最近有需求是查两个公司之间的投资关系 比如 a和b之间有哪些直接投资和间接投资。
例如
a->b
a->e->b
a->c->d->b
b->f->a
需求是查出7跳以内的ab之间的投资关系
v的标签是company_name,属性是company_name ,eid 其中id=eid
e的标签是invest,属性是 stock_percent
最开始写的查询语句是
g.V()
.has('company','company_name',P.within('公司B','公司A')) --找到a b两个公司的点
.repeat(outE('invest').otherV().simplePath()) --通过外边一直向外辐射
.until(and( --直到 两个条件都满足
loops().is(lte(7)), --条件1 循环7次以内
has('company','company_name',P.within('公司B','公司A'))) --a->b b->a的路线
)
.path()
.by(valueMap('company_name')).by(valueMap('stock_percent'))
这个查询本身没有问题。 and里面两个条件分开写 普通查询也没问题,但是在查询一个点边比较多时 7跳后有3000路径的数据时出现了超时问题。
按照专业人士说,这个查询使用and作为退出traversal条件,但是tinkerpop编译器很笨,只要until内部条件是false,就会跳数+1再进行traversal,不会识别until内部复杂条件,导致实际从一个点遍历了一个子图,涉及的中间点边非常多,最终导致超时
最后优化后
g.inject(1).union(V().has('company','company_name', P.within("公司2","公司1")))--这里可以直接g.V().has() 我这里union是因为可以同时company_name 和eid去查
.repeat(outE('invest').otherV().simplePath()).times(7).emit() --收集1-7跳的所有路径
.or(has('company','company_name',P.within("公司4","公司7")),has('company','company_name',P.within("公司6","公司5")))
.path().by('company_name').by('stock_percent')
在优化查询时遇到了这个问题。
g.V().has('company','company_name', P.within("公司1")).repeat(outE('invest').otherV().simplePath()).times(7).emit().has('company','company_name',P.within("公司7")).path().by('company_name').by('stock_percent')
g.V().has('company','company_name', P.within("公司1")).repeat(outE('invest').otherV().simplePath()).times(7).emit(has('company','company_name',P.within("公司7"))).path().by('company_name').by('stock_percent')
请问这两个查询有什么区别。
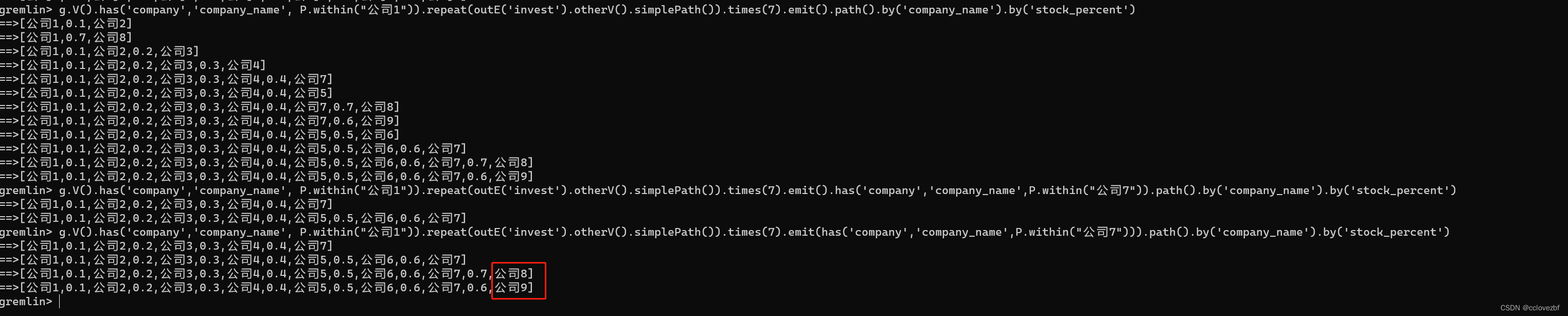
前者会先获取 1-7跳的所有数据,然后再过滤最后节点为公司7的数据
后者是收集所有含有节点为公司7的数据,并且直到7跳,也就是说我到了公司7的节点,还要继续往后面跳
上面仅供参考 开始硬核处理。
上面的结果在outE改为bothE之后查询还是卡住了。卡住了怎么办?各位老哥有何良策。
这时候要介绍两个方法profile()和explain().
算了不搞了。搞来搞去跳数太多了 最后需求必须用bothE 6跳后的路径有32E 7跳后的路径有300多亿,实在搞不下去了。
最后直接减少跳数为4跳。