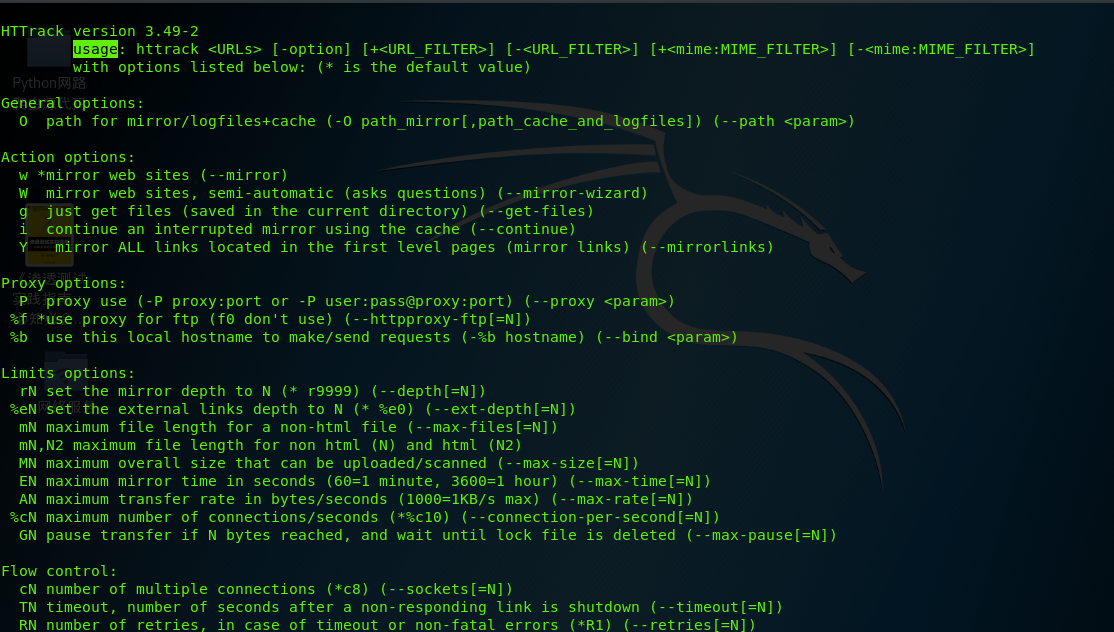
2、将一般的参数选项做个解释
Enter project name //输入项目名称, 程序会自动生成一个本地项目名称
Enter URLs (separated by commas or blank spaces) //欲抓取的网站地址
注意的是 Action中的参数操作:
(enter) 1 Mirror Web Site(s) 镜像网站
2 Mirror Web Site(s) with Wizard 镜像网站和向导
3 Just Get Files Indicated 只获得文件中声明的文件
4 Mirror ALL links in URLs (Multiple Mirror) 在URl中所有的链接 多镜
5 Test Links In URLs (Bookmark Test) 书签测试
0 Quit 退出
Proxy (return=none) : 如果没有代理 不选择代理
You can define wildcards, like: -*.gif +www.*.com/*.zip -*img_*.zip
Wildcards (return=none) : //使用通配符下载,我直接回车
3、对HTTPrack的安装,如果是kali 则系统直接集成了该工具,LinuX或者其他麒麟系统没有的可以使用 apt -get install 安装
4、具体扒皮一个网站如下