目录
- 写在前面
- 名词定义
- 流量策略相关
-
- 问题1:一级服务是否会被驱逐?如果不能,一旦一级服务发生故障,该怎么办?有什么快速失败的方法?
- 问题2:二级及二级之后的服务是否应该设置连接池?如果设置了连接池,它的下游服务在配置了异常值检测的情况下,是否会因为上游服务连接池溢出而被驱逐?
- 问题3:如果在二级及之后的服务不设置连接池的情况下,应该怎么保护这些次级服务以防大流量的冲击?是通过envoyfilter的速率限制吗?
- 问题4:如果是HTTP/2,那么connectionPool的限制是否生效?为何HTTP/2每个实例都建立两个连接?
- 问题5:上游服务的断路器是如何实现的?
- 问题6:连接池的大小设定是为了限流吗?
- 问题7:在网格的pod内,应用程序对sidecar的链接与sidecar与上游服务的链接是什么关系?
- 问题8:在连接池溢出导致熔断后,下游服务会收到503,这个503是谁返回的
写在前面
当初因业务需求,我们升级了技术架构,在多番比较之后,最终选择了前沿技术框架servicemesh……代表性之一的istio。在入了坑之后才发现,这玩意儿的资料在国内真不算多,各种配置在官方文档虽然有介绍,但是大多数都是浅浅的几笔带过,在真正上生产使用的时候,就需要不断的自行探究他的实现机制,否则你就不知道这个参数为什么要这么设置,这么设置是否对你的业务场景来说是合适的。
虽然istio是开源框架,但我作为一个运维角色,对代码没有过深的造诣,不能像很多大神一样直接通过研究代码来透析本质,因此只能在不断的实践与实验中去寻找”真相“,本文就是记录我在使用istio过程中遇到的各种疑问,有些已经得到了实际验证,有些还没有具体结果,需要在之后的工作中与学习中不断探索。
文章会持续更新,增加新问题,解决老问题,或者更新老问题。
名词定义
服务级别
注意:以下设定仅是本文为方便描述自行定义。
-
一级服务:本文中是指直接被ingressgateway映射端口,可以直接供集群外部调用的服务。
-
二级服务:被一级服务调用的服务,三级、四级服务以此类推
说明:此处的服务级别是相对的,而不是绝对的,目的是为了方便后续说明各个服务之间的调用关系。比如A\B\C三个服务,A服务映射ingressgateway,A调用B,B调用C,那么A就是一级服务,B就是二级服务,C就是三级服务。如果这时有一个D也是映射ingressgateway,D调用C,那么此时C就是二级服务。
流量策略相关
问题1:一级服务是否会被驱逐?如果不能,一旦一级服务发生故障,该怎么办?有什么快速失败的方法?
回答:(推论答案)
以下仅为推论,我还没有实际证据证明,希望有同学了解的,给一个准确答案:
1.他没有下游服务(在不包含ingressgateway的情况下),也就没有服务对他进行被动异常值检测,他只要不是因为健康检查出现问题,应该不会被驱逐实例,但是健康检查出现问题依然会被驱逐。
2.一级服务是被集群外部直接调用的服务,因此外部调用它的服务(或者是client)应该设置对应的策略,比如超时、重试等等,如果是客户端还应该设置一旦请求失败如何展示的问题等
问题2:二级及二级之后的服务是否应该设置连接池?如果设置了连接池,它的下游服务在配置了异常值检测的情况下,是否会因为上游服务连接池溢出而被驱逐?
回答:(可以参考问题8)
问题3:如果在二级及之后的服务不设置连接池的情况下,应该怎么保护这些次级服务以防大流量的冲击?是通过envoyfilter的速率限制吗?
回答:(可以参考问题8)
envoyfilter进行限速是可行的,但是在生产中如何应用,需要持续探索
问题4:如果是HTTP/2,那么connectionPool的限制是否生效?为何HTTP/2每个实例都建立两个连接?
回答:
如果使用HTTP/2,那么connectionPool应该是没有意义了正常来说HTTP/2两个实例之间只有一个链接,所以设置的多或少都不会影响HTTP/2。而且官方文档说的比较明确:
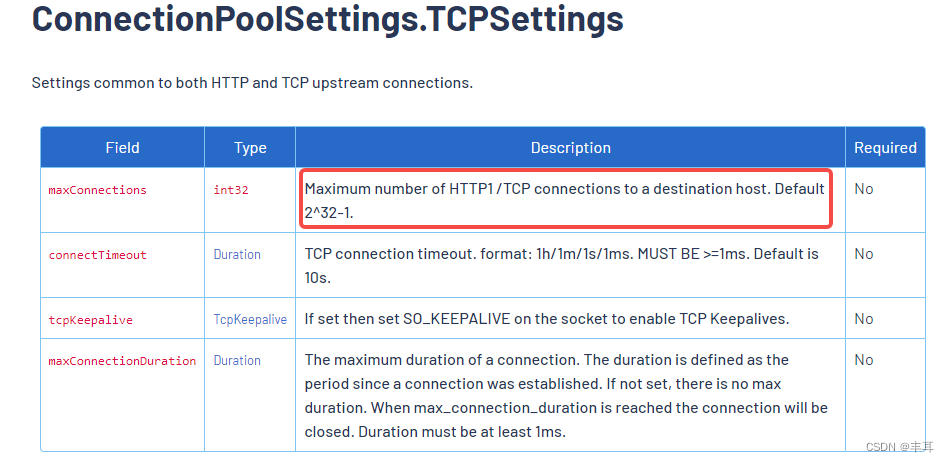
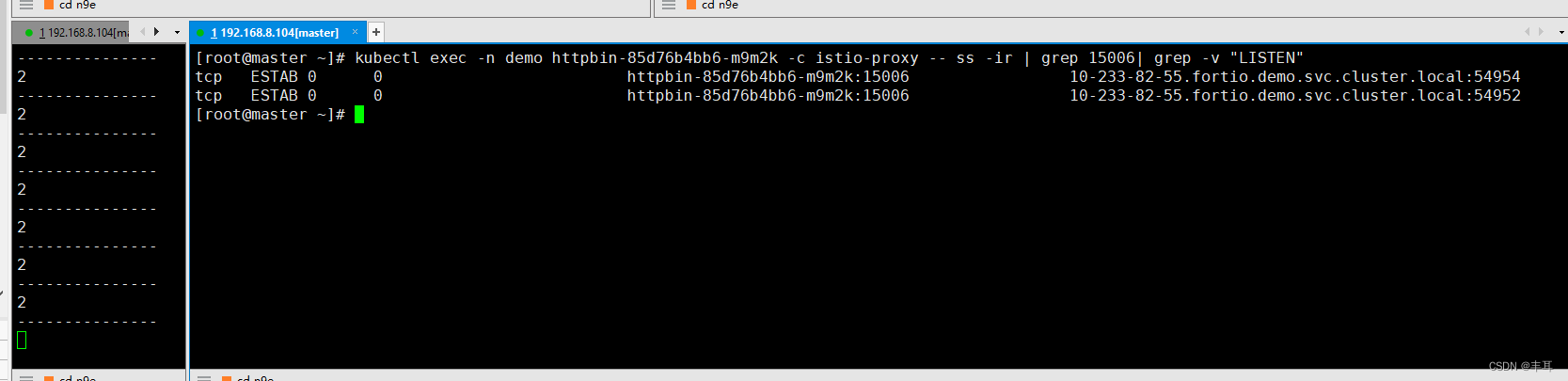
但是在使用HTTP/2的时候我们会发现它会创建两个链接,我在网上找了一下资料:
Istio代理在HTTP/2通信时确实会建立两个TCP连接,这是因为Istio代理需要在两个TCP连接上进行多路复用。其中一个TCP连接用于控制流,另一个TCP连接用于数据流。控制流上的帧用于控制消息的流动,而数据流上的帧则包含实际的请求和响应数据。
说明:本人对通信协议不是很入门,如有错误,烦请指正。
问题5:上游服务的断路器是如何实现的?
回答:
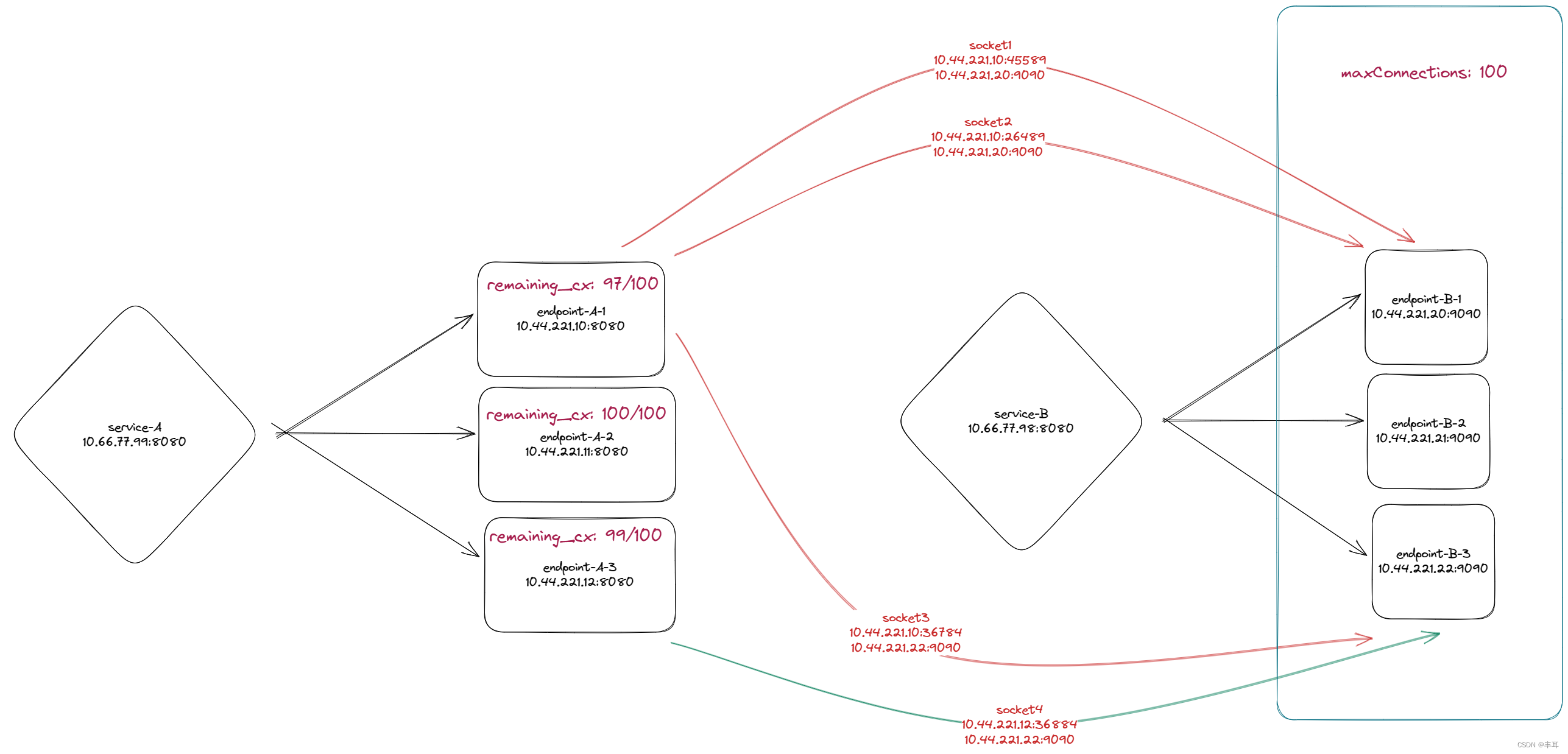
- 在http/1.1协议时,上游服务通过在destinationrule中配置connectionPool,在tcp.maxConnections设置下游每个实例到上游cluster的最大TCP连接数
说明:
下游服务的每个实例与上游服务的cluster的最大TCP连接数,即下游服务如果有三个实例,上游服务也有三个实例,上游服务设置最大连接数设置为100,则下游服务的实例1与上游服务两个实例的连接数之和最大为100,下游服务的实例2与上游服务的连接数之和最大也为100,实例3同理。
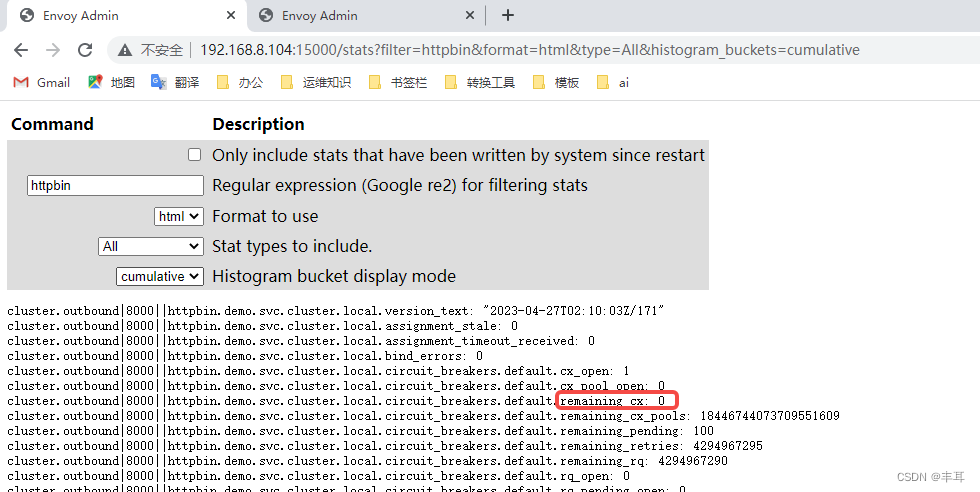
而不是说下游集群与上游集群的最大连接数是100。这个控制的值可以在istio-proxy的15000/stat中的remaining_cx查询到,如下边的示例演示。
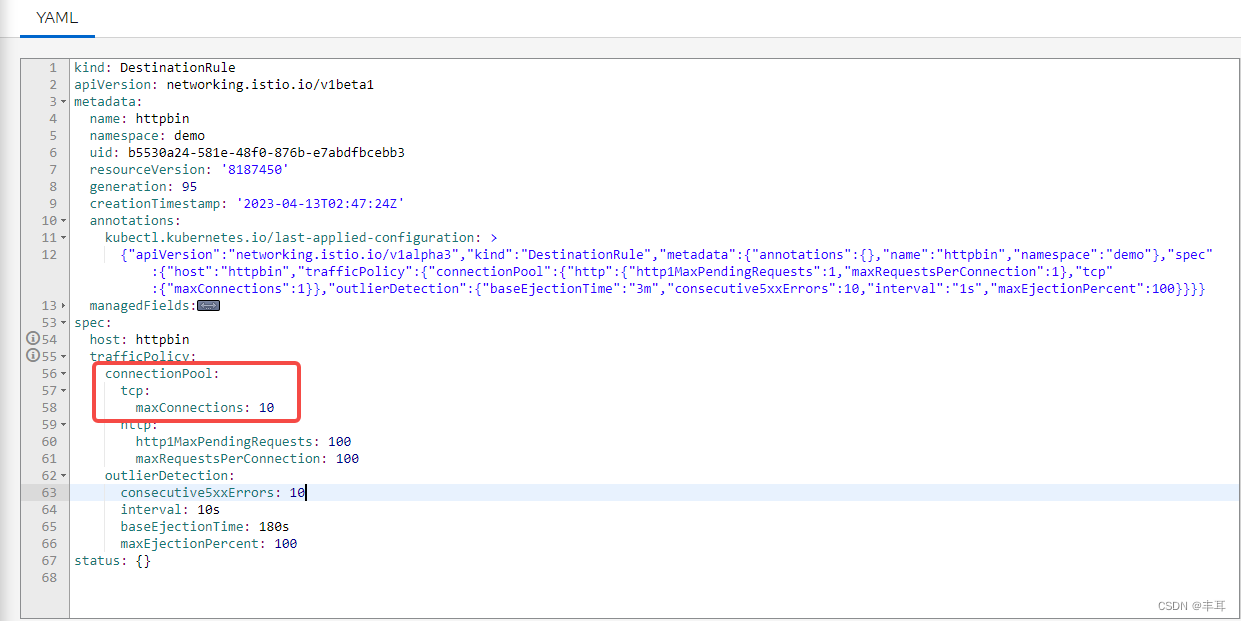
验证:
httpbin设置最大连接数是10
这边起了两个fortio实例:
注意看访问的映射端口是不同的,一个是15000,一个是25000
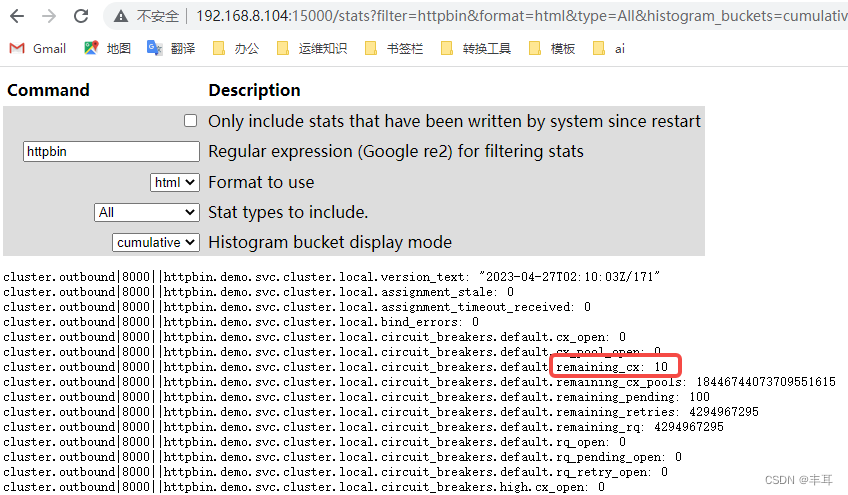
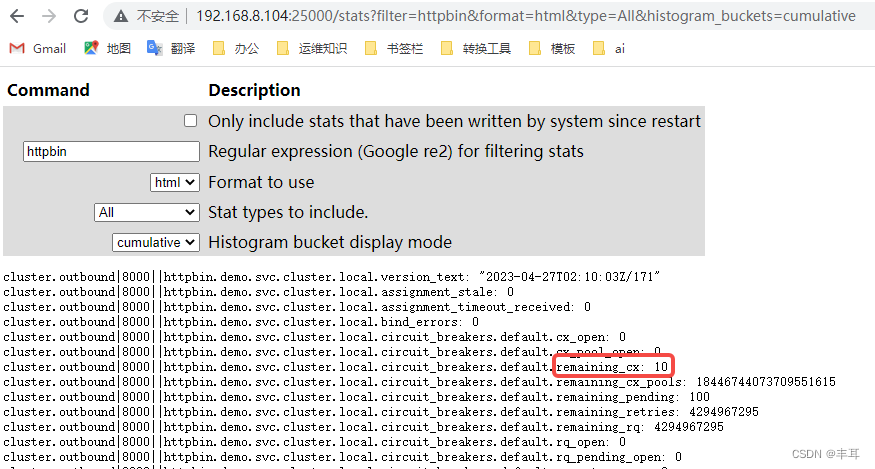
可以看到每个都是显示剩余10个连接。
然后看httpbin中,每个来自15006的连接都是0(此处为了更加显著的显示结果,只有fortio来调用httpbin,所以直接过滤15006的连接即可)
- 第一步,先从一个fortio发起调用:

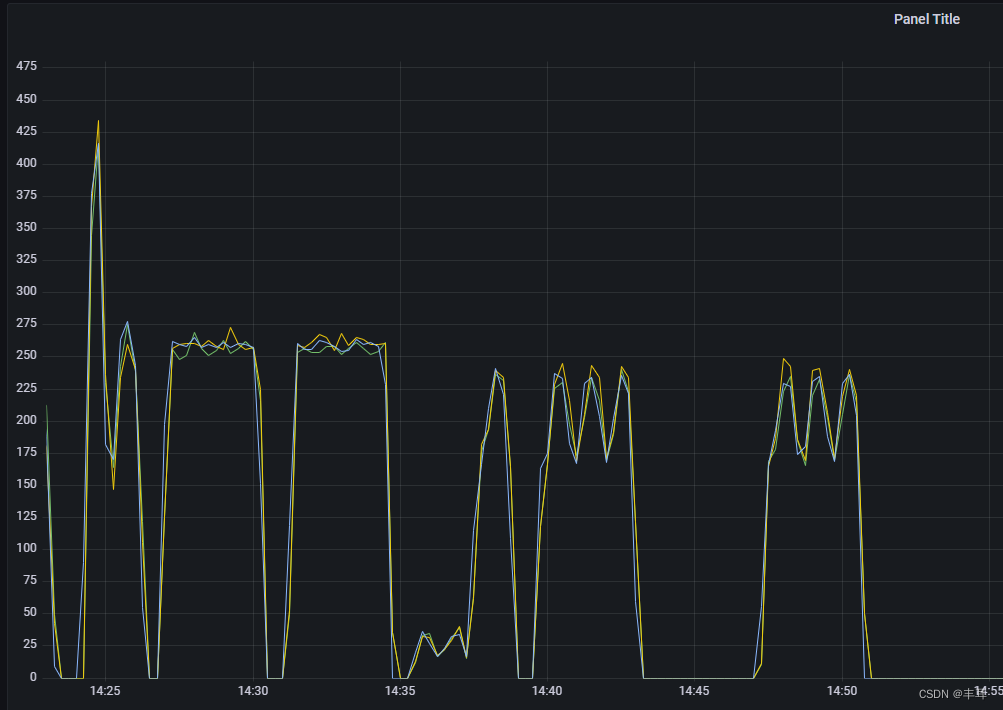
直接起了10个并发,为了持续时间长一点儿,我们发送2000000个请求,可以看到,此时的remaining_cx值已经变为0
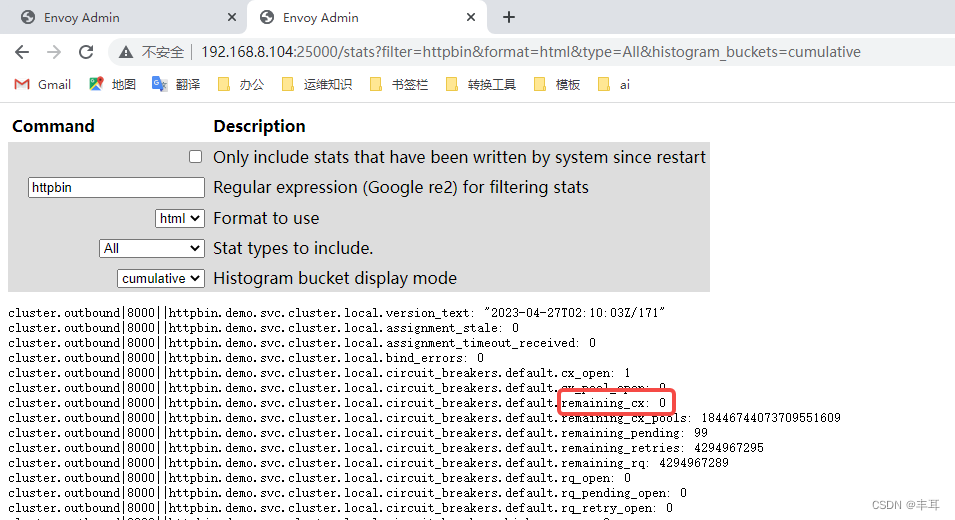
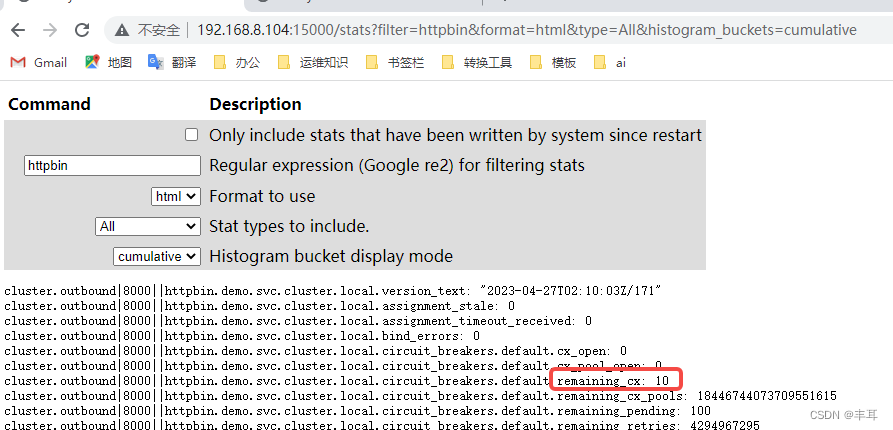
但是另一个pod的remaining_cx值仍然为10
再看三个httpbin里边的连接数,三个pod相加是10,这个时候就是再增加并发数,它们的相加之和也是10。
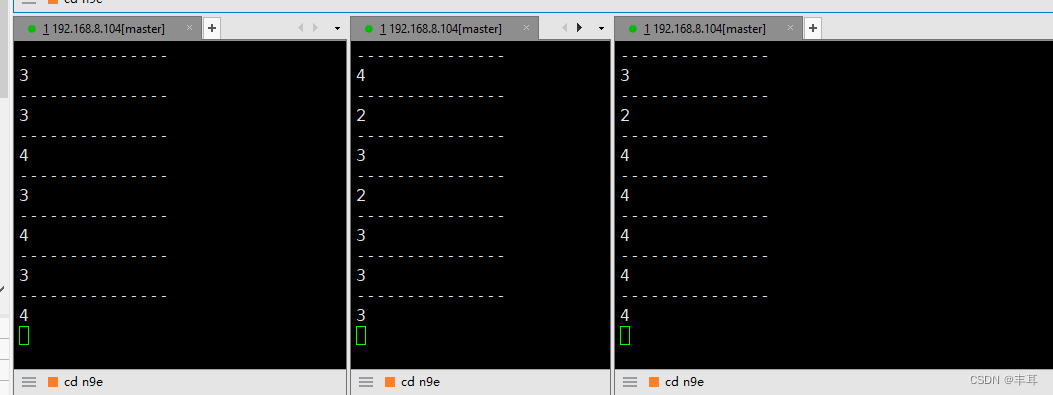
- 接着我们启动另一个pod对httpbin的请求
连接之和已经为20了
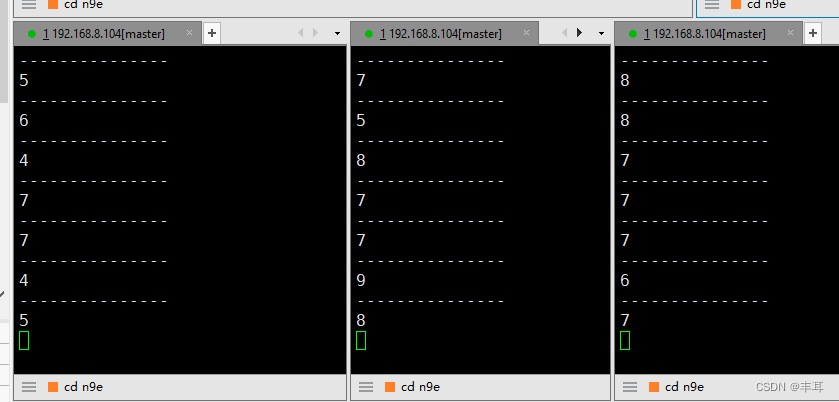
-
那么单个httpbin的实例会超过设定的10个连接吗?我们把fortio改为3个实例,把httpbin将为2个实例,来测试一下

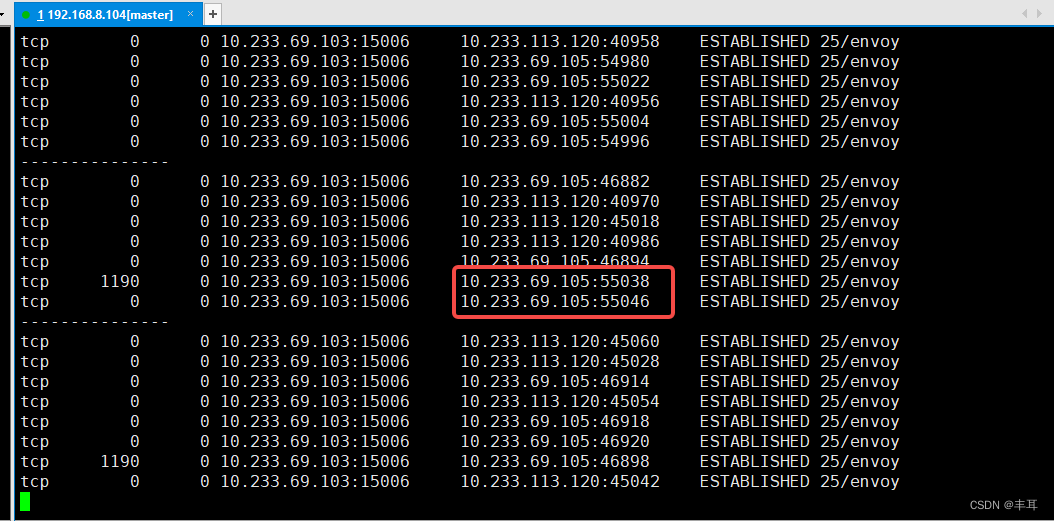
很显然,单个实例是会超过设定的最大连接数的,这也从侧面证明了,这个最大TCP连接数,限定的就是下游服务的单个实例与上游服务cluster之间的连接数。 -
在http/1.1协议中,对于maxRequestsPerConnection的设置,懂http协议的同学应该明白是怎么回事,http/1.1即使是长链接状态下,一次也只能发送一个请求,等到返回才会发起另一个请求,达到最大请求数后,这个连接就会close,再建立一个新的连接。这样大家也就明白了这个参数在istio配置中的作用了吧。
-
http1MaxPendingRequests没啥好说的,就是等待队列,对http/1.1和http2都生效
那么据此,我么可以简单推导一下上下游服务的最大连接数和实例数之间的关系:
数学水平一半,推导有误,恳请指正
B服务单个实例可承受最大链接数a,B服务设置最大连接数x,共有y个实例
A服务作为下游服务,共计b个实例,每个实例到B服务都可以发起x个链接,所以B服务共可以发起xb个链接
要使B服务不会过载,则应该满足:xb/y<=x<=a
当x=a时:
b/y<=1
b<=y
当x<a时:
b/y<a/x
由此可知:b<=ay/x
这只是简单的推导,现实情况远远比这个复杂,需要根据实际情况具体计算
问题6:连接池的大小设定是为了限流吗?
回答:
连接池大小的设定与限流是有一定联系的,但它们并不等同。
连接池大小的设定是为了限制与其他服务建立和保持连接的数量,从而避免连接超负荷或者资源浪费,同时优化应用程序的性能和稳定性。
而限流是通过限制每秒钟可以处理的请求数量,来限制应用程序的流量和请求负载。在Istio中,限流可以通过基于规则的配额设置实现。
两者不同的地方在于,连接池大小的设定是针对建立和保持连接的数量,而限流则是针对每秒钟可以处理的请求数量。虽然连接池大小的设定可以在一定程度上控制应用程序的流量,但它并不是限流的直接实现。
综上所述,连接池大小的设定和限流都是优化应用程序性能和稳定性的手段,但它们是两个不同的概念和实现方式。
问题7:在网格的pod内,应用程序对sidecar的链接与sidecar与上游服务的链接是什么关系?
回答:
- 如果是HTTP/2,那没啥好说的,都是单个长链接。
- 如果应用程序使用HTTP/1.1,如果没做特别配置,sidecar默认会对上游使用HTTP/1.1。虽然envoy支持HTTP/1.1与HTTP/2的转换,但是因为istio认为如果强行将HTTP/1.1与HTTP/2进行转换,可能会影响稳定性与准确性等等,比如在HTTP/2的传输过程中一旦丢包,那在HTTP/1.1那边就容易出现问题。说到此处,也就能引出envoy的另一个特性,对于envoy本身来说,他的上有链接和下游链接是解耦的,这也就是为什么它可以进行HTTP/1.1与HTTP/2转换的原因;既然envoy将上下游链接解耦了,那么上下游链接就不会存在必然的关系。但是间接的正相关关系还是存在的,毕竟下游链接和请求多了,在连接池范围内,上游的链接和请求也会增加。
下面以bookinfo的例子解释一下:
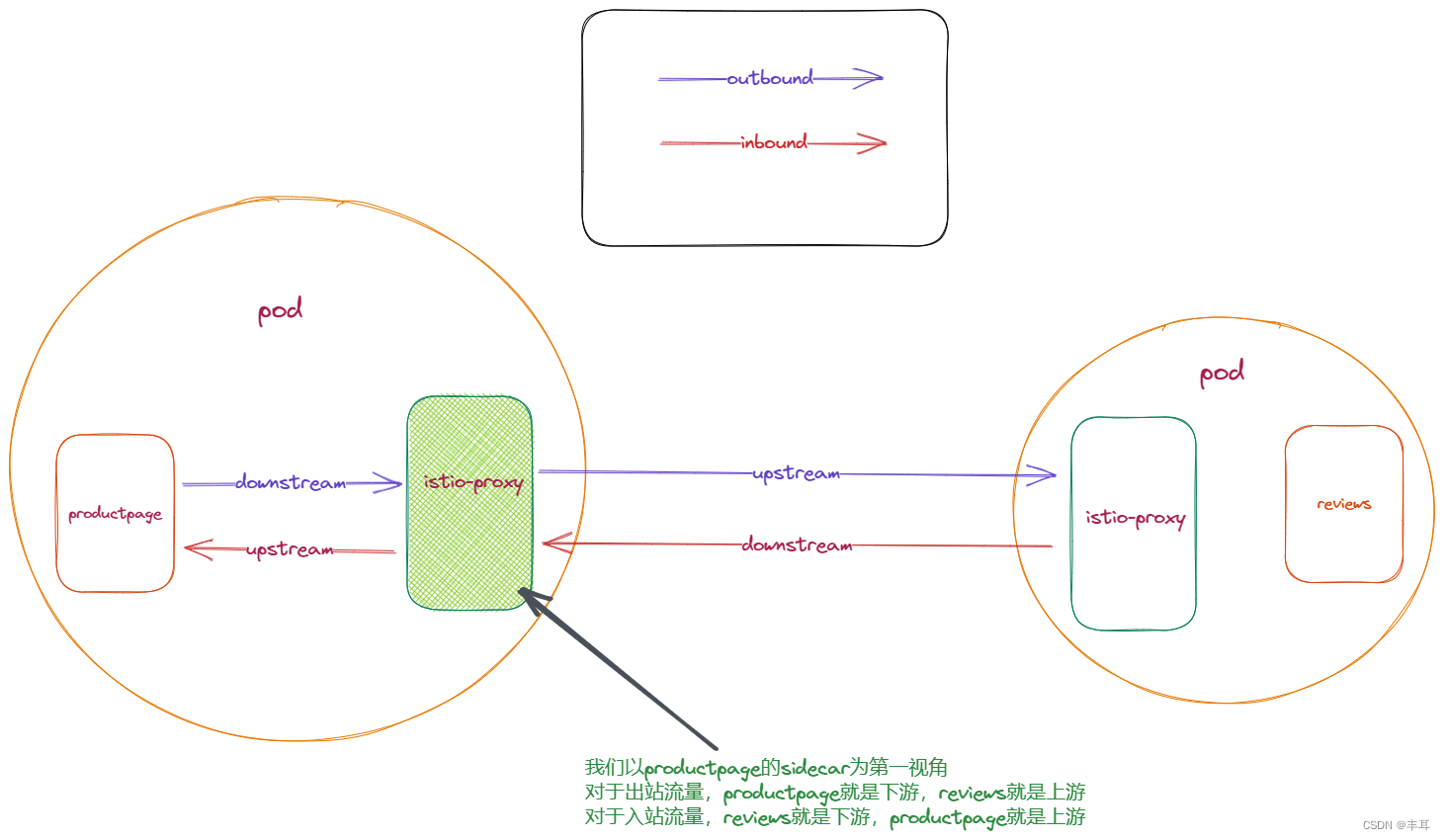
上游和下游是相对的,当我们以sidecar为视角去看待链接时,对于outbound流量,他的下游就是同pod里的应用程序,而上游就是访问的目标cluster,对于inbound流量,则正好相反。
无论时outbound还是inbound,sidecar对于它上下游的链接都是解耦的。也就是说,它上下游链接的生命周期是不一致的,比如使用HTTP/1.1的时候,上游可能有100个链接,下游可能有50个链接,再比如对于outbound,下游是HTTP/1.1,在配置了h2UpgradePolicy: UPGRADE,那么上游就是HTTP/2。
问题8:在连接池溢出导致熔断后,下游服务会收到503,这个503是谁返回的
回答:
当前服务的sidecar返回的503。
在istio中,如果连接池用尽,再发送请求会导致溢出熔断,此时的503是由Envoy返回的。这是因为Envoy会缓存上游服务的连接,如果上游服务的连接失效或关闭,Envoy会尝试通过这些连接发送请求,导致连接被重置,然后Envoy会把这个错误封装成503返回给下游调用方。
分析:
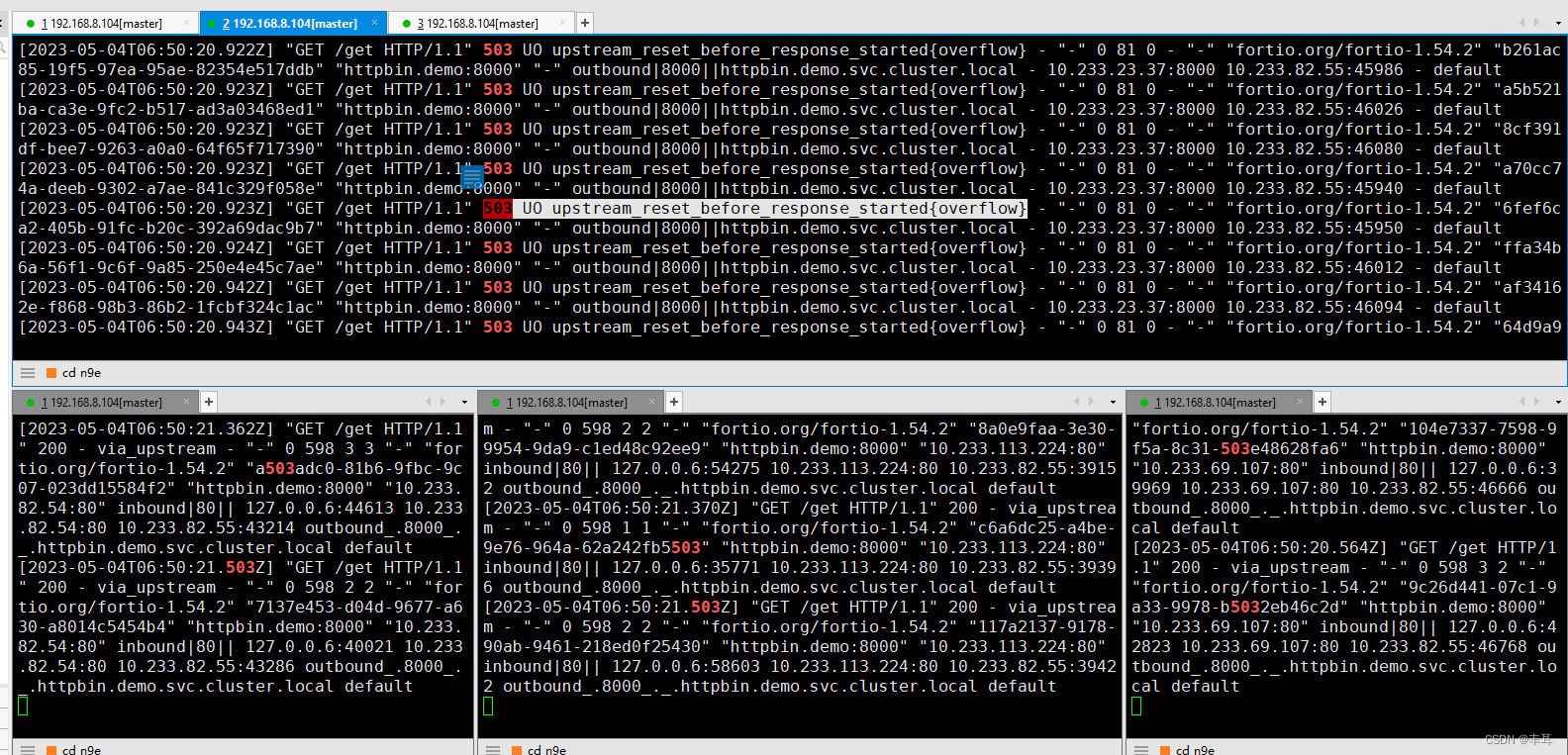
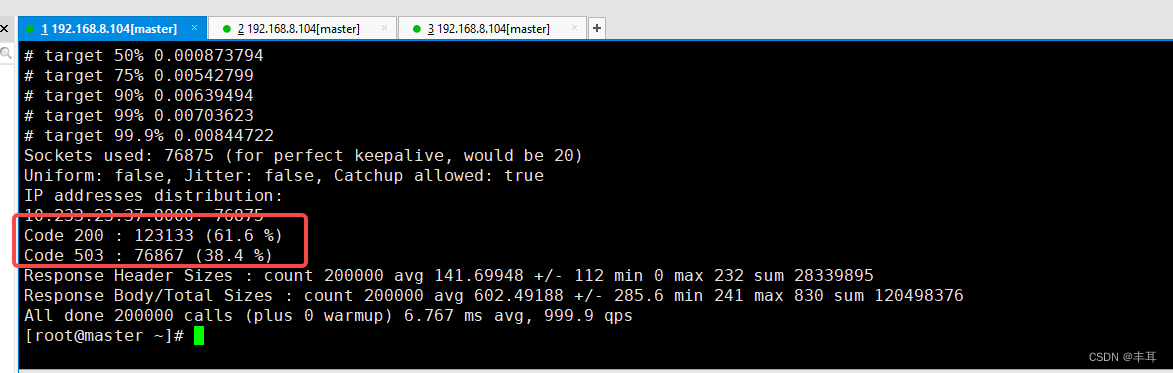
首先我们看在发生503错误时,只有请求发起方的fortio的sidecar出现大量503报错,而httpbin的sidecar中只有200;
再看fortio的返回日志:503 UO upstream_reset_before_response_started{overflow}
这个错误表示上游服务的连接池溢出,导致请求被重置。 UO是Envoy的响应标志,表示upstream overflow with circuit breaking,也就是说上游服务的连接数超过了熔断器的阈值。 overflow是Envoy的重置类型,表示连接池用尽。而我们上面分析过了,连接池的计数器是在下游服务的sidecar中,此处也间接说明这个503应该是fortio的sidecar自己生成的状态码。
在envoy的文档中,也说明了这一点:
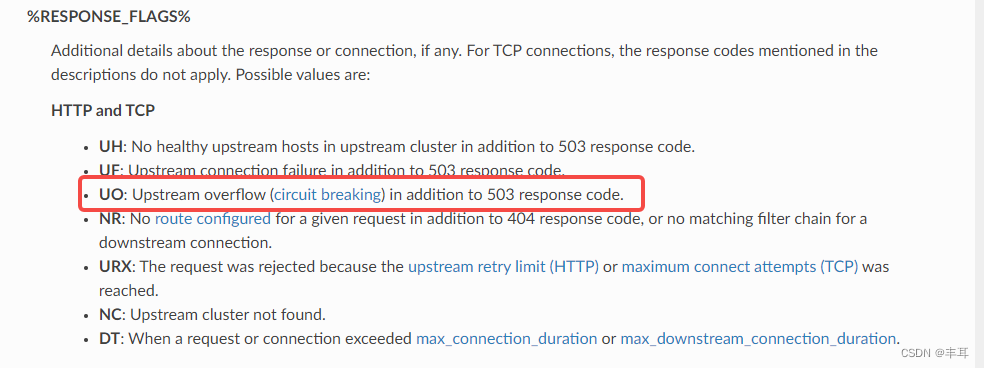
基于以上观点,认为503状态码不是由上游服务返回的,而是当前服务的sidecar在基于连接池溢出的判断后自动生成并返回给下游应用的,也就是说,这个错误是在负载均衡之前,Envoy在选择上游服务实例之前就发现连接数已经达到了熔断器的阈值,所以就直接拒绝了请求,没有进行负载均衡。
同时在多次的测试过程中,也没有发现触发异常值检测,从侧面也佐证返回的应该不是上游服务。反过来,似乎也证明了连接池溢出并不会触发异常值检测。