环境配置
1.环境选择
python 3.6
tenserflow 1.4.0
keras 2.2.4
2.python3.6的下载及配置
①下载链接
https://www.filehorse.com/download-python-64/35070/
②安装
安装过程比较简单,这里就不多加描述了。
③配置环境变量
根据自己安装的位置将路径添加到PATH环境变量。下面是我的安装路径
F:\PythonLocation
F:\PythonLocation`Scripts`
说明:
PythonLocation是我安装路径自己取得名称,需要对应到你自己的路径
3.安装相应的模块
win+R进入cmd,执行下面命令
pip install --upgrade pip #更新pip
pip install tensorflow==1.4.0 #安装 tensorflow
pip install --upgrade numpy #numpy是一个基础的数组计算包,有时候版本较老会报错
pip install keras==2.2.4 #yolo train.py文件里面要用到keras这个高层神经网络API
pip install pillow #安装 图片处理模块PIL(pillow)
pip install matplotlib #安装 2D绘图库matplotlib
pip install opencv-python #安装 opencv视觉库
官方模型的使用
1.下载官方模型
①yolov3.weights权重文件的下载
下载链接:https://pjreddie.com/media/files/yolov3.weights
说明:
将下载的文件放到keras-yolo3文件中
②keras-yolo3代码的下载
Github的下载链接:https://github.com/qqwweee/keras-yolo3
百度网盘分享链接:https://pan.baidu.com/s/1KwiR4itdofL0DmhaJtbGJA
提取码:pfy2
说明:
建议使用百度网盘分享链接下载,Github下载的内容可能存在一些修改内容,会引起后续操作的一些错误。百度网盘分享中已经包含yolov3.weights权重文件,不需要再进行添加,就可以忽略权重文件的下载。
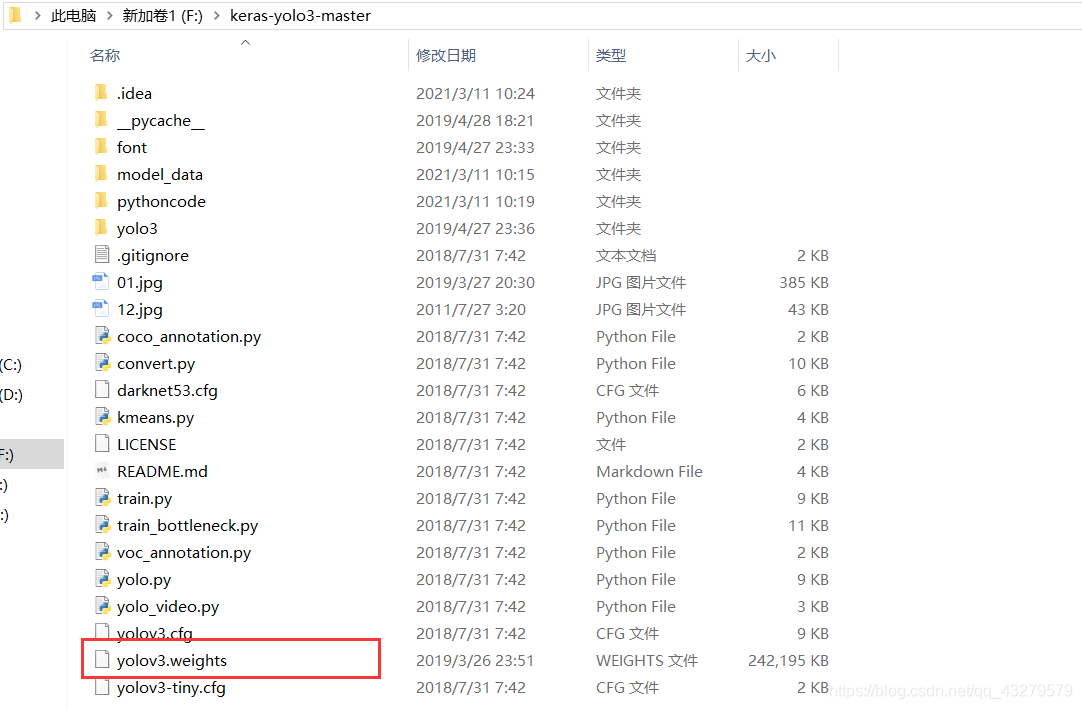
③转换权重文件
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
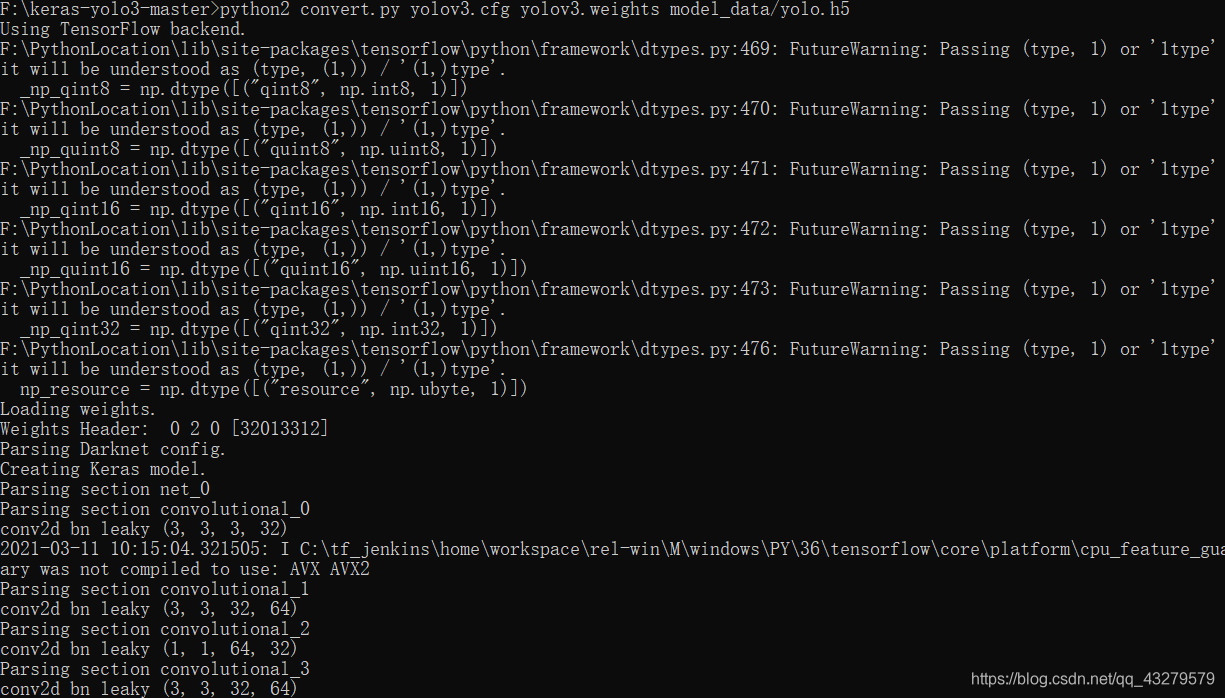
执行完成后
④图片识别
python yolo_video.py --image
提示输入图片路径(图片所处的位置是keras-yolo3-master目录中,跟权重文件再同一目录下)
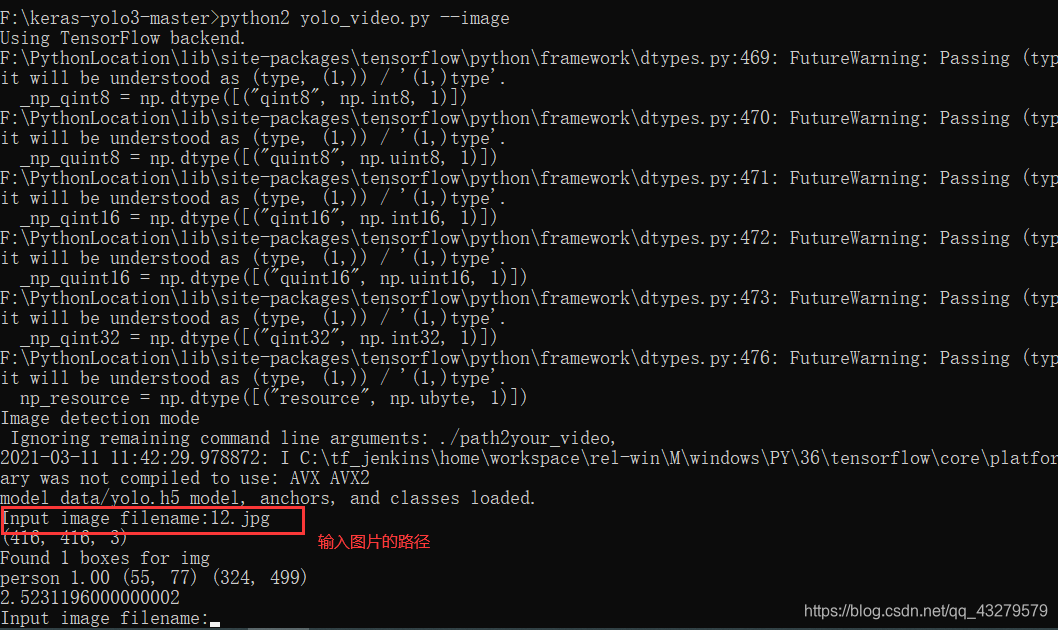
执行效果

制作VOC数据集
VOC全称Visual Object Classes,出自The PASCAL Visual Object Classes(VOC)Challenge,这个挑战赛从2005年开始到2012年,每年主办方都会提供一些图片样本供挑战者识别分类。
PASCAL VOC官网:http://host.robots.ox.ac.uk/pascal/VOC/
1.VOC格式
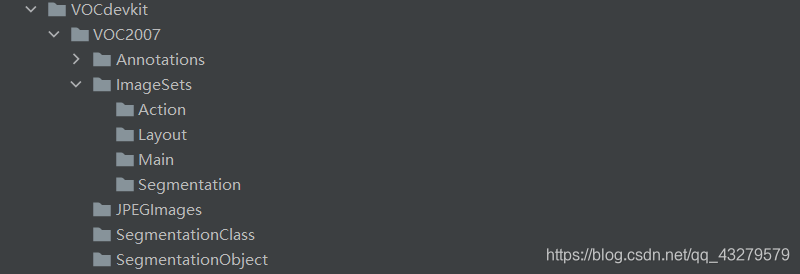
格式目录说明
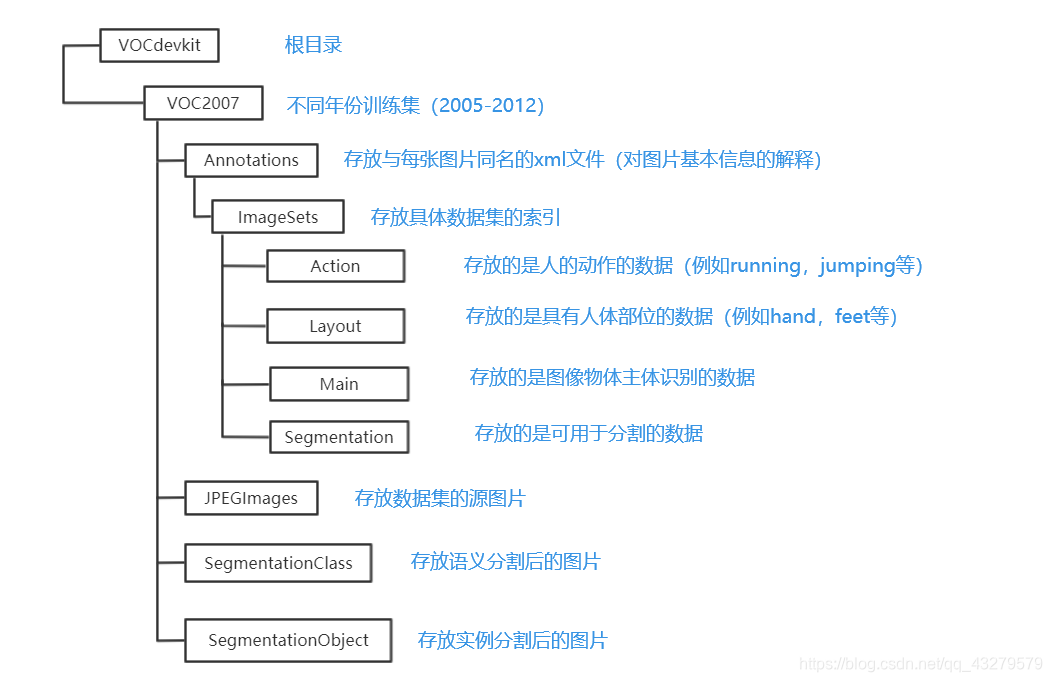
获取VOC数据集格式的方法
①下载官方的VOC数据集,将里面的内容删除,只保留各个文件夹
②按照这个格式手动建立一个文件夹集
这个文件夹直接放到工程文件keras-yolo3-master。
2.准备样本及XML标记
①下载LabelImg
LabelImg 是一个可视化的图像标定工具。Faster R-CNN,YOLO,SSD等目标检测网络所需要的数据集,均需要借此工具标定图像中的目标。生成的 XML 文件是遵循 PASCAL VOC 的格式的。
下载链接:
https://github.com/tzutalin/labelImg/releases
可以源码安装、也可以直接下载exe免安装版本
②图像标注
运行Labellmg
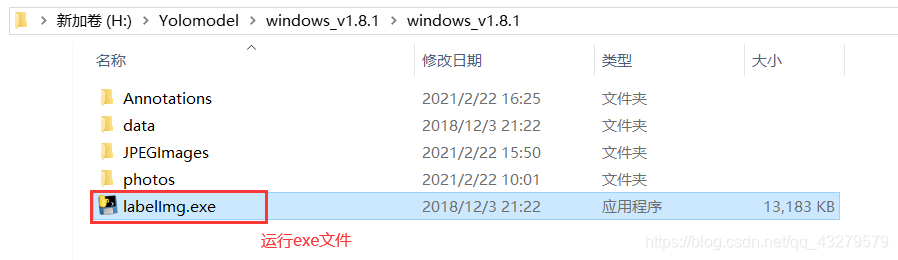
使用方式
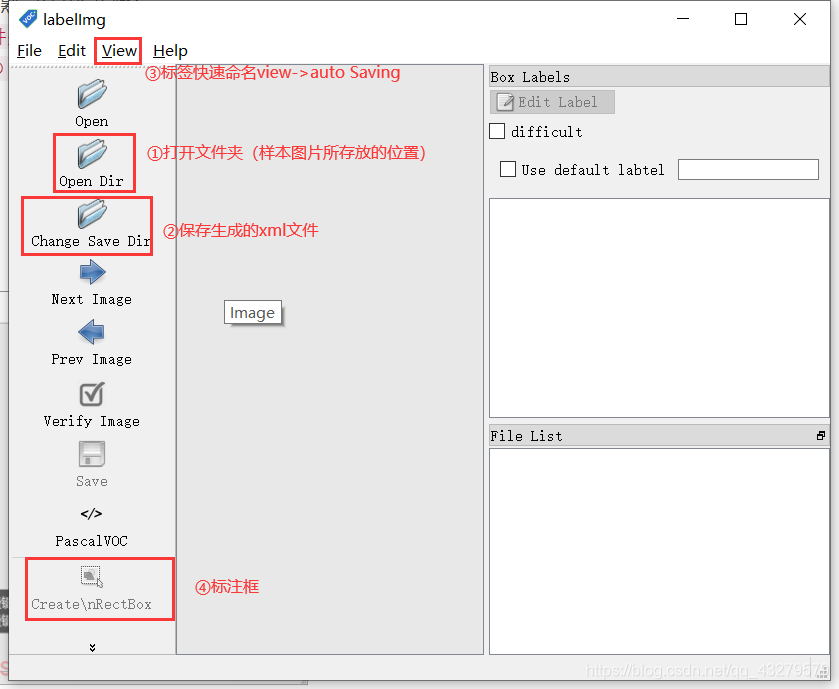
打开文件夹(JPEGImagess)->设置保存文件夹(annotations) 设置自动保存(view ->auto Saving)->标注框(Create RectBox)并命名 快捷键A保存xml->快捷键D下一张
③生成索引
在VOC2007文件夹中新建一个**.py文件**(名字可以命名)
代码如下
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
运行代码后,在ImageSets/Main下生成test.txt,train.txt,trainval.txt,val.txt文件
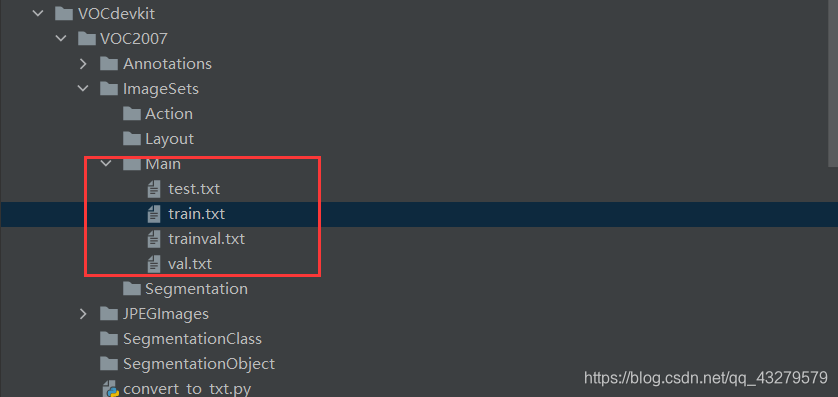
说明:
{class}_train.txt 保存类别为 class 的训练集的所有索引
{class}_val.txt 保存类别为 class 的验证集的所有索引
{class}_trainval.txt 保存类别为 class 的训练验证集的所有索引
YOLO 模型训练
1.生成训练索引
在工程文件keras-yolo3-master中,修改voc_annotation.py文件
主要是把里面classes的内容改成要训练的对象(要和前面标记的一致)
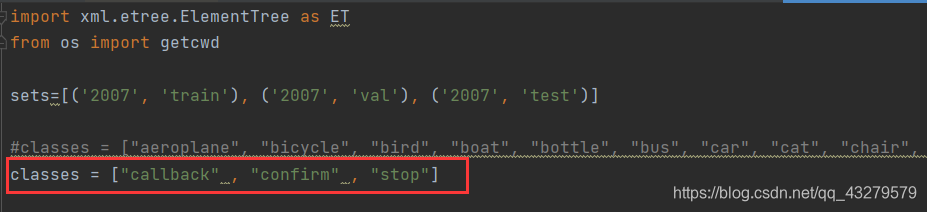
运行该程序,得到下面几个文件,将文件的前缀2007去掉

2.修改配置文件
首先要修改一下 model_data 文件夹中的coco_classes.txt和voc_classes.txt,将里面的对象改成自己要训练的对象名称
3.执行训练
直接将model_data文件夹中原版的yolo.h5复制,改名为yolo_weights.h5,将其作为预训练权重
生成yolo_weights.h5文件之后,在keras-yolo3-master工程文件夹中找到train. py,根据需要,可以更改里面的迭代次数epochs 等参数。如果显存小的话,可以改小batch_size。
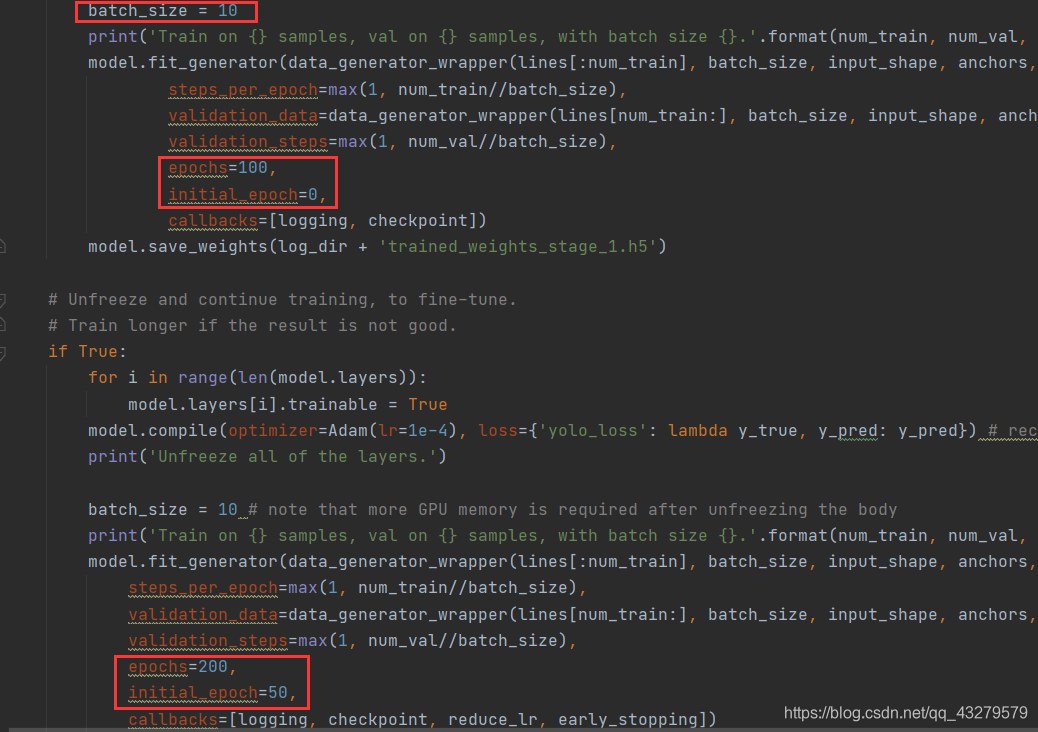
运行train.py
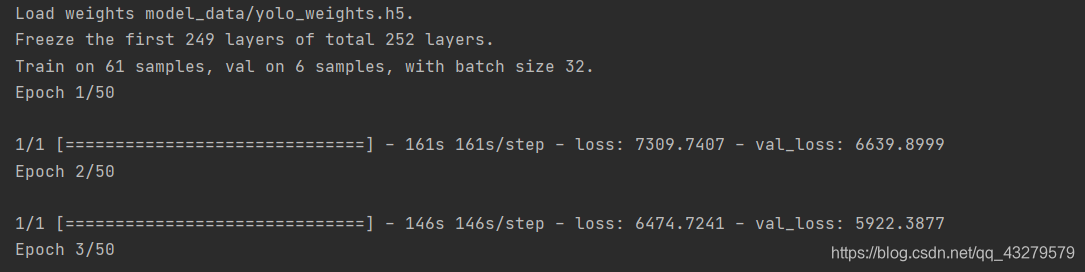
这个训练过程会花费时间比较久。
训练完成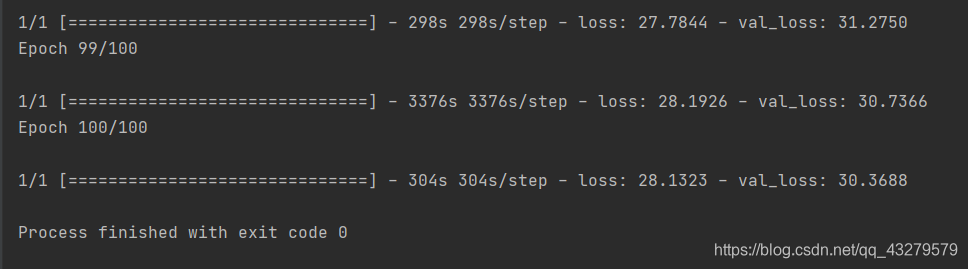
遇到问题
1.AttributeError: ‘str’ object has no attribute 'decode

解决方法:
卸载原来的h5py模块,安装2.10版本
pip install h5py==2.10 -i https://pypi.tuna.tsinghua.edu.cn/simple/
参考资料
1.keras版本yolov3提示str object has no attribute decode
2.【Keras+TensorFlow+Yolo3】一文掌握图像标注、训练、识别(tf2填坑)
3.【YOLO】使用VOC数据集训练自己的YOLOv3模型(Keras/TensorFlow)