这是发生在集成一个yolov5中没有的检测头head的情况下发生的错误,出现的时候是已经训练起来了,在训练结束时发生的报错,下面是我的解决办法。
1、问题出现及分析排查
改yolov5的网络进行训练时出的报错:
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
百思不得其解,经过反复调试最终解决了该问题,其实细心一点估计早就解决了。
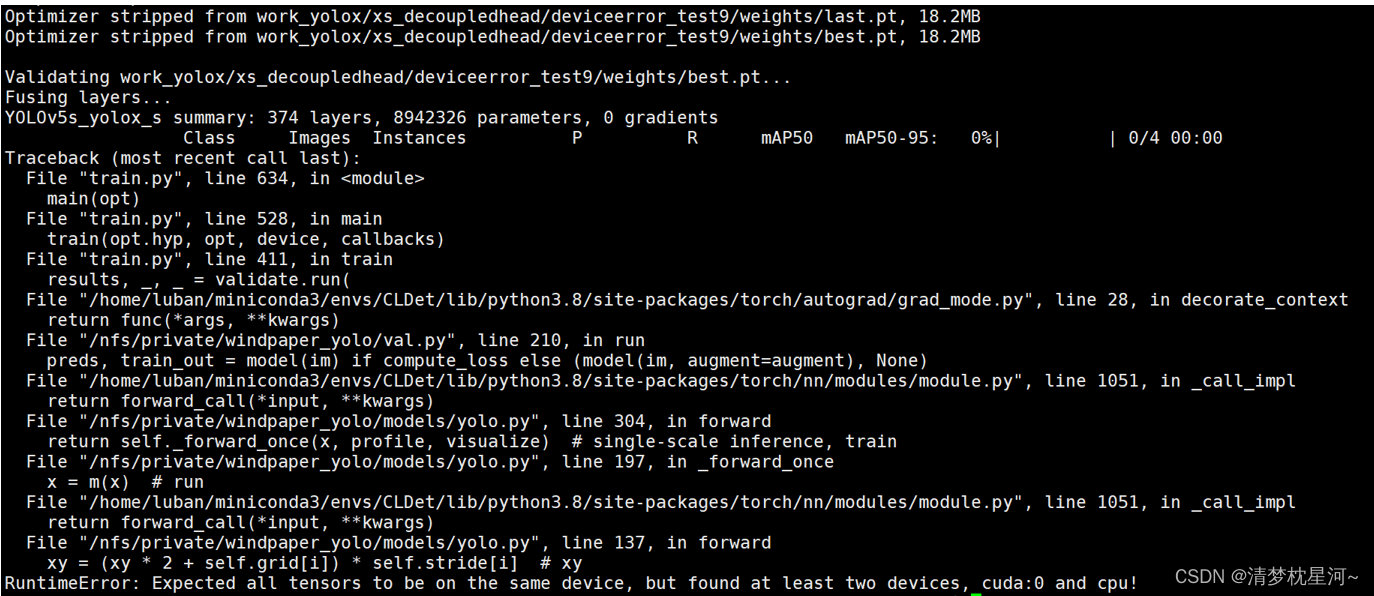
具体问题报错如下:
Optimizer stripped from work_yolox/xs_decoupledhead/deviceerror_test9/weights/last.pt, 18.2MB
Optimizer stripped from work_yolox/xs_decoupledhead/deviceerror_test9/weights/best.pt, 18.2MB
Validating work_yolox/xs_decoupledhead/deviceerror_test9/weights/best.pt...
Fusing layers...
YOLOv5s_yolox_s summary: 374 layers, 8942326 parameters, 0 gradients
Class Images Instances P R mAP50 mAP50-95: 0%| | 0/4 00:00
Traceback (most recent call last):
File "train.py", line 634, in <module>
main(opt)
File "train.py", line 528, in main
train(opt.hyp, opt, device, callbacks)
File "train.py", line 411, in train
results, _, _ = validate.run(
File "/home/luban/miniconda3/envs/CLDet/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 28, in decorate_context
return func(*args, **kwargs)
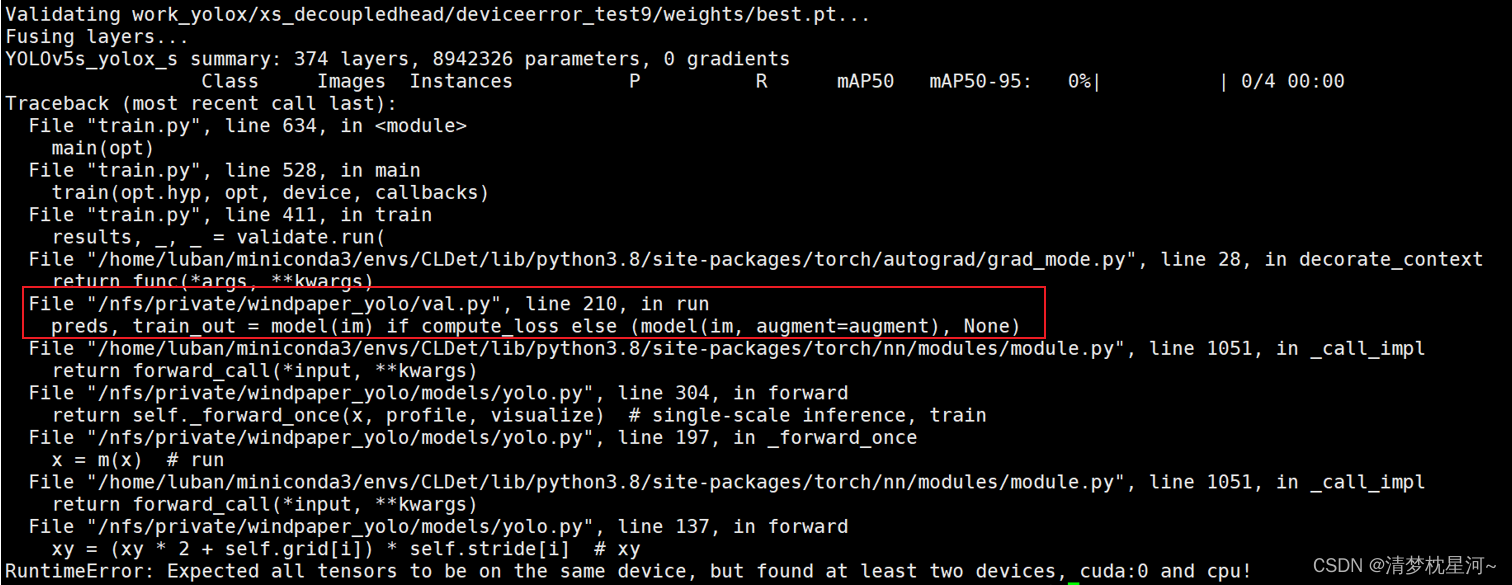
File "/nfs/private/windpaper_yolo/val.py", line 210, in run
preds, train_out = model(im) if compute_loss else (model(im, augment=augment), None)
File "/home/luban/miniconda3/envs/CLDet/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/nfs/private/windpaper_yolo/models/yolo.py", line 304, in forward
return self._forward_once(x, profile, visualize) # single-scale inference, train
File "/nfs/private/windpaper_yolo/models/yolo.py", line 197, in _forward_once
x = m(x) # run
File "/home/luban/miniconda3/envs/CLDet/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/nfs/private/windpaper_yolo/models/yolo.py", line 137, in forward
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
乍一看,就是变量类别不一致问题,有的在cuda设备上,有的在cpu设备上,导致计算的时候报错。这里也可以看到,问题最终是出现在
File "/nfs/private/windpaper_yolo/models/yolo.py", line 137, in forward
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
因为这是训练过程出现的问题,且只出现在最后阶段,无论前面训练多少个epochs都没错,所以一开始查错有一点曲折。由于训练已经完成在调用验证代码出现的问题,先找到了val.y,在下面这行代码的位置反复调试,试图找出在cpu和gpu的变量,把他们统一整合到gpu上
试了半天,发现都是gpu变量,包括im、model、targets等,甚至直接找模型的参数如model.parameters()、model.state_dict()等来看所在的位置,结果要么是在gpu上,要么就是看不到,后面也几乎放弃了。
最后经过仔细分析,在yolo.py中反复看,最后经过尝试,终于排查出了问题,修改后经过验证就解决了问题。
2、问题解决方法
在yolov5中的yolo.py中有这么一段代码:
def _apply(self, fn):
# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
self = super()._apply(fn)
m = self.model[-1] # Detect()
if isinstance(m, (Detect, Segment)):
m.stride = fn(m.stride)
m.grid = list(map(fn, m.grid))
if isinstance(m.anchor_grid, list):
m.anchor_grid = list(map(fn, m.anchor_grid))
return self
这是 class BaseModel的一个私有函数,没有找到调用的位置,具体执行方法还不太清楚。结合这个函数的提示,以及错误中涉及 self.grid 和 self.stride,我关注到了这个函数。函数中对yolov5构建head做了处理,如Detect、Segment,我尝试把我改的head模块和这几个放一起加到代码中进行调试。我先在val.py中打断点验证了stride的类型,发现:
ipdb> model.stride.device
device(type='cpu')
可见,确实存在cpu类型的变量。然后我在yolo.py中的class BaseModel的_apply(self, fn)上调试发现:
ipdb> fn
<function Module.to.<locals>.convert at 0x7fc1a25ed280>
ipdb> m.stride
tensor([ 8., 16., 32.])
ipdb> type(m.stride)
<class 'torch.Tensor'>
ipdb> m.grid
[tensor([]), tensor([]), tensor([])]
ipdb> m.anchor_grid
[tensor([]), tensor([]), tensor([])]
把我的检测头head加到代码中调试,即把你yaml配置文件中的head的模块名称加到YOUR_HEAD_MODULE,再跑代码,就不会再报错,修改如下:
def _apply(self, fn):
# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
self = super()._apply(fn)
m = self.model[-1] # Detect()
if isinstance(m, (Detect, Segment, YOUR_HEAD_MODULE)):
m.stride = fn(m.stride)
m.grid = list(map(fn, m.grid))
if isinstance(m.anchor_grid, list):
m.anchor_grid = list(map(fn, m.anchor_grid))
return self
修改前后变量的变化如下调试过程:
> /nfs/private/windpaper_yolo/models/yolo.py(236)_apply()
235 if isinstance(m, (Detect, DetectDcoupleHead, Segment)):
--> 236 m.stride = fn(m.stride)
237 m.grid = list(map(fn, m.grid))
ipdb> m.stride
tensor([ 8., 16., 32.])
ipdb> n
> /nfs/private/windpaper_yolo/models/yolo.py(237)_apply()
236 m.stride = fn(m.stride)
--> 237 m.grid = list(map(fn, m.grid))
238 if isinstance(m.anchor_grid, list):
ipdb> m.stride
tensor([ 8., 16., 32.], device='cuda:0')
ipdb> m.grid
[tensor([]), tensor([]), tensor([])]
ipdb> n
> /nfs/private/windpaper_yolo/models/yolo.py(238)_apply()
237 m.grid = list(map(fn, m.grid))
--> 238 if isinstance(m.anchor_grid, list):
239 m.anchor_grid = list(map(fn, m.anchor_grid))
ipdb> m.grid
[tensor([], device='cuda:0'), tensor([], device='cuda:0'), tensor([], device='cuda:0')]
ipdb> n
> /nfs/private/windpaper_yolo/models/yolo.py(239)_apply()
238 if isinstance(m.anchor_grid, list):
--> 239 m.anchor_grid = list(map(fn, m.anchor_grid))
240 return self
ipdb> m.anchor_grid
[tensor([]), tensor([]), tensor([])]
ipdb> n
> /nfs/private/windpaper_yolo/models/yolo.py(240)_apply()
239 m.anchor_grid = list(map(fn, m.anchor_grid))
--> 240 return self
241
ipdb> m.anchor_grid
[tensor([], device='cuda:0'), tensor([], device='cuda:0'), tensor([], device='cuda:0')]
ipdb> n
--Return--
DetectionMode... )
)
)
)
可以发现,上述变量m.stride、m.grid和m.anchor_grid经过这个函数后就都加了device='cuda:0’的身份,这就会进入cuda成为cuda变量存在gpu中,从而是参数变量类型一致,我修改后训练正常,自此就完成了该bug的修改。