数据分析完整流程:保险行业数据分析
一、业务背景
1.业务环境
-
宏观
中国是世界第二大保险市场,但在保险密度上与世界平均水平仍有明显差距。 -
业界
保险行业2018年保费规模为38万亿,同比增长不足4%,过去“短平快“的发展模式已经不能适应新 时代的行业发展需求,行业及用户长期存在难以解决的痛点,限制了行业发展。 -
社会
互联网经济的发展,为保险行业带来了增量市场,同时随着网民规模的扩大,用户的行为习惯已发生转变,这些都需要互联网的方式进行触达。 -
保险科技:当前沿科技不断应用于保险行业,互联网保险的概念将会与保险科技概念高度融合。
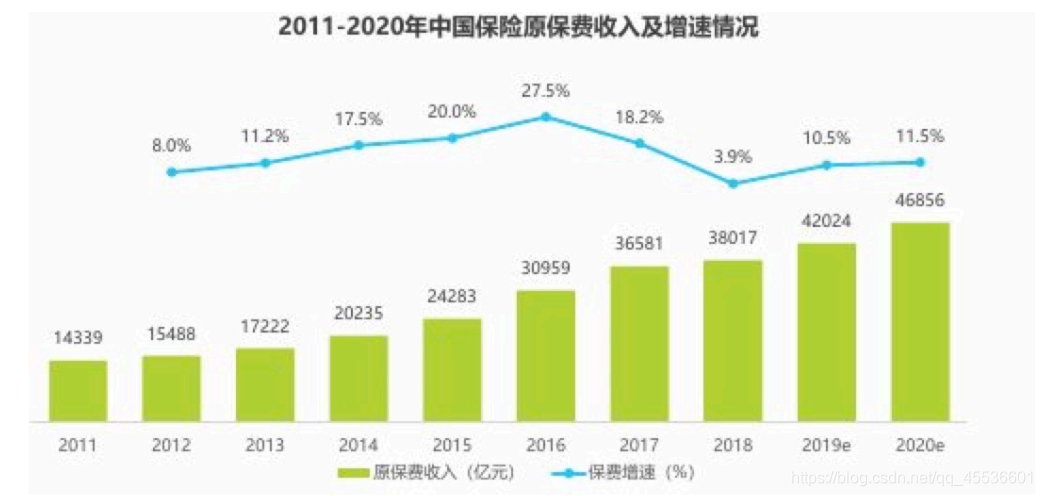
中国保险市场持续高速增长。 根据保监会数据, 2011~2018年,全国保费收入从1.4万亿增长至3.8万亿,年复合增长率17.2%。 2014年,中国保费收入突破2万亿,成为全球仅次于美国、日本的第三大新兴保险市场市场; 2016年,中国整体保费收入突破3万亿,超过日本,成为全球第二大保险市场; 2019年,中国保费收⼊有望突破4万亿。
2. 发展现状
- 概览
受保险行业结构转型时期影响,互联网保险整体发展受阻, 2018年行业保费收入为1889亿元, 较去年基本持平,不同险种发展呈现分化格局,其中健康险增长迅猛, 2018年同比增长108%,主要由短期医疗险驱动。 - 格局
供给端专业互联网保险公司增长迅速,但过高的固定成本及渠道费用使得其盈利问题凸显,加上发展现状强,经营渠道建设及科技输出是未来的破局方法, 渠道端形成第三方平台为主,官网为辅的格局,第三方平台逐渐发展出B2C、 B2A、B2B2C等多种创新业务模式。 - 模式
互联网保险不仅仅局限于渠道创新,其核心优势同样体现在产品设计的创新和服务体验的提升。
3. 发展趋势
- 竞合格局
随着入局企业增多,流量争夺更加激烈,最终保险公司与第三方平台深度合作将成为常态。 - 保险科技
当前沿科技不断应用于保险行业,互联网保险的概念将会与保险科技概念高度融合。
4. 衡量指标

5. 业务目标
针对保险公司的健康险产品的用户,制作用户画像,然后进行精准保险营销。
二、案例数据
1. 数据来源
美国某保险公司,和本公司合作多年。现在该公司有一款新的医疗险产品准备上市。
2. 产品介绍
这一款新的医疗产品主要是针对65岁以上的人群推出的医疗附加险,销售渠道是直邮。
3. 商业目的
为保险公司某种健康险产品做用户画像,找出最具有购买倾向的人群以进行保险营销。
4. 数据介绍
本次案例数据共有76个字段,字段繁多,在处理数据时,需要先将数据按照类别进行归类,方便理解查看。
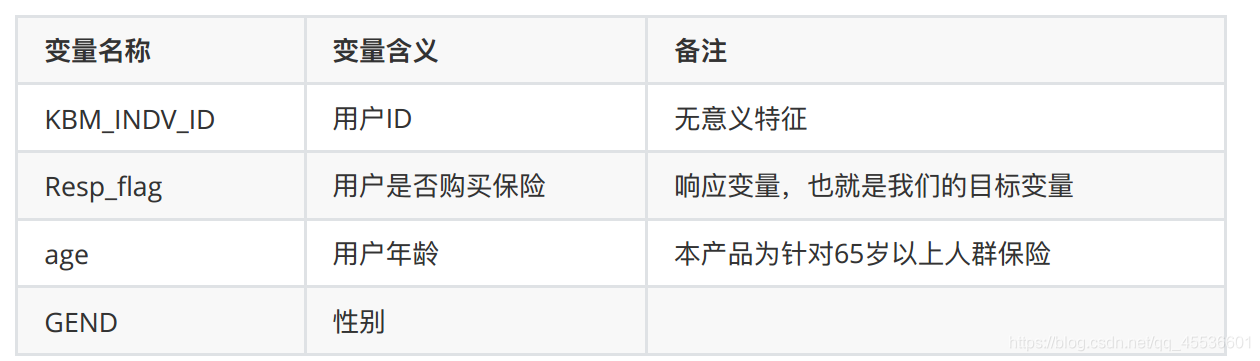
4.1 基本信息
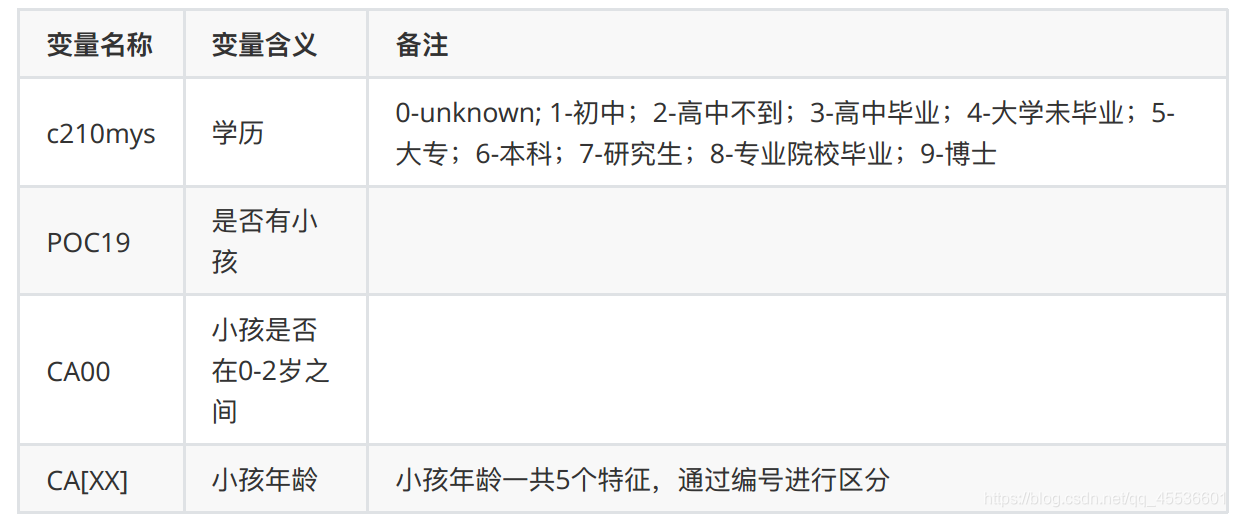
4.2 基本情况
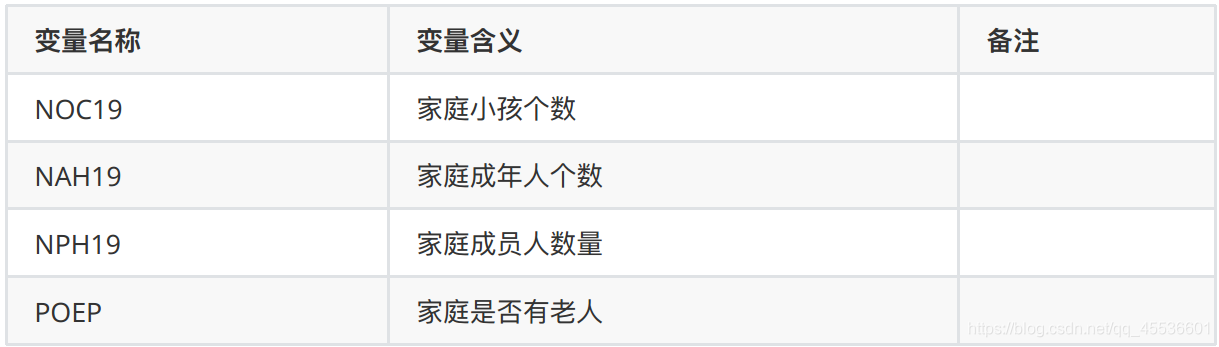
4.3 家庭成员
4.4 家庭成员情况
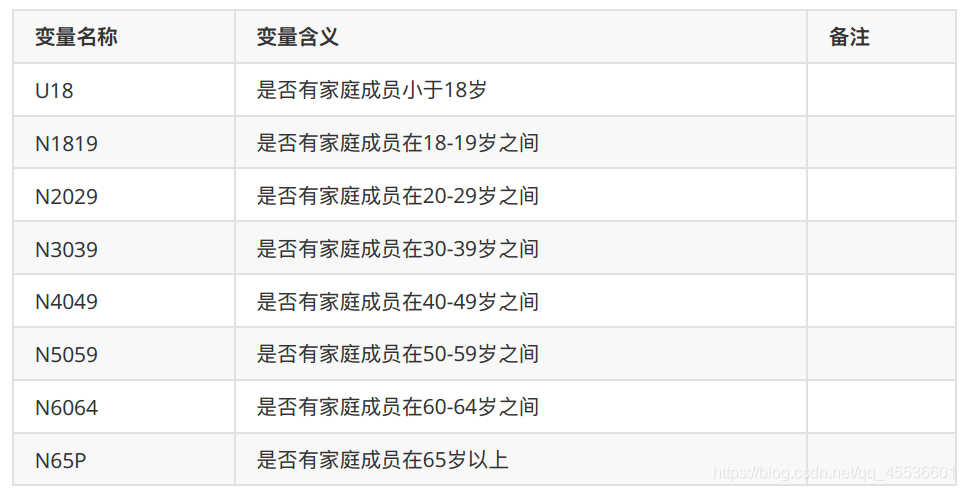
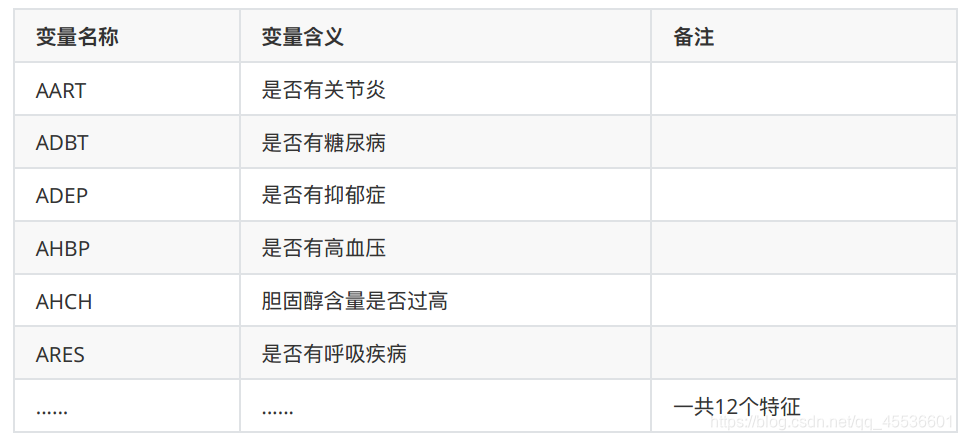
4.5 疾病史
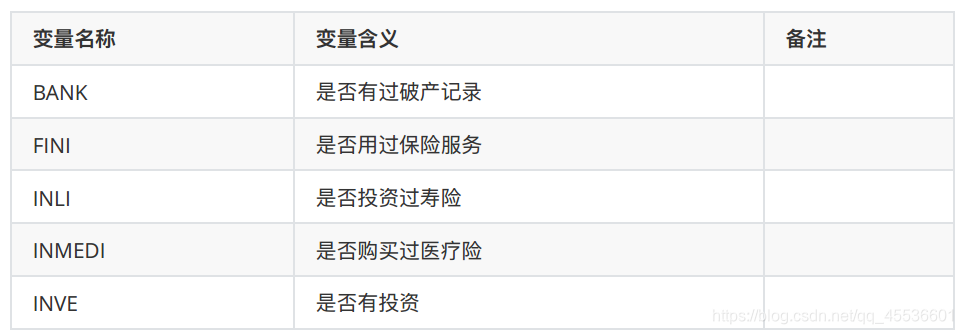
4.6 金融信息
4.7 个人习惯

4.8 家庭状况
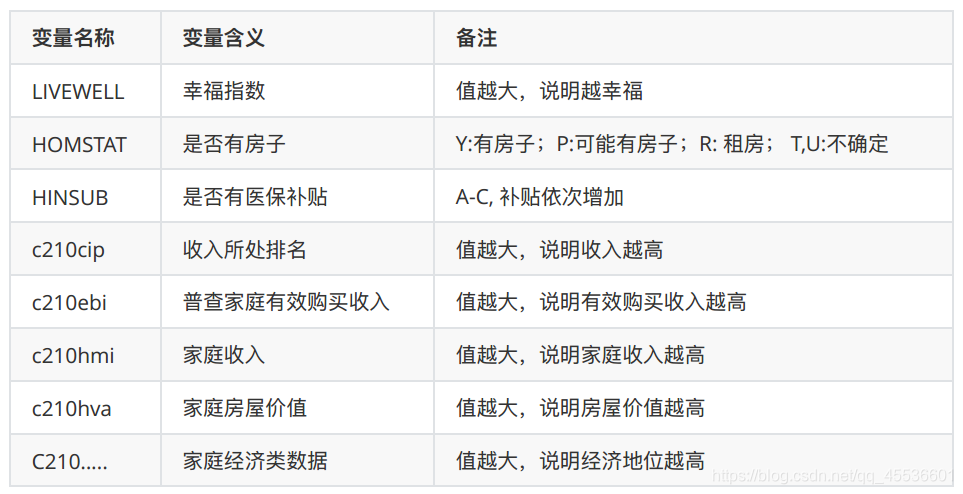
4.9 居住城市
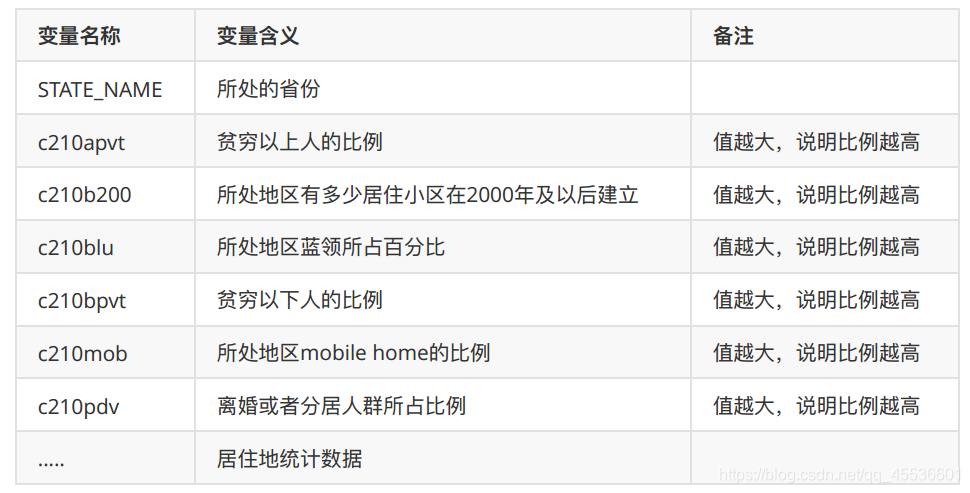
5. 分析思路
- 根据经验,我们可以大概判别哪些特征很可能和用户是否购买保险会有相关关系。
- 结合我们的业务经验,以及数据可视化,特征工程方法,先行探索这些特征中哪些特征更重要。
- 建模之后,再回顾我们这里认为比较重要或不重要的特征,看一下判断是否准确。
三、Python代码实现
- 了解数据样本和特征个数、数据类型、基本信息等
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
df=pd.read_csv(r'D:\liwork\a\data\ma_resp_data_temp.csv')
pd.set_option('max_columns',100) #显示100列数据
df.head()
df.shape
df.info()
- 统计数据基本信息、统计空值数量
#将id转化为object
df['KBM_INDV_ID']=df['KBM_INDV_ID'].astype('object')
df.dtypes
df.describe().T
describe = df.describe().T
describe.to_excel('output/describe_var.xlsx')
#统计空值
len(df.columns)
#空值的列
len(df.columns)-df.dropna(axis=1).shape[1]
NA=df.isnull().sum() # 统计各个列空值的数量
NA
#重置索引
NA=NA.reset_index()
NA
`#修改列名
NA.columns=['Var','NA_count']
NA``
#过滤出有缺失的数据,过滤出大于0的数据
NA=NA[NA.NA_count>0].reset_index(drop=True)
NA
#统计空值比例
NA.NA_count/df.shape[0]
- 数据可视化分析
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn')
#支持中文输出
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
# plt.rcParams['font.family']='Arial Unicode MS' # OS系统
- 探索样本分类是否平衡
df.resp_flag.value_counts()
plt.figure(figsize=(10,3))
sns.countplot(y='resp_flag',data=df)
plt.show()
#比例关系
df.resp_flag.sum()/df.resp_flag.shape[0]
- 绘制年龄的分布情况
#直方图+密度曲线
sns.distplot(df['age'],bins=20)
df['age'].min() #查看年龄
df['age'].max()
- 分别绘制两类样本的年龄分布
x = np.random.randn(100)
sns.kdeplot(x)
#填充颜色
sns.kdeplot(x,shade=True,color='y')
sns.kdeplot(df.age[df.resp_flag==0],label='0',shade=True)
sns.kdeplot(df.age[df.resp_flag==1],label='1',shade=True)
plt.xlabel('Age')
plt.ylabel('Density')
- 查看不同学历之间购买保险的数量
#学历的分布
plt.figure(figsize=(10,3))
sns.countplot(y='c210mys',data=df)
plt.show()
sns.countplot(x='c210mys',hue='resp_flag',data=df)
- 不同县的大小对应的购买数量
sns.countplot(x='N2NCY',hue='resp_flag',data=df)
含空值的列,每一列的数据类型统计出来,并加在NA的表中
temp=[]
for i in NA.Var:
temp.append(df[i].dtypes)
NA['数据类型']=temp
NA
- 空值填充
NA[NA.Var!='age']
df.AASN.mode()[0]
#用众数填充
for i in NA[NA.Var!='age'].Var:
df[i].fillna(df[i].mode()[0],inplace=True)
#对年龄用均值进行填充
df.age.fillna(df.age.mean(),inplace=True)
#验证结果 全是0就代表都已填充完毕
df.isnull().sum()
变量编码
df.head()
#删除ID
del df['KBM_INDV_ID']
#筛选object
df_object=df.select_dtypes('object')
df_object.shape
from sklearn.preprocessing import OrdinalEncoder
df_object=OrdinalEncoder().fit_transform(df_object)
df_object
#字符转数值
for i in df.columns:
if df[i].dtypes=='object':
df[i]=OrdinalEncoder().fit_transform(df[[i]])
df.head()
建模
from sklearn import tree
from sklearn.model_selection import train_test_split
#切分数据集
X=df.iloc[:,1:]
y=df['resp_flag']
Xtrain,Xtest,Ytrain,Ytest=train_test_split(X,y,test_size=0.3,random_state=420)
#建模
clf = tree.DecisionTreeClassifier().fit(Xtrain,Ytrain)
clf.score(Xtest,Ytest)
模型优化
from sklearn.model_selection import GridSearchCV
#网格搜索
param_grid={'max_depth':range(3,8),
'min_samples_leaf':range(1000,3000,100)}
GR = GridSearchCV(tree.DecisionTreeClassifier(),param_grid,n_jobs=-1,cv=5)
GR.fit(Xtrain,Ytrain)
#求出tree.DecisionTreeClassifier里面参数的值
GR.best_params_
GR.best_score_
clf=tree.DecisionTreeClassifier(max_depth=7,min_samples_leaf=1000).fit(Xtrain,Ytrain)
clf.score(Xtest,Ytest)
画决策树
features=list(df.columns[1:])
import graphviz #要提前安装哦
dot_data = tree.export_graphviz(clf,
feature_names=features,
class_names=['No Purchase','Purchase'],
filled=True,
rounded=True)
graph = graphviz.Source(dot_data)
graph
#输出图片
graph.render('model1')
四、输出结果
我们来看一下购买比例最高的两类客户的特征是什么:
第一类
- 处于医疗险覆盖率比例较低区域
- 居住年限小于7年
- 65-72岁群体
- 那么我们对业务人员进行建议的时候就是,建议他们在医疗险覆盖率比例较低的区域进行宣传推广,然后重点关注那些刚到该区域且年龄65岁以上的老人,向这些人群进行保险营销,成功率应该会更高。
第二类
- 处于医疗险覆盖率比例较低区域
- 居住年限大于7年
- 居住房屋价值较高
- 这一类人群,是区域内常住的高端小区的用户。这些人群也同样是我们需要重点进行保险营销的对象。