机器学习保险行业问答开放数据集: 2. 使用案例

在上一篇文章中,介绍了数据集的设计,该语料可以用于研究和学习,从规模和质量上,是目前中文问答语料中,保险行业垂直领域最优秀的语料,关于该语料制作过程可以通过语料主页了解,本篇的主要内容是使用该语料实现一个简单的问答模型,并且给出准确度和损失函数作为数据集的Baseline。
DeepQA-1
为了展示如何使用该语料训练模型和评测算法,我做了一个示例项目 - DeepQA-1,本文接下来会介绍DeepQA-1,假设读者了解深度学习基本概念和Python语言。
Data Loader
数据加载包含两部分:加载语料和预处理。 加载数据使用 insuranceqa_data 载入训练,测试和验证集的数据。

预处理是按照模型的超参数处理问题和答案,将它们组合成输入需要的格式,在本文介绍的baseline model中,预处理包含下面工作:
- 在词汇表(vocab)中添加辅助Token: <PAD>, <GO>. 假设x是问题序列,是u回复序列,输入序列可以表示为:
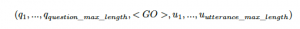
超参数question_max_length代表模型中问题的最大长度。 超参数utterance_max_length代表模型中回复的最大长度,回复可能是正例,也可能是负例。

其中,Token <GO> 用来分隔问题和回复,Token <PAD> 用来补齐问题或回复。
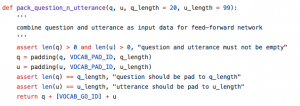
训练数据包含了141,779条,正例:负例=1:10,根据超参数生成输入序列:
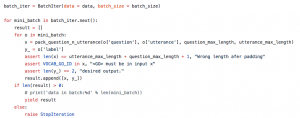
上图 中 x 就是输入序列。y_代表标注数据:正例还是负例,正例标为[1,0],负例标为[0,1],这样做的好处是方便计算损失函数和准确度。测试数据和验证数据也用同样的方式进行处理,唯一不同的是它们不需要做成mini-batch。需要强调的是,处理词汇表和构建输入序列的方式可以尝试用不同的方法,上述方案仅作为表达baseline结果而采用,一些有助于增强模型能力的,比如使用word2vec训练词向量都值得尝试。
Network
baseline model使用了最简单的神经网络,输入序列从左侧进入,输出序列输出包含2个数值的vector,然后使用损失函数计算误差。
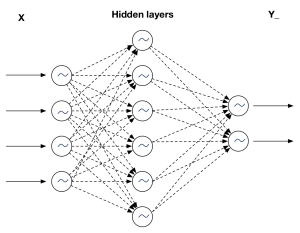
超参数,Hyper params
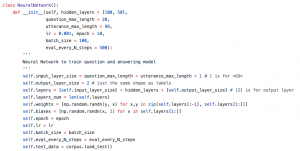

损失函数
神经网络的激活函数使用函数,损失函数使用最大似然的思想。
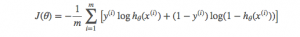

迭代训练
使用mini-batch加载数据,迭代训练的大部分工作在back_propagation中完成,它计算出每次迭代的损失和b,W 的误差率,然后使用学习率和误差率更新每个b,W 。
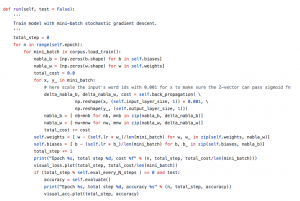
执行训练脚本
python3 deep_qa_1/network.py
Visual
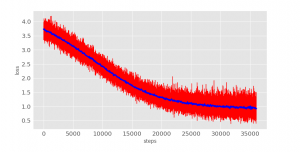
在训练过程中,观察损失函数和准确度的变化可以帮助优化超参数的设计。
loss
python3 visual/loss.py
accuracy
python3 visual/accuracy.py
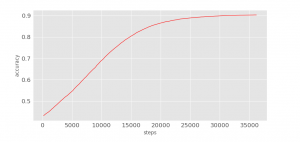
在迭代了25,000步后就基本维持在一个固定值,学习停止了。
Baseline
使用获得的Baseline数据为:
Epoch 25, total step 36400, accuracy 0.9031, cost 1.056221.
总结
Baseline model设计的非常简单,它展示了如何使用insuranceqa-corpus-zh训练FAQ问答模型,项目的源码参考这里。在过去两周中,为了能让这个数据集能满足使用,体现其价值,我花了很多时间来建设,仓促之中仍然会包含一些不足,比如数据集中,每个问题是唯一的,不包含相似问题,是这个数据集目前最大的缺陷,另外一方面,因为该数据集的回复包含一个正例和多个负例,可以用用于训练分类器,也可以用于训练ranking model。如果在使用的过程中,遇到任何问题,可以通过数据集的地址 反馈。
机器学习保险行业问答开放数据集: 1. 语料介绍
目前机器学习,尤其是因为深度学习的一波小高潮,大家对使用深度学习处理文本任务,兴趣浓厚,数据是特征提取的天花板,特征提取是深度学习的天花板。在缺少语料的情况下,评价算法和研究都很难着手,在调研了众多语料之后,深知高质量的开放语料十分稀少,比如百度开放的Web QA 1.0 语料,包含的问题也就是四万余条,而分成不同的垂直领域,就根本不能用于FAQ模型的训练,这就是我做了这个语料的原因 - 支持常见问题集模型的算法评测和研究。我将通过两篇文章来分享这个语料:(1) 语料介绍, 介绍语料的组成; (2) 使用案例,介绍一个简单使用该语料进行深度学习训练的案例,可以作为 baseline。
该语料库包含从网站Insurance Library 收集的问题和答案。
据我们所知,这是保险领域首个开放的QA语料库:
该语料库的内容由现实世界的用户提出,高质量的答案由具有深度领域知识的专业人士提供。 所以这是一个具有真正价值的语料,而不是玩具。
在上述论文中,语料库用于答复选择任务。 另一方面,这种语料库的其他用法也是可能的。 例如,通过阅读理解答案,观察学习等自主学习,使系统能够最终拿出自己的看不见的问题的答案。
数据集分为两个部分“问答语料”和“问答对语料”。问答语料是从原始英文数据翻译过来,未经其他处理的。问答对语料是基于问答语料,又做了分词和去标去停,添加label。所以,"问答对语料"可以直接对接机器学习任务。如果对于数据格式不满意或者对分词效果不满意,可以直接对"问答语料"使用其他方法进行处理,获得可以用于训练模型的数据。
欢迎任何进一步增加此数据集的想法。
快速开始
语料地址
在Python环境中,可以使用pip安装
兼容py2, py3
pip install --upgrade insuranceqa_data
问答语料
| 问题 | 答案 | 词汇(英语) | |
| 训练 | 12,889 | 21,325 | 107,889 |
| 验证 | 2,000 | 3354 | 16,931 |
| 测试 | 2,000 | 3308 | 16,815 |
每条数据包括问题的中文,英文,答案的正例,答案的负例。案的正例至少1项,基本上在1-5条,都是正确答案。答案的负例有200条,负例根据问题使用检索的方式建立,所以和问题是相关的,但却不是正确答案。
{
"INDEX": {
"zh": "中文",
"en": "英文",
"domain": "保险种类",
"answers": [""] # 答案正例列表
"negatives": [""] # 答案负例列表
},
more ...
}
训练:corpus/pool/train.json.gz
验证:corpus/pool/valid.json.gz
测试:corpus/pool/test.json.gz
答案:corpus/pool/answers.json 一共有 27,413 个回答,数据格式为 json:
{
"INDEX": {
"zh": "中文",
"en": "英文"
},
more ...
}
中英文对照文件
问答对
文件: corpus/pool/train.txt.gz, corpus/pool/valid.txt.gz, corpus/pool/test.txt.gz.
格式: INDEX ++$++ 保险种类 ++$++ 中文 ++$++ 英文
答案
文件: corpus/pool/answers.txt.gz
格式: INDEX ++$++ 中文 ++$++ 英文
语料库使用gzip进行压缩以减小体积,可以使用zmore, zless, zcat, zgrep等命令访问数据。
zmore pool/test.txt.gz
加载数据
import insuranceqa_data as insuranceqa
train_data = insuranceqa.load_pool_train()
test_data = insuranceqa.load_pool_test()
valid_data = insuranceqa.load_pool_valid()# valid_data, test_data and train_data share the same properties
for x in train_data:
print('index %s value: %s ++$++ %s ++$++ %s' % \
(x, d[x]['zh'], d[x]['en'], d[x]['answers'], d[x]['negatives']))answers_data = insuranceqa.load_pool_answers()
for x in answers_data:
print('index %s: %s ++$++ %s' % (x, d[x]['zh'], d[x]['en']))
问答对语料
使用"问答语料",还需要做很多工作才能进入机器学习的模型,比如分词,去停用词,去标点符号,添加label标记。所以,在"问答语料"的基础上,还可以继续处理,但是在分词等任务中,可以借助不同分词工具,这点对于模型训练而言是有影响的。为了使数据能快速可用,insuranceqa-corpus-zh提供了一个使用HanLP分词和去标,去停,添加label的数据集,这个数据集完全是基于"问答语料"。
import insuranceqa_data as insuranceqa
train_data = insuranceqa.load_pairs_train()
test_data = insuranceqa.load_pairs_test()
valid_data = insuranceqa.load_pairs_valid()# valid_data, test_data and train_data share the same properties
for x in test_data:
print('index %s value: %s ++$++ %s ++$++ %s' % \
(x['qid'], x['question'], x['utterance'], x['label']))vocab_data = insuranceqa.load_pairs_vocab()
vocab_data['word2id']['UNKNOWN']
vocab_data['id2word'][0]
vocab_data['tf']
vocab_data['total']
vocab_data包含word2id(dict, 从word到id), id2word(dict, 从id到word),tf(dict, 词频统计)和total(单词总数)。 其中,未登录词的标识为UNKNOWN,未登录词的id为0。
train_data, test_data 和 valid_data 的数据格式一样。qid 是问题Id,question 是问题,utterance 是回复,label 如果是 [1,0] 代表回复是正确答案,[0,1] 代表回复不是正确答案,所以 utterance 包含了正例和负例的数据。每个问题含有10个负例和1个正例。
train_data含有问题12,889条,数据 141779条,正例:负例 = 1:10 test_data含有问题2,000条,数据 22000条,正例:负例 = 1:10 valid_data含有问题2,000条,数据 22000条,正例:负例 = 1:10
句子长度:
max len of valid question : 31, average: 5(max)
max len of valid utterance: 878(max), average: 165(max)
max len of test question : 33, average: 5
max len of test utterance: 878, average: 161
max len of train question : 42(max), average: 5
max len of train utterance: 878, average: 162
vocab size: 24997
可将本语料库和以下开源码配合使用
DeepQA2: https://github.com/Samurais/DeepQA2
InsuranceQA TensorFlow: https://github.com/l11x0m7/InsuranceQA
Chatbot Retrieval: https://github.com/dennybritz/chatbot-retrieval
声明
声明1 : insuranceqa-corpus-zh
本数据集使用翻译 insuranceQA而生成,代码发布证书 GPL 3.0。数据仅限于研究用途,如果在发布的任何媒体、期刊、杂志或博客等内容时,必须注明引用和地址。
InsuranceQA Corpus, Hai Liang Wang, https://github.com/Samurais/insuranceqa-corpus-zh, 07 27, 2017
任何基于insuranceqa-corpus衍生的数据也需要开放并需要声明和“声明1”和“声明2”一致的内容。
声明2 : insuranceQA
此数据集仅作为研究目的提供。如果您使用这些数据发表任何内容,请引用我们的论文:
Applying Deep Learning to Answer Selection: A Study and An Open Task。Minwei Feng, Bing Xiang, Michael R. Glass, Lidan Wang, Bowen Zhou @ 2015
北京森林工作室汉语句义结构标注语料库(BFS-CTC)共享资源
句义结构分析是汉语语义分析中不可逾越的重要环节,为了满足汉语句义结构分析的需要,北京森林工作室(BFS)基于现代汉语语义学理论构建了一种层次化的汉语句义结构模型,定义了标注规范和标记形式,建设了一个汉语句义结构标注语料库BFS-CTC(Beijing Forest Studio – Chinese Tagged Corpus)。
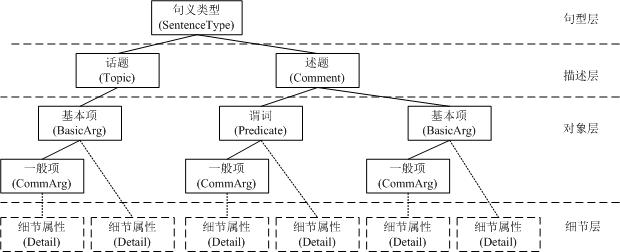
标注内容方面,基于句义结构模型的定义标注了句义结构句型层、描述层、对象层和细节层中所包含的各个要素及其组合关系,包括句义类型、谓词及其时态、语义格类型等信息,并且提供了词法和短语结构句法信息,便于词法、句法、句义的对照分析研究。
语料库组织结构方面,该语料库包括四个部分,即原始句子库、词法标注库、句法标注库和句义结构标注库,可根据研究的需要,在词法、句法、句义结构标注的基础上进行深加工,在核心标注库的基础上添加更多具有针对性的扩展标注库,利用句子的唯一ID号进行识别和使用。
语料来源和规模方面,原始数据全部来自新闻语料,经过人工收集、整理,合理覆盖了主谓句、非主谓句、把字句等六种主要句式类型,规模已达到50000句。
BFS-CTC基于现代汉语语义学,提供了多层次的句义结构标注信息,在兼容现有标注规范的情况下进行了词法和语法标注。BFS标注的词法,句法及句义既可以单独使用也可综合使用,可用于自然语言处理多方面的研究。
为进一步推动汉语语义分析的研究和发展,,北京森林工作室(BFS)从2013年4月15日起对外开放下载3,000句句义结构标注示例,更多句义结构标注语料可向BFS申请后免费使用,详见http://www.isclab.org/archives/2013/04/1740.html。句义结构的基本形式如下图所示:
NLP资源共享盛宴
“科技创新,方法先行”。为响应科技部“十二五”关于加强科技资源共享的号召,中科院自动化所“自动化学科创新思想与科学方法研究(课题编号:2009IM020300)”课题 与国内专业的科研数据共享平台-数据堂 网站展开全面合作,将自动化学科数字化知服务网络平台的部分后台数据,以及项目中的一些其他数据资源,免费提供给自然语言处理等相关领域同仁从事科研使用。数据专区地址是:http://www.datatang.com/member/5878。如您论文或项目使用该专区数据,请注明数据来自“自动化学科创新思想与科学方法研究”课题,编号2009IM020300,以及数据堂数据地址http://www.datatang.com/member/5878。
该专区主要包括以下几部分资源:
1.面向计算机学科内学术共同体相关研究的中文DBLP资源
2.面向人物同名消歧研究的的中文DBLP资源
3.万篇随机抽取论文中文DBLP资源
4.以自然语言处理领域中文期刊论文为主导的中文DBLP资源
5.面向文本分类研究的中英文新闻分类语料
6.文本分类程序(含开源代码)
7.面向汉语姓名构词研究的10万中文人名语料库
8.以IG卡方等特征词选择方法生成的多维度ARFF格式英文VSM模型
9.以IG卡方等特征词选择方法生成的多维度ARFF格式中文VSM模型
欢迎自动化学科数字化知识服务网络平台:http://autoinnovation.ia.ac.cn
欢迎大家继续关注自动化学科创新方法课题,我们的联系方式
http://weibo.com/autoinnovation,
欢迎大家关注数据堂: http://weibo.com/datatang
祝大家新春快乐,龙年如意!
请求捐赠短信,为短信语料库的创建出一份力
大家好:
我们是来自新加坡国立大学计算机学院的研究人员。我们在6年前收集过英文短信,之后发布了10,000条英文短信的语料库,供研究人员免费使用。
目前我们重新启动了短信收集项目,扩展已有的英文短信,同时还为了创建中文短信库。该项目通过了新加坡国立大学学术委员会的审查。目前我们收集到 15,111条中文短信,语料库已经发布。详情见http://wing.comp.nus.edu.sg:8080/SMSCorpus/。
短信属于隐私数据,收集十分不易。目前在学术领域,公开的短信数据库非常稀少。我们发这个帖子的目的,是让更多的人了解我们的工作,宣传我们的语料库,更重要地是希望你能够帮助语料库的创建。
希望大家能够捐赠一些自己的短信!为短信研究贡献自己的一份力量!捐赠短信的详细方法见项目主页(http://wing.comp.nus.edu.sg:8080/SMSCorpus/)的短信捐赠页面。在存入数据库前,我们会对收集到的短信做相应的处理,保护捐献者的隐私。
感谢大家!
公布一批中文文本分类的新闻语料库
注:博文转载、语料库使用,请注明提供者、来源以及空间提供方。
免责声明:此语料库仅供自然语言处理的业余爱好者研究和交流,禁止用于任何商业用途(包括在资源内部链接广告等行为)。
感谢网易新闻中心、腾讯新闻中心、凤凰新闻中心以及新浪新闻中心提供新闻素材。新闻著作权归以上网站所有,任何人未经上述公司允许不得抄袭。
语料库下载地址:http://download.cnblogs.com/finallyliuyu/corpus.rar
语料素材来源: 凤凰新闻中心、网易新闻中心、腾讯新闻中心、新浪新闻中心。
语料库整理提供者: finallyliuyu
语料库空间提供方: 博客园(无偿提供)
说明:
1、此语料库非职务作品,由本人在业余时间搜集整理,免费提供给对NLP狂热的业余爱好者学习研究使用;本人是自然语言处理的业余爱好者,在类别定义等方面都可能存在一些欠缺,欢迎大家提出宝贵意见和建议;
2、下载地址提供的是MS SQL2000数据库的备份文件。使用此数据库,您需要安装 MS SQL2000 server,然后将corpus.rar解压并还原。压缩包大小为54.8M,共包含39247篇新闻,分为历史、军事、文化、读书、教育、IT、娱乐、社会与法制等八个类别。历史类、文化类、读书类新闻来自于凤凰网,IT类的新闻全部来自tech.qq,教育类的新闻来自edu.qq,娱乐类的新闻来自网易。社会与法制类的新闻来自于新浪和腾讯的几个版面;
3、需要特别注意的是,有的新闻在开头处有大量空白,因此在查询数据库ArticleText字段中有大片空白的,不是空新闻,是整个新闻体截断显示的缘故。
4、有关语料库的其他情况,请参考《献给热衷于自然语言处理的业余爱好者的中文新闻分类语料库之一》。
我本人在此语料库做过的验证性实验有:《KL语义距离计算系列》 ,《Kmeans聚类系列》以及《文本分类和特征词选择系列》。
微软:Web N-gram Services
微软研究院的官方网站上近期发布了一篇文章:“Microsoft Web N-gram Services",大意是邀请整个社区使用其提供的"Web N-gram services",这个服务旨在通过基于云的存储平台,推动网络搜索,自然语言处理,语音技术等相关领域,在研究现实世界的大规模网络数据时,利用该服务所提供动态数据对项目中的常规数据进行补充更新,进而有所发现和创新。 继续阅读
欧洲议会平行语料库介绍
平行语料库对于统计机器翻译(SMT)的研究至关重要,欧洲议会平行语料库是目前互联网上可免费获取的非常规范的平行语料库。本文主要根据欧洲议会平行语料库的英文主页介绍进行了粗略翻译,其时间跨度从1996年至2006年,目前这个语料库还在继续扩建中。 继续阅读
EuroMatrix与开放精神
打开SMT官网主页下的这个页面:http://www.statmt.org/matrix/,会发现一个漂亮的“欧洲矩阵(Euro Matrix)”,这是一个由11*11小方块组成的矩阵:在其对角线上,有欧洲11个国家的名字和国旗;而对角线之外的小方块里,则是机器翻译里的BIEU评分。这个矩阵图展示了欧盟11个国家官方语言间的110种翻译结果的BLEU评分值,而这幅图的背后,则是宏伟的EuroMatrix工程! 继续阅读
MIT自然语言处理第二讲:单词计数(第三部分)
自然语言处理:单词计数
Natural Language Processing: (Simple) Word Counting 继续阅读