自制数据训练yolov3模型
1、制作数据集
数据集的来源主要有以下两个途径
1)搜索网上已有的相关数据集
2)使用网络爬虫技术获取图片库的数据
2、数据集标注
数据集收集完毕之后要做的就是按照自己要做的项目要求对图片进行标注,方法如下:
1)安装标注工具labelimg(以windows为例,前提是有anaconda)
①下载labelimg工具包
②打开cmd或者Anaconda Prompt ,cd 到labelImg的所在路径并进入
③执行如下代码便可打开labelImg界面
conda install pyqt=5
conda install -c anaconda lxml
#注意,第二次想要打开labelimg界面的时候只需要执行下面两步就行
pyrcc5 -o libs/resources.py resources.qrc
python labelImg.py
具体方法可参见:https://github.com/heartexlabs/labelImg
2)使用labelImg进行数据标注
①修改predfined_classes.txt里面的类别信息
打开./labelImg-master/data/predfined_classes.txt,修改成需要模型识别的类型并保存
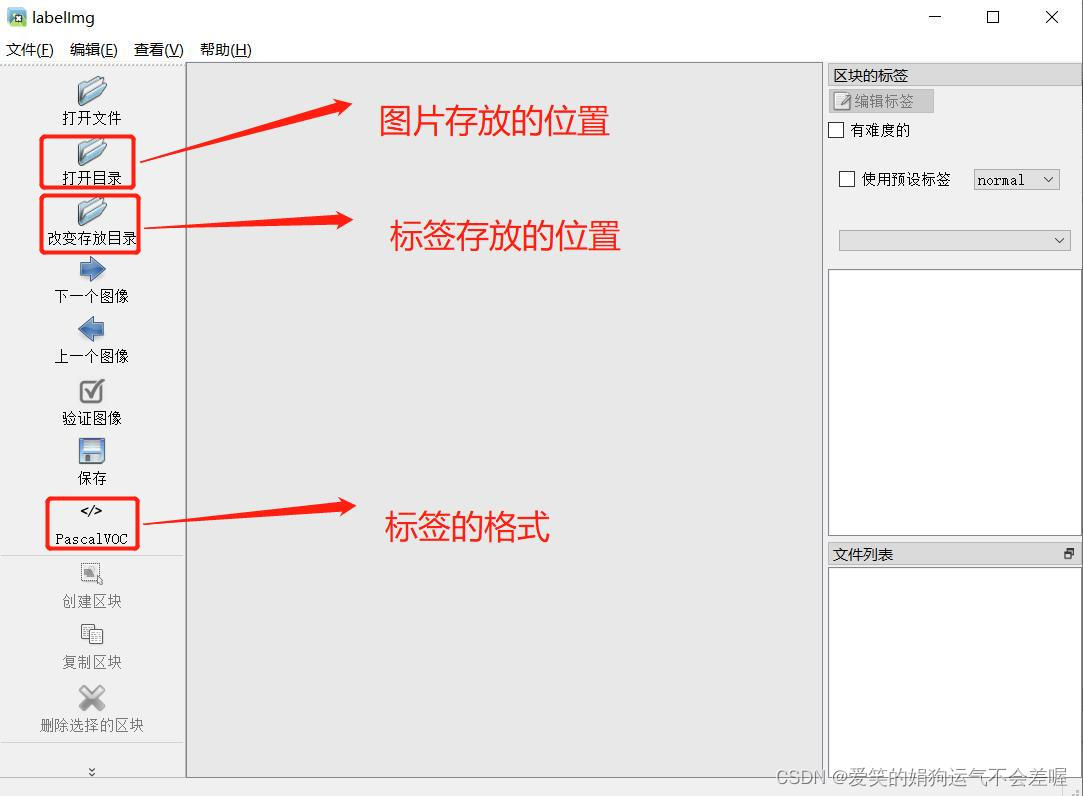
②labelimg的页面如下所示,主要关注三个位置,打开目录,改变存放路径已经yolo格式的选择,再开始标注前需要设定这三个参数
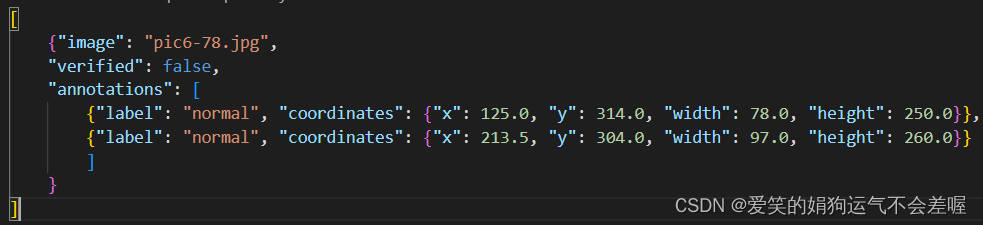
yolo的的格式主要是以下两种:
第一种:Pascal VOC 对应的.json格式
该格式需要转换为txt格式才会用于yolo模型的训练
第二种:YOLO对应的.txt格式
第一列对应的是对象的label属性,后面是归一化之后的坐标

③使用快捷键在labelImg里面进行标注
a.使用大写字母W创建标注区块并选择标签
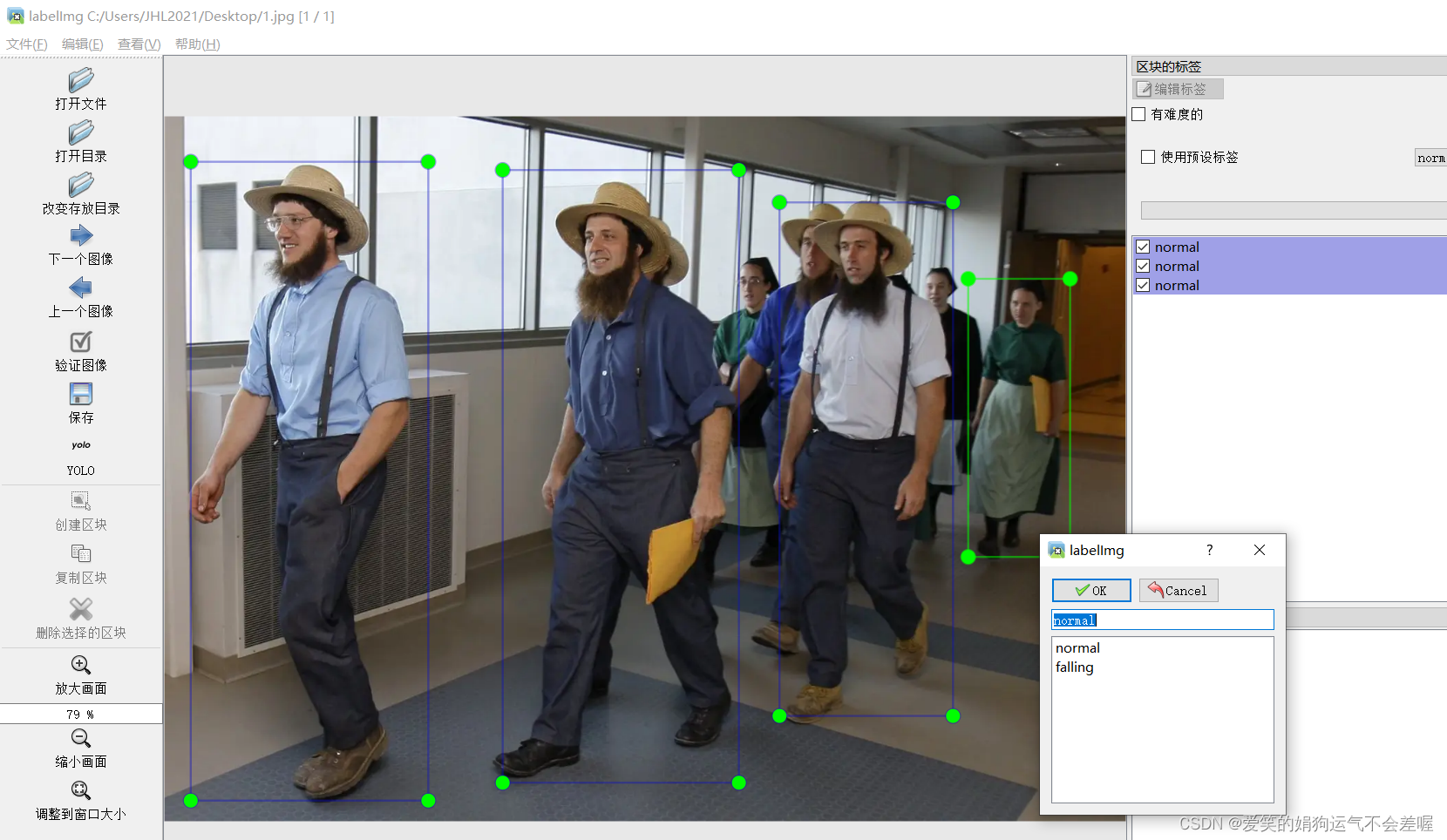
b.标注完之后Ctrl+S保存,然后大写字母D就可以进行下一张标注
3、模型训练
1)数据集划分
新建一个文件夹xx,里面包含三个文件夹,一个是Annotations,里面存放所有的标注结果即txt文件,一个是JPEGImages,里面存放所有的标注jpg图片,最后一个是ImageSets,同时在改文件夹下面建一个Main文件夹,如图所示

划分数据集的代码xx/test.py如下,划分数据集的时候可根据情况选择是否要划分出test数据集
import os
import random
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = './Annotations'
txtsavepath = './ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
print(len(trainval))
train = random.sample(trainval, tr)
print(len(train))
ftrainval = open('./ImageSets/Main/trainval.txt', 'w')
ftest = open('./ImageSets/Main/test.txt', 'w')
ftrain = open('./ImageSets/Main/train.txt', 'w')
fval = open('./ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
整个代码执行完毕就可以看到Main文件夹的txt文档了,里面的内容为各个数据集中的图片名称,如下图
2)下载github上面的yolov3的项目仓库
https://github.com/ultralytics/yolov3/tree/archive
git clone -b archive https://github.com/ultralytics/yolov3.git
将1)步创建的三个文件夹及内容均放在data目录下,然后重新生成数据集划分的txt文档,此时的txt文档添加了图片的路径,并将txt文档放置data的目录下面
add_path.py的内容如下
import os
imgpath = './data/JPEGImages/'
txtpath = './data/ImageSets/Main/'
savepath = './data/'
txtlist = os.listdir(txtpath)
for txt in txtlist:
image_ids = open(txtpath + txt).read().strip().split()
filename = savepath + txt
if not os.path.isfile(filename):
fd = open(filename, mode = 'w', encoding = 'utf-8')
for image_id in image_ids:
fd.write(imgpath + '%s.jpg\n' % (image_id))
fd.close()
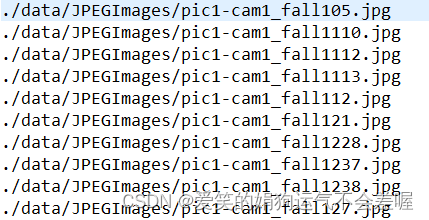
此时的txt的内容如下:
3)修改data目录下相关的参数
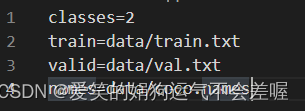
①coco.data,主要是类别数量,train和val数据集对应的txt文档的位置
②coco.names,就是你自己数据集的标签名字

4)修改yolov3的.cfg文件
yolov3.cfg文件存在于./yolov3/cfg文件夹里面
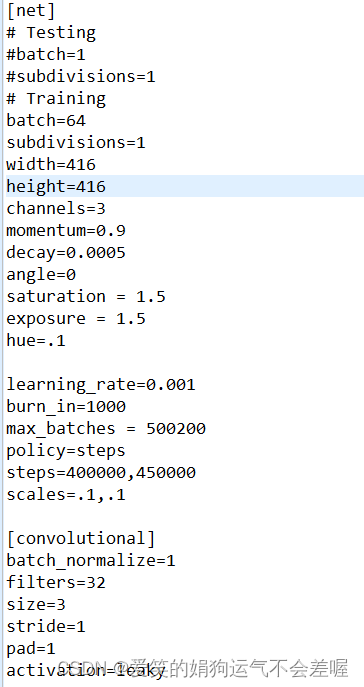
在net里面主要修改图片的大小即width和height,其次还需要修改yolov3结构上的参数,主要有三个地方(三个地方需要修改的内容一致,所以此处只放一张图)

[yolo]处只需要修改classes即可,如果需要实现多尺度训练可以将random设置为1,另一处需要修改的是紧邻[yolo]前面的[convolutional],他的filters = 3*(类别数+4+1)
5)修改训练代码train.py
train.py需要修改的参数如下:
–cfg,–data,–weights的自定义位置,其中wights是指官方的yolov3.weights,可以自己提前下好存放在weights文件下面,还有–img-size需要根据cfg文件的数值进行修改,即你的width和height
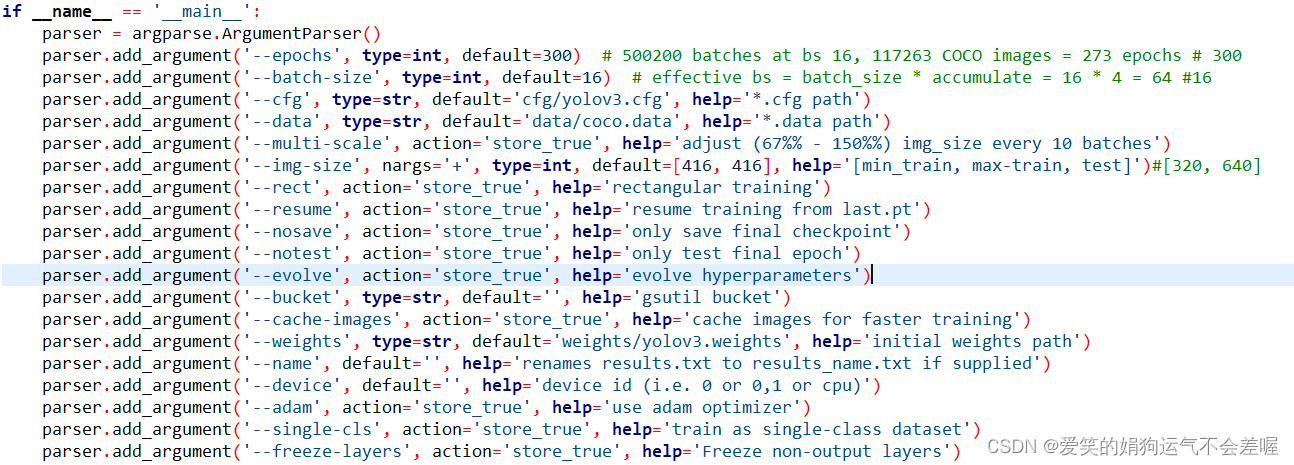
6)模型训练
直接在命令行输入如下代码即可执行:
python3 train.py --cfg cfg/yolov3.cfg --data data/coco.data --epochs XX --device x
其中–标识符对应的参数可以直接在5)中进行提前确定,也可以在执行的时候重新添加
4、问题总结与解决办法
1)内存限制的问题
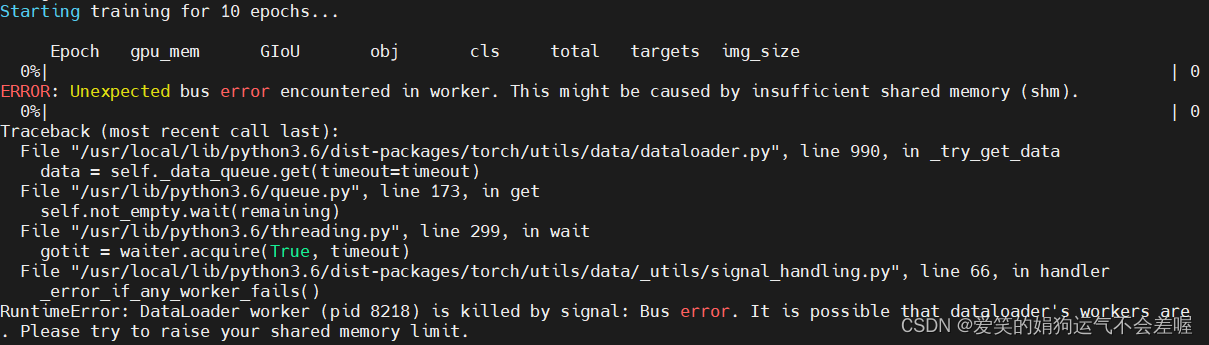
出现这个问题一般有两个原因,一个是batch_size设置过大,一个是数据导入的时候多线程设置太多(如果有其它进程使用多线程是很有可能出现这种问题的),解决办法就是在5)中降低–batch-size的默认值,另一个就是在train.py中数据导入部分将nw参数降低

2)图片解析的问题
在代码运行的过程中,也会出现无法解析的过程,就是cv2.imread()读取图片返回为None的情况,具体原因和详细的解决办法参见本人的博客
https://blog.csdn.net/LJ1120142576/article/details/127676051
3)图片路径解析问题
如果在代码运行期间出现无法对图片路径进行解析,代码错误定位大概在test.py的138行左右(这个问题我忘了截图了,所以只能大概描述一下),主要是image_id的问题,原始的代码126行写的是
image_id = int(Path(paths[si]).stem.split('_')[-1])
这一步的写法是根据原来数据集的命名写的,所以根据自己的数据集的命名就会出现错误提示,我这边是直接将这一步改为如下语句
image_id = paths[si]
直接用图片的位置来显示图片的image_id,说白了就是表征后面的属性对应于这张图片就行,同理大概在207行的位置有个imgIds也需要更改,直接改成如下的语句
imgIds = [x for x in dataloader.dataset.img_files]
注意:
在这里说明一下我的理解:在train.py的代码里面出现了调用test.py里面test函数的过程,主要是每个epoch之后使用val数据集进行验证,虽然调用的是test.py中的test函数,但是并不是对test数据集进行测试,而是用val数据集进行验证,如果需要测试模型的最终效果,还需要修改test.py里面的if name == ‘main’: 这部分的内容
相关参考链接
【1】链接: link
【2】链接: link
【3】链接: link
【4】链接: link
以上便是根据自己的训练过程进行的总结和说明,一方面是为了方便自己以后进行回顾,另一方面也帮小伙伴避一些遇见的坑,如果大家发现有不对的地方还请指正,谢谢啦