爬取汽车之家新闻
- 伪造浏览器向某个地址发送Http请求,获取返回的字符串
- response = requests.get(url = '地址')
- response.content
- response.encoding = apparent_encoding
- response.text
- bs4,解析HTML格式的字符串
- soup = BeautifulSoup('<html>...</html>', "html.parser")
- soup.find(name='标签名')
- soup.find(name='标签名', id='il')
- soup.find(name='标签名', _class='il')
- soup.find(name='标签名', )
asdf
asdf
一、下载页面
首先抓取要爬的页面
import requests ret = requests.get(url="https://www.autohome.com.cn/news/")
此时print(ret)返回的是一个对象: <Response [200]>
然后再print(ret.content)输出如下:
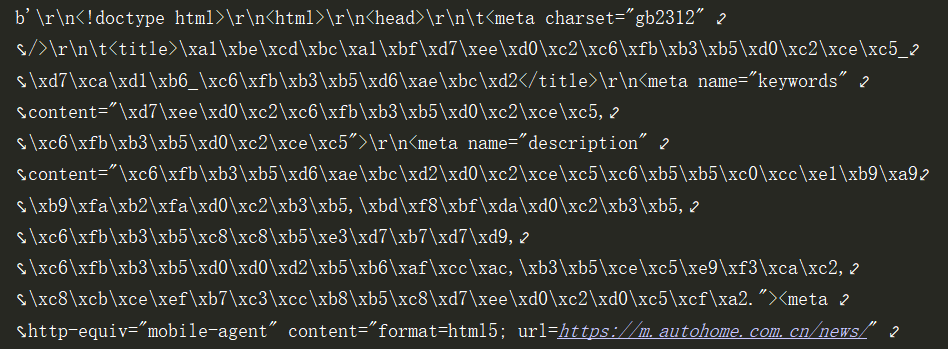
上图看出返回的是整个网页文本,不过是以字节形式的文本。
这不是我们需要的,接着再改用print(ret.text)输出如下:
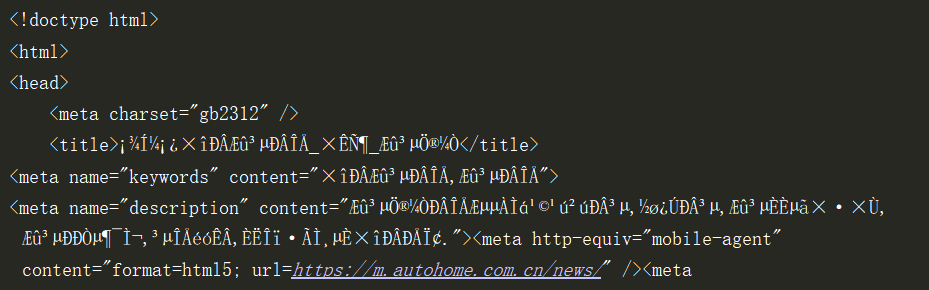
此时,出现了恶心的乱码!!!,我们再用encoding对ret进行编码:
ret.encoding = 'gbk'
这样可能不是很智能,那我们可以换一种方式:
ret.encoding = ret.apparent_encoding
在这里,print(ret.apparent_encoding)可以自动获取网页的编码格式。此时print(ret.text)已经能正常显示网页了:

二、解析:获取想要的指定内容
此时我们分析汽车之家新闻页面:
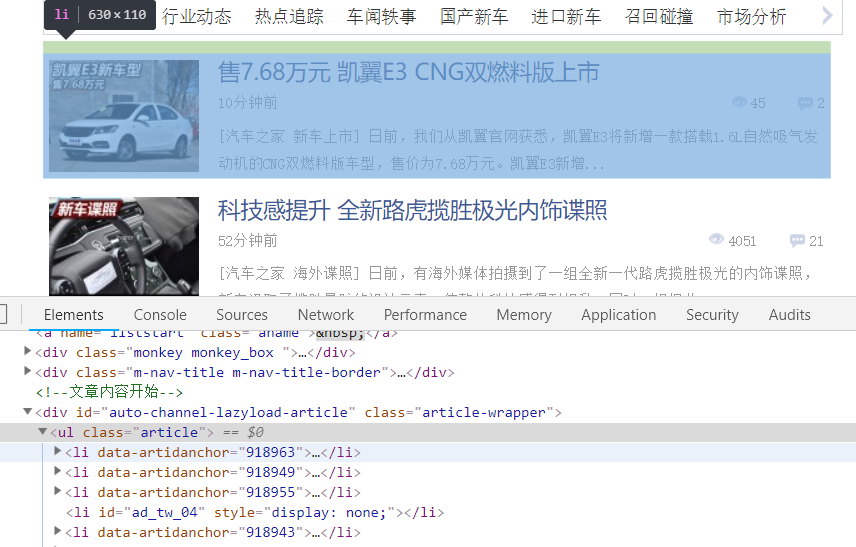
初步判断,新闻部分位于id为"auto-channel-lazyload-article"的div下面的li标签中,之所以选择id是因为class名称可能不是唯一的,不好用于过滤
此时,我们需要在py文件头部导入bs4模块,这个模块主要用来帮我们解析整个html页面,相当于正则表达式的功能
from bs4 import BeautifulSoup
用html解析器对网页进行解析
soup = BeautifulSoup(ret.text, 'html.parser')
我们用print(type(soup))输出soup的类型得到: <class 'bs4.BeautifulSoup'> ,可以看出soup由文本变成对象了。
提取出新闻所在的div:
div = soup.find(name='div',id='auto-channel-lazyload-article')
我们先print(div)查看下结果:
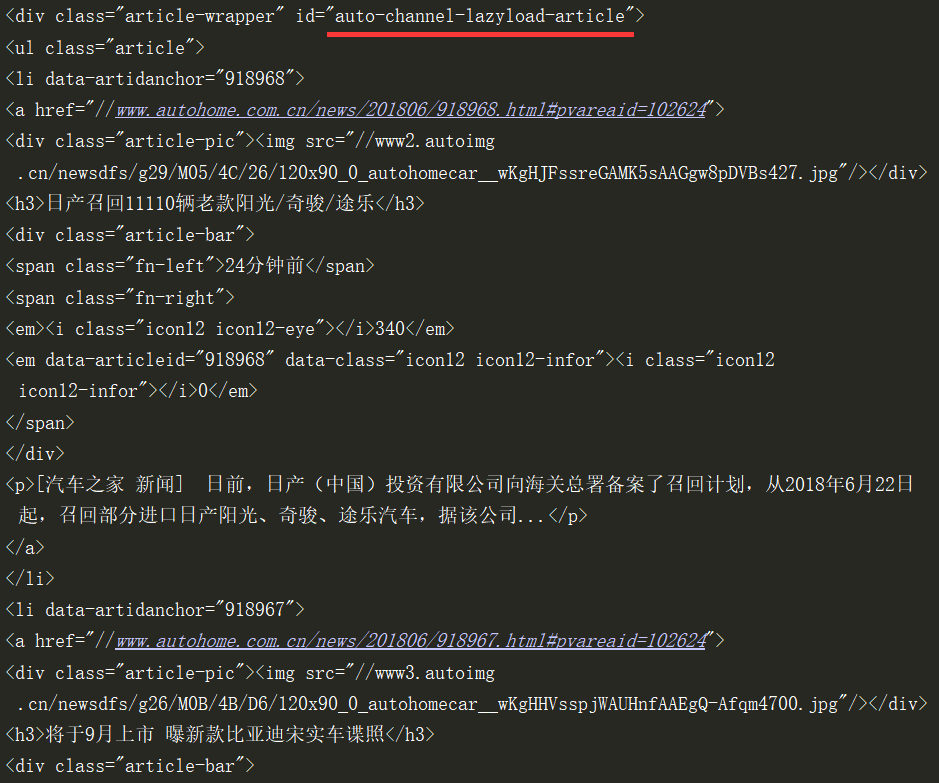
然后再对这个div对象进行二次解析,我们最终要拿到里面的li,用find_all找所有的li
li_list = div.find_all(name='li')
再次print(li_list)输出:
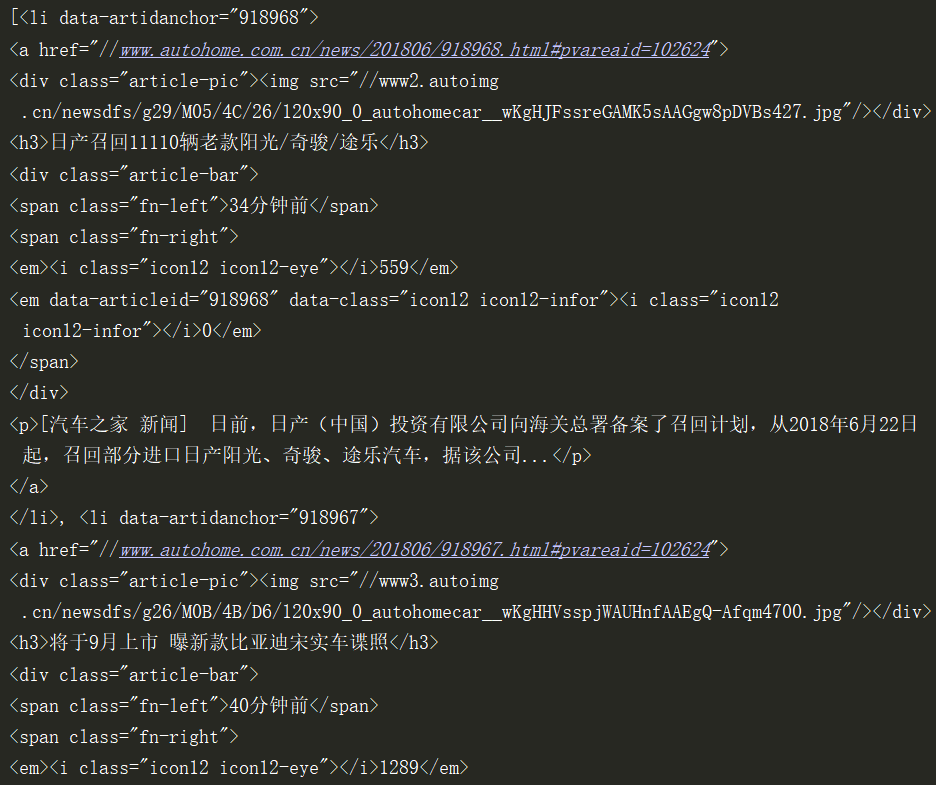
可以看出li_list已经是一个列表了。我们需要先找出里面的h3标签
for li in li_list: h3 = li.find(name='h3')
用print(h3)查看下h3标签

可以看出上图有一个为None的地方,我们返回网页查看源码
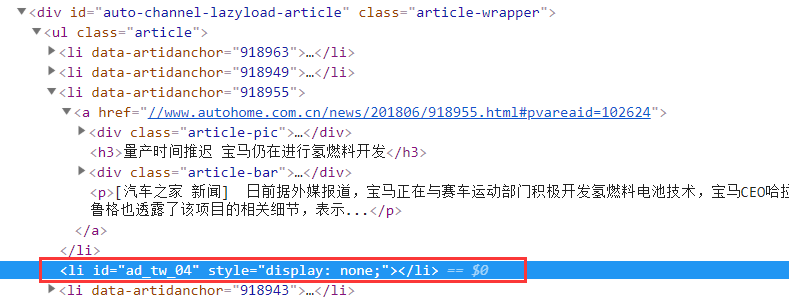
目测这里应该是一个广告位,这里我们可以采取if判断直接过滤掉
for li in li_list: h3 = li.find(name='h3') if not h3: continue print(h3)
在这里h3是一个对象,我们最终需要得到h3的文本
print(h3.text)
目前我们只是取得了每个li标签的新闻标题,再获取新闻正文和超链接
for li in li_list: h3 = li.find(name='h3') if not h3: continue print(h3.text) p = li.find(name='p') print(p.text) a = li.find('a') # 不写name默认取第一个a print(a.attrs) # attrs拿取所有属性

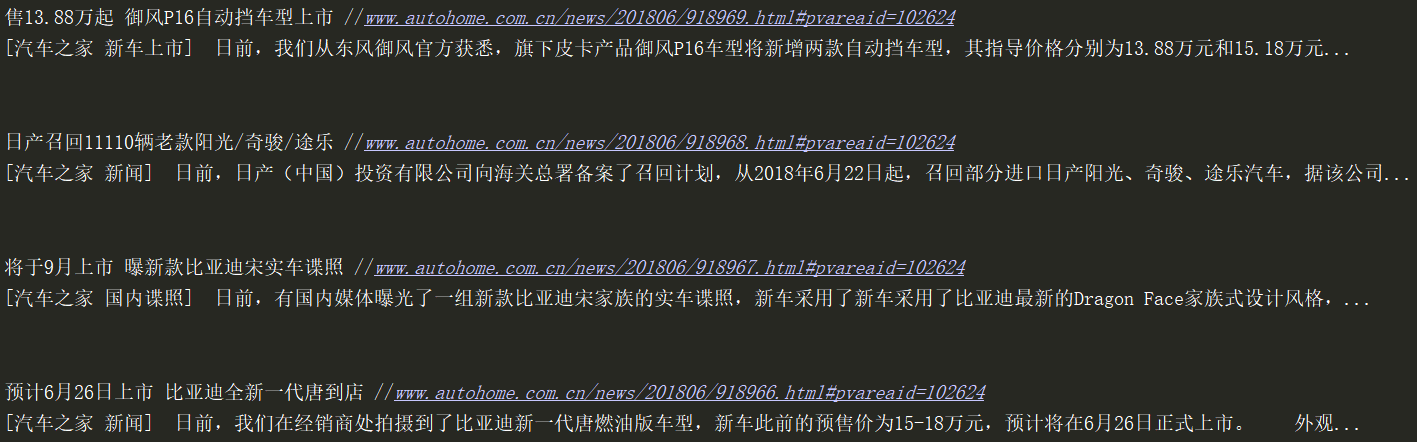
对输出进行优化:
print(h3.text, a.get('href')) print(p.text) print('\n')
我们顺便爬下图片吧
img = li.find('img') # print(img) src = img.get('src') # print(src) file_name = src.rsplit('__', maxsplit=1)[1] # print(file_name) ret_img = requests.get( url='https:' + src ) with open(file_name, 'wb') as f: f.write(ret_img.content) print('\n')
此时在自己当前路径下,已经下载了很多图片