问题描述:
今天测试提了个bug: 说在富文本编辑器上编辑了公告内容后,再查看公告的时候,页面上展示内容格式却乱码了,是有什么格式要求吗?
接收到问题后,我马上进行了问题复现:
果然在查看公告内容的时候,出现了HTML文本未能正常解析的问题:

查看代码,代码是直接使用v-html解析接口返回的数据,我改变了一下v-html的变量取的是data里的htmlStr='<p>这是内容</p>',p标签内的信息却能被正常解析渲染出来。那为什么会乱码呢?

再查看接口返回的数据内容:
<p><b>1.这是加粗文字</b></p><p><b><font size="6">2.这是加粗大号文字</font></b></p><p><font size="5" style="background-color: rgb(255, 255, 255);" color="#ff0000">3.这是红色字体</font></p><p><span style="background-color: rgb(0, 255, 0);">4.这是背景色为绿色的字体</span></p><p><br></p>
原来是后端对前端传过去的HTML结构进行了一层转义(html编码)处理,直接使用v-html无法解析成功,展示的会是HTML源代码。
解决方法:
既然后端对HTML进行了转义处理,那么在渲染数据之前,当然要对HTML进行反转义(html解码)处理了,才能使用v-html正常渲染出html标签。
于是我封装了HTML反转义的方法,放入项目工具库中:
//html反转义
HTMLDecode(text) {
var reg = /<[^>]+>/g;
if (reg.test(text)) {
return text;
}
var temp = document.createElement('div');
temp.innerHTML = text;
var output = temp.innerText || temp.textContent;
temp = null;
return output;
},在渲染数据之前,先调用这个函数,对html进行反转义处理
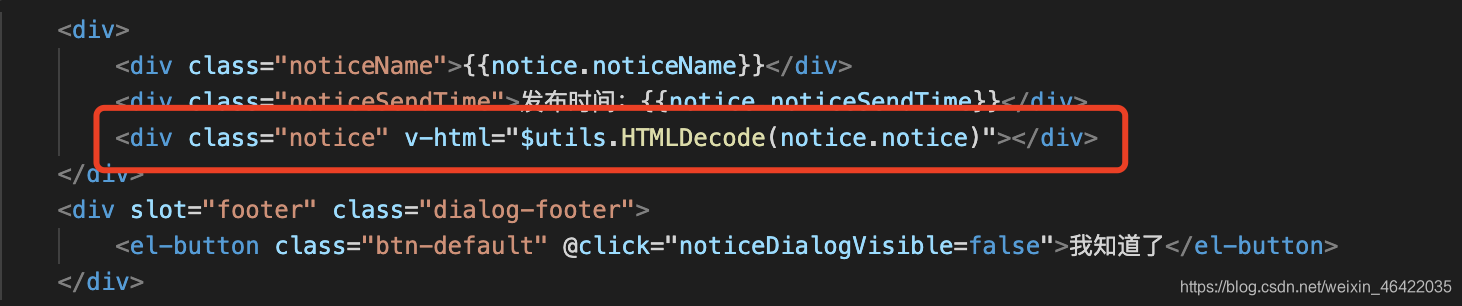
再查看页面信息,HTML结构就能正常解析渲染出来了:

反转义后的HTML结构可以被正常解析渲染,问题也就解决啦,可以把bug指回给测试了。

在最后,小小补充一下,我在学习过程中,用JS实现HTML转义和反转义的常用方法总结:
JS实现html转义和反转义主要有两种方式:
1.利用用浏览器内部转换器实现html转义;
2.用正则表达式实现html转义;
JS工具方法总结:
let HtmlUtil = {
2 /*1.用浏览器内部转换器实现html编码(转义)*/
3 htmlEncode:function (html){
4 //1.首先动态创建一个容器标签元素,如DIV
5 var temp = document.createElement ("div");
6 //2.然后将要转换的字符串设置为这个元素的innerText或者textContent
7 (temp.textContent != undefined ) ? (temp.textContent = html) : (temp.innerText = html);
8 //3.最后返回这个元素的innerHTML,即得到经过HTML编码转换的字符串了
9 var output = temp.innerHTML;
10 temp = null;
11 return output;
12 },
13 /*2.用浏览器内部转换器实现html解码(反转义)*/
14 htmlDecode:function (text){
15 //1.首先动态创建一个容器标签元素,如DIV
16 var temp = document.createElement("div");
17 //2.然后将要转换的字符串设置为这个元素的innerHTML(ie,火狐,google都支持)
18 temp.innerHTML = text;
19 //3.最后返回这个元素的innerText或者textContent,即得到经过HTML解码的字符串了。
20 var output = temp.innerText || temp.textContent;
21 temp = null;
22 return output;
23 },
24 /*3.用正则表达式实现html编码(转义)*/
25 htmlEncodeByRegExp:function (str){
26 var temp = "";
27 if(str.length == 0) return "";
28 temp = str.replace(/&/g,"&");
29 temp = temp.replace(/</g,"<");
30 temp = temp.replace(/>/g,">");
31 temp = temp.replace(/\s/g," ");
32 temp = temp.replace(/\'/g,"'");
33 temp = temp.replace(/\"/g,""");
34 return temp;
35 },
36 /*4.用正则表达式实现html解码(反转义)*/
37 htmlDecodeByRegExp:function (str){
38 var temp = "";
39 if(str.length == 0) return "";
40 temp = str.replace(/&/g,"&");
41 temp = temp.replace(/</g,"<");
42 temp = temp.replace(/>/g,">");
43 temp = temp.replace(/ /g," ");
44 temp = temp.replace(/'/g,"\'");
45 temp = temp.replace(/"/g,"\"");
46 return temp;
47 },
48 /*5.用正则表达式实现html编码(转义)(另一种写法)*/
49 html2Escape:function(sHtml) {
50 return sHtml.replace(/[<>&"]/g,function(c){return {'<':'<','>':'>','&':'&','"':'"'}[c];});
51 },
52 /*6.用正则表达式实现html解码(反转义)(另一种写法)*/
53 escape2Html:function (str) {
54 var arrEntities={'lt':'<','gt':'>','nbsp':' ','amp':'&','quot':'"'};
55 return str.replace(/&(lt|gt|nbsp|amp|quot);/ig,function(all,t){return arrEntities[t];});
56 }
57 };以上是个人的一点小总结,如有不正之处还请谅解和指正,谢谢!