是的!我们这节又要说设计模式了!不过没以前那么难哦,我是认真的!
1. 代码调优策略与过程(Code-Tuning Strategies and Process)
代码调优并不是为了修复bug,而是对正确性的代码进行修改以提高其性能。(通常都是些小规模的变化)
关于调优的几点说明
- 调优不会减少代码行数(代码行数与性能之间无必然联系)
- 不要猜原因,而应该要有明确的优化目标
通过度量发现程序热点与瓶颈(通过上节的工具),代码调优建立在对程序性能的精确度量的基础之上,当程序做过某些调整后,要重新分析,并重新了解需要优化的性能瓶颈,微小的变化能导致优化的方向大不相同。 - 不要边写程序边调优
在没有完整的程序前,无法获知性能瓶颈。在开发阶段调优,更容易忽视其他更重要的质量指标。
性能从不是追求的第一目标,正确性才是! - 不是性能优化的第一选择
代码调优的过程:
- 备份!!!!!!!!!!!!!!!(这才是第一步!!血与泪的教训嗷!!!)
- 通过度量分析发现代码热点瓶颈
- 分析原因,评判代码调优的必要性
- 调优
- 每次调优都要重新度量
- 如果无效果或者负效果则回滚到步骤1
2. 常见的低效来源(Common Sources of Inefficiency)
- I/O
- Paging
- Operators
- Object creation
- GC
- All perspectives of your code
- ……
3.对象创建的调优与复用(Code Tuning for Object Creation and Reuse)【含代码调优的设计模式】
1. 单例模式(Singleton Pattern)
某些类在应用运行期间只需要一个实例可以采用这种设计模式。
基本思想:程序员一般需要的时候就new一个对象,导致创建多个object。然而我们可以强制客户端只能创建一个object实例,避免因为new操作所带来的时空性能(尤其是GC)的损失,也便于复用。
具体方法:设置静态变量来储存单一实例对象,将构造器修改关键字变为private,从而是客户端无法new。在构造器中new新的实例,提供静态方法来获取单一实例对象。
恩,还是栗子实在:

这里很重要的一点就是当你静态获取该对象的时候,对于静态变量在内存中只有一个拷贝,JVM只会为静态分配以此内存,在加载类的过程中完成静态变量的内存分配。所以只会出现一个对象。
这里还有一个更好地栗子:

此时进一步提升性能,只有在需要的时候才会new出来,而非提前构造出来。
2.轻量模式(Flyweight Pattern)
解决问题栗子:如果文本编译器中的“字符”,同一个字符会重复出现多次,代表同样的内容,但字体字号等不同。那么我们就可以采用这种模式优化。
该模式中允许在应用中不同部分共享使用objects,降低大量对象带来的时空代价。
先来说一下内部状态与外部状态:
- 内部特征:不管在什么场合使用该object,内部特征都不变
- 外部特征:不是固定的,需要在不同场合分别指派/计算其值
还是来看个例子吧(工厂生产大小颜色不同,但是形象相同的外星儿人):


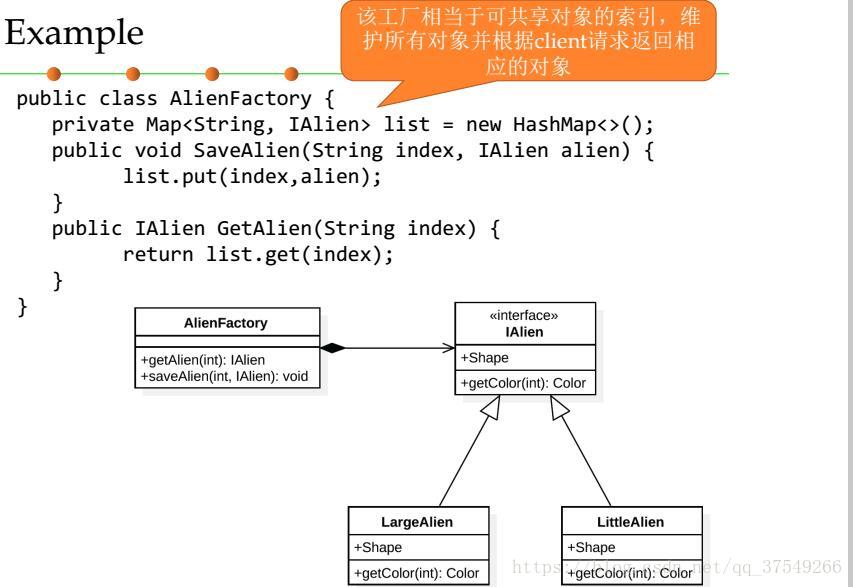
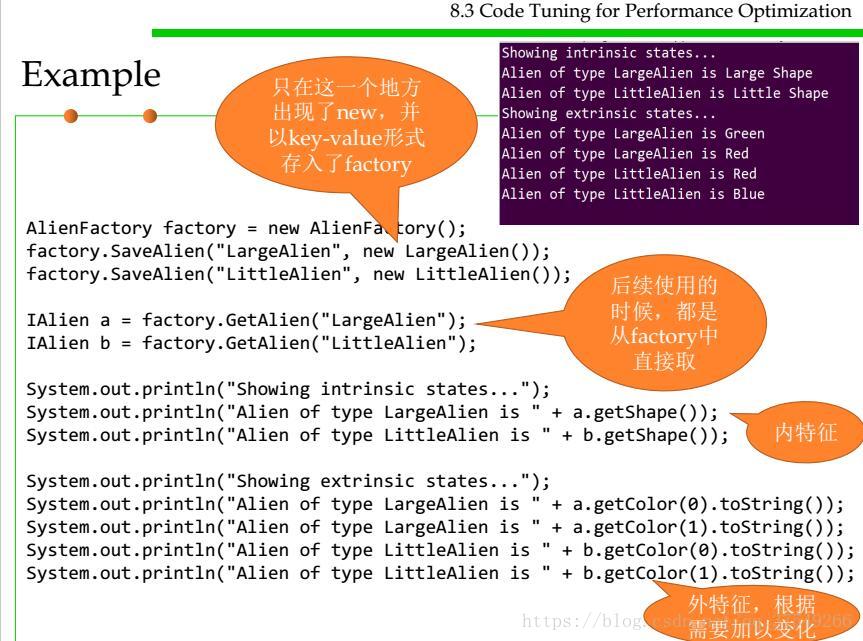
其实还是很简单的,现在来说一下其与单例模式的区别吧:
- 单例模式:不区分各个场合下的不同表现形式,统一用一个实例来表示。
- 轻量模式:同一个事物,具有多种不同的表现形式,在对象层面的复用比单例模式更加灵活
轻量模式在外部特征不同,内部特征相同的时候可以复用,这样节省了CPU和内存。
单例模式是只有一个(通常是可变的)类的实例。它经常用于多线程环境中,以使用单个实例和“查看”相同的状态来方便所有线程。
最后值得一提的是,虽然轻量模式外部特征可以变化,但他是不可变类型,原因很简单,就是因为他在类之中已经定义好了,就算你修改外部特征,只要有相同的内部特征,那么这就是一个实例对象,就像上面的例子,大大的绿外星人和大大的蓝外星人所指的对象不都是LargeAlien嘛?
3. 原型模式(Prototype Pattern)
在这种设计模式中是通过克隆的方式,而非new来创建对象。(因为直接new成本太高,尤其是需要与外部I/O、网络、数据库打交道的时候,new一个图很可怕的呀!!!)
没有栗子都是空话:


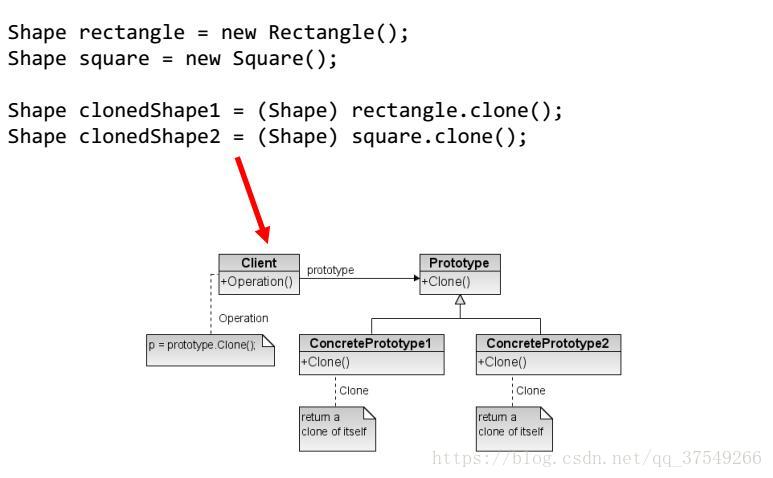
此处需要注意,Object.clone()是protected,所以需要将其重写为public,与此同时其返回类型是Object,所以需要进行强转。
这里还要说一下引用拷贝与对象拷贝两个概念,emm……不解释,看个图就懂了……
引用拷贝:

对象拷贝:
为什么提这个?因为上面的设计模式存在一个问题——浅拷贝与深拷贝问题。先来说一下概念在给大家形象解释:
- 浅拷贝:使用一个已知实例的成员变量对新创建的实例成员变量逐个赋值。(只复制对象本身,但不复制对象对外的引用)
- 深拷贝:类的拷贝方法不仅要复制对象的所有非引用成员变量值(简单数据类型),还要为引用类型(对象)的成员变量创建新的实例,并且初始化为原对象的值。
什么意思?
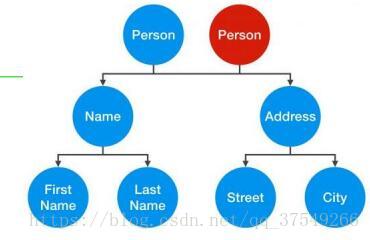
这是浅拷贝的一个例子,可以看见其只复制了最外层的对象,引用的内层对象是相同的,也就是说我修改了红色的person的address,蓝色的person的address也会发生变化。
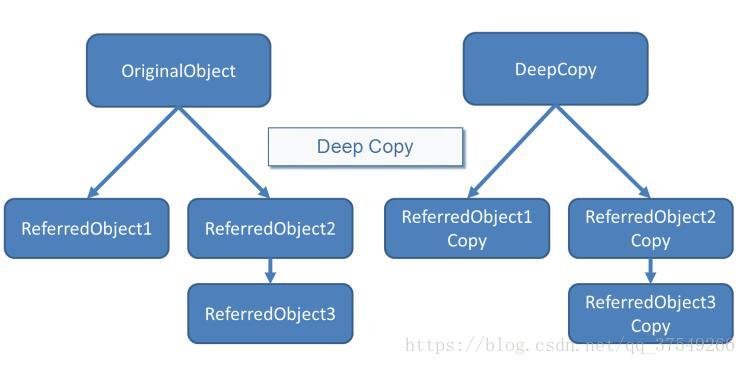
这是深拷贝!可以看出其完全复制了两个对象,复制前后所占内存*2.也就是说我修改一个对象的内部成员变量,另外一个对象是不变的!这就是区别。好了重点来了!!!!
java中Object中的clone方法是浅拷贝!!!!!
然而原型设计模式要求新对象与原对象要相互独立,要求深拷贝!所以对于内部的结构都要逐层copy,将新对象的引用指向新的内部结构。当然了如果内部只有简单的数据类型或immutable的变量,则直接调用父类默认的clone方法即可。
在实际编程中千万要注意自己重写的方法是否实现了深拷贝。
在最后谈一下萌萌哒java中的cloneable接口,看起来很高级吧!但为啥说他萌,大家可以看一下源码……

怎么样?是不是超可爱?!!!卡哇伊呐……这货原来是个二哈,看起来挺吓人,其实尼玛这不就是个空接口嘛!!!
4. 对象池模式(Object Pool Pattern)
对象复用:
时刻记住new是一个很巨大的性能代价。很多时候,对象不用就直接扔掉,需要在创建是一种巨大的浪费。所以对象复用要求就是不要扔掉对象,留着以后用嘛……
对象池模式的根本思想就是对象复用,如果这个对象我们以后还会用到,那我们为啥不把他存起来呢?
当然也是有缺点的,对于原本要被GC的对象,现在要留在pool中,内存自然会浪费一些,不过这就是用空间换时间的算法思想啊……
栗子就不给了,因为实在没什么说的,随随便便建个List或者Set什么的存起来就可以称之为对象池模式了,具体大家自己把握哦!
最后提一下,其实前面提到的单例模式与轻量模式本质上就是对象池,不过有点变化而已,细想想也能理解,单例模式把一个个相同的对象压缩为一个对象,自然成立。轻量模式则是把内在特征相同的对象都压缩为一个对象,也是体现了对象复用的思想。
5. 规避垃圾回收 (Avoiding GC)
核心思想:减少创建对象的数量,避免GC代价。
简单的例子:

String pool下面会讲到。
要尽可能的使用简单数据类型去减少GC,对类成员变量也是如此。(能用int存储String,就用int,可以用int/long代替Date对象)
局部的简单数据类型在栈中储存,GC代价很低。类的简单类型成员变量在GC的时候代价也很低,若为object成员变量这就需要GC了。
4.字符串(String)中的代码优化
String,没错他是个对象,并非基础数据类型。然而他在java中的地位很特殊。可能是买了JDK的VIP。
String Constant Pool,字符串常量池,没错这是java专门为String创建的pool。功能就是与前面所讲的一样。
好了,现在我们想一想当初刚开始学java的时候,String类型怎么写的?
//下面给出String类型两种写法,抱歉不是孔乙己两种就够了!
String string = "java";
String string = new String("java");
这两种写法都创建了一个值为“java”的常量string。然而第一种却没有用new……现在学完很多东西在来看,这显然是非常神奇的?你String类型又不是基础数据类型,你是个object凭啥不使用new啊!这就牵扯到了字符串常量池的问题。
在Java中基本数据类型有八种,Java为了运行时的速度更快,节省内存,为这八种数据类型提供了常量池,还记得之前提到过的有关硬件的知识吗?我提到过关于cache的思想,没错这里就体现了。其实现就是类似cache。当我们创建基本数据类型的时候,就在相对应的常量池中创建。所以int、double等等都不需要new(在堆中创建才需要new),这也是这种写法的本质!现在再来看String,他也可以这么写,这是因为在Java中存在上面所说的字符串常量池。明明String是对象却与基本数据类型有一样的待遇,这不是开了VIP这是什么?
所以我们再来解释上面两种写法,第一种String类型是在字符串常量池中创建的,而第二种则是在对堆中创建的。这也恰好证明了为什么String明明是object却可以像基本数据类型一样使用“==”来判定行为等价。因为如果都是第一种方式创建的,那么其会在字符串常量池中有且仅有一个String,不同的引用都会指向改地址,所以“==”也就能够成立,下面这个例子就来说明解释这个知识点:
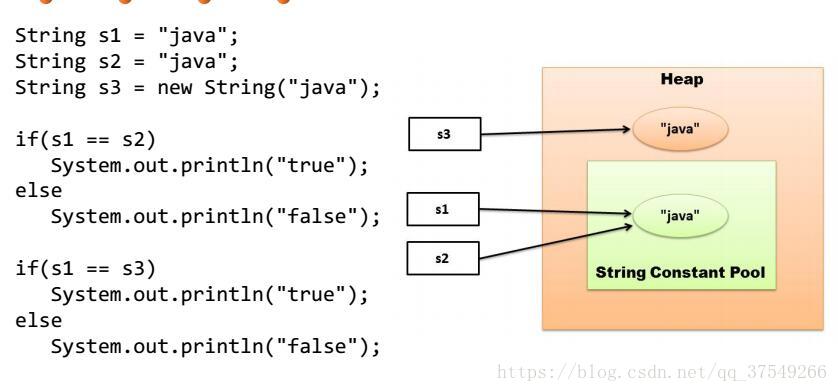
你们猜第一个输出和第二个输出是什么?
Answer:true、false。
怎么样?有意思吧!另外还要注意的是字符串常量池其实就是堆中分配的一块空间。
结束啦?nonono……我们现在再来看看和String类型差不多的数据对象Integer(这个更有意思哦!):
我们来看以下代码:
Integer x1 = Integer.valueOf(127); Integer x2 = Integer.valueOf(127); Integer x3 = new Integer(127); Integer x4 = new Integer(127); Integer x5 = Integer.valueOf(128); Integer x6 = Integer.valueOf(128); System.out.println(x1 == x3); //false System.out.println(x3 == x4); //false System.out.println(x1 == x2); //true System.out.println(x5 == x6); //false
怎么样?是不是想摔键盘?这尼玛是啥啊?!
第一个和第二个输出很好理解,这两个对象指向两个空间肯定不相等啊!那么第三个呢?难不成……Integer这家伙也跟JDK申请了VIP也拥有了一个专属的常量池?不过如果要是那样第四个输出为啥是false?!
其实嘛,上面的回答之猜对了一半,Integer确实跟JDK有交易,但是可能因为钱少?没有给过她一个专属的常量池,不过……给了点额外的小东西:我们来看一下源码(秘密在于这个Integer.valueOf这个静态方法上):
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
什么?这个IntergerCache是什么东西?!接着往下找!
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
我去……一个-128到127的缓存!这回明白了吧。这里可以理解为建了一个[-128,127]范围的常量池!当取127的时候他会直接将引用指向池中地址,而128这个位于边界外的悲惨的家伙,就没那么幸运了。所有都引用都会指向堆中的一个新分配的地址。
大家感兴趣可以看看其他的基本对象类型是什么样的?直接看源码就可以,Boolean也很有意思哦!
5. 其他的代码调优方法
就简单说说吧!
逻辑:
if (x > 5 && x < 10).....
if (x > 5){
if(x < 10){...}
}
这两种哪个更好呢?答案是第二个,第二个中如果程序发现x<=5了,那么他就不会在往下判定了。省了一步比较哇。
循环:
比如在数组中查找一个数据,可以用一个boolean的标志变量,如果找到就修改他然后break;

优化方法就是,加一个判断条件,如果找到break;
这些就不在多说了,都是些平时写代码的的小技巧,没什么条理,唯有靠平时的经验与汗水!
Ahhh……好像说了很不得了的话,诶嘿嘿……第八章到现在就已经说完了。当然正如第一章所说我现在也是在处于一个复习阶段,所以时间比较紧,第九章的内容呢由于不是考点,所以会在考试之后在给大家讲解。下一章我们来谈一谈第十章——多线程哇!