目录
基本介绍
NGINX通过limit_req_zone和limit_req两条指令来实现速率限制。指令limit_req_zone定义了限速的参数,指令limit_req在所在的location使能定义的速率。
QPS即每秒查询率,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。QPS = req/sec = 请求数/秒,即每秒的响应请求数,也即是最大吞吐能力。
模块配置具体解读
limit_req_zone指令设置了速率限制和共享内存区域的参数,但它实际上并不限制请求速率。因此我们需要通过在contexts中使用limit_req指令来将其限制应用于特定location或server块。
limit_req_zone
定义一个以IP为限制请求的方式,名字为req_limit_zone,开辟10M的共享内存区域,每秒处理的速率为10个请求
limit_req_zone $binary_remote_addr zone=req_limit_zone:10m rate=10r/s;说明 :limit_req_zone指令通常在 HTTP 块中定义,使其可在多个上下文中使用,它需要以下三个参数:
- key - 定义应用限制的请求特性。示例中使用的是 Nginx 嵌入变量binary_remote_addr(二进制客户端地址)
- zone - 定义用于存储每个 IP 地址状态以及被限制请求 URL 访问频率的共享内存区域。保存在内存共享区域的信息,意味着可以在 Nginx 的 worker 进程之间共享。定义分为两个部分:通过zone=keyword标识区域的名字,以及冒号后面跟区域大小。16000 个 IP 地址的状态信息,大约需要 1MB,所以示例中区域可以存储 160000 个 IP 地址。
- rate - 定义最大请求速率。在示例中,速率不能超过每秒 10 个请求。Nginx 实际上以毫秒的粒度来跟踪请求,所以速率限制相当于每 100 毫秒 1 个请求。因为不允许”突发情况”,这意味着在距离前一个请求 100 毫秒内到达的请求将被拒绝。
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=10r/s;
server {
location /login/ {
limit_req zone=mylimit;
proxy_pass http://my_upstream;
}
}
limit_req
limit_req指令来将其限制应用于特定location或server块。
limit_req zone=req_limit_zone burst=10 nodelay;- limit_req zone=req_limit_zone; 每个 IP 地址被限制为每秒只能请求 10 次 URL,更准确地说,在距离前一个请求的 100 毫秒内不能请求该 URL。
- limit_req zone=req_limit_zone burst=10; burst 参数定义了超出 req_limit_zone指定速率的情况下(示例中的 req_limit_zone区域,速率限制在每秒 10 个请求,或每 100 毫秒一个请求),客户端还能发起多少请求。距离上一个请求 100 毫秒内到达的请求将会被放入队列,我们将队列大小设置为 10。
也就是说,如果从一个给定 IP 地址发送 11 个请求,Nginx 会立即将第一个请求发送到上游服务器群,然后将余下 10 个请求放在队列中。然后每 100 毫秒转发一个排队的请求,只有当传入请求使队列中排队的请求数超过 10 时,Nginx 才会向客户端返回503。
- limit_req zone=req_limit_zone burst=10 nodelay; 使用 nodelay 参数,可以实现无延迟的排队;Nginx 仍将根据 burst 参数分配队列中的位置,当一个请求到达时,只要在队列中能分配位置,Nginx 将立即转发这个请求。将队列中的该位置标记为”taken”(占据),并且不会被释放以供另一个请求使用,直到一段时间后才会被释放(在这个示例中是,100 毫秒后)。
limit_req zone=name [burst=number] [nodelay | delay=number];location /login/ {
limit_req zone=mylimit burst=20 nodelay;
proxy_pass http://my_upstream;
}
- 上面这段配置中我们设置了burst=20,该配置定义了客户端可以超过区域指定速率的请求数(对于我们前面定义的mylimit区域,请求速率限制为每秒 10 个请求即每 100 毫秒 1 个)。在前一个请求之后 100 毫秒内到达的请求会被放入到队列中,这里我们将队列大小设置为 20。
- 说如果有22个请求同时发送过来,那么NGINX会马上把第1个请求根据相关规则转发给upstream服务器,然后把接下来的第2到21共计20个请求放入队列中,接着直接返回503代码给第22个请求,随后的2秒时间内,每100毫秒从队列中取出一个请求发送给upstream服务器进行处理。
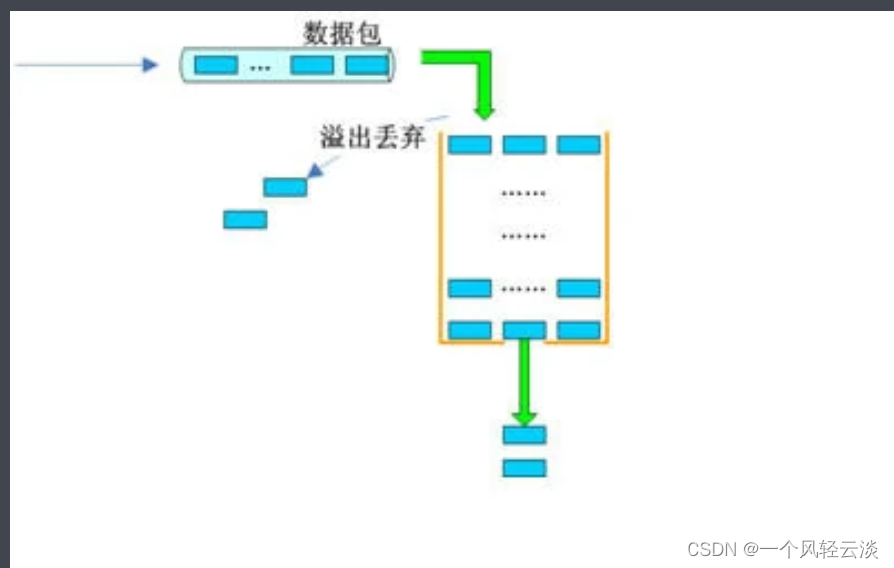
原理:漏桶算法
漏桶算法(Leaky Bucket Algorithm)是一种用于流量控制和限流的经典算法。其基本原理是将请求放入一个有固定容量的“桶”中,桶内的请求以固定速率传出。当桶满时,新进入的请求将被丢弃。漏桶算法可以保证处理请求的速率恒定,从而有效防止流量激增导致的服务不稳定。
当主机接口向网络中传送数据包时,可采取漏桶算法,使得接口输出数据流的速率恒定。
-
输出不规则数据流的主机类似灌水的水龙头
-
算法中定义的漏桶类似水桶
-
不规则数据流输入漏桶类似向漏桶中灌水

流量输出漏桶类似漏桶漏水

接下来,详细分解一下漏桶算法在数据包传送过程中的实现原理。
1、队列接收到准备转发的数据包。
2、队列被调度,得到转发机会。由于队列配置了流量整形,队列中的数据包首先进入漏桶中。
3、根据数据包到达漏桶的速率与漏桶的输出速率关系,确定数据包是否被转发。
如果到达速率≤输出速率,则漏桶不起作用。
如果到达速率>输出速率,则需考虑漏桶是否能承担这个瞬间的流量。
- 1) 若数据包到达的速率-漏桶流出的速率≤配置的漏桶突发速率,则数据包可被不延时的送出。
- 2) 若数据包到达的速率-漏桶流出的速率>配置的漏桶突发速率,则多余的数据包被存储到漏桶中。暂存在漏桶中的数据包在不超过漏桶容量的情况下延时发出。
- 3) 若数据包到达的速率-漏桶流出的速率>配置的漏桶突发速率,且数据包的数量已经超过漏桶的容量,则这些数据包将被丢弃。