知识推理简介
1.知识推理任务分类
推理就是通过各种方法获取新的知识或者结论,这些知识和结论满足语义。其具体任务可分为可满足性(satisfiability)、分类(classification)、实例化(materialization)。
可满足性可体现在本体上或概念上,在本体上即本体可满足性是检查一个本体是否可满足,即检查该本体是否有模型。如果本体不满足,说明存在不一致。概念可满足性即检查某一概念的可满足性,即检查是否具有模型,使得针对该概念的解释不是空集。
2.知识推理简介
OWL本体语言是知识图谱中最规范(W3C制定)、最严谨(采用描述逻辑)。表达能力最强的语言(是一阶谓词逻辑的子集),它基于RDF语法,使表示出来的文档具有语义理解的结构基础。促进了统一词汇表的使用,定义了丰富的语义词汇。同时允许逻辑推理。
关于OWL语言的逻辑基础:描述逻辑。
描述逻辑
描述逻辑(Description Logic)是基于对象的知识表示的形式化,也叫概念表示语言或术语逻辑,是一阶谓词逻辑的一个可判定子集。
一个描述逻辑系统由四个基本部分组成:
一、最基本的元素有概念、关系、个体。
概念即解释为一个领域的子集
关系解释为该领域上的二元关系(笛卡尔积)
个体解释为一个领域内的实例
二、TBox术语集:概念术语的公理集合
它是泛化的知识,是描述概念和关系的知识,被称之为公理(Axiom)。由于概念之间存在包含关系,TBox 知识形成类似格(Lattice)的结构,这种结构是由包含关系决定的,与具体实现无关。TBox语言有定义和包含,其中定义为引入概念及关系的名称,如Mother、Person、has_child,包含指声明包含关系的公理
三、Abox断言集:个体的断言集合
指具体个体的信息,ABox包含外延知识(又称为断言(Assertion)), 描述论域中的特定个体。描述逻辑的知识库 K:= <T, A>, T即TBOx, A即ABOx。ABox 语言包含概念断言和关系断言,概念断言即表示一个对象是否属于某个概念,例如Mother(Alice)、Person(Bob)。关系断言表示两个对象是否满足特定的关系
四、TBox 和 ABox上的推理机制
描述逻辑语义:解释I是知识库K的模型,当且仅当I是K中每个断言的模型。若一个知识库K有一个模型,则称K是可满足的。若断言σ对于K的每个模型都是满足的,则称K逻辑蕴含σ,记为。对概念C,若K有一个模型I使得则称C是可满足的。
描述逻辑依据提供的构造算子,在简单的概念和关系上构造出复杂的概念和关系。描述逻辑至少包含以下构造算子:交 (),并(),非 (¬),存在量词 ()和全称量词 ()。有了语义之后,我们可以进行推理。通过语义来保证推理的正确和完备性。
本体推理方法与工具
基于本体推理的方法常见的有基于Tableaux运算的方法、基于逻辑编程改写的方法、基于一阶查询重写的方法、基于产生式规则的方法等。
一、基于Tableaux运算
基于Tableaux运算适用于检查某一本体的可满足性,以及实例检测。其基本思想是通过一系列规则构建Abox,以检测可满足性,或者检测某一实例是否存在于某概念。这种思想类似于一阶逻辑的归结反驳。
Tableaux运算规则(以主要DL算子举例)如下:

这里对第一个解释一下,第一个是说如果C 和D(x) 的合取是,同时呢C(x) 和 D(x) 却不在里,那么也就是说有可能只包含了部分C,而C(x)不在里面,那么我们就把它们添加到里。
Tableaux运算的基于Herbrand模型,Herbrand模型你可以把它简单的理解为所有可满足模型的最小模型。
二、基于逻辑编程改写的方法
本体推理具有一定的局限性,如仅支持预定义的本体公理上的推理,无法针对自定义的词汇支持灵活推理;用户无法定义自己的推理过程等。因此引入规则推理,它可以根据特定的场景定制规则,以实现用户自定义的推理过程。
基于以上描述,引入Datalog语言,它可以结合本体推理和规则推理。面向知识库和数据库设计的逻辑语言,表达能力与OWL相当,支持递归,便于撰写规则,实现推理。
Datalog 的基本语法包含:
原子(Atom): 其中p是谓词,n是目数, 是项 (变量或常量),例如 has_child(X, Y);
规则(Rule):由原子构建,其中H 是头部原子,是体部原子。例如: has_child X, Y : −has_son X, Y
事实(Fact): 它是没有体部且没有变量的规则,例如 has_child Alice, Bob : −
Datalog程序是规则的集合;
三、基于一阶查询重写的方法
基于查询重写我们可以高效地结合不同数据格式的数据源;同时重写方法关联起了不同的查询语言。
一阶查询是具有一阶逻辑形式的语言,因为Datalog是数据库的一种查询语言,同时具有一阶逻辑形式,因此可以以Datalog 为中间语言,首先重写SPARQL 语言为Datalog ,再将Datalog 重写为SQL 查询。
四、基于产生式规则的方法
产生式系统是一种前向推理系统,可以按照一定机制执行规则从而达到某些目标,与一阶逻辑类似,但也有区别。被应用于自动规划、专家系统上。
产生式系统由: 事实集合(Working Memory)、产生式/规则集合、推理引擎组成:
事实集/运行内存(Working Memory, WM): 是事实的集合,用于存储当前系统中所有事实。
事实(Working Memory Element,WME),包含描述对象和描述关系。描述对象形如,其中type, attr_i , val_i 均为原子 (常量),例如 (student name: Alice age: 24)。描述关系(Refication),例如 (basicFact relation:olderThan firstArg: John secondArg: Alice)简记为(olderThan John Alice)。
产生式集合(Production Memory, PM)就是产生式的集合。产生式就是类似于这种的语句。其中conditions 是由条件组成的集合,又称为LHS。actions 是由动作组成的序列,称为RHS 。
LHS 是条件(condition)的集合,各条件之间是且的关系,当LHS 中所有条件均被满足,则该规则触发。条件的形式为:
RHS是动作序列,即执行时的顺序,是依次执行的,动作的种类包含 ADD pattern、 REMOVE i、MODIFY i( attr spec ) 。
推理引擎:它可以控制系统的执行,包含模式匹配(用规则的条件部分匹配事实集中的事实,整个LHS都被满足的规则被触发,并被加入议程(agenda))、解决冲突(按一定的策略从被触发的多条规则中选择一条)、执行动作(执行被选择出来的规则的RHS,从而对WM进行一定的操作)。
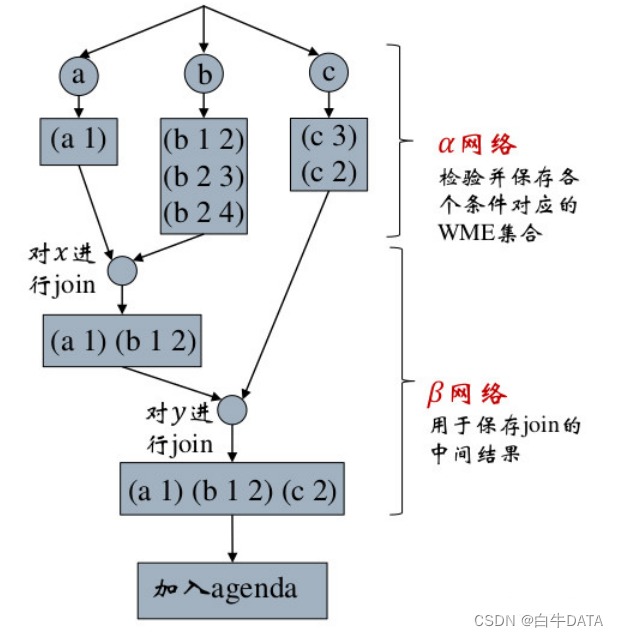
模式匹配 RETE 算法
模式匹配即用每条规则的条件部分匹配当前WM。一种高效的模式匹配算法是RETE 算法,1979年由Charles Forgy(CMU)提出,将产生式的LHS组织成判别网络形式,是一种典型的以空间换时间的算法。其流程如下图所示:
相关工具介绍
Drools
Drools 是商用规则管理系统,其中提供了一个规则推理引擎,核心算法是基于RETE算法的改进。提供规则定义语言,支持嵌入Java代码。
Jena
Jena 用于构建语义网应用Java 框架,提供了处理RDF、RDFs、OWL 数据的接口,还提供了一个规则引擎。提供了三元组的内存存储于查询。
RDF4J
RDF4J 是一个处理RDF 数据的开源框架,支持语义数据的解析、存储、推理和查询。能够关联几乎所有RDF存储系统,能够用于访问远程RDF存储。