在过去的两年里,一直在广泛使用Python,过程中寻找到令人惊叹的库,明显提高效率,增强在数据工程和商业智能项目中的表现。
Pendulum
Python 中有许多库可用于日期时间,但我发现 Pendulum 在日期的任何操作上都易于使用。
Pendulum扩展了内置的 Python 日期时间模块,添加了更直观的 API,用于处理时区并对日期和时间执行操作:
例如添加时间间隔、减去日期和在时区之间转换。它提供了一个简单、人性化的 API 来格式化日期和时间。
1、安装
pip install pendulum
2、实例化时区和时区换算:
# 导入库
# import library
import pendulum
dt = pendulum.datetime(2023, 6, 8)
print(dt)
输出:
2023-06-08T00:00:00+00:00
2.2 local() 使用本地时区
#local() 使用本地时区
local = pendulum.local(2023, 6, 8)
print("本地时间:", local)
print("本地时区:", local.timezone.name)
输出:
本地时间:2023-06-08T00:00:00+08:00
本地时区:Asia/Shanghai
2.3 创建日期时间实例
# Printing UTC time
utc = pendulum.now('UTC')
print("Current UTC time:", utc)
输出:
Current UTC time: 2023-06-08T10:44:51.856673+00:00
2.4 将 UTC 时区转换为欧洲/巴黎时间
# 将UTC 时区转换为欧洲/巴黎时间
europe = utc.in_timezone('Europe/Paris')
print("巴黎当前时间:", europe)
输出:
Current UTC time: 2023-06-08T10:47:27.836789+00:00
Current time in Paris: 2023-06-08T12:47:27.836789+02:00
FTFY
您是否遇到过数据中存在的外语无法正确显示的情况?
这被称为:Mojibake术语用于描述编码或解码问题而发生的乱码或乱码文本。
当使用一种字符编码编写的文本使用不同的编码错误解码时,通常会发生这种情况。
ftfy python库将帮助您修复Mojibake,这在NLP用例中非常有用。
安装
pip install ftfy
例
print(ftfy.fix_text('Correct the sentence using “ftfyâ€\x9d.'))
print(ftfy.fix_text('✔ No problems with text'))
print(ftfy.fix_text('à perturber la réflexion'))
输出
除了Mojibake,ftfy将修复不正确的编码,不正确的行尾和不正确的引号。可以理解解码为以下任何编码的文本:
拉丁语-1 (ISO-8859–1)
Windows-1252 (cp1252 — 用于微软产品)
Windows-1251 (cp1251 — cp1252的俄语版本)
Windows-1250 (cp1250 — cp1252的东欧版本)
ISO-8859–2(与Windows-1250不完全相同)
MacRoman(在 Mac OS 9 及更早版本上使用)
cp437(用于 MS-DOS 和某些版本的 Windows 命令提示符)
Sketch
Sketch是一个独特的AI代码编写助手,专为使用Python中的pandas库的用户而设计。
它利用机器学习算法来理解用户数据的上下文,并提供相关的代码建议,使数据操作和分析任务更容易、更高效。
Sketch不需要用户在他们的IDE中安装任何其他插件,因此可以快速轻松地开始使用。
这可以大大减少数据相关任务所需的时间和精力,并帮助用户编写更好、更高效的代码。
安装
pip install sketch
例我们需要在 Pandas 数据框中添加一个 .sketch 扩展名才能使用此库。
.sketch.ask
ask是Sketch的一项功能,允许用户以自然语言格式询问有关其数据的问题。它为用户的查询提供基于文本的响应。
# Importing libraries
import sketch
import pandas as pd
file = "D://7 Datasciense//DS_visilization//altair//airports.csv"
# Reading the data (using twitter data as an example)
df = pd.read_csv(file)
print(df)
输出美国机场的概况:
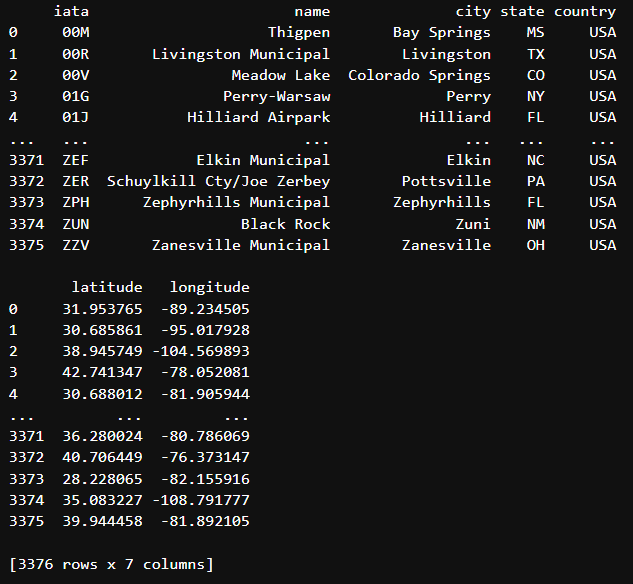
# 问表单有哪些项目
df.sketch.ask("Which columns are category type?")
iata, name, city, state, country
合并到下一个命令输出截图
# 描述表单的形状行和列的大小
df.sketch.ask("What is the shape of the dataframe")
The shape of the dataframe is (3376, 8).
以上两条命令的结果:
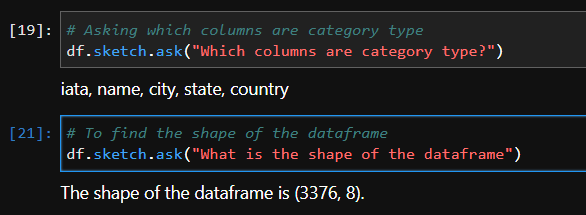
.sketch.howto
HowTo 是一项功能,它提供了一个代码块,可用作各种数据相关任务的起点或结论。
我们可以要求代码片段来规范化它们的数据、创建新特征、绘制数据,甚至构建模型。
这将节省时间并轻松复制和粘贴代码;
您无需从头开始手动编写代码。
# 请用一段代码实现可视化
df.sketch.howto("Visualize the emotions")
输出
.sketch.apply
.apply 函数有助于生成新特征、解析字段和执行其他数据操作。
要使用此功能,我们需要拥有 OpenAI 帐户并使用 API 密钥来执行任务。我还没有尝试过这个功能。
我喜欢使用这个库,尤其是如何操作,我发现它很有用。
pgeocode 地理编码
_“pgeocode”_是我最近遇到的一个优秀的库,它对我的空间分析项目非常有用。
例如,它允许您查找两个邮政编码之间的距离,并通过输入国家/地区和邮政编码来提供地理信息。
https://pgeocode.readthedocs.io/en/latest/

https://pypi.org/project/pgeocode/
以上页面里可以找到链接下载全球的邮政编码:
http://download.geonames.org/export/zip/
数据按“原样”提供,不带任何精度、时效性或完整性的保证或陈述。此自述文件描述了GeoNames邮政编码数据集。
主要的GeoNames地理名称数据提取位于此处:http://download.geonames.org/export/dump/
支持的国家/地区:
目前支持近100个国家/地区。当国家邮政服务开始以兼容许可证发布数据时,将添加新的国家/地区。
对许多国家/地区来说,纬度/经度是通过在主要的geonames数据库中搜索邮政编码的地名来确定的, _administrativedivisions_和邮政编码的数值邻近度是地名消歧的因素。
对于找不到主要的_geonames_数据库中对应的地理名称的邮政编码和地名,计算相邻邮政编码的平均纬度/经度。
部分中文国家简称的编码
地名数据库中提供的国家名单
以及相应的国家代码如下:
安道尔(AD)、阿根廷(AR)、美属萨摩亚(AS)、
奥地利(AT)、澳大利亚(AU)、奥兰群岛(AX)、
孟加拉国(BD)、比利时(BE)、保加利亚(BG)、
百慕大(BM)、巴西(BR)、白俄罗斯(BY)、
加拿大(加拿大)、瑞士(瑞士)、哥伦比亚(CO)、
哥斯达黎加(CR)、捷克(CZ)、德国(DE)、
丹麦(DK)、多米尼加共和国(DO)、
阿尔及利亚(DZ)、西班牙(西班牙)、芬兰(FI)、
法罗群岛(FO)、法国(fr)、
墨西哥(MX)、荷兰(荷兰)、挪威(NO)、
新西兰(新西兰)、
菲律宾(菲律宾)、巴基斯坦(PK)、波兰(PL)、
波多黎各(PR)、葡萄牙(PT)、留尼汪岛(RE)、
罗马尼亚(RO)、俄罗斯联邦(俄罗斯)、瑞典(SE)、
斯洛文尼亚(SI)、斯洛伐克(SK), 圣马力诺(SM)、
泰国(TH)、土耳其(TR)、乌克兰(UA)、
美利坚合众国(美国)、乌拉圭(UY)、罗马教廷(VA)、
美属维尔京群岛(VI)、马约特岛(YT)、南非(ZA)
完整的英文国家简称的编码
Andorra (AD), Argentina (AR), American Samoa (AS), Austria (AT), Australia (AU), Åland Islands (AX),
Bangladesh (BD), Belgium (BE), Bulgaria (BG), Bermuda (BM), Brazil (BR), Belarus (BY),
Canada (CA), Switzerland (CH), Colombia (CO), Costa Rica (CR), Czechia (CZ),
Germany (DE), Denmark (DK), Dominican Republic (DO), Algeria (DZ),
Spain (ES),
Finland (FI), Faroe Islands (FO), France (FR),
United Kingdom of Great Britain and Northern Ireland (GB), French Guiana (GF), Guernsey (GG), Greenland (GL), Guadeloupe (GP), Guatemala (GT), Guam (GU),
Croatia (HR), Hungary (HU),
Ireland (IE), Isle of Man (IM), India (IN), Iceland (IS), Italy (IT),
Jersey (JE), Japan (JP),
Liechtenstein (LI), Sri Lanka (LK), Lithuania (LT), Luxembourg (LU), Latvia (LV),
Monaco (MC), Republic of Moldova (MD), Marshall Islands (MH), The former Yugoslav Republic of Macedonia (MK), Northern Mariana Islands (MP), Martinique (MQ), Malta (MT), Mexico (MX), Malaysia (MY),
New Caledonia (NC), Netherlands (NL), Norway (NO), New Zealand (NZ),
Philippines (PH), Pakistan (PK), Poland (PL), Saint Pierre and Miquelon (PM), Puerto Rico (PR), Portugal (PT),
Réunion (RE), Romania (RO), Russian Federation (RU), Sweden (SE), Slovenia (SI), Svalbard and Jan Mayen Islands (SJ), Slovakia (SK), San Marino (SM),
Thailand (TH), Turkey (TR),
Ukraine (UA), United States of America (US), Uruguay (UY),
Holy See (VA), United States Virgin Islands (VI),
Wallis and Futuna Islands (WF), Mayotte (YT),
South Africa (ZA)
安装
pip install pgeocode
例获取特定邮政编码的地理信息
# Checking for country "India"
nomi = pgeocode.Nominatim('In')
# Getting geo information by passing the postcodes
nomi.query_postal_code(["620018", "620017", "620012"])
输出
“PGEOCODE”
通过将国家和邮政编码作为输入来计算两个邮政编码之间的距离,结果以公里为单位:
# 两个邮政编码之间的物理距离
distance = pgeocode.GeoDistance('In')
distance.query_postal_code("620018", "620012")
输出

geopandas
派生出若干新的需求:
a、就是如何获得中国的国家简称?
待续
b、如何根据邮编获取经纬度和所在地名称?
待续
5
rembg
rembg 是另一个有用的库,可以轻松地从图像中删除背景。
#Installation
pip install rembg
例
# Importing libraries
from rembg import remove
import cv2
# path of input image (my file: image.jpeg)
input_path = 'image.jpeg'
# path for saving output image and saving as a output.jpeg
output_path = 'output.jpeg'
# Reading the input image
input = cv2.imread(input_path)
# Removing background
output = remove(input)
# Saving file
cv2.imwrite(output_path, output)
输入本地目录存入待处理的照片:

输出扣去背景的效果:

Humanize
翻译为字面意思即“人性化”—为数字、日期和时间提供简单、易于阅读的字符串格式。
该库的目标是获取数据并使其更加人性化,例如,通过将秒数转换为更具可读性的字符串,如“2 分钟前”。
该库可以通过多种方式格式化数据,包括使用逗号格式化数字、将时间戳转换为相对时间等。
我经常在数据工程项目中使用整数和日期和时间。
安装
pip install humanize
示例-整数
# Importing library
import humanize
import datetime as dt
# Formatting numbers with comma
a = humanize.intcomma(951009)
# converting numbers into words
b = humanize.intword(10046328394)
#printing
print(a)
print(b)
输出
951,009
10.0 billion
示例日期和时间
import humanize
import datetime as dt
a = humanize.naturaldate(dt.date(2012, 6, 5))
b = humanize.naturalday(dt.date(2012, 6, 5))
print(a)
print(b)
输出
Jun 05 2012
Jun 05
7
开放街道地图 OSM 数据
osmnx是获取有关当地社区空间信息的非常有用的工具。
除了广泛的可用性之外,它可以通过Python轻松获得。本文向您展示如何下载OSM数据,如下所示。图为柏林的餐馆。

显示所有餐厅的柏林地图
柏林餐厅目标是收集不同年份、不同地理位置以及不同类型的机构的数据。当然,您只需选择一个选项即可轻松简化任务。
首先,让我们首先通过加载必要的库来设置我们的文件。我还喜欢为指向文件目录的路径定义全局变量。所以,让我们也这样做。
# 必要的模块
import os
from os.path import join
import osmnx
import pandas as pd
# 全局路径变量
main_path = "your_main_path"
data_path = join(main_path, "data")
需要操作系统来处理我们的目录路径。
osmnx是我用来从OSM检索数据的主要库。我建议使用虚拟环境来避免库安装时出现任何问题。
我通常在 Anaconda 中设置一个虚拟环境,并通过通道 conda-forge 安装 osmnx。最后,熊猫主要用于数据操作和导出。
第二步要求我们为感兴趣的数据指定所有相关参数,包括我们要提取的地点类型以及地理位置。
cities = ["Berlin, Germany", "Hamburg, Germany"]
places = ["restaurant", "bar"]
cities = [“柏林, 德国”, “汉堡, 德国”]
地点 = [“餐厅”, “酒吧”]
#注意:如果您有外部存储的城市列表,您也可以在此处阅读。
#你只需要在这些城市中循环。
我喜欢将以前定义的不同位置存储在自己的文件夹中。这是完全可选的。以下代码自动设置文件夹结构。
for p in places:
isExist = os.path.exists(join(data_path, p))
if not isExist:
os.makedirs(join(data_path, p))
为了获得不同的年份,我们定义了一个时间戳,即检索OSM快照的时间点。这是按如下方式完成的:
# 设置时间戳
settings = '[out:json][timeout:180][date:"{year}-12-31T00:00:00Z"]'
时间戳设置为年底。任何其他日期也可以。
{year} 是用于循环多年中的占位符。
因此,要定义的最后一个参数是时间范围。
years = ["2020", "2021"]
最后,我们需要一个列表来存储收集的数据。
# 用于存储数据
extracted_data = []
一切准备就绪后,我们可以遍历所有选项。
# 循环年份并在地点获取时间快照:
对于城市中的城市: 对于年份:
# 定义标签标签
for place in places:
for city in cities:
for year in years:
# 定义标签
tag = {
"amenity" : place}
# 设置提取年份
osmnx.settings.overpass_settings = settings.format(year = year)
# 提取标签和年份的数据
tagged_data = osmnx.geometries_from_place(city, tags = tag)
# 添加快照年份
tagged_data["snap_year"] = year
# 导出数据
filename = str(place) + "_" + str(year) + "_" + str(city) + ".csv"
path = join(data_path, place)
tagged_data.to_csv(join(path, filename))
# 打印以查看代码在打印时
extracted_data.append(tagged_data)
# 追加列表以存储数据
print(f"Extraction of {
year} and {
city} for {
tag} completed")
请注意,我在这里定义了便利设施如餐厅和酒吧。您还可以根据 OSM 标签定义其他类型如休闲。您可以通过咨询谷歌来了解不同的类型。就是这样。总之,它检索指定参数集的 OSM 数据。
您可能已经熟悉其中一些库,Sketch、Pendulum、pgeocode 、 ftfy 以及开放街道地图 OSM 数据对于我的数据工程是必不可少的,非常依赖它们。
最后:
【想要学习爬虫的朋友们 我这里整理了很多Python学习资料上传到CSDN官方了,有需要的朋友可以扫描下方二维码进行获取】
一、学习大纲
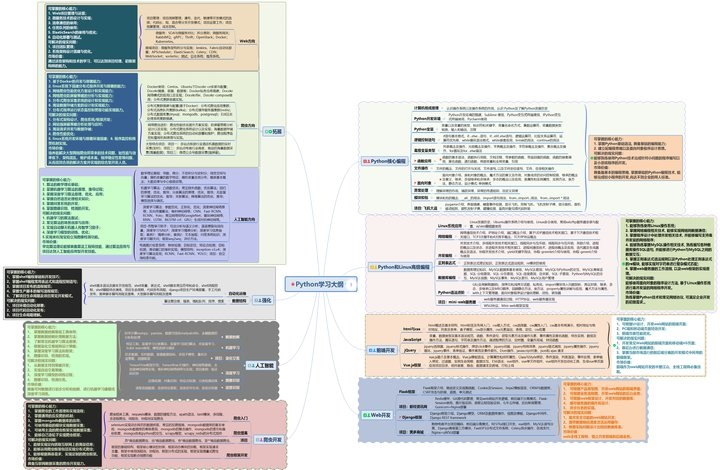
二、开发工具

三、Python基础材料
四、实战资料