一、简介
- POLARDB 是阿里云自研的下一代关系型分布式数据库,100%兼容MySQL,之前使用MySQL的应用程序不需要修改一行代码,即可使用POLARDB。
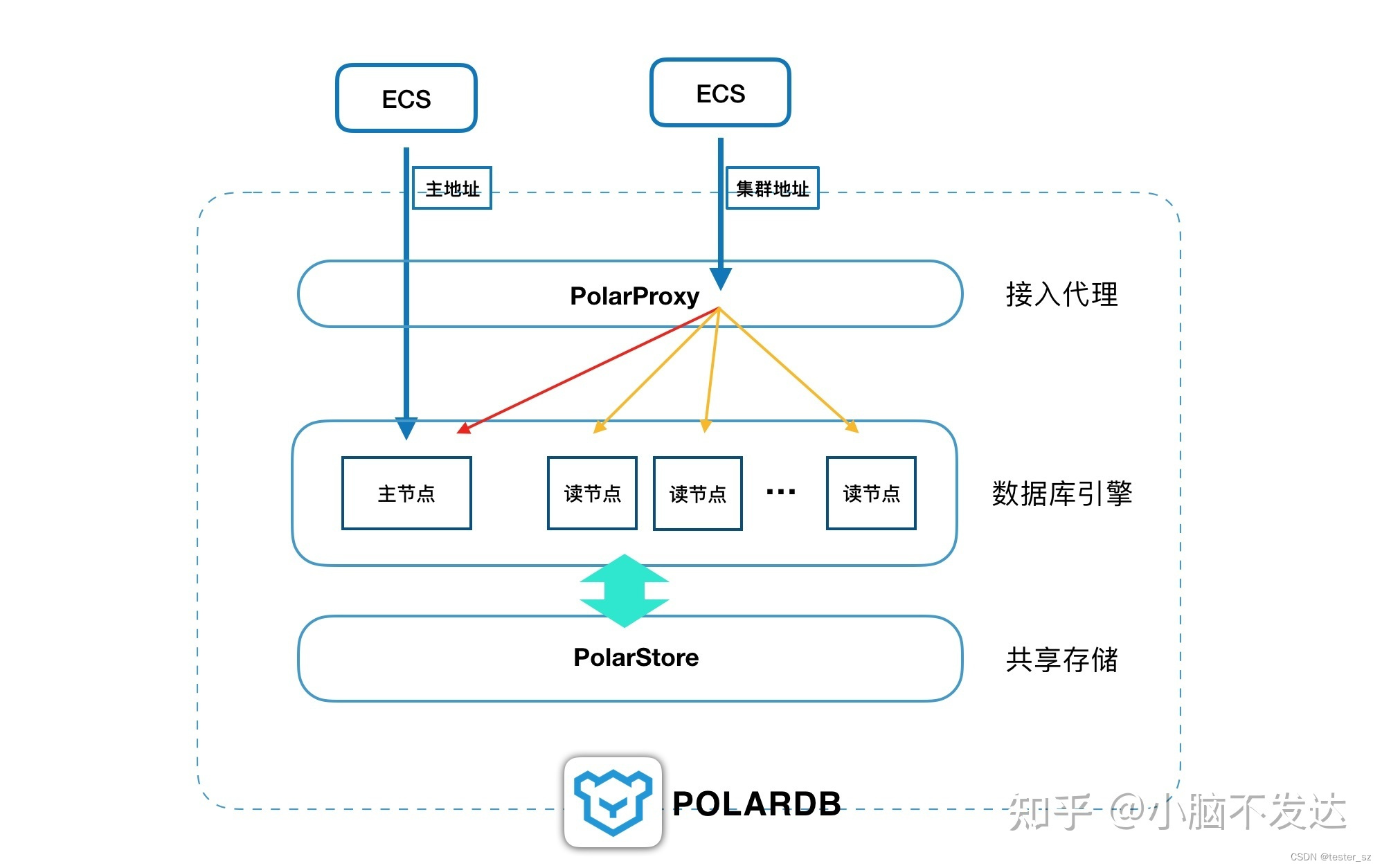
- POLARDB在运行形态上是一个多节点集群,集群中有一个Writer节点(主节点)和多个Reader节点,他们之间节点间通过分布式文件系统(PolarFileSystem)共享底层的同一份存储(PolarStore)。
- POLARDB通过内部的代理层(Proxy)对外提供服务,也就是说所有的应用程序都先经过这层代理,然后才访问到具体的数据库节点。
- Proxy可以做安全认证(Authorization)和保护(Protection),
- 解析SQL,把写操作(比如事务、Update、Insert、Delete、DDL等)发送到Writer节点,
- 解析SQL,把读操作(比如Select)均衡地分发到多个Reader节点,这个也叫读写分离。
- POLARDB对外默认提供了两个数据库地址,一个是集群地址(Cluster),一个是主地址(Primary)
- 推荐使用集群地址,因为它具备读写分离功能可以把所有节点的资源整合到一起对外提供服务。
- 主地址是永远指向主节点,访问主地址的SQL都被发送到主节点,当发生主备切换(Failover)时,主地址也会在30秒内自动漂移到新的主节点上,确保应用程序永远连接的都是可写可读的主节点。
二、特点
除了可以像使用MySQL一样使用POLARDB,这里还有一些传统MySQL数据库不具备的优势。
- 容量大
最高100T,不再因为单机容量的天花板而去购买多个MySQL实例做Sharding,甚至也不需要考虑分库分表,简化应用开发,降低运维负担。
- 高性价比
多个节点只收取一份存储的钱,也就是说只读实例越多越划算。
- 分钟级弹性
存储与计算分离的架构,再加上共享存储,使得快速升级成为现实。
- 读一致性
集群的读写分离地址,利用LSN(Log Sequence Number)确保读取数据时的全局一致性,避免因为主备延迟引起的不一致问题。
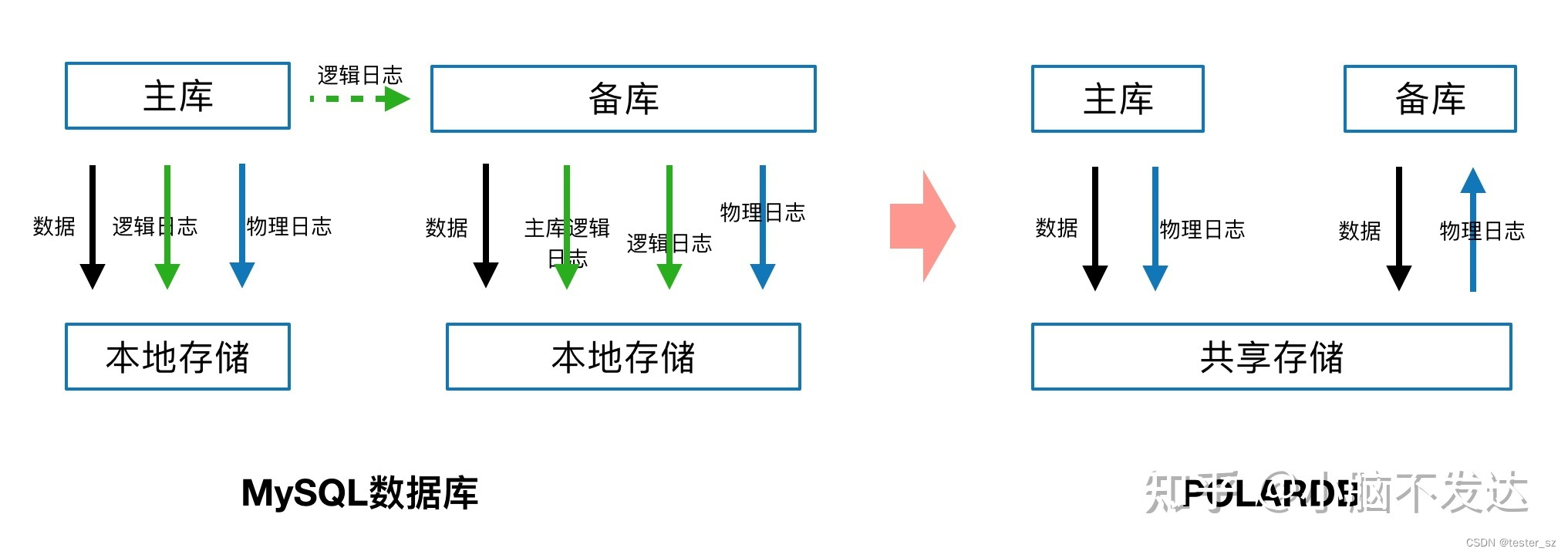
- 毫秒级延迟——物理复制
利用基于Redo的物理复制代替基于Binlog的逻辑复制,提升主备复制的效率和稳定性。即使是加索引、加字段的大表DDL操作,也不会对数据库造成延迟。
- 无锁备份
利用存储层的快照,可以在60秒内完成2T数据量大小的数据库的备份。并且这个备份过程不需要对数据库加锁,对应用程序几乎无影响,全天24小时均可进行备份。
- 复杂SQL查询加速
内置并行查询引擎,对执行时长超过1分钟的复杂分析类SQL加速效果明显。该功能需要额外连接地址。
三、PolarFS
- PolarFS设计中采用了如下技术以充分发挥I/O性能:
- PolarFS采用了绑定CPU的单线程有限状态机的方式处理I/O,避免了多线程I/O pipeline方式的上下文切换开销。
- PolarFS优化了内存的分配,采用MemoryPool减少内存对象构造和析构的开销,采用巨页来降低分页和TLB更新的开销。
- PolarFS通过中心加局部自治的结构,所有元数据均缓存在系统各部件的内存中,基本完全避免了额外的元数据I/O。
- PolarFS采用了全用户空间I/O栈,包括RDMA和SPDK,避免了内核网络栈和存储栈的开销。
在相同硬件环境下的对比测试,PolarFS中数据块3副本写入性能接近于单副本本地SSD的延迟性能。从而在保障数据可靠性的同时,极大地提升POLARDB的单实例TPS性能。
四、PolarDB日志
在数据库PolarDB中开创性地引入了物理日志(Redo Log)代替了传统的逻辑日志,不仅极大地提升了复制的效率和准确性,还节省了50%的 I/O 操作,对于有频繁写入或更新的数据库,性能可提升50%以上。
五、PolarProxy
PolarProxy存在的意义是可以把底层的多个计算节点的资源整合到一起,提供一个统一的入口,让应用程序访问,极大地降低了应用程序使用数据库的成本,也方便了从老系统到POLARDB的迁移和切换。
本质上,PolarProxy是一个容量自适应的分布式无状态数据库代理集群,动态的横向扩展能力,可以将POLARDB快速增减读节点的优势发挥到极致,提升整个数据库集群的吞吐,访问它的ECS越多,并发越高,优势越明显。